۱. چکیده
مسئله مورد مطالعه پروژه این است که با استفاده از اطلاعات فیلمها و امتیازاتی که در مجموعه داده IMDb به هر فیلم داده شده است، از طریق روشهای
یادگیری ماشین، امتیاز فیلم را پیشبینی نماییم. نتایج نشان می دهد روش ها و ویژگی های داده ای که در این پروژه در نظر گرفته شده از تحقیقات پیشین بهتر
عمل کرده و می توان با دقت بالاتری امتیاز فیلم ها را پیش بینی کرد .
۲. مقدمه
هرهفته تعداد بسیار زیادی فیلم منتشر می شود که در ژانرهای متفاوتی قرار می گیرند؛ مانند انیمیشن،کمدی،رمانتیک،وحشتناک ،تخیلی و غیره که به یکی از اساسی ترین موضوع های سرگرم کننده مردم تبدیل شده اند. بنابراین انتخاب فیلم مناسب و جذاب از میان آن ها کار بسیار دشوار و زمان بری است.در این میان پلتفرم های آنلاین بسیاری وجود دارد؛ از جمله:RottenTamatoes، Metacritic و پایگاه فیلم اینترنتی IMDb که اطلاعات منصفانه و دقیقی در مورد فیلم ها مانند بازیگران،کارگردانان،بودجه و امتیاز دهی کاربران و نظرات آنها را در اختیار مخاطبان قرار می دهد.
در حال حاضر، بهترین و معتبرترین پایگاه فیلم اینترنتی،IMDb می باشد. این سایت شامل اطلاعاتی در مورد فیلم و سریال های تلویزیونی و سینمایی مثل سوابق مالی،بیوگرافی،امتیاز کاربران، بازیگران،کارگردانان،عوامل تولید،بررسی ها و ... می باشد.در حدود 3.4 میلیون عنوان فیلم و سریال در آن قرار گرفته است.این پایگاه فیلم بیشتر از 60 میلیون کاربر ثبت شده دارد.
براساس مطالعات انجام شده،صنعت فیلم سازی در آمریکا که سالانه بیش از 10 میلیارد دلار درآمد از فروش فیلم به دست می آورد، تاثیر بالایی را در اقتصاد این کشور به جا گذاشته است.همین موضوع ،مسئله پیش بینی امتیاز فیلم را پر اهمیت تر جلوه می دهد.تحقیقات زیادی در رابطه با پیش بینی امتیاز فیلم انجام گرفته است که اکثریت آن ها برمبنای رتبه دهی کاربران است .همچنین در برخی از آن ها برای پیش بینی از رسانه های اجتماعی مختلف استفاده می شود؛مانند:
یوتیوب،توییتر و غیره.با این حال،استفاده کمتری از معیارهای فیلم (مثل کارگردان،بازیگران و تاریخ) شده است.اما مهم ترین منبع اطلاعاتی برای پیش بینی، داده های موجود در اینترنت است.
۳. کارهای مرتبط
تاکنون پژوهش های وسیعی بر روی موضوع پیش بینی امتیاز فیلم انجام شده است.همان طور که گفتیم،اکثر محققان این فرایند را برپایه ی روزنامه ها،مقالات و شبکه های اجتماعی بررسی کرده اند.اما برخی از آن ها،مطالعات خود را براساس ویژگی های فیلم ها انجام داده اند.
در مقاله [1] این تحقیق به منظور پیش بینی آینده فیلم از نظر میزان کسب و کار با استفاده از داده ها در رسانه های اجتماعی و بهره گیری از تحلیل احساسات انجام شده است.یک کار مشابه دیگر درمقاله [2] ارائه شده است که در آن از رسانه های اجتماعی مانند توییتر و نظرات یوتیوب برای دست یابی به هدف قبلی به کار می رود.[3] با استفاده از داده های IMDb و داده های boxofficemojo و ضریب همبستگی به عنوان یک واحد اندازه گیری،دو مجموعه داده از فیلم های منتشر شده و فیلم های پس از انتشار و آزمایش های کاربردی بر روی آن ها ایجاد کرده است.[4] با استفاده از داده های IMDb،RottenTamatoes و ویکیپدیا در مورد فیلم ها و بهره گیری از الگوریتم های یادگیری ماشین مانند رگرسیون خطی، رگرسیون SVM و رگرسیون منطقی،امتیاز فیلم پیش بینی خواهد شد.
آزمایش مقاله ی [5] ،رویکرد آن متناسب با چیزی است که ما به دنبال آن می گردیم. روش اصلی انجام این آزمایش در شکل1 به نمایش گذاشته شده است :
استخراج داده
آماده سازی داده ها
انتخاب ویژگی
کلاس بندی

شکل1.مراحل مختلف آزمایش
۳.۱. استخراج داده
مجموعه داده مورد استفاده از پایگاه فیلم اینترنتی (IMDb) جمع آوری شده است.فیلم های از سال 2004 تا 2014 بررسی شده اند. تنها فیلم هایی انتخاب شده اند که در ویکی پدیا صفحات سال آن ها ذکر شده بود و نیز فیلم های انگلیسی که در ایالات متحده منتشر شده اند. فیلم های دیگر حذف شده است.سپس باpython. داده مر بوطه را استخراج کرده و مجموعه حاوی 2000 داده شد.
۳.۲. آماده سازی داده ها
داده های استخراج شده از IMDb باید به داده های عددی (Numeric) تبدیل می شدند تا بتوان آن ها را برای تجزیه،تحلیل و طبقه بندی مورد استفاده قرار دهد. در زیر تعدادی از آن ها را بیان کرده است.
۳.۲.۱. امتیاز فیلم (Rating )
هر فیلم در IMDb یک امتیاز بین 0 تا 10 دارد. هر کاربر می تواند به فیلم ها رای دهد و میانگین رای گیری همان امتیاز فیلم است. ما امتیاز فیلم(rating) را برای تجزیه و تحلیل وکلاس بندی استفاده می کنیم و این برچسب (label) کلاس برای پیش بینی خواهد بود.
۳.۲.۲. امتیاز MPAA
انجمن فیلم