فعل مرکب فعلی است که از دو یا چند کلمه ساخته شده است و این کلمات روی هم رفته، نقش یک فعل را بازی میکنند و با هم به عنوان یک واحد واژگانی در واژگان اهل زبان ذخیره میشوند.
مثلا: بعضی از فروشندگان برای افزایش وزن به مرغها آب میزنند.
هدف از این پروژه ارائه روشی برای تشخیص خودکار افعال مرکب در زبان فارسی میباشد.
مقدمه
امروزه استفاده از نرم افزارهای پردازش زبان طبیعی به طور گسترده ای در حال پیشرفت بوده و گسترش روز افزون آن ها باعث شده در بسیاری از حیطه ها بدون وجود این گونه نرم افزارها روند عادی کار ما دچار خلل شود .
انواع مختلفی از این گونه برنامه ها عبارتند از : غلط یاب های نحوی، مدلسازی معنایی، استخراج اطلاعات، ترجمه گر های ماشینی و همچین پردازشگرهایی که به طور طبیعی به وسیله ی صدا با کاربر تعامل می کنند مثل پردازشگرهای فرمان های صوتی در اکثر تلفن های هوشمند .
در پردازشگرهای صوتی روند کلی در تصویر زیر نشان داده شده :

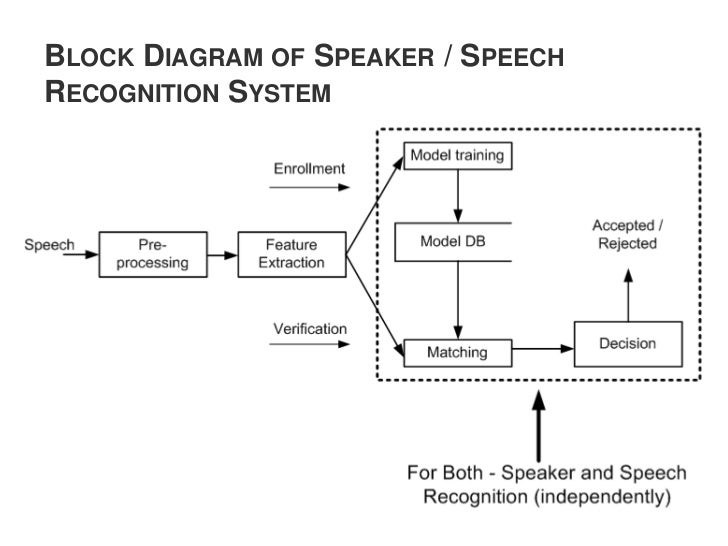
اما در اینجا ما با پردازشگری مبتنی بر متن ارتباط خواهیم داشت ،
در تمامی سیستم های پردازش زبان طبیعی مبتنی بر متن یکی از مراحل اولیه و تاثیرگذار، تشخیص ( اجزای کلام ) یا (Part of Speech (POS
در جمله می باشد . این اجزای کلام در واقع همان نقش های دستوری می باشد که اجزای جمله آن را تشکیل می دهند .
