نویسهخوانی به عملیات تشخیص متن از داخل عکس گفته میشود. در این پروژه از شما انتظار میرود تا بتوانید عکسهایی از متون تایپ شده زبان فارسی، را به متن تبدیل نمایید.
۱. مقدمه
در این بخش برای توصیف پروژه و ایجاد درک صحیح از آن برای خواننده به پاسخ دادن به چند سوال میپردازیم.
۱.۱. نویسهخوان 1 چیست؟
به طور کلی به نرمافزاری که قابلیت تبدیل یک تصویر شامل نوشته به متن قابل پردازش را داشته باشد نویسهخوان میگویند.
۱.۲. چگونه به یک ماشین خواندن متن را بیاموزیم ، ارتباط نویسهخوانی و هوشمصنوعی؟
موضوع فراگیری نویسهخوانی در ماشین آغاز گر طرز فکر بسیار جالبی در باره دنیای کامپیوتر میباشد (یا حداقل برای شخص من بوده).
اگر یک تصویر از حرف فارسی " گ " را - فارغ از خوش خط یا بد خط بودن نویسنده - درمقابل ما بگیرند و از ما بخواهد که تشخیص دهیم که این حرف کدام یک از حروف مجموعه الفبای فارسی است ، پاسخ به این برای ما - انسان ها - بسیار آسان خواهد بود. اما اگر عبارت ۲۳۷۴ × ۷۴۵ را در مقابل ما قرار دهند و پاسخ آن را از ما بخواهند - با فرض اینکه یک نابغه ذاتی نیستیم - برای محاسبه آن احتمالا به زمان قابل توجهی و یک قلم و کاعذ نیاز خواهیم داشت.
حال فرض کنیم یک ماشین در مقابل همین ۲ پرسش قرار گیرد. محاسبه ۲۳۷۴ × ۷۴۵ برای یک ماشین یک سوال بسیار آسان است در حالی که برای یک انسان بسیار زمان بر است. و در عین حال فهمیدن و تشخیص حرف " گ " برای یک ماشین (موجودیتی که تنها صفر و یک میفهمد!) و تنها میتواند یک درک داده ای و سطح پایین از یک تصویر بر اساس رنگ ها و پیکسل هایش داشته باشد یک کار بسیار بسیار دشوار است!
تفاوت اصلی در نوع حل مساله در انسان ها و ماشین ها است. ماشین ها توانایی بسیار زیادی در محاسبه دارند اما انسان ها توانایی بسیار بالایی در یادگیری.
نکته دیگری که از این مقایسه قابل برداشت است این است که یک انسان در نهایت میتواند حاصل ۲۳۷۴ × ۷۴۵ را محاسبه کند اما آیا یک مایشن هم تنها با تکیه بر قابلیت های محاسبه ای خود میتواند یک نوشته را بخواند؟ جواب این سوال بله است، اما نه آن دست بله هایی که بتوانیم به تحقق آن امیدوار باشیم!
واقعیت این است نوشتن یک الگوریتم برای انجام عمل خواندن متن و تشخیص صحیح تک تک کاراکتر های آن، حداقل تا به امروز برای ما به عنوان برنامه ریز های ماشین ها امکان پذیر نبوده.
علاوه بر این موضوع ، باید توجه داشت که توانایی یاد گرفتن عامل اصلی برتری انسان بر ماشین - حداقل تا زمان معاصر - میباشد و همین موضوع ، یعنی قابلیت یادگیری انسان موجب شده که بتواند یک ضرب بسیار سخت را - شاید در زمان بیشتر - انجام دهد ُ اما یک کامپیوتر در یک زمان معقول نتواند به تنهایی یک حرف را تشخیص دهد.
و در نهایت بحث بهبود نتیجه نیز ارزش تفکر کردن را دارد ! انسان میتواند با تمرین و یادگیری زمان محاسبه ضرب را کاهش دهد و دقت خود را بالا ببرد اما یک ماشین ُ مانند ساختار صفر و یکی اش ، نهایتا یا میتواند یک حرف را در یک زمان عملی 2 تشخیص دهد یا نمیتواند !
نتیجه کلی مقایسه بالا این کلیّت را در بر دارد که برای حل برخی دسته ای از مسایل پیچیده از کامپیوتر باید به دنبال دسته ای کلی از الگوریتم ها باشیم که به کامپیوتر توانایی یادگیری آن مساله را ببخشد ، نه توانایی صرفا حل آنرا ، دقیقا مشابه مغز انسان.
این دسته از الگوریتم ها به الگوریتم های یادگیری ماشین معروف هستند.
۱.۳. کاربرد های نویسه خوان چیست ؟
نویسه خوان میتواند کاربرد های بسیاری داشته باشد ،
تصور کنید متن جالبی را در یک روزنامه مشاهده میکنید و میخواهید آنرا برای دوستتان بفرستید ، معمولا همه ما با عکس برداری از آن صفحه این کار را انجام میدهیم ، اما آیا بهتر نبود اگر میتوانستیم با تلفن هوشمند خود از آن عکس بگیریم و نرم افزاری متن آنرا تشخیص میداد و برای ما تولید میکرد ؟ قطعا در این صورت دست ما باز تر میبود.
یا فرض کنید مقدار زیادی کار تحقیقاتی و محاسبه در کاغذ انجام داده اید و میخواهید آنرا تبدیل به یک سند معتبر کنید ، قطعا ناچار هستید زمان زیادی را برای تایپ دوباره آن صرف کنید!
علاوه بر آن در زمینه های مهم تری نیز نویسه خوان کاربر دارد ، خواندن شماره پلاک خودرو ها در دوربین های کنترل سرعت ، امکان پردازش چک بانکی در دستگاه های خودپرداز ، یا تولید نسخه بک آپ از اسناد مهم کتابخانه ها و ادارات به صورت دیجیتال ، همه میتوانند کاربرد های بسیار مهم یک نویسه خوان دقیق باشند.
امروزه در بسیاری از ادارات و سازمان های دولتی ، افراد زیادی ساعت های زیادی را به وارد کردن اطلاعات فرم هایی که با دست پر شدهاند به کامپیوتر صرف میکنند و با در اختیار داشتن یک نرم افزار نویسهخوان میتوان در زمان و نیروی انسانی بسیاری صرفهجویی نمود.
۱.۴. مقایسه نویسه خوان در زبان فارسی با دیگر زبان ها
این واقعیت بسیار سخت وجود دارد که فرآیند ایجاد یک سیستم هوشمند برای تشخیص زبان فارسی بسیار دشوار تر از زبانی مثل انگلیسی میباشد ( باید با این موضوع کنار بیاییم!). این سختی فقط مختصّ زبان فارسی نیست، تمام زبان های سرهم نوشته شده 3 درجه سختی بسیار بیشتری نسبت به زبان هایی که خطوط آنها گسسته و جدا از هم است دارند.
دلیل این سختی مضاعف در قسمت های بعدی به طور کامل تر شرح داده خواهد شد، اما با یک نگاه ساده هم میتوان تصور کرد یک ماشین برای فهم حرف ' ه ' فارسی نیاز به یادگیری چندین شکل مختلف ان (ابتدا ، میانه و انتها) دارد، علاوه بر آن با مشاهده یک کلمه انگلیسی، فرآیند قطعه قطعه سازی 4 که دلیل بسیاری از اشتباهات در سیستم های نویسهخوان است، در آن آسان تر صورت میگیرد آما در یک کلمه فارسی جایگاه هر حرف و تشخیص آن خود یک مساله بسیار پیچیده است.
۱.۵. ابزار های موجود متن باز
موتور Tesseract
موتور نویسهخوان Tessearct اولین نویسهخوان موجود در دنیای متن باز بوده. هم اکنون هم تمام کد مرجع آن در مخزن گیتهاب قابل مشاهده است. توسعه آن از دهه ۸۰ میلادی آغاز شده و تا امروز نیز ادامه داشته است. این موتور قابلیت یادگیری بیش از ۴۰ زبان دنیا از جمله عربی را دارد و علاوه بر آن هسته اصلی بسیاری از ابزار های وابسته نیز ماشد.موتور OCRopy
این موتور جدید تر از Tesseract میباشد و نحوه پیاده سازی آن نیز کمتر از Tesseract وابسته به زبان است. علاوه بر آن ساختار آن نیز تنها وابسته به تصویر یک نوشته نیست و در پیاده سازی آن از علاوه بر تحلیل شکل کلمه، به بررسی لغوی آن نیز پرداخته میشود.
OCRopus is an OCR system that combines pluggable layout analysis، pluggable character recognition، and pluggable language modeling. It aims primarily for high-volume document conversion، namely for Google Book Search، but also for desktop and office use or for vision impaired people.
با رجوع به صفحات ویکی این پروژه در مخزن گیتهاب در مییابیم که بخش تشخصی حرف ها 5 در این موتور بر پایه موتور Tesseract نوشته شده است و مدل زبان و تحلیلگر قالب دو بُعد جدید پردازش در این موتور میباشند که موجب بهبود نتایج آن برای داده های نامنظم تر و زبان های سرهم شده است.
توضیحات بیشتر در باره بازخورد ها و بازدهی این موتور های چند زبانه برای زبان فارسی در بخش های بعدی گفته خواهد شد.
۱.۶. ابزار های فارسی
با جستوجوی صفحات وب، میتوان بلافاصله دریافت که نویسه خوانی به زبان فارسی از نظر پیشرفت، فاصله زیادی با معادل های خود در زبان های دیگر دارد.
