Demo: a demo version of the tagger can be viewd from here, this version may often be down because of the VPS breakdowns or code updates. thanks to Mr.Khalili for the design.
recognizing and extracting exact name entities, like Persons, Locations and Organizations from natural language text is called Named Entity Recognition (NER). for example in the sentence "[PER Murdoch] discusses future of [ORG News Corp]" understanding that the word "Murdoch" is a Person and the entity "News Corp" is the name of an Organization is the task of an NER agent.
Abstract:
in this paper, firstly, we are going to explain different techniques, methods, discuss design challenges, misconceptions and feature extraction which underline the development of an efficient and robust NER system. then we are going to introduce Iris: the Farsi name entity recognizer agent which is based on statistical distribution techniques and machine learning methods. Iris uses techniques corresponding to natural language processing and Farsi words and sentence's syntax and structure.
1. Introduction
Natural Language Processing applications are characterized by making complex interdependent decisions that require large amounts of existing knowledge. in this paper we discuss one such application, Named Entity Recognition (NER). the sentence below shows the necessity of using prior knowledge and non-local decisions. in the absence of such method it is difficult to understand "Blinker" is a person.
[PER BLINKER] BAN LIFTED . [LOC LONDON] 1996-12-06 [MISC Dutch] forward [PER Reggie Blinker] had his indefinite suspension lifted by [ORG FIFA] on Friday and was set to make his [ORG Sheffield Wednesday] comeback against [ORG Liverpool] on Saturday. [PER Blinker] missed his club’s last two games after [ORG FIFA] slapped a worldwide ban on him for appearing to sign contracts for both [ORG Wednesday] and [ORG Udinese] while he was playing for [ORG Feyenoord].>
it is also not obvious that the last mention of "Wednesday" is an organization. the whole task of an NER system is to identify, extract and label the entity names in a text.
data is being generated with a fast pace and with it the need to use them, but most of the data created is unstructured and unlabeled, the basic task of labeling this data, i.e. giving meaning to the text in a way computer and other algorithms understand is very important. it is the basis of many other problems such as Question Answering, Summarization Systems, Information Retrieval, Machine Translation, Semantic Web Search and Bioinformatics.
at this time researchers use different methods for this task which we will discuss. NER involves two tasks, which are firstly identification of proper names in text, and secondly the classification of these names into a set of predefined categories of interest.
1.1. Name entity types
different tasks require differnet number of types, but the most common types are PER for person names, ORG for organizations (companies, governmetnt organizations, committees, etc), LOC for locations (cities, countries, etc).
The CoNLL1 shared task concentrated on four name entities: persons (PER), locations (LOC), organizations (ORG) and names of miscellaneous entities (MISC) that do not belong to the previous three groups.
MUC2 in their MUC7 dataset which is a subset of the North American News Text Corpora annoted entitites including people, locations, organizations, monetry units, and so on.
1.2. NER tagging schemes
before we go along, in the task of NER there are two main tagging schemes, BIO and BILOU.
BIO: 'B' stands for 'beginning' and signifies the beginning of a name entity, 'I' stands for 'inside' and signifies that the word is inside of a name entity, and 'O' stands for 'outside' which signifies that the word is just a regular word outside of a name entity[1].
table 1-1.an example for name entity tags based on BIO scheme.
| NE tag | word of sentence |
|---|---|
| B-PER | John |
| I-PER | Kerry |
| O | will |
| O | fly |
| O | to |
| B-LOC | paris |
BILOU: it stands for Beginning, Inside and Last tokens of multi-token chunks, Unit-length chunks and Outside, which is self explanatory, in the evaluation section we'll discuss the evaluation process based on each scheme and problems that exist[1].
table 1-2.an example for name entity tags based on BILOU scheme.
| NE tag | word of sentence |
|---|---|
| B-PER | John |
| L-PER | Kerry |
| O | will |
| O | fly |
| O | to |
| U-LOC | paris |
1.3. Different NER approaches
in references [2,3] different approaches of NER are introduced, each with different usage:
1.3.1. Rule-based NER
hand made rule-based approach focuses on extracting name entities using a lot of human-made rule sets, generally the tagger system consists of a set of patterns using grammatical (e.g. part of speech), syntactic (e.g. word precedence) and orthogiraphic features (e.g. capitalization, prefixes, etc) in combination with dictionaries. these kind of models have better results for restricted domains and have the ability to detect complex entities that learning models have difficulty with. how ever these rule-based systems lack the ability of portability and even though the data is slightly changed, they have a high cost to change the rules. these approaches are domain and language specific and do not easily adapt to new domains and languages[2].