به طور مثال در زبان انگلیسی صورت زیر را داریم :

در زبان فارسی به طور کلی گروه های زیر در جمله موجود می باشد :

تجزیه یک جمله در زبان فارسی با استفاده از درخت تجزیه :
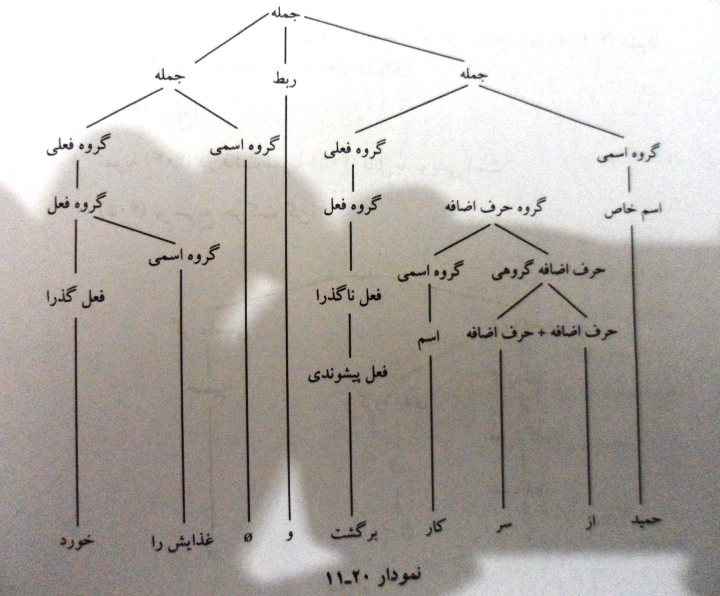
در تعیین اجزای کلام تشخیص فعل مهمترین و تاثیرگذارترین بخش انجام کار است .
هچنین در میان نقشهای دستوری، فعل بیشترین حالت صرفی را در مقایسه با سایرین به خود میگیرد.
فارغ از دنیای نرم افزار و در حوزه ادبیات فارسی، مساله تشخیص فعل در جمله دارای پیچ و خم ها و نکات ظریفی است که گاهی بین ادبدانان اختلاف نظر در تشخیص فعل به وجود میآورد .
از دیدگاه ادبیات فارسی فعل در 6 ساختار شناسایی شده است .
فعل های ساده
فعل های پیشوندی
فعل های مرکب
فعل های پیشوندی مرکب
عبارت های فعلی
فعل های لازم یک شخصه
در اینجا تمرکز بر روی صورت ظاهری یا مدل صرف افعال است ، که این صورت ظاهری، در نتیجه کار در حوزه ادبیات استخراج
و ارایه میشود .
کارهای مرتبط
در اینجا دسته بندی 6 گانه ی افعال را به دو دسته ی کلی ( افعال ساده ) و ( افعال مرکب ) تقسیم بندی می کنیم و مطالعات را بر روی این دو دسته انجام خواهیم داد .
افعال ساده : شامل یک ( ریشه فعل ) هستند که با کمک افعال کمکی و پیشوندها و پسوندها صرف میشود.
افعال مرکب : شامل یک ( ریشه فعل ) و یک ( بخش ثابت فعل ) هستند که صرف نمیشود و همیشه ثابت است . این بخش ثابت ممکن است شامل یک یا چند کلمه دیگر باشد . ممکن است بین بخشهای فعل فاصله باشد یا ترتیب بخشها عوض می شود .
برای تشخیص افعال و نقش کلمه به طور کلی از دو مفهوم استفاده می شود که شناسایی آن ها در زیر آمده است .
ریخت شناسی
که به ساختارهای کلمات و ریشه یابی واژگان می پردازد . به بیانی دیگر ریخت شناسی به علم شناختن اجزای معنی دار یک واژه گویند که آن واژه را میسازد . به این اجزای تک واژ گویند . ( morpheme )
به طور کلی دو طریق برای گسترش واژه ها وجود خواهد داشت .
روش اول تصریف ( inflection ) می باشد . در این روش از ترکیب یک واژه با اجزای دستوری دیگر ، واژه ای از نوع واژه ی اول ایجاد می کند ، این روش گسترش به ما ایم امکان را می دهد که با شناختن تعدادی از تک واژ ها و کلمات بتوانیم رده ی خیل زیادی از کلمات ترکیبی را نیز تشخیص دهیم
به طور مثال :
نشانه جمع فارسی ( ان ) زمانی که به یک اسم مثل درخت اضافه شود واژه ی درختان به وجود می آید که همانند درخت اسم بوده و نوع دستوری مشابه ی دارد .
روش دوم روش اشتقاق است . در اشتقاق با افزودن یک جز دستوری به یک واژه، یک واژه در رده جدیدی به وجود میآید .