واضح است که این فرآیند برای تنها تشخیص اعداد و حروف یکه فارسی در سامانه دوربین های کنترل ترافیک با موفقیت پیاده سازی شده است اما فقدان یک ابزار متن باز برای گسترش استفاده های نویسهخوان در ابعاد مختلف احساس میشود.
همچنین ابزار های فارسی نویسه خوان با استفاده محدود و به صورت تجاری در حال حاضر وجود دارند اما علاوه بر گرانی بسیار با رجوع به صفحات وب و نوشته های درج شده در توصیف نتایح کاربران این محصولات نمیتوان از صحت و جامعیت کاربرد های این محصولات اطمینان کامل داشت. برای مثال میتوان به مقاله سایت یک پزشک در باره نویسه خوان فارسی آراکس شاره کرد.
یکی از ابزار های فارسی نویسهخوانی که نمیتوان از اشاره کردن به آن چشم پوشی نمود نیز رابط فارسی یادگیری موتور Tesseract میباشد که به عنوان یک پروژه متن باز در گیتهاب موجود است و در یک بازه زمانی کوتاه در آن تلاش شد که با ایجاد یک محیط مخصوص زبان فارسی، به موتور Tesseract آموزش داده شود. با وجود گذشتن مدت زیاد از پایان توسعه این پروژه کماکان میتوان از آن به عنوان جدی ترین تلاش ایجاد نویسهخوان فارسی متنباز نام برد.
۲. کارهای مرتبط
میخواهیم به بررسی روش های مختلف ایجاد یک نویسه خوان بپردازیم و نتایج ثبت شده در مقالات را مقایسه کنیم. در این قسمت در تمامی مراجع ارجاعی اولویّت با مقالاتی که برای نویسهخوان های مستقل از زبان نگارش شده اند.
۲.۱. نویسه خوانی بر پایه تشخیص مسیر 6
موتور Tesseract یک نمونه از موتور هایی میباشد که بر این اساس ایجاد شده. در این رویه تاکید اصلی سیستم بر قطعه قطعه سازی نوشته و تشخیص کاراکترها بر اساس شکل آنها میباشد. این روش نیازمند آن است که رویه قطعه قطعه سازی برای هر زبان جدید صورت گیرد. علاوه بر این همانطور که در بخش مقدمه گفته شد غلبه بر چالش هاش زبان های سرهم نیز مانع بزرگی به شمار می آیند. (با ذکر این نکته که این مشکل تنها در زبان های فارسی ، عربی یا هندی که ساختار به هم پیوسته دارند رخ نمی دهد، در بسیاری از زبان ها مانند انگلیسی هم بسیاری از افراد کلمات خاصی را به صورا به هم پیوسته مینویسند. یا در بسیاری از اسناد چاپی به مرور زمان به دلیل پخش شدن جوهر در کاغذ کلمات به هم متصل میشوند و قطعه قطعه سازی آنها سخت تر میشود)
در یک نگاه اولیه میتوان به این موضوع فکر کرد که شاید بتوان با قدرت بخشیدن به الگوریتم های قطعه قطعه سازی میتوان بر این مشکل غلبه کرد اما به دلیل محدود بودن توان ما در این زمینه (این واقعیت که عملا نمیتوان این فرایند را به صورت ایده آل انجام داد) زمان یادگیری سیستم بسیار بالا میرود و در حالت بدتر شاید سیستم هرگز به درستی آموزش داده نشود. در نتیجه طبیعتا به این فکر میکنیم اگر راهکاری متفاوت با وابستگی کمتر به قطعه قطعه سازی نوشته و زبان در دسترس است، آنرا نیز بررسی کنیم. این کار در بخش بعدی صورت میگیرد.

۲.۲. یک روش بهتر : شبیه سازی نویسهخوان مشابه سیستم تشخیص گفتار 7
ایده اولیه این رویه از سیستم های تشخیص گفتار ناشی میشود. در یک سیستم تشخیص گفتار، برنامه باید بتواند صدای گوینده را دریافت کند و متنی که وی گفته را تولید کند. با وجود ظاهر متفاوت، میتوان نشان داد که این دو مساله در ظاهر بسیار شبیه به هم هستند [1].
در یک سیستم تشخیص صدا، یک سیگنال صوتی وابسته به زمان (نمودار آن شامل دو بردارد شدت صوت و زمان است) ورودی سیستم است [5]. موضوع اصلی و مورد علاقه ما رابطه وابستگی زمانی بین سیگنال های ورودی سیستم میباشد (به طور دقیق تر وابستگی هر ورودی به ورودی قبل). با فرض اینکه مدل کامل فرکانس های آوا ها را در اختیار داریم (از نقطه نظر نویسه خوان به آن مدل کلمه گفته میشود - در بخش توضیخات مدل مارکوف توضیخات بیشتری در این زمینه ذکر شده است) برای دریافت کلمه " سلام " ابتدای آوای " س " را پردازش میکنیم و سپس همین آوا به تدریح به " سَ " تبدیل میشود، سپس " ل " در ادامه آن تشخیص داده میشود و... علاوه بر ترتیب ، برآیند نهایی این آوا ها در کنار هم سیستم را به سمت جواب میبرد.
دقت به این روند باعث میشود دریبایم که در تشخیص صدا ، روند پردازش کاملا متفاوت از روش قبلی توضیح داده شده میباشد و ورودی ها در قالب یک دنباله در سیستم مورد پردازش قرار میگیرند ، و این دقیقا اتفاقیست که اگر بتوانیم آنرا در نویسه خوان مدل کنیم، مشکل قطعه قطعه سازی دیگر بر سر راه ما نخواهد بود.
میتوان سیستمی را در نظر گرفت که در آن ورودی به جای یک سیگنال صوتی یک بردارد از خصوصیت های مستقل از زبان وابسته به یک قاب از یک خط از نوشته باشد. در مورد این بردار از خصوصیت های مستقل از زبان در بخش های بعد توضیحاتی ارایه خواهد شد.

با دانستن این اطلاعات نیاز به یک مدل ایده آل برای نمایش و انجام پردازش بر روی یک دنباله تصادفی از رویداد ها (ورودی ها) داریم. بدین منظور در بخش بعدی مدلی به نام مدل پنهان مارکوف 8 را معرفی میکنیم.
۲.۳. مدل پنهان مارکوف
حال که فهمیدیم یک راه حل مناسب برای رهایی از مشکلات عدیده نویسه خوان های بر پایه مسیر ، شبیه سازی آن با مدل های پیوسته ای است که در سیستم های تشخیص گفتار به کار میروند، باید توضیحات بیشتری در مورد نحوه کار آنها به دست آوریم.
مدل های مارکوف برای شبیه سازی اتفاقات تصادفی به کار میروند. با این شرط که سیستم داری نوعی خاصیت بی حافظگی باشد و در هر لحظه وضعیت سیستم تنها به وضعیت اکنون سیستم بستگی دارد و نه وضعیت های قبلی. میتوان در قالب نظریه احتمال این مساله را اینگونه بیان کرد که احتمال هر رخداد در زمان t+1 تنها به احتمال رخداد آن در زمان t وابسطه است و از احتمال های زمان 0 تا t-1 مستقل است.
به این ساده سازی فرض مارکوف 9 نیز گفته میشود.
زمانی که در یک سیستم احتمال رخداد یک پدیده در آینده را تنها به زمان حال ( یک واحد زمانی قبل ) وابسطه بدانیم به آن مدل مارکوف مرتبه یک گفته میشود، اگر پدیده ای را به n حالت قبل وابسته در نظر بگیریم به آن مدل مارکوف مرتبه n گفته میشود.
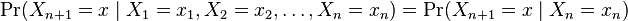
با در نظر گرفتن این ساده سازی میتوان هر دنباله از پدیده ها را به صورت یک گراف از احتمال های تغییر حالت بین وضعیت های سیستم نمایش داد که به آن نمایش گرافی یک مدل مارکوف میگویند.

توضیحات بسیاری در باره مدل های مارکوف میتوان بیانکرد، در این بخش ما تنها در آن حدی از آن که مربوط به این پروژه میشود را توضیح میدهیم.
۲.۴. جزییات و مثالی از مدل پنهان مارکوف
برای فهم مدل های مارکوف به صورت کامل ، این موضوع را با مثال مطرح میکنیم:
فرض کنید که در شهری خاص قرار داریم و در میانه هر روز وضعیت آب و هوا را مشاهده میکنیم و برا اساس آن یه وضعیت 10 را به این روز نسبت میدهیم.
فرض میکنیم که وضعیت های آب و هوایی به صورت زیر مشخص میشوند :
همچنین فرض کنید ماتریسی در اختیار داریم که در آن احتمال رفتن از یک حالت به حالت های دیگر مشخص شدهاست :
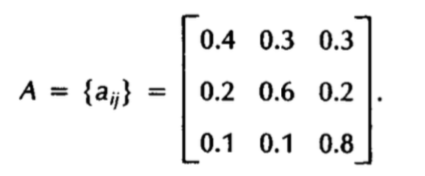
این ماتریس از مولفه های اصلی این مدل میباشد که به آن ماتریس تغییر حالت 11 گفته میشود. توجه شود که این یک ماتریس توزیع احتمال است و جمع هر سطر و ستون آن باید ۱ باشد.