FASTUS is a system based on handcrafted regular expressions which divided the task into three main steps: recognizing phrases, recognizing patterns & groups and in the third stage merging the incidents, in which distinct structures that describe the same entity are identified and merged[4].
1.3.2. Machine learning-based NER
in these systems which is mostly the focus of this article, the NER task is converted into a classification problem and statistical models are employed to solve it, which will be discussed later on. in this type of approach, the system looks for patterns and relationshios in the text to make a model using statistical models and machine learning algorithms. unlike the rule-based method, these types of approaches can be easily changed and used at different domains and languages[2,3].
in this task two main methods of machine learning are used[2]:
supervised learning: it involves using a system that can learn to classify a given set of labled examples, the supervised term is used because the people who marked the training examples are teaching the program the right distinctions. this approach requires preparing a large amount of labeled training data. many methods such as HMM3[5], CRF4[6], perceptron[7] of this type of learning are proposed for NER which will be discussed later.
semi-supervised: a recent approach is to use both labeled and unlabelled data, this approach benefits from both supervised and unsupervised learning and has some interesting techniques. labled data is hard to find and expensive and time consuming to produce, in contrast unlabelled data is cheap and easy to obtain a huge amount of. recent result and especially in this task have shown that one could reach better results, simply by adding unlabelled data to their supervised system. some commonly used methods for semi-supervised learning are co-training, graph-based methods and so on[2].
1.3.3. Hybrid NER
the approach is to combine the rule-based and machine learning-based methods and make new methods from strongest points from each method. although this type of method might get better results than other approaches, the weakness of handcraft rule-based NER remains the same[2].
2. Related works
In recent years, automatic named entity recognition and extraction systems have become one of the popular research areas that a considerable number of studies have been addressed on developing these systems. NE5 recognization like many NLP6 tasks, can be broken down to two stages, preprocessing and processing.
the focus of this paper will mostly be on machine learning methods, so the features and methods discussed are mostly in same context.
2.1. Preprocessing
in an NLP problem we are dealing with a natural language, in which some things are fixed and hardly change, so we can use them as features to solve our problem. as illustrated in the introduction, NER is a knowledge-intensive task so in this section some important knowledge rescources will be discussed.
2.1.1. Gazetteers
an imortant question at the inception of NER was whether machine learning techniques are necessary at all, and wheter simple dictionary lookup would be suffiient for a good performance. indeed the baseline for this task was just a dictionary lookup for entitites which are in the training data[8]. it turns out that while problems of coverage and ambiguity prevent a simple straightforward lookup, using gazetteers as a feature in machine-learning based approches is critical for good performance[3].
knowing this, one can extract gazetters from the web and large collections of unlabeled text.
2.1.2. Brown clustering
it's been illustrated that unlabeled text can be used to improve the performance of the NER system[3]. brown clustering is a hierarchical word clustering algorithm[9]. the intuition behind this algorithm is that similar words appear in similar contexts, more precisely similar wods, have similar distribution of words to their immediate left and right. for example before the word "the" it's likely that you see "in" or "on" and many similar words. the algorithm takes sentences as input and based on the words and their similarities in the contexts and it outputs each word and its cluster. for example here is an input and output of the algorithm[10].
input:
the cat chased the mouse
the dog chased the cat
the mouse chased the dog
table 2-1. output of the brown clustering algorithm
| cluster represented as bit string | word |
|---|---|
| 0 | the |
| 10 | chased |
| 110 | dog |
| 1110 | mouse |
| 1111 | cat |
2.2. Processing
in this section we study some local and non local features.
2.2.1. Lexical information
using n-gram one can get a good improvement in results. n-gram is a language model for predicting the next item in a sequence of items, in this case characters of the words. an n-gram of size one is called unigram and size 2 is called bi-gram, which are the common n-grams used in this task. for example for a sequences of characters, the 3-grams that can be generated from "good morning" are "goo", "ood", "od ", "d m", " mo", "mor" and so forth[2].
2.2.2. Affix
affix is an addition to the base form of a word in order to change its meaning or create a new word, e.g. suffix and prefix letters.
using this feature one can once again identify similar words[2].