یکی از متدوال ترین گونه های ریخت شناسی استفاده از ریخت شناسی حالت متناهی است . در این روش تعریف الگو بر اساس عبارات منظم انجام می شود و پیاده سازی آن بر اساس مدل ماشین متناهی صورت می گیرد .
برای انجام ریخت شناسی در زبان های مختلف نرم افزار هایی ارایه شده از جمله نرم افزار xerox اما به دلیل جهانی بودن کارایی پایینی دارند .
ارایه توصیفی جامع از ساختارهای زبان فارسی ( در این پروژه برای انواع افعال مرکب ) که بتوان از آن در برنامه های رایانه ای استفاده کرد ( مبتنی بر حالت متناهی یا همان DFA ) اولین و اساسی ترین گام در انجام این پروژه می باشد .
الگوریتم porter :
همچنین استفاده از الگوریتم هایی که بتواند ریشه ی کلمات را تشخیص دهد نیز در یافتن افعال بسیار کمک خواهد کرد ُ در زبان انگلیسی الگوریتمی برای یافتن ریشه کلمات وجود دارد که به الگوریتم porter شهرت دارد . این الگوریتم با استفاده از یک ساختار تصمیم گیری و همچین تشخیص وند ها و کاستن و اضافه کردن آن ها سعی در یافتن ریشه ی کلمات دارد ُ از این الگوریتم به طور گسترده در موتور های جست و جو برای بهبود نتایج نمایش داده شده استفاده می شود .
مثالی از روند کار این الگوریتم را از اینجا مشاهده کنید .
مثالی دیگر :
"alumnus" → "alumnu", "alumni" → "alumni", "alumna"/"alumnae" → "alumna"
با توجه به اینکه در فارسی مرز کلمات به طور دقیق مشخص نیست و بسیاری از کلمات دو بخشی بوده و جدا نوشته می شوند استفاده از این الگوریتم ها چندان کارا نیست.
استفاده از روش های بدون پایگاه داده
در این گونه الگوریتم ها قوانین ریخت شناسی مبتنی بر زبان و DFA نبوده و از پردازش حجم زیادی از متون به دست می آید که ذاتا دقیق نیست و عموما برای گسترش و غنی کردن پایگاه داده کاربرد دارد .
برچسب گذاری
در اینجا به کلمات تشکیل دهنده ی یک متن یک برچسب که حاوی نقش کلمات در جمله است نسبت داده می شود .
در تشخیص فعل ما نیازمند جداسازی وند و ریشه و ... هستیم که این امر باعث می شود ریخت شناسی حالت متناهی و استفاده از قوانین ماشین و اریه الگو های تشخیصی ما را در این کار یاری دهد .
تحقیقات
همان طور که پیش تر شرح داده شده برای تشخیص افعال مرکب ابتدا باید فعل بودن یک واژه مشخص گردد ، در واقع جمله باید تحلیل صرفی گردد سپس با استفاده از الگوهای مشخص نوع فعل مشخص گردد .
برای پیاده سازی در ابتدا نیاز به پایگاه داده ای پویا به منظور ذخیره ی دادگانی برای پیاده سازی مدل های صرفی نیاز است .
پایگاه داده ی پویا ، پایگاه داده با قابلیت اضافه شدن داده جدید طبق قانون گذاری ها و محدودیت های اعمال شده می باشد به این گونه که لیستی از واژگان زبان فارسی تهیه شده و به دو بخش کلی واژگان و افعال بخش بندی خواهد شد . این داده ها برای تشخیص نقش واژگان در جمله استفاده می شود .
اولین و مهم ترین داده مرجعی از بن های افعال می باشد ، با استفاده از این دادگان می توان الگوهایی مبنی بر بن فعل برای تشخیص فعل و نوع آن ارائه داد .