همچین وضعیت سیستم در زمان t را نیز با
نمایش میدهیم.
به مجموعه اطلاعات ماتریس تغییر حالت و حالت کنونی یک مدل گفته میشود که آن را با \lambda نمایش میدهیم ، برای تشریح بهتر کارکرد این مدل میخواهیم به پاسخ پرسش زیر بپردازیم :
چه احتمالی وجود دارد که با دانستن یک مدل
\lambda = { A ، q_0 }
وضعیت های آینده به شرح زیر باشند:
O = { S_1 , S_1 , S_1 , S_2 , S_3 , S_2 , S_1 }
به دنباله نشان داده شده با O دنباله مشاهدات 12 گفته میشود.
این مساله را در قالب ریاضی زیر میتوان شرح داد :
P( O | \lambda ) = \pi_{1} + a_{11} + a_{11} + a_{12} + a_{23} + a_{32} + a_{21}
نماد \pi به معنی وضعیت آغازین سیستم است و آنرا به صورا زیر تعریف میکنیم:
\pi_{i} = P(q_1 = S_i)
به طور مشابه میتوان به پرسش های جالب دیگری هم با استفاده از همین مدل پاسخ داد:چه احتمالی وجود دارد که برای d روز پیاپی در یک وضعیت باقی بمانیم؟
چه احتمالی وجود دارد پس پس از یک روز آفتابی ، ۳ روز پیاپی باران ببارد؟
چه احتمالی وجود دارد پس برای یک هفته بارش برف نداشته باشیم؟
ذکر این نکته مهم است که در انتخاب تعداد حالات این مدل مارکوف ، حداقل حالات یا ساده ترین شکل ممکن در نظر گرفته شده است. برای مثال در صورتی که این دانش را داشته باشیم که احتمال بارش باران پس از یک روز بارانی دیگر متفاوت از دیگر احتمال بارش باران پس از یک روز آفتابی است ( توجه کنید که در مدل های مارکوف مرتبه n وابستگی به n وضعیت قبلی مجاز است و در نظر گرفته میشود) واضح است که تعداد حالت های مدل و ابعاد ماتریس تغییر حالت بیشتر خواهد شد.
برای تشریح کامل مدل پنهان مارکوف لازم است که اجزای 13 آنرا بشناسیم.
تعداد حالت ها که با N نمایش داده میشود.
تعداد حالت های مشاهدات در هر وضعیت که دریافت میشود ( در مثال قبل ۳ حالت مشاهده در هر وضعیت داشتیم - برفی ، بارانی و آفتابی ). تعداد این مشاهدات با M و دنباله آن با V = { v_1 , v_2 , ... , V_M } نمایش داده میشود. توجه شود که این دنباله لزوما با تعداد حالات برابر نیست و در این مثال به دلیل توضیح داده شده در بخش قبلی (یک حالت به ازای هر وضعیت آب و هوایی) تعداد ها یکسان میباشد.
ماتریس احتمال تغییر حالت که با نماد A , a_{i} نمایش داده میشود. هر عضو در سطر i و ستون j به معنی احتمال رفتن از وضعیت i به وضعیت j میباشد.
احتمال مشاهدات متفاوت در هر ورودی. احتمال اینکه در وضعیت i مشاهده k ام جزو مشاهدات دریافتی باشد با نماد زیر نمایش داده میشود:
B = b_i(k) = P( v_k | q_t = s_i )وضعیت اولیه سیستم که در طی مثال نیز توضیح داده شد. احتمال اینکه سیستم با وضعیت i آغاز گردد به صورت زیر نمایش داده میشود:
\pi_{i} = P(q_1 = S_i)
با داشتن این اطلاعات اولیه به بررسی سه چالش اصلی در یک مدل مارکوف میپردازیم :
به در اختیار داشتن یک مدل \lambda = ( A , B , \pi ) ُ با مشاهده یک ورودی خاص O = { o_1 , o_2 , .. , 0_m} چگونه به صورت بهینه احتمال رخداد این ورودی با فرض این مدل را محاسبه کنیم؟
P ( O | \lambda ) = ?با فرض یک دنباله ورودی O = { o_1 , o_2 , .. , 0_m} و یک مدل \lambda چگونه یک دنبال از وضعیت ها را ( Q = { q_1 , 1_2 , .. } ) انتخاب بکنیم که به بهترین نحو ورودی سیستم رو توجیه کنند.
چگونه یک مدل با پارامتر های فوق را تشکیل دهیم.
قبل از فکر کردن و درگیر کردن ذهن با روش های حل هریک از چالش فوق ُ لازم است که برای واضح شدن اهمیّت آنها، ربط هریک از مراحل با رویه تشخیص یک نوشته در این پروژه را توضیح دهیم [6]:
به مثال اصلی که ایده دهنده اصلی ما به مدل های پنهان مارکوف بود بازمیگردیم. یک سیستم تشخیص گفتار:
فرض کنید که به ازای هر کلمه w در الفبای سیستم W یک مدل با N وضعیت تشکیل دهیم. سیگنال های ورودی سیستم به صورت بردار های فرکانسی برچسب گذاری شده بر اساس زمان نشان داده میشوند.
اولین قدم ایجاد مدل کلمات ُو پیش بینی اولیه پارامترهای آن است. این کار دقیقا برابر با چالش ۳ میباشد.
در مرحله بعد لازم است که به وسیله یک مجموعه اطلاعات صحیح اولیه برای آموزش سیستم، وضعیت های مدل را تغییر دهیم و پرامتر های آن را بهبود بخشیم. این بخش باعث میشود که در میان وضعیت های یک مدل (که خود نشان دهنده یک کلمه است) دنباله صحیح وضعیت را پیدا کنیم. شاید لازم باشد یک بار دیگر تکرار بکنیم که تا این مرحله به چه چیزی رسیده ایم:
ما برای هریک از کلمات ورودی سیستم یک مدل با تعداد حالات مشابه در نظر گرفتیم. هر یک از این مدلها (که در واقع قبل از آموزش دیدن و اجرای این مرحله کاملا مشابه هم هستند) در یک وضعیت آغازین قرار دارند و با مشاهده دنباله ای از بردار های ورودی به وضعیت های متقاوت میروند. پس لازم است که هر مدل برای شناسایی یک کلمه آموزش دیدهشود یا به عبارت دیگر، با مشاهده دنباله حالتهایی که مدل به آن به ازای یک ورودی خاص میرود، پارامترهایش را به گونه ای تغییر دهد که برای حالت های نزدیک به این ورودی نیز بتواند آنرا تشخیص دهد. این کار با تکرار مکرر چالش ۲ انجام میگیرد. سیستم با مشاهده یک ورودی آموزشی دنباله وضعیت هایی را که با این ورودی بیشترین همخوانی را دارند (این ورودی را توجیه میکنند) تشخیص داده و خود را با توجه به آن اصلاح میکند. این مرحله شامل رویه استخراج ویژگی ها 14 که یکی از همه ترین بخش های این پروژه می باشد نیز میباشد که در فاز پیاده سازی با جزییات بیشتر در مورد آن توضیحاتی داده خواهد شد.
و در نهایت، هدف نهایی ما: اینکه پس از آموزش دیدن یک مدل توسط ورودی های اولیه، با مشاهده یک ورودی بتوانیم احتمال وجود این ورودی در یک مدل را بدست آوریم و نهایتا تشخیص دهیم که کدامیک از مدل ها بیشترین شانس را برای توجیه این ورودی دارد. این کار در چالش ۱ انجام میگیرد.
بدست آورد روشی بهنیه برای رفع هریک از این چالش ها روش های مخصوصی دارد [6] که در بخش پیاده سازی بیشتر در مورد آنها بحث خواهد شد.
۲.۵. ساختار یک نویسه خوان بر اساس مدل پنهان مارکوف
حال که بسیاری از فواید مدل های مارکوف، استفاده از آنها در سیستم های تشخیص گفتار و ربط آن با سیستم نویسه خوان را بررسی کردیم، میتوانیم به بررسی ساختار یک نویسه خوان بر پایه نظریات مطرح شده برسیم.
در این بخش چکیده ای از معماری یک نویسه خوان با الگو از سیستم تشخیص گفتار بیان میگردد. قبل از آغاز کار لازم به ذکر است که با توجه به گستردگی چالش های رَویه تشخیص یک نوشته در عکس، این پروژه تنها به بُعد تشخیص میپردازد و توضیخات این بخش و پیاده سازی نیز مربوط به همین بُعد خواهدبود.
برای درک بهتر این موضوع خط لوله اصلی رویه تبدیل یک نوشته به متن را میتوان در شکل زیر مشاهده کرد.

یکپارچه سازی [^Binarization]: شامل تبدیل عکس رنگی به یک تصویر کاملا سیاه و سفید به منظور افزایش درک سیستم از هر پیکسل در عکس.
قطعه قطعه سازی:مطالب بسیاری در باره حذف این بخش در سیستم نویسهخوانی که آنرا در این مقاله شرح دادیم مطرح شد، اما نهایتا نباید فراموش کنیم که بخش تشخیص یک خط در متن کماکان یک چالش - قابل حل - در مسیر ما میباشد.
تشخیص: بخش اصلی که سیستم بر اساس آن بتواند متن نهایی را تولید کند.