2.2.3. POS7 tags
part of speech tags which are givent to a word based on its role in the sentence as well as its definition and the context i.e. relationship with adjacent and related words in a sentence or phrase.
table 2-2. an example of POS tagging[2,3].
| POS tag | word |
|---|---|
| DET | the |
| N_SING | waiter |
| VBD | cleared |
| N_PL | plates |
| P | from |
| DET | the |
| N_SING | table |
2.2.4. Previous NE information
previous NE information also called UniChunk, can be used as a feature in many cases. the intuition behind it, is to find a similar situation, which had been recognized before in the train set and compare it to current situation of work chunks, knowing a number of predictions before e.g. two last name entity predictions can help find the similar situation[2,11].
2.2.5. Some simple patterns
capitalization of the word(in languages that have capitalization)[3].
number normalization: normalizing dates and numbers, that is 12/8/2004 becomes Date, 1980 becomes DDDD allows a degree of abstraction to years, phone numbers, etc[3].
word shapes: map words to simplified representation that encodes attributes such as length, campitalization, numerals, Greek letters, internal punctuation, etc[11].
table 2-3. an example of word shape[11].
| shape | word |
|---|---|
| Xx-xxx | varicella-zoster |
| xXXX | mRNA |
| XXXd | CPA1 |
2.2.6. Classifier
in this task the most common classifiers used, are called sequence classifiers which in this case are ME8 sequence models and CRFs which predict labels from data[12].
in ME, there are words and the goal is to assign classes or tags to each of them. it's common to better explore the search space i.e. at a certain position one NE tag is the best, but later on once in another state it gives one a reason that maybe the former tags shoud have been chosen differently. in this section we study two of these inferences.
Beam inference: in Beam inference at each position rather than just deciding the most likely label, we can keep several posibilities, so we might keep the top K complete sub sequences up to the point where we are at so far, and so at each state, we'll consider each partial subsequence and extend that to one further position. it's very fast and easy to implement and it turns out, at Beam sizes of 3-5, gives enough posibilities and works as well as exact inference in many case. but one gets no guarantees that has find the globally best name entity tag sequence, and even worse the best sequence might not even be checked, or in terms of Beam inference, might fall off the Beam[12].

Figure 2-1. showing sequence inference based on sequence model Viterbi inference: it's a form of dynamic programming and requires a small window of state influence (e.g. past two states are relevant). it guarantees that the global best sequence is returned, but it's harder to implement and forces one to a fixed small window[12].
CRFs: conditional random fields are another kind of probabilistic sequence model. CRFs are undirected graphical models used to calculate the conditional probability of values on particular output nodes given values assigned to other input nodes[13]. suppose the observed input data sequence:
o = \left \{ o_{1},o_{2},...o_{T} \right \}such as a sequence of words in a document, and let 'S' be a set of FSM states, each associated with a tag, such as ORG, having the sequence of states (the values on T output nodes):s = \left \{ s_{1},s_{2},...s_{T} \right \}CRF can define the conditional probability of a state sequence given an input sequence as:P(s|o) = \frac{1}{Z_{0}} exp(\sum_{t=1}^{T}\sum_{k}\lambda _{k}f_{k}(s_{t-1},s_{t},o,t))where Z_{0} is a normalization factor over all state sequeces, f_{k} is an arbitary feature function over its arguments, and \lambda_{k} is a learned weight for each feature function[13]. we'll discuss the CRFs with more detail later in the implementation section.
3. Evaluation
the evaluation of name entity task is a little tricky, firstly becuse there are different number of name entity tag sets and also different schemes (e.g. earlier discussed BIO, and BILOU, etc) and secondly because it is done per entity and not per token, because in this task the goal is to find both the bandries and the class of a name entity, in other words our unit of interest is the whole entity.

so in the contingency table the values will be at the level of entities.
3.1. Precision and Recall
precision and recall are standart tools in IR9 evaluation. in this task TP10 are the entities that system labeled correctly, FP11 are the entities that system labeled incorrectly, FN12 are the entities that should have been labeled, but the system did not labeled them. with that in mind Precision will be:
and Recall would be:
Precision and Recall are straight for tasks like IR and text categorization, where there is only one grain size document. these measure behave a bit differently for NER when there are boundary errors, which are very common. for example in the sentence "First Bank of Chicago announced earnings ..." if the system labeled "Bank of Chicago" as an organization instead of labeling the "First Bank of Chicago" it would count as both a FP and a FN, so selecting nothing would have been better.