نمونه ای از ایک پایگاه داده مورد استفاده برای تشخیص فعل به شکل زیر است :
بن ماضی#بن مضارع
ایستاد#ایست
باخت#باز
بخشید#بخش
بدون وجود این بن ها تشخیص فعل در فارسی عملا ممکن نیست .
از آنجا که در برنامه های پردازشگر زبان طبیعی هدف تنها تشخیص فعل نیست دادگان دیگری برای تشخیص واژگان مورد استفاده قرار خواهد گرفت تا بتوان ضمایر ، حروف ربط ، کلمات پرسشی و و دیگر نشانه ها را تشخیص داد و نوع کلمات را مشخص کرد .
این پایگاه داده معمولا بسیار بزرگ بوده و کارایی و دقت پردازشگر را تحت تاثیر مستقیم قرار خواهد داد .
به طور مثال نمونه از یک پایگاه داده کلمه ای استفاده شده در یک پردازشگر زبان فارسی :
آبپز
آبچکان
آبژاول
آبکردن
آبکردنی
آبکشی
آبکشیده
...
همان طور که می توان دریافت تلاش شده تمامی کلمات زبان فارسی پوشش داده شود تا بتوان بهترین نتیجه را حاصل کرد .
حال با این دادگان شرح داده شده امکان تعریف الگو و تحلیل صرفی برای ما فراهم می شود ، با مقایسه ی دادگان اول و دوم می توان کلماتی که بن فعلی در آن ها استفاده شده استخراج کرد و با مقایسه با الگو هایی که ارائه خواهد شد نوع فعل ، زمان و دیگر ویژگی ها را تشخیص داد .
مرحله ی اول تکه کردن جمله به واژه ها یا tokenize کردن می باشد . در این مرحله جمله به واژگان تشکیل دهنده اش تکه می شود .
tokenizer.tokenize('این جمله (خیلی) پیچیده نیست!!!')
['این', 'جمله', '(', 'خیلی', ')', 'پیچیده', 'نیست', '!!!']
جداسازی دقیق واژگان و همچنین تشخیص علایم یا punctuation بسیار مهم است زیرا اولین و مهم ترین بخش کار را تشکیل خواهد داد .
این بخش مشکلی کوچک خواهد داشت آن این که در زبان فارسی افعال دارای پیش وند و پس وند هایی می باشند ، پس این ها نباید جدا شوند برای مثال فعل "خواهند رفت " نباید به شکل "خواهند"،"رفت" تکه شود .
برای مثال چند نمونه از پیش وند ها و پس وند ها به شکل زیر است :
self.after_verbs = set([
'ام', 'ای', 'است', 'ایم', 'اید', 'اند', 'بودم', 'بودی', 'بود')]
self.before_verbs = set([
'خواهم', 'خواهی', 'خواهد', 'خواهیم', 'خواهید', 'خواهند')]
تا به اینجا جمله ی ورودی به بخش های واحدی تجزیه شد ، این بخش ها باید به گونه ای باشند که نقش ( POS ) بگیرند .
حال پس از آنکه جمله به کلمات تشکیل دهنده تکه شد نوبت به پردازش تکه ها (token) می رسد .
لازم به ذکر است برای تشخیص افعال در زبان فارسی راه های غیر دقیق زیادی وجود دارد .
به طور مثال :
در زبان فارسی افعال معمولا در انتهای جمله ظاهر می شوند یعنی درست قبل از علایم پایان جمله ، اما این راه دقیقی برای تشخیص نیست ، در اینجا تلاش شده راه های دقیق مورد بررسی قرار گیرد .
برای پردازش تکه ها باید آن ها را با الگو هایی مقایسه کرد اما پیش از آن که به بررسی الگو ها بپردازیم اندکی درباره ی ریشه یابی کلمات (stemmer ) شرح داده می شود .
ریشه یاب ها به منظور تشخیص بخش اصلی کلمه به کار رفته و پس وندها و پیش وندها را تشخیص داده از اصل کلمه حذف می کنند ، این کار باعث کاهش حجم دادگان واژه ها شده و کار پردازش را ساده خواهد کرد.