۲.۵.۱. دیاگرام نویسه خوان نهایی
بدون مقدمه بیشتر، ابتدا سیستم نهایی را مشاهده میکنیم و سپس اجزای آنرا بررسی میکنیم:

به طور خلاصه میتوان در شکل مشاهده کرد که سیستم به دو بخش اصلی آموزش و تشخیص تفکیک شدهاست. هسته اصلی سیستم آموزش (مدل سازی کاراکتر ها15) ابتدا توسط داده های آموزشی، پس از استخراج ویژگی ها، به بهبود پارامتر ها میپردازد. (در مثال بخش قبل برای فهم بهتر و سادگی از یک کلمه به عنوان پایه مدل ها نام برده شد، در حالی که واضح است در این صورت میبایست بیشمار مدل برای کلمات ممکن داشت!)
همانطور که در بخش قبل به شباهت مدل ها قبل از آموزش دیدن اشاره شد، در این بخش هم این نکته قابل ذکر است که تجربه نشان داده متفاوت گرفتن تعداد حالات برای مدل های کاراکتر های مخالف (مثلا کارکتر هایی که به نظر پیچیدگی بیشتری دارند تعداد حالات بیشتری داشته باشند) عملا کارایی چندانی در بهبود عملکرد نهایی سیستم نخواهد داشت [4].
علاوه بر مدل هایی که از ویژگی های ظاهری حروف استخراج میگردند، میتوان در یک سطح بالاتر ( سطح کلمات ) از مدل های زبانی نیز برای بهبود و تایید نتایج استفاده کرد. ( البته میتوان از مدل های زبانی در سطح حروف نیز استفاده کرد اما انباشتگی بسیار زیاد اطلاعات آن عملا باعث ناکارامدی میشود) ساختار این مدل های زبانی بسیار مشابه کاری که نویسهخوان در سطح حروف انجام میدهد است، تنها با این تفاوت که در سطح کلمات و ترتیب قرار گیری آنها در پی یکدیگر، احتمال صحت یک دنباله بررسی میشود. ( از بررسی جزییات کارکرد این بخش به دلیل عدم ارتباط با پروژه اصلی پرهیز میشود)
تا این مرحله از توضیحات چندین بار از واژه استخراج ویژگی نام برده شد و حال که به بُعد پیاده سازی نزدیک هستیم بهترین فرصت میباشد که کمی بیشتر در مورد آنها توضیح دهیم.
در بخش قبل به چالشی اشاره کردیم که در طی آن باید راهی برای بهبود پارمتر های مدل خود پیدا میکردیم. مشخصاً این کار امکان پذیر نیست مگر آنکه راهی برای تبدیل یک مشاهد سیستم به یک مجموعه از پارامتر های قابل فهم برای سیستم، داشته باشیم. این پارامتر های قابل فهم همان ویژگی های یک قاب از ورودی (که معادل یک مشاهده - V_i - میباشد) است. برای مثال میتوان در هر قاب ویژگی های زیر را استخراج کرد:
میزان غلظت پیکسل های سیاه و سفید
مشتق طولی از بردار غلظت
مشتق عرضی از بردار غلظت
پس هر بردارد از ویژگی ها نهایتا بیانگر یک مشاهده خواهد بود و حال میتوان متوجه شد که به چه دلیل هم در بخش آموزش و هم در بخش تشخیص سیستم نتیجه بخش استخراج ویژگی ها به پردازشگر اصلی منتقل میکند.
بحث در مورد اینکه کدام ویژگی ها برای دریافت بهترین نتایج مناسب تر هستند میتواند یکی از کار های اصلی بخش پیاده سازی باشد. ( ویژگی های فوق در مراجع [1] به عوان یک سری از ویژگی های لازم و حداقل مطرح شدهاند)
برای جمع بندی نهایی معماری کلی نویسهخوان، یک بار دیگر مراحل اصلی عکس فوق را با مقدمات ریاضی مطرح شده در بخش قبل از مدل های مارکوف تطابق میدهیم:
سیستم ابتدا بر اساس پردازش تصویری از قاب های پیاپی از ورودی و استخراج ویژگی های آنها یک دنباله از ورودی های آموزشی V_i را مهیا میکند. بخش ایجاد کننده مدل های کاراکترها (چالش ۳) برای هر کاراکتر یک مدل خام ایجاد کرده و با مشاهده ورودی های مخالف با طرز نوشتن های متفاوت و .. شروع به بهبود پارامتر مدل برای تشخیص بهتر این کاراکتر میکند.
و در نهایت سیستم در زمان تشخیص و آزمایش نهایی بار دیگر دنباله مشاهدات ورودی را با همان روشی که بر طبق آن آموزش دیده است تبدیل به یک بردار ویژگی میکند و با مقایسه میزان شباهت آن با مدل های مختلف متن نهایی را تولید میکند.
۲.۵.۲. آیا نتیجه بهتری میگیریم ؟
پس از بیان تمام این مقدمات باید با هم یکبار دیگر چند پرسش بسیار ساده تر را پاسخ دهیم:
چرا نویسه خوانخود را بر اساس مقدمات فوق پیاده سازی کنیم؟ آیا روش بهتری وجود ندارد؟ اصلا چرا از صفر اینکار را انجام میدهیم ؟ ایا شانسی برای یادگیری ابزار های موجود متن باز حال حاضر برای زبان فارسی وجود ندارد؟
با جستجویی در وب میتوانیم بسیاری از روش های دیگر برای پیاده سازی نویسه خوان را پیدا کنیم:
پیاده سازی بر اساس الگوریتم های تطابق مسیر( روشی که ترکیب آن با شبکه عصبی پایه Tesseract است ) 16
پیاده سازی با ابزارهای متلب
پیاده سازی بر اساس شبکه های عصبی ( روشی که Ocropy بر پایه آن نوشته شده - لینک )
همان طور که در بخش های اولیه توضیح داده شد، هریک از روش های زیر به دلایل متفاوت (که اصلی ترین آنها وابستگی زیاد به تشخیص حروف در زبان هایی با نوشتار گسسته است) راه حل مناسب و امید بخشی به حساب نمیآیند، در حالی که روش ارایه شده بر پایه تشخیص گفتار- حداقل در ظاهر و بر پایه مقالات نگارش شده در این زمینه- بسیار امیدوار کننده تر میباشد و در در مقالاتی که نتایج برخی آزمایش هایشان را منتشر کردهاند، مشاهده میکنیم که برای زبان عربی (که در یک مرتبه مشابه سختی با زبان فارسی قرار دارد ) به ضریب خطای کمتر از ۱٪ هم بدست آمده است [1] .
۳. آزمایش ها
پس از یافتن یک دیدگاه اولیه از تئوری های استفاده شده برای پیاده سازی حال میتوانیم آمایش هایی بر اساس همین روش ها را پیاده سازی و نتایج آن را بررسی کنیم ( لینک مخزن گیتهاب پروژه ).
۳.۱. آماده سازی سیستم پیاده سازی
به منظور در دست داشتن یک ابزار قابل اعتماد از نظر کیفیت و سرعت در پیاده سازی مدل های مارکوف، از کتابخانه Hidden Markof Toolkit - HTK Speech Recognition System استفاده میکنیم. همانطور که در توضیحات قبل اشاره شد سیستم برای یادگیری مراحلی مشابه با تشخیص گفتار را طی میکند.
تمام مراحل ذکر شده در قست های بعدی در واقع مراحل یادگیری و آزمایش ذکر شده در کتاب مرجع HTK میباشند. با این تفاوت که ما سعی کردهایم که در آن به جای داده های صوتی و بررسی آنها در قالب آوا ها، فایل های تصویری را به عنوان ورودی سیستم در نظر بگیریم و حروف آنرا برسی کنیم [7] .
به منظور تمرکز بر ارایه نتایج از پرداختن توضیحات جزیی در باره دستورات کتابخانه HTK در این پژوهش نامه پرهیز شدهاست و تنها به نام چندی از دستورات پر کاربرد بسنده کردیم. توضیحات کامل در این مورد درکتاب مرجع HTK ذکر شدهاست و مطالعه آنرا بر عهده خواننده میگذاریم.
مراحل انجام هریک از آزمایش ها به شرح ذیل است:
آماده سازی داده های آزمایش
برای به دست آوردن حجم بسیار زیادی از داده های متقارن تصویری به همراه متن های صحیح مربوط به هریک از قابلیت های برچسب17 Canvas در HTML5 استفاده میکنیم. به این طریق میتوانیم هر تعداد فایل متنی موجود را به نوشته فارسی در قالب عکس (با اندازه و قلم های متفاوت ) تبدیل و ذخیره کنیم. در طی آزمایش های اولیه بیشتر تصاویر تولید شده شامل اسم های فارسی ایجاد شده توسط کتابخانه های Faker یا متن های جمع آوری شده از سرتیتر های سایت های خبری میباشد.
تبدیل تصاویر به فرمت های مجاز
در مرحله قبل به منظور سهولت و سرعت در تولید تصاویر آنها را با فرمت PNG ایجاد مینماییم. اما برای پردازش ساده تر در مراحل استخراج ویژگی ها باید آنها را به ساختاری انتقال دهیم که به صورت خودکار قابل پردازش باشند. بدین منظور از کتابخانه Netpbm (که یکی از قدیمی ترین ابزار های پردازش تصویر در محیط های یونیکس است) استفاده میکنیم. Netpbm ساختاری یکپارچه و انعطاف پذیر (و در عین حال بسیار سبک و کم حجم) برای نمایش و پردازش تصاویر ایجاد میکند. به صورت کلی این کتابخانه ۳ فرمت اصلی برای تصویر دارد : Portable Bitmap - Portable Graymap - Portable Pixmap
ما در طی اینازمایش تمام تصاویر را به نوع اول یعنی PBM تبدیل میکنیم. این فرمت تنها به نگه داشتن اطلاعات دودویی از تصویر بسنده میکند و با توجه به اینکه در مراحل بعدی نیز تنها تصاویر سیاه و سفید را مورد پردازش قرار میدهیم استفاده از این فرمت بسیار بهینه تر میباشد.