3.2. F-score
F-score is a harmonic mean of precision and recall.
despite the challenges in these measurements, they're the most common measures for evaluation in NER.
4. Experiments
What comes next is a briefing about the corpuses used in the experiments and evaluations, first method and features that were taken in action in each one and the evaluation of each trained model.
4.1. Corpus
The data used to train NER taggers conventionally consists of a huge number of rows, each one consists of a number of columns which are the actual word, part of speech tag and NER tag which sequentially form sentences.
First corpus that has been used in the experiments has the same conventional format, it consists of 208165 words. the data is distributed to total number of 9 classes. the NER tagging schema is BIO13 and the entity tags are PERS (for person), ORG (for organization), LOC (for location) and MISC (for miscellaneous).

Figure 4-1.showing a number of rows out of data set 'A' as an example
as the courtesy of Mr.Asgari.
But the problem with this data set is the ambiguity of entity names in Persian language (not to be confused with Name Entity Ambiguities which is another problem), for example in the sentences
ایران با واشنگتن در دیداری .....
or
پوتین، آنکارا را تهدید کرد.
the word ایران in here does not mean a location and neither does واشنگتن or آنکارا and should not be tagged LOC, both of them should be tagged as organizations.
Another important things is the lack of Ezafe construction annotation in the data set which can be used for phrase bounderies and sequences[14].
وزارت (کسره) آموزش و پرورش(کسره) ایران (کسره) اسلامی ...
Next problem with this data set is the lack of normalization in Persian characters, e.g. جمهوری and جمهوری are different, these problems can be seen in words with ی ,ک ,ه.
The second data set which is the courtesy of Mr.Abdous is far more better, richer and delicate than the first one. for the sake of referencing this data set will be called 'B'. this data set consists of 400 thousand rows, which like data set 'A' has BIO tagging schema and has 13 number of classes consisting 6 entity types: Facility, Organization, Person, Location, Event, Product.

Figure 4-2. showing a number of rows out of data set 'B' as an example
Unlike the data set 'A' this one benefits from Ezafe annotations as it can be seen in Figure 4-2 there are more columns in the data set, the 3rd column shows more information about the part of speech tag, showing Ezafe construction as 'GEN' which can be seen in some of the rows. In addition, this data set is normalized and because of its covering number of entity types, does not have the former discussed ambiguity.
4.2. Test 'A'
A couple number of tests have been done on each data set, only one of each will be discussed here. as discussed in many papers, CRFs are one of the best tools for the task of named entity recognition[15,16]. for both of these tests Stanford'CRF has been used, which is a very powerful and well-engineered CRF classifier[16]. this classifier is a part of Stanford CoreNLP which provides a set of natural language analysis tools.
The features used in this experiment are as follows:
Class Feature: which includes a feature for the class (as a class marginal) in other words puts a prior on the classes which is equivalent to how often the feature appeared in the training data.
N-grams: makes features from letter n-grams, i.e. substrings of the word, not the words.
No mid grams: which Does not include character n-gram features for n-grams that contain neither the beginning or end of the word.
Previous Sequences: using any class combination features using next classes.
Maximum left and right words (window size) used is 2.
Word Shape: Stanford NER feature factory has a couple of word shapers which can be used to return the shape of the word that can be used as a feature.
Disjunctive words: which include features giving disjunctions of words anywhere in the left or right disjunction-width which preserves direction but not position.
Quasi-Newton optimizer (L-BFGS): which actually is not a feature but is worth mentioning, it is an optimizer which maintains a number of past guesses which are used to approximate the Hessian. Having more guesses makes the estimate more accurate, and optimization is faster, but the memory used by the system during optimization is linear in the number of guesses.

Figure 4-3. an example of the model trained on data set 'A'
As it can be seen in Figure 4-3,this model tagged most of the entities right but failed to tag "فرهنگستان زبان و ادب فارسی ایران" as an organization, one of the reasons could be the lack of Ezafe construction annotations in the data set which was discussed earlier. training another model on this data set using more and better features would surely make it more precise.
4.3. Test 'B'
In this test data set 'B' has been used to train the model and the added features are as follows:
POS tags: the part of speech information about each word alongside other features could be very helpful.