پس وند ها :
self.ends = ['ات', 'ان', 'ترین', 'تر', 'م', 'ت', 'ش', 'یی', 'ی', 'ها', 'ٔ', 'ا', '']
برای مثال نمونه ای از یک ریشه یاب :
stemmer.stem('کتابی')
'کتاب'
stemmer.stem('کتابها')
'کتاب'
stemmer.stem('کتابهایی')
'کتاب'
stemmer.stem('کتابهایشان')
'کتاب'
stemmer.stem('اندیشهاش')
'اندیشه'
حال باید واژه ها نقش گذاری شده سپس فعل مرکب تشخیص داده شود .
برای اینکار باید جمله را به عبارت های اسمی ، فعلی و .. تجزیه کرد حال اگر در بخش عبارت فعلی الگوی زیر وجود داشت فعل مرکب تشخیص داده می شود .
{اسم + ( عبارتی شامل بن که بدنه ی اصلی فعل است ) } = عبارت فعلی
این کار به شکل زیر صورت می گیرد :
([('نامه', 'Ne'), ('ایشان', 'PRO'), ('را', 'POSTP'), ('دریافت', 'N'), ('داشتم', 'V'), ('.', 'PUNC')]))
عبارت های فعلی و اسمی به تفکیک :
'[نامه ایشان NP] [را POSTP] [دریافت داشتم VP] .'
برای تشخیص ای افعال به ماشین ها حالت متناهی نیاز داریم تا با توجه به گرامرهای تعریف شده فعل و انواع آن مشخص گردد .
چند مورد از الگوهای موجدو برای تشخیص فعل :
بن ماضی + م|ی|یم|ید|ند| ماضی ساده
بن ماضی -> G
پس وندها -> post
نمونه ی DFA ماضی ساده :
s->AB
A->[G]
B->[post]
الگوی ماضی استمراری :
می + بن ماضی + یم |ید|ند|م|ی
s->(mi)AB
A->[G]
B->[post2]
الگوی ماضی بعید :
بن ماضی + ه + بود + (یم|ید|ند|م|ی)
s->[G]'h'(bod)B
B->[post2]
تعریف این DFA ها برای تمامی افعال فارسی صورت می پذیرد ، پس از آن با استفاده از دادگان بن ها و واژگان و استفاده از الگوها ، عبارت فعلی یا همان VP تشخیص داده می شود و اگر ساختار به صورت" اسم + فعل " باشد ، این عبارت فعل مرکب است .
دقت و بهبود عملکرد به دادگان و الگو های دقیق وابسته بوده و بسیار حائز اهمیت است .
باید توجه داشت افعال منفی نیز جزئی از افعال بوده پس در تعریف ماشین باید دسته ی جداگانه از گرامر را شامل شوند .
ماضی مستمر مجهول منفی :
بن ماضی + ه + نمی شد + (یم|ید|ند|م|ی)
s->[G]'h'(nemi)(shod)B
B->[post2]
با این روش فعل ، نوع زمان و تمامی ویژگی ها تشخیص داده شده و می توان از آن در کاربرد های زیادی از جمله انواع ویرایشگرها و ... استفاده کرد .
لازم به ذکر است در زبان فارسی کتابخانه برای پیاده سازی پردازش زبان طبیعی با نام هضم تحت زبان پایتون وجود دارد که پیاده سازی و پردازش را ساده و بسیار کارا خواهد کرد .
کارهای آینده
ارئه مدل های بهبود یافته برای تشخیص .
مراجع
بررسی راهکارهای ماشین تشخیص هوشمند افعال مرکب در زبان فارسی ( علم وصنعت )
پردازشگر فارسی هضم
ساختواژه حالت-متناهی ( روشی مناسب برای طراحی پردازشگر ساختواژی ) دفتری نژاد,
کتابخانه هضم