استخراج ویژگی ها
دستورات زیر برای استخراج ویژگی ها به ترتیب استفاده میشوند. همانطور که اشاره شد این مراحل کاملا بر پایه Netpbm صورت میگیرد و دلیل اصلی سازگار کردن تصاویر با این کتابخانه سهولت این مرحله بود.pnmdepth 255 $f | # Change to grey Level pgmmedian | # Smooth the image pgmslope| # Perform "Slope" correction pgmslant -M M | # Perform "Slant" correction using Std. Desv. pgmnormsize -c 5 | # Perform size normalization pgmtextfea -c $DIM > /tmp/tmp.fea # Compute feature extraction pfl2htk /tmp/tmp.fea $DDEST/${d/pbm/fea} # Convert to HTK format
در دستورات فوق متغییر $f تعداد پنجره های استفاده شده برای استخراج ویژگی های هر عکس میباشد. (در آزمایش های ما این مقدار ۲۰ قرار داده شده)

ایجاد مدل اولیه 18 حروف
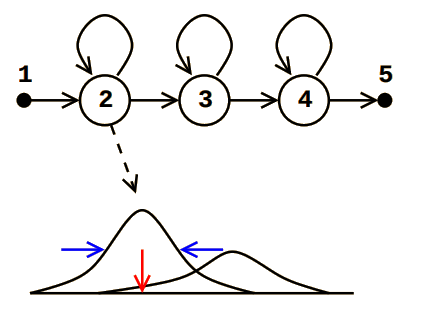
همانگونه که در توضیحات بخش قبل ذکر شد در ابتدای فرآیند برای هر کاراکتر یک مدل یکسان ایجاد میشود که در فاز یادگیری به تدریج مدل ها از یکدیگر تمایز پیدا میکنند و هریک نشانگر یک حرف خاص خواهد بود. در این بخش تعریف مدل بر اساس ساختار استاندارد شده در کتابخانه HTK صورت میگیرد که در آن به هر حرف یک مدل سمت راستی 19 تخصیص میشود که در آن ۸ وضعیت یکسان تعریف شده که احتمال انتقال از هر وضعیت به وضعیت بعدی .۴ و وضعیت اکنون .۶ در نظر گرفته میشود. این مدل به صورت یک فایل متنی ذخیره میشود.
علاوه بر آن با پردازش همه جمله های تعریف شده به عنوان داده یادگیری یک فایل از لیست تمام حروف قابل تشخیص سیستم ایجاد میشود.
انجام این مرحله پیاده سازی چالش ۱ توضیح داده شده در بخش مقدمه میباشد.
ایجاد لیست های یادگیری
به منظور خودکار کردن رویه یادگیری لیستی از تصاویر پردازش شده در قالب ویژگی ها ایجاد میکنیم و عمل یادگیری را روی تمام عناصر این لیست انجام میدهیم. در آزمایش های ما این لیست شامل کل داده های ورودی میباشد. علاوه بر آن برای آزمایش نتایج ۱۰ لیست ۱۰۰ تایی به صورت تصادفی از میان داده های ورودی انتخاب شده و عمل تشخیص 20 روی آنها صورت میگیرد و میانگین نهایی آنها مورد بحث قرار داده میشود. این روش به منظور حذف ضریب تصادفی بودن نتیجه در آزمایش و اطمینان از صحیح بودن ضریب خطای نهایی میباشد.
ایجاد فایل های مرجع برای یادگیری و تشخیص
فایل مرجع یادگیری ایجاد شده به منظور داشتن یک منبع صحیح از حروف به کار رفته در هر کلمه است. در همه بخش های بعدی این فایل ها به عنوان یک داده صحیح از کلمه نوشته شده در یک عکس ( چه در زمان یادگیری و چه در زمان تشخیص) استفاده میکنیم. شایان ذکر است که مانند مرحله تعریف مدل های مارکوف برای کلمه، در این محله نیز ساختار فایل های ایجاد شده مطابق کتابخانه HTK میباشد.
تنها تفاوت اصلی در فایل مرجع آموزش و فایل مرجع تشخیص این است که در فایل استفاده شده در بخش آموزش جمله ها تا مرز حروف تجزیه شدهاند و در بخش تشخیص جملات تا مرز یک کلمه تجزیه میشود.
sample.mlf # فایل مرجع یادگیری
\*/train_122.lab
پ
ر
س
ت
و
@
م
ط
ه
ر
ی
.
SampleRef.mlf # فایل مرجع تشخیص
پرستو
مطهری
.
مطابق قرارداد های HTK حرف . به عنوان نشانه پایان یک جمله و حرف @ به عنوان یک آوای خالی ( سکوت ) شناخته میشود که در آزمایش های ما از آن برای نشان دادن یک فاصله 21 استفاده میشود.
یادگیری
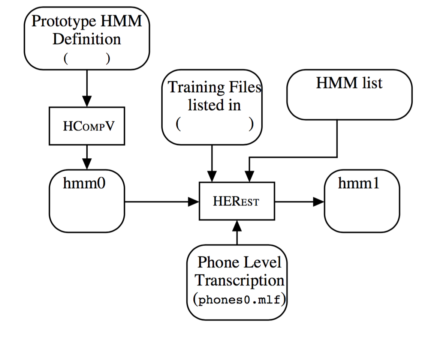
پارامتر های اصلی یادگیری اولیه
در بخش یادگیری سه پارامتر اصلی به عنوان ورودی در نظر گرفته میشود.مدل خام حروف
لیست یادگیری
لیست حروف موجود
هر یک از جمله های موجود در لیست یادگیری به همراه متن متناسب با آن به ترتیب مشاهده شده و مدل حروف تک تک کلمات مشاهده شده در متن ورودی به تدریج به روزرسانی میشود.
انجام این مرحله پیاده سازی چالش ۲ توضیح داده شده در بخش مقدمه میباشد.
ایجاد مدل های زبانی
همانطور که در بلوک دیاگرام سیستم کلی اشاره شد، به منطور ایجاد نتایج بهتر از یک مدل زبانی وسیع به عنوان یکی از ورودی های بخش تشخیص استفاده میشود. در برخی آزمایش های انجام شده با توجه به نوع داده ورودی استفاده شده سعی شده که کامل ترین نوع مدل زبانی موجود مورد استفاده قرار گیرد.
مثلا در آزمایش های صورت گرفته بر روی جمله های خبری هر جمله ای که یک یا چند کلمه از آن به عنوان یک تصویر یادگیری برگزیده میشود، به صورت کامل در فایل مدل زبانی ذخیره میگردد.
نتیجه نهایی این مدل زبانی دو فایل با نام های Network و Dictionary میباشد که در آنها یک مدل مرتبه ۲ 22 از کلمه های استفاده شده ذخیره میگردد.
تشخیص

مراحل تشخیص یک جمله
بلوک دیاگرام فوق در کتاب مرجع HTK مجموعه اطلاعات و بخش هایی که در نهایت موجب تشخیص یک ورودی سیستم میشوند را نشان میدهد. همانطور که مشاهده میشود مدل های زبانی ایجاد شده، مدل های حروف به همراه یک فایل مجهول به عنوان ورودی در نظر گرفته میشوند و توسط دستورHVite( که نام آن برگفته شده از الگوریتم Viterbi است ) پردازش شده و توسط دستورHResultآنالیز شده و درصد خطای آن بدست میآید.
انجام این مرحله پیاده سازی چالش ۳ توضیح داده شده در بخش مقدمه میباشد.
۳.۲. آزمایش اول : یادگیری اسامی فارسی
در یک آزمایش اولیه نام های فارسی ایجاد شده توسط کتابخانه های Faker را به عنوان ورودی سیستم در نظر میگیریم.