Using Titles: matches a word against a list of name titles (آقا,خانم, etc.).
Using word pairs: adds features for (pw, w, c) and (w, nw, c), in which p is the position of the word in the sentence, w is the word, c is class and n is the n-gram for the word. this kind of feature would create a lot of additional features which may not be all useful.
In addition to these features this data set 'B' has more classes and rows.

Figure 4-4. an example of the model trained on data set 'B'
5. Performance Evaluation
system configuration:
OS X El Capitan
Processor: 2.5 GHz Intel Core i5
Memory: 16 GB 1600 MHz DDR3

5.1. Evaluation of Test 'A':
to evaluate the performance of this model, a number of 20 thousand rows of the data set 'A' was taken, tagged by the model and tested against the gold tags which lead to the F1-score of 90.36 %. this is an token-based evaluation not an entity-based one.
table 5-1. Precision,Recall and F1-score of model 'A'.
| F1-Score | Precision | Recall |
|---|---|---|
| 90.36 | 94.36 | 87.13 |
5.2. Evaluation of Test 'B':
The same was done for model 'B' which lead to a F1-score of 93.25%.
table 5-2. Precision,Recall and F1-score of model 'B'.
| F1-Score | Precision | Recall |
|---|---|---|
| 93.25 | 99.40 | 87.83 |
5.3. Brown Clustering Approach
as stated earlier brown clusters give some level of abstraction and meaning to un-supervised text which can be used as another feature for CRF. It maps each word in the text to a cluster shown as bits, an example is shown in figure 5-1.
The text used to make the mapping dictionary was a wiki-pedia dump, after running the algorithm on extracted and normalized data the brown cluster tag for each word (if existed) was added to the text corpus.
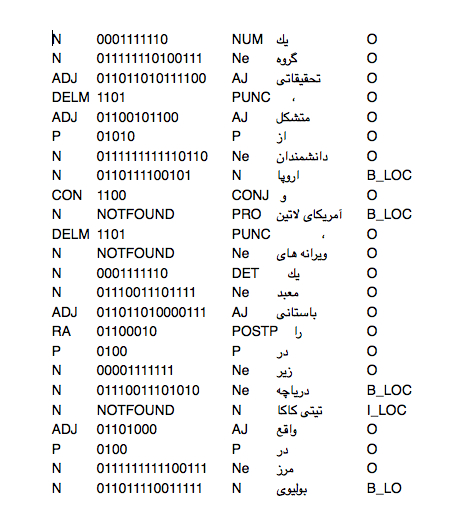
As it can be seen some of the words' are tagged as 'NOTFOUND' which is a special cluster tag for words with no mapping in the dictionary.
The rest of this part explains the results from a 5-Fold Cross Validation evaluation, in which the Data Set was separated into 5 parts, each time using 4 out of 5 as train set and the rest as test set to perform a 5-fold validation, repeating this process 5 times, with each of the 5 subsample used exactly once as the validation data.
The results from these tests were amazingly high, the NER tag 'O' which represents a word not being tagged as a named entity is considered in the True-Positives if the Golden Tag (the supervised NER tag from corpus) and the prediction, both has this same value.
Alongside Brown-Cluster tag as another feature, all other features are the same as they were in Test 'B'. Due to space limitations, only one of the five classification report tables is shown, for further analysis of all tables(precisions, recalls and exactly what kind of induction each number provides) refer to the demo page.
These reports were produced using the scikit-learn's classification report tool for multi-labled classifications.
Table 5-3. Precision, Recall and F1-score for all the classes in fold 3.
| F1-Score | Recall | Precision | Number of Labels | Class Label |
|---|---|---|---|---|
| 1.00 | 1.00 | 1.00 | 71808 | O |
| 0.61 | 0.51 | 0.77 | 141 | B_PERS |
| 0.79 | 0.76 | 0.83 | 93 | I_PERS |
| 0.82 | 0.79 | 0.85 | 135 | B_LOC |
| 0.71 | 0.67 | 0.77 | 15 | I_LOC |
| 0.71 | 0.61 | 0.86 | 119 | B_ORG |
| 0.82 | 0.76 | 0.89 | 95 | I_ORG |
| 0.74 | 0.62 | 0.91 | 66 | B_FAC |
| 0.68 | 0.54 | 0.91 | 94 | I_FAC |
| 0.53 | 0.61 | 0.47 | 74 | B_EVENT |
| 0.68 | 0.78 | 0.60 | 449 | I_EVENT |
| 0.29 | 0.23 | 0.39 | 31 | B_PRO |
| 0.00 | 0.00 | 0.00 | 5 | I_PRO |
| 0.99 | 0.99 | 0.99 | 73125 | avg/total |
The following table shows results for each test and the total average of each evaluation parameter.
Table 5-3. Precision, Recall and F1-score of 5-fold cross validation.
| Recall | Precision | F1-Score | Test Number |
|---|---|---|---|
| 0.96 | 0.96 | 0.96 | I |
| 0.98 | 0.98 | 0.98 | II |
| 0.96 | 0.96 | 0.96 | III |
| 0.99 | 0.99 | 0.99 | IV |
| 0.96 | 0.97 | 0.96 | V |
| 0.97 | 0.97 | 0.97 | Total |
5.4. Deep Learning Approach
Neural networks, a beautiful biologically-inspired programming paradigm which enables a computer to learn from observational data has provided the best solutions to many problems in image recognition, speech recognition, and natural language processing.
Recently, Deep learning, a powerful set of techniques for learning in neural networks has been introduced. using deep architectures for Neural Networks, equipes one with great tools to solve many problems. Deep Learning has a lot to it and the study of it for this section, and in fact the level of abstraction needed to understand what is described next is not within the scope of this paper. The reader is strongly encouraged to have a background in neural nets and deep learning architectures for which there are some important links down below.
5.4.1. Features:
right to it, the only backbone to all of this and what actually has made it all possible is the distributed representations of words and phrases and their compositionality, or in one word Word2Vec[17].
Word2Vec is a two-layered neural network that processes text. it gets as input a text corpus and its output is conventionally a set of vectors which are the feature vectors for words.
While this neural net is not a deep neural network its output can be used in deep nets as a vector of features, a vector that deep neural nets can understand. the process of learning a Word2Vec model is amazingly fast and efficient.
The purpose and usefulness of the Word2Vec is that is groups the vectors of similar words together in vector-space, i.e. it detects similarities mathematically and creates vectors that are distributed numerical representations of word features with no supervision.
The text used to train the Word2Vec model is the same normalized and tokenized wiki-pedia dump.

5.4.2. Classifier
Recurrent Neural Networks and LSTMs 14 are powerful neural network algorithms which are very useful for processing sequential data, in this case natural language text. These networks differ from conventional feedforward networks because they have a feedback loop, where output from step n-1 is fed back into the network to affect the outcome of step n, and so forth for each step thus making them a very good choice for this task. This makes these networks context aware and giving them a level of memory, hence the name[18].
Actually the architecture is inspired by human brain and human memories. The framework chosen for this project is Keras, a high level modular neural networks library in Python.
5.4.3. Evaluation and Test
The model was trained on the first corpus (data-set 'A'), a two layerd RNN15, the first layer is a 200 to 64 encoder, which means it takes as input a vector of length 200 which is the result vector of each word in the data-set from the trained Word2Vec model and another labels vector of length 9, showing the NER tag index by 1 and other entries 0.
Second Layer outputs 9 values which will be a number between 0 to 1, index of the maximum value of these will be taken as the predicted NER tag index in the vector.
Table 5-9. Precision, Recall and F1-score of the Deep Learning approach on data-set 'A'.
| F1-Score | Precision | Recall |
|---|---|---|
| 94.53 | 96.34 | 95.42 |
6. Future work
This task requires to test many methods, including the recent methods such as Deep Learning, many more Deep Learning methods such as LSTMs can be used for this task. Using only the Word2Vec vector as a vector-space feature is not enough, because each word may have different NER tags in different situations, such as "ایران", which can be be tagged as LOC in one sentence and as ORG in another sentence being a part of an ORG token, having only one vector for this word as a feature and not considering the word in the context of the sentence is one of the problems which has to be solved in this area of approach.
The Word2Vec model can be better trained with higher accuracy on a larger corpus, the news text data from Mirad which is more than a million news articles is going to be used to train the model for better results.
As for the CRF classifier approach the classifiers can be trained with more features such as Stems and Lemmas of the word, a list of Gazettes can also be useful for training the classifier.