نتیج بدست آمده به شرح زیر است:
درصد های اعلام شده در جدول نتیجه میانگین حاصله از ۱۰ مرتبه اجرای عمل تشخیص روی ۱۰۰ داده ورودی به صورت تصادفی میباشد.
| قلم - اندازه | تعداد داده | صحت کلمه | صحت جمله |
|---|---|---|---|
| میترا ۴۲ | ۵۰۰ | ۸۰.۷۵٪ | ۷۷٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۴۹.۱۳٪ | ۴۰.۱٪ |
| میترا ۱۰۲ | ۱٬۵۰۰ | ۴۱.۴۱٪ | ۳۴٪ |
| میترا ۱۴۲ | ۲۵٬۰۰۰ | ۷.۳۹٪ | ۱.۲۱٪ |
۳.۳. آزمایش دوم : یادگیری از آرشیو های خبری
در آزمایش های آرشیو خبری تلاش بر این بوده که از داده هایی با مقیاس بزرگتر استفاده شود. همچنین جملات ورودی سیستم محدود به یک نام نیستند و برخی از جملات ورودی سیستم طولی بیش از ۱۵ حرف دارند.
| قلم - اندازه | تعداد داده | حداکثر تعداد طول جمله | صحت کلمه | صحت جمله |
|---|---|---|---|---|
| میترا ۴۲ | ۱٬۵۰۰ | ۳ | ۵۱.۰۶٪ | ۵۲.۰۰٪ |
| میترا ۴۲ | ۵٬۰۰۰ | ۳ | ۱۹.۲۱٪ | ۱۸.۲۰٪ |
| میترا ۴۲ | ۱۳٬۰۰۰ | ۳ | ۷.۱۸٪ | ۸.۰۰٪ |
| میترا ۴۲ | ۲۵٬۰۰۰ | نامحدود | ۱.۹۶٪ | ۱.۱۲٪ |
| میترا ۴۲ * | ۳۵٬۰۰۰ | ۳ | ۶.۹۶٪ | ۴.۸۷٪ |
۳.۴. نتایج اولیه برگرفته شده از آزمون ها
آزمایش های صورت گرفته در مقیاس های کوچک بیانگر این است که سیستم کلی که تمام مقدمات بر پایه آن بود، یعنی پیاده سازی نویسهخوان بر اساس تشخیص گفتار و یافتن بیشتر شباهت میان مدل های مارکوف، نهایتا قابل پیاده سازی است و میتواند جوابگو باشد. همچنین نتایج خوب در مقیاس های کوچک نمایانگر این نکته است که در متون ساده با دامنه محدود (مانند متن محدود به لغات مربوط به یک موضوع خاص) با یادگیری صحیح و در مدت زمان بسیار کم میتوان به نتایج خوبی دست یافت.
افت ضریب صحت کلمات با افزایش تعداد داده ها اصلی ترین مشکل سیستم اکنون است که میتواند دلایل مختلفی داشته باشد. تعداد داده های آزمایش شده بیشتر شده، اما نه تا حدی که به دقیق تر شدن بیشتر سیستم کمکی بکند. برای مثال در یک آزمایش با ۵۰۰ نام به عنوان ورودی تعداد حالت های موجود بسیار محدود است و میزان یادگیری نیز برای برای آن کفایت میکند. اما در یک آزمایش با ۵۰۰۰ داده ورودی تعداد حالات و کلمه های ممکن با ضریب بسیار زیادی رشد پیدا میکند (این تفاوت مخصوصاً در داده های خبری که میزان تنوع لغت در آنها بیشتر است مشهود است) در حالی که ۱۰ برابر شدن داده ها با ضریب کمتری باعث بهبود یادگیری مدل ها میشوند.
استفاده شدن از مدل های زبانی ضعیف نیز میتوان از دلایل کاهش دقت سیستم با گسترده تر شدن زبان باشد. در آزمایش های فوق برای تولید مدل زبانی از منبع مستقل استفاده نشده و به مجموع کل متن های ورودی سیستم برای تولید Bigram بسنده شده است. مثلا در آزمایشی با ۵۰۰ جمله ۳ حرفی از داده های خبری تنها همین ۵٬۰۰۰ جمله به عنوان مرجع زبان استفاده شدهاند. تنها در آزمایش آخر پایگاه های خبری که با علامت * مشخص شده است از یک مبع مستقل شامل بیش از ۵۰٬۰۰۰ جمله کامل خبری استفاده شده است که تاثیر مثبت آن نیز قابل مشاهده است. (هرچند با وجود آن نیز دقت بسیار پایین است)
در تمام آزمایش ها از یک رویه ثابت برای استخراج ویژگیها استفاده شده است. با وجود بهره گیری این رویه از روش های پیشنهاد شده در منابع شاید ایجاد تغییر در آنها بتواند موجب عملکرد سیستم گردد.
تنوع قلم ها و اندازه ها به حدی بودهاست که نشان دهد حداقل در این مرحله از پروژه نمیتواند تاثیر بسزایی ( مثلا رساندن یک نمونه آزمایش با دقت زیر ۵۰٪ به یک دقت مطلوب بالای ۷۰٪) در بهبود سیستم داشته باشد.
پارامتر های بسیاری زیادی را میتوان در مراحل انجام شده تغییر داد که تمام حالت های آنها ممکن است به نتیجه بهتر منجر شود. (انجام این تغییرات بعد مطالعه بیشتر و در فاز بهبود آزمایش میشود )
۴. قدم های بعدی پیشرو برای بهبود سیستم
با توجه به توصیفات و نتایج ذکر شده در قسمت قبل راهکار های زیر را برای بهبود سیستم در نظر میگیریم و نتایج بدست آمده از آنها را بررسی خواهیم کرد.
۴.۱. بهبود بردار ویژگی ها
۴.۱.۱. انواع پردازش تصاویر ورودی برای استخراج ویژگی ها
در میان مراحل استخراج ویژگی ها، بخش مهمی به منظور هموار سازی23 تصویر در نظر گرفته شده است. فیلتر های اعمال شده در این بخش علاوه بر تاثیر بر نتایج آزمایش های اکنون میتوانند برای کاربرد عملی سیستم نیز بسیار مهم باشند، زیرا در واقعیت تصاویر ورودی سیستم متن های منظم ایجاد شده در قالب کامپیوتر نیستند و قطعا نیاز به پالایش خواهند داشت. فیلتر های هموار سازی به منظور حذف ارتعاشات24 و آشکار ساختن ویژگی ها بدون وابستگی به میزان کیفیت تصویر، اهمیّت بسیار زیادی خواهد داشت.
فیلتر های مورد استفاده در پردازش تصویر، معمولا توسط یک سیستم خطی نمایش داده میشوند. پاسخ ضربه این سیستم خطی یک ماتریس دو بعدی در نظر گرفته میشود و حاصل نهایی تصویر پس از عبور از این سیستم حاصل کانولوشن این ماتریس در تمام دامنه تصویر ورودی است.
برای مثال یکی از فیلتر های استفاده شده رد این پژوهش، فیلتر یکپارچه25 نام دارد . پاسخ ضربه این فیلتر به شکل زیر در نظر گرفته میشود :
مشخص است که حاصل اعمال این کانولوشن بر تصویر، میانگین خانه های اطراف هر پیکسل را در آن خانه قرار میدهد .
یکی دیگر از فیلتر های بسیار جالب که به دلیل خواصش در فضای دو بعدی و همچنین در فضای فرکانسی بسیار به کار میرود، فیلتر گاوسی است . پاسخ ضربه این فیلتر یک ماتریس با تقریبی از نمایش تابع پالس گاوسی26 ( که به تابع زنگ شکل معروف است ) در نظر گرفته میشود .

که تقریبا به شکل مقابل درمیآید :
علاوه بر نوع فیلتر اعمال شده بر تصویر، تعداد المان های مشاهده شده در هر قاب نیز میتواند بر بهبود نتایج تاثیر داشته باشد . در ساختار HTK هر مشاهده در قالب تعداد نامتناهی از بردار هایی با طول یکسان در نظر گرفته میشود. هریک از این بردار ها را میتوان یک قاب عرضی (مانند تصویر ارایه شده در مقدمات پژوهش ) به عرض یک پیکسل در نظر گرفت که اطلاعات کل تصویر در آن قاب مذکور را شامل میشود. این مقدار تحت عنوان Dim به عنوان پارامتر اولیه سیستم قابل مقداردهی است و به صورت پیش فرض در آزمایش های قبلی مقدار ۲۰ به آن داده شد.
۴.۱.۲. آزمایش
نتایج بدست آمده از تغییر پارامتر های مرحله استخراج ویژگی ها به شرح زیر است :
با افزایش طول بردار ویژگی ها
| قلم - اندازه | تعداد داده | طول بردار ویژگی | طول جملات | صحت کلمه | صحت جمله |
|---|---|---|---|---|---|
| میترا ۴۲ | ۱٬۰۰۰ | ۱۰ | ۱ | ۵۸.۴۳٪ | ۵۸.۴۳٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۲۰ | ۱ | ۷۰.۹۲٪ | ۷۰.۹۲٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۴۰ | ۱ | ۸۴.۶۹٪ | ۸۴.۶۹٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۸۰ | ۳ | ۳۶.۲۱٪ | ۳۶.۲۱٪ |
با تغییر نوع فیلتر
| قلم - اندازه | تعداد داده | نوع فیلتر | طول جملات | صحت کلمه | صحت جمله |
|---|---|---|---|---|---|
| میترا ۴۲ | ۱٬۰۰۰ | Gaussian | ۱ | ۸۵.۱۷٪ | ۸۵.۱۷٪ |
| میترا ۴۲ | ۱٬۰۰۰ | Uniform | ۱ | ۸۴.۹۹٪ | ۸۴.۹۹٪ |
| میترا ۴۲ | ۱٬۰۰۰ | Hamming | ۱ | ۸۴.۱۲٪ | ۸۴.۱۲٪ |
۴.۱.۳. نتیجه
تغییر دادن طول بردار ویژگی پارامتر تاثیرگذاری بر نتیجه است. هرچند نباید فراموش کرد افزودن بیرویه آن موجب کاهش سرعت و افت نتایج میشود. ( ایجاد پیچیدگی بیش از حد عملا مقادیر بیشتری را برای ایجاد تمایز بین نمونه هایی که باید یکسان تشخیص داده شوند، در اختیار قرار میدهد و در نتیجه احتمال خطا بیشتر میشود.) قطعا نوع داده ورودی نیز تاثیر گذار است و باید به توجه به آن این مقدار بدست آید. آزمایش ها نشان میدهد که که برای متن های ایجاد شده توسط ماشین و با اندازه هایی مشابه مقادیر پیشفرض آزمایش های این پژوهش ( ۴۰ )، مقدار بین ۲۰ تا ۵۰ برای طول این بردار کفایت میکند و تاثیر مطلوبی در عین افزودن پیچیدگی زمانی کم، بر سیستم میگذارد.
استفاده از فیلتر های متفاوت، با وجود اشاره به جزییات و انجام چند آزمایش ساده، تلاش بیشتر در مورد مشاهده تاثیر مهم یک نوع فیلتر خاص از جامعیت پژوهش میکاهد و بر عهده کاربر برحسب نیاز خواهد بود. باید توجه داشته باشیم که استفاده از فیلتر خیلی بیش از مورد های دیگر به کاربرد و نوع ورودی بستگی دارد. ( توضیحات بیشتر در باره نحوه استفاده از روش های مختلف استخراج ویژگی در کنار HTK در مخزن پروژه ارایه میشود. ) همانطور که مشاهده میشود در متن های ایجاد شده به وسیله کامپیوتر و بدون هیچ ارتعاشی و با صرف نظر کردن پیچیدگی هایی که از تصاویر دست نویس یا تصاویر گرفته شده با دوربین و ..، تغییر این فیلتر تاثیر زیادی بر نتیجه نخواهد گذاشت. هرچند ذکر این نکته مهم است که فیلتر گاوسی با توجه به کاربرد های بسیار زیادش[۸] در رفع ارتعاش و همچنین قابل محاسبه بودنش در زمان ثابت ( O(k) ) احتمالا برای موارد کاربردی، بهینه تر خواهد بود.
۴.۲. افزایش تعداد تکرار های مشاهدات و دقت توزیع احتمال
۴.۲.۱. توزیع احتمالی گاوسی27 و استفاده آن در نویسهخوان
در بخش مقدمات، چهارمین عضو هر مدل پنهان مارکوف به شرح زیر تعریف شد :
احتمال مشاهدات متفاوت در هر ورودی. احتمال اینکه در وضعیت i مشاهده k ام جزو مشاهدات دریافتی باشد با نماد زیر نمایش داده میشود:
B = b_i(k) = P( v_k | q_t = s_i )
برای ذخیره این اطلاعات، به دلیل وجود تعدد های بسیار از مدل های مخلوط28 توزیع احتمال استفاده میشود. برای تفهیم بهتر این موضوع، آنرا در قالب مثال نویسخوان مطرح میکنیم :
در ابتدا برای ایجاد مدل های حروف، به ازای هر حرف یک مدل تعریف شده که تعداد حالات آن بر اساس مقدار تعریف شده توسط کاربر میباشد. روند به روز رسانی این مقادیر احتمال ( که میتواند از هرنوع توزیع رایجی استفاده کند، توزیع نرمال29 یا در این مثال توزیع گاوسی) باید به کرّات انجام شود و برای تحقق این امر از توزیع های مخلوط استفاده میشود . تفاوت و ویژگی توضیح های مخلوط در این است که ،در مشاهده n ام یک بردارجدید از ورودی ها و تلاش برای ارزیابی مجدد احتمال ها، به جای تغییر توزیع احتمال ایجاد شده در مرحله n-1 ام، یک توزیع جدید برای ورودی جدید در نظر گرفته میشود و ترکیب یا مخلوط30 آن با توزیع قبلی در نظر گرفته میشود.
هریک از توزیع های مخلوط گاوسی با دو پارامتر واریانس و میانه خود مقدار دهی و بهروزرسانی میشود.
۴.۲.۲. آزمایش
دوپارامتر بسیار مهم در پیاده سازی ارایه شده برای نویسهخوان تعداد تکرار های مشاهدات نمونه های آزمایش و همچنین تعداد مخلوط های گاوسی برای تعریف توزیع های احتمال میان حالت های مدل مارکوف ایجاد شده است. افزایش هریک از این متغیرها میتواند طبیعتا موجب افزایش دقت نتایج بدست آمده بشود. لازم به ذکر است در کنار بهبود نتایج زمان های لازم برای یادگیری و تشخیص نیز به طبع با بیشتر شدن تعداد تکرارها، بیشتر میشود.
برای بررسی تغییرات ایجاد شده ابتدا با یک نمونه داده خام (و نسبتا کم تعداد برای ایجاد امکان تکرار های متعدد آزمایش) بررسی بهبود را آغاز میکنیم و سپس همین راهبرد را بر روی داده های آزمایش شده قبلی تکرار میکنیم.
نتایج بدست آمده از افزایش تعداد تکرار ها و ثابت نگه داشتن توزیع احتمال :
| قلم - اندازه | تعداد داده | تعداد توزیع | تکرار | طول جملات | صحت کلمه | صحت جمله |
|---|---|---|---|---|---|---|
| میترا ۴۲ | ۱٬۰۰۰ | ۶۴ | ۴ | ۳ | ۳۳.۲۱٪ | ۱۴.۸۱٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۶۴ | ۸ | ۳ | ۴۶.۶۴٪ | ۲۲.۱٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۶۴ | ۱۶ | ۳ | ۴۶.۶۴٪ | ۲۲.۱٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۶۴ | ۳۲ | ۳ | ۴۵.۱۲٪ | ۲۳.۲۰٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۶۴ | ۶۴ | ۳ | ۴۹.۷۶٪ | ۲۵.۹۵٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۶۴ | ۱۲۸ | ۳ | ۴۸.۵۲٪ | ۲۸.۲٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۶۴ | ۲۵۶ | ۳ | ۴۶.۷۳٪ | ۲۳.۴۱٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۶۴ | ۵۱۲ | ۳ | ۵۱.۹۶٪ | ۲۸.۶۹٪ |
نتایج بدست آمده از افزایش توزیع احتمال و ثابت نگه داشتن تکرار :
| قلم - اندازه | تعداد داده | تعداد توزیع | تکرار | طول جملات | صحت کلمه | صحت جمله |
|---|---|---|---|---|---|---|
| میترا ۴۲ | ۱٬۰۰۰ | ۶۴ | ۳۲ | ۳ | ۴۷.۱۷٪ | ۲۵.۴۸٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۶۴ | ۳۲ | ۳ | ۷۸.۳۹٪ | ۸۱.۴۳٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۱۲۸ | ۳۲ | ۳ | ۹۲.۸۲٪ | ۸۶.۱۵٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۲۵۶ | ۳۲ | ۳ | ۹۶.۷۳٪ | ۹۳٪ |
| میترا ۴۲ | ۱٬۰۰۰ | ۵۱۲ | ۳۲ | ۳ | ۹۹.۵۹٪ | ۹۸٪ |
برای مشاهده دقیق تر اثر این تغییرات چند نمونه از داده هایی که در آزمایش های ابتدایی سنجیده شدند را انتخاب میکنیم. سطر های اول مربوط به آزمایش های قبلی و سطر های بعدی ازمایش های بهبود یافته میباشند.
نتایج بهبود یافته در اسامی فارسی
| قلم - اندازه | تعداد داده | تعداد توزیع | تکرار | صحت کلمه | صحت جمله |
|---|---|---|---|---|---|
| میترا ۴۲ | ۵۰۰ | ۶۴ | ۳۲ | ۸۰.۷۵٪ | ۷۷٪ |
| میترا ۴۲ | ۵۰۰ | ۱۲۸ | ۳۲ | ۱۰۰٪ | ۹۹.۲۱٪ |
| میترا ۴۲ | ۱٬۵۰۰ | ۱۲۸ | ۳۲ | ۹۱.۱۵٪ | ۸۳٪ |
نایج بهبود یافته از آرشیو های خبری
| قلم - اندازه | تعداد داده | تعداد توزیع | تکرار | حداکثر طول جمله | صحت کلمه | صحت جمله |
|---|---|---|---|---|---|---|
| میترا ۴۲ | ۵٬۰۰۰ | ۳۲ | ۴ | ۳ | ۱۹.۲۱٪ | ۱۸.۲۰٪ |
| میترا ۴۲ | ۵٬۰۰۰ | ۵۱۲ | ۳۲ | ۳ | ۹۳.۳٪ | ۹۱.۸۹٪ |
۴.۲.۳. نتیجه
واضح است که بیشتر کردن تعداد توزیع های احتمال تاثیر بسیار بهتری بر نتایج بدست آمده دارد. نهایتا آزمایش های متعدد نشان داده هردو روش فوق و ترکیبشان با یکدیگر میتواند تاثیر بسیار خوبی در نتیج سیستم بگذارد. هرچند این واقعیت قابل چشم پوشی نیست که هردو زمن یادگیری سیستم را نیز افزایش میدهند. برای رفع این مشکل میتوان از پردازش موازی داده ها استفاده کرد و تا حد خوبی آنرا جبران نمود. ( جزییات موازی کردن پردازش های یادگیری در مخزن ارایه شده است.) تجربه نشان داده، با توجه به دو معیار اصلی طول جملات و تعداد داده ها، مقادیر بین ۸ تا ۳۲ برای تکرار، و قادیر بین ۶۴ تا ۲۵۶ برای تعداد توزیع های احتمال هر حالت کفایت میکند.
۴.۳. بهبود داده های یادگیری
در بسیاری از یادگیری های انجام شده در مرحله پیاده سازی به یک نکته کوچک توجه نشده بود. متاسفانه در بسیاری از منابع فارسی متنی موجود، ضعف استفاده از حروف عربی و غیر استاندارد فارسی وجود داشته. برای مثال معادل های نادرست "ی" و "ئ" برای حرف فارسی "ی". وجود این دوگانگی ها موجب کاهش دقت سیستم در یادگیری حرف مذکور میشود. در این مرحله تمام منابع متنی ایجاد شده ابتدا ارزیابی و پالایش شده و اینگونه دوگانگی ها از میان دیده ها حذف گردیده است.
۵. آزمایش نهایی با استفاده از روش های ارایه شده در فاز بهبود.
آزمایش نهایی زیر با بهره گیری از روش های ارایه شده فوق برای نشان دادن قابلیت سیستم در مقیاس بزرگ بدست آمده است.
| قلم - اندازه | تعداد داده | تعداد توزیع | تکرار | حداکثر طول جمله | صحت کلمه | صحت جمله |
|---|---|---|---|---|---|---|
| میترا ۴۲ | ۱۷٬۰۰۰ | ۲۵۶ | ۳۲ | ۱ | ۷۵.۶۴٪ | ۷۵.۶۴٪ |
| میترا ۴۲ | ۱۷٬۰۰۰ | ۵۱۲ | ۳۲ | ۱ | ۸۹٪ | ۸۹٪ |
۶. نتیجه نهایی
با استفاده از تکنیک ها و روش های اریه شده در قسمت قبل ، نشان داده شد که میتوان ایراد اصلی آزمایش های اولیه، یعنی ناتوانی سیستم در تشخیص صحیح میان انبوه بزرگی از داده ها را برطرف کرد. قطعا غلبه بر مشکل مقیاس پذیری نشان دهده پایان مشکلات نخواهد بود، در متن پژوهشنامه نیز به بسیاری از مسایلی که میتوانند یک مانع بزرگ بر سر راه باشد اما در این مرحله از آنها چشم پوشی کردیم، اشاره شد. اما نتایج اکنون سیستم میتواند نشان دهنده یک مسیر صحیح برای رفع همه این موانع باشد.
به عنوان آخرین عمل برای ثمر بخش بودن این پژوهش، کلیه اطلاعات مربوط به نحوه راه اندازی سیستم نویسهخوان فارسی که تمام آزمایش های این پژوهشنامه به وسیله آن انجام شده ، به همراه منابع و کد های مربوطه در مخزن گیتهاب پروژه قرار گرفته و نتایج بعدی در توضیحات مخزن درج خواهد شد.
۷. کار های آینده
مختصرا به برخی از مواردی که در طی این پژوهش به آنها اشاره مستقیم نشد، یا بسیار سطحی بررسی شدند، یا مربوط به آینده میباشند، اشاره میکنیم و توضیح مختصری در مورد آنها میدهیم :
مدل زبانی : HTK ( چه بخواهیم چه نخواهیم ) از مدل های زبانی برای بهبود نتایج استفاده میکند. (البته میتوان ضریب تاثیر آنرا کاهش داد.) در طی این پژوهش اشاره مختصری به تاثیر مثبت استفاده از مدل های زبانی قوی مخصوصا در داده های طولانی (جملات بلند با بیش از ۴ حرف) شد، اما نتایج مجزا برای میزان تاثیر آن ارایه نشد. دلیل اصلی اهمیت این موضوع این است که در صورت عدم توجه به مدل زبانی و استفاده از مدلی که با داده ها همخوانی لازمه را نداشته باشد، نه تنها تاثیر مثبت ندارد، بلکه موجب افت نتایج نیز میگردد .
استخراج ویژگی :نویسهخوان فارسی ایجاد شده در طی این پژوهش ( خوب یا بد ) بر پایه سیستم تشخیص گفتار بنا شده و فقط مرحله ایجاد و استخراج ویژگی های آن متفاوت میباشد. در طی این پژوهش راهکار ها و توضیحاتی در مورد روند انجام اینکار و بهبود آن مطرح شد، اما از تغییرات بزرگ و اساسی بر روی استخراج ویژگی ها پرهیز شد. ( عملا خواستیم ابتدا تمام قابلیت های این روش استخراج را بررسی کنیم و سپس یک روش دیگر را امتحان کنیم ) و استفاده از این انعطاف با ایجاد تغییرات اساسی در این بخش نیز میتواند نتایج جالبی را به همراه داشتهباشد. برای نمونه یکی از فرضیه های شکل گرفته استفاده از مدل های آماری ( محاسبه واریانس و میانه هر قاب مشاهدات ) به جای مدل های ریاضی ( مشتق طولی و عرضی ) میباشد که باید در آینده آزمایش بشود.
فونت های متعدد : با توجه به اهداف پژوهش و روندی که به مرور زمان به خود گرفت، به دلیل محدودیت زمانی برای انجام آزمایش های متعدد تقریبا از یک مجموعه فونت و اندازه ثابت برای داده های یادگیری استفاده شد.یادآوری این سوال اهمیت دارد که از خود بپرسیم : هدف از یاد دادن فونت های جدید به سیستم چیست ؟ اگر قرار است تشخیص از یک مجموعه متون ثابت و مشخص که طبیعتا دستخط یا فونت ثابتی نیز دارند انجام شود، یادگرفتن فونت جدید نیز بی دلیل خواهد بود. برای رفع مشکلاتی مانند ارتعاش و خطوط دستنویس هم بسیار بعید است یادگیری فونت های متعدد گره گشا باشد و احتمالا باید با اعمال فیلتر ها به این نتایج دست یافت.
تشخیص در سطح جمله، لغت،یا ترکیب هردو : این موضوع در حد یک فرضیه باقی مانده، اما از اهمیت بسیار زیادی برخوردار است و میتواند واسطی میان استفاده آزمایش محور و استفاده کاربردی نویسهخوان فارسی باشد. آزمایش ها نشان داد که - طبیعتا - با انجام عمل تشخیص در سطح کلمات ( داده های آزمایش با طول جملات ۱ ) نتایج بهتری خواهیم گرفت. همچنین این ایراد ( که در پژوهش به آن اشاره ای نشد ) در میان آزمایش ها مشاهده شد، که مثلا اگر سیستم به درستی بتواند جمله " کیان به خانه آمد " را تشخیص دهد، متاسفانه هیچ تضمینی وجود ندارد که بتواند همیشه کلمات "کیان" و "خانه" را درست تشخیص دهد. هرچند با احتمال بسیار قوی این ایراد نیز راه حل هایی خواهد داشت ، اما از هزینه زیاد پردازش تصاویر جملات کامل و طولانی، بردارهای ویژگی بزرگتر، زمان یادگیری بیشتر و .. آن نیز نمیتوان چشم پوشی کرد. این فرضیه ( یا سوال مهم ) مطرح است که آیا انجام یک پیش پردازش بر روی تصاویر و انجام قطعه قطعه سازی ( که متاسفانه یا خوشبختانه از اولین خطوط این پژوهش پرهیز از آن را تاکید کردیم ) روی آن تا حد کلمات ، در مجموع چه از نظر زمانی و چه از نظر دقت بهینه تر خواهد بود یا خیر؟ تا به اینجا اینکه از نظر دقت بهینه تر خواهد بود را به نوعی نشان دادهایم، اما این به شرطی خواهد بود که فرض کنیم که میتوانیم همه تصاویر ورودی برای تشخیص را نیز مانند تصاویر یادگیری تا حد کلمات مجزا، بشکانیم ( عمل قطعه قطعه سازی برای کلمات جدا بسیار ساده تر است و چیزی که از ابتدای این پژوهش سعی کردیم از آن پرهیز کنیم قطعه قطعه سازی تا حد حروف و سعی بر تشخیص یک کلمه بر پایه حروف بود.)
۸. مراجع
[1] A Robust، Language-Independent OCR System . Zhidong Lu, Issam Bazzi, Andras Kornai, John Makhoul,
Premkumar Natarajan, and Richard SchwartBBN Technologies, GTE Internetworking, Cambridge, MA 02138
[2] Post Processing of Optically Recognized Text via Second Order Hidden Markov Model . Srijana Poudel , University of Nevada, Las Vegas
[3] Optical Character Recognition - A Combined ANN/HMM Approach , Sheikh Faisal Rashid Thesis
[4] The Optical Character Recognition for Cursive Script Using HMM: A Review . Saeeda Naz, Arif I. Umar, Syed H. Shirazi
[5] The 1994 BBN/BYBLOS Speech Recognition System, Nguyen, T. Anastasakos, F. Kubala, C. LaPre, J. Makhoul, R. Schwartz, N. Yuan, G. Zavaliagkos, and Y. Zhao
[6] A tutorial on hidden Markov models and selected applications in speech recognition
[7]Documentation for HTK
[8]Image Filters in Machine Vision
۹. لینک های مفید
Optical Character recognition
Feasable
Curved script language
Segmentation
Charachter Recognition
Path Recognition
Speech recognition
Markov Assumption
State
State Transition Metrice
Observation
Element
Featur Extraction
Character Modeling
Pattern Matching
Tag
Prototype
Left to Right HMM
Recognition
Space
Bigram Language Model
Smoothing
Noise
Uniform
Gaussian Pulse
Gaussian Mixture Model
Mixture Models
Normal Distribution
Mixture