There are many methods for extracting a Gazetteers list from Knowledge Bases such as DBpedia, a structured KB16 based on WikiPedia providing a rich and consistent anthology in 125 languages[19].
7. References
[1] http://stackoverflow.com/questions/17116446/what-do-the-bilou-tags-mean-in-named-entity-recognition. as available on November 2015.
[2] Mansouri, Alireza.Affendey, Lilly Suriani,Mamat, Ali. Named Entity Recognition Approaches. Journal of Computer Science. 2008. vol 8. pages 339-344.
[3] Lev Ratinov, Dan Roth. Design Challenges and Misconceptions in Named Entity Recognition. Proceedings of the Thirteenth Conference on Computational Natural Language Learning. June 2009. pages 147-155.
[4] Jerry R. Hobbs, Douglas Appelt, John Bear,David Israel, Megumi Kameyama, Mark Stickel, and Mabry Tyson. FASTUS: A Cascaded Finite-State Transducer for Extracting Information from Natural-Language Text. “SRI International FASTUS
[5] Zhou, GuoDong and Su, Jian. Named entity recognition using an HMM-based chunk tagger. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics ACL 02. July 2002. pages 473-480.
[6] Vijay Krishnan and Christopher D. Manning.(july 2006) An Effective Two-StageModel for Exploiting Non-Local Dependencies in Named Entity Recognition. Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the ACL ACL 06
[7] Lars Buitinck and Maarten Marx. (2012). Two-stage named-entity recognition using averaged perceptrons system MUC-6 test results and analysis”, Proceedings of the MUC-6, NIST, Morgan-Kaufmann Publisher, Columbia, 1995
[8] Erik F. Tjong Kim Sang and Fien De Meulder. Introduction to the Conference on Natural Language Learning-2003 Shared Task:Language-Independent Named Entity Recognition. (2003)
[9] Peter F. Brown; Peter V. deSouza; Robert L. Mercer, Vincent J. Della Pietra, Jenifer C. Lai (1992). Class-based n-gram models of natural language. Computational Linguistics 18.
[10] Percy Liang. Semi-Supervised Learning for Natural Language. Massachusetts Institute of Technology. Dept. of Electrical Engineering and Computer Science Journal. 2005. pages 1-86.
[11] Professor Dan Jurafsky & Chris Manning. Sequence Models for Named Entity Recognition. Coursera Stanford NLP course. video 9.3. as view on November 2015.
[12] Professor Dan Jurafsky & Chris Manning. Maximum Entropy Sequence Models. Coursera Stanford NLP course. video 9.4. as view on November 2015.
[13] Mccallum, Andrew. Early Results for Named Entity Recognition with Conditional Random Fields, Feature Induction and Web-Enhanced Lexicons. Conference on Computational Natural Language Learning. 2003. pages 1-4.
[14] Alireza Nourian, Mohammad Sadegh Rasooli, Mohsen Imany, and Heshaam Faili. On the Importance of Ezafe Construction in Persian Parsing. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics
and the 7th International Joint Conference on Natural Language Processing (Short Papers).Association for Computational Linguistics. 2015. pages 877–882
[15] Wenhui Liao and Sriharsha Veeramachanen. A Simple Semi-supervised Algorithm For
Named Entity Recognition. Proceedings of the NAACL HLT Workshop on Semi-supervised Learning for Natural Language Processing.2009. pages 58–65
[16] Jenny Rose Finkel, Trond Grenager, and Christopher Manning. Incorporating Non-local Information into Information
Extraction Systems by Gibbs Sampling. Association for Computational Linguistics. 2005. pages 363-370.
[17] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean. Distributed Representations ofWords and Phrases
and their Compositionality. 2015.
[18] Richard Socher, Rohit Mundra. Deep Learning for NLP. Stanford CS 224D Deep Learning for NLP Course. 2015
[19] Jun’ichi Kazama, Kentaro Torisawa. ExploitingWikipedia as External Knowledge for Named Entity Recognition. Association for Computational Linguistics. 2007. pages 698–707.
Due to privacy and policy of both data sets, either data sets or either models cannot be uploaded. the code for web demo is available at github.
the Conference on Natural Language Learning
Message Understanding Conference
conditional random field
name entity
natural language processing
part of speech
maximum entropy
information retrieval
true positives
false positives
false negatives
Beginning-Inside-Outside
Long-Short Term Memories
Recursive Nerual Network
Knowledge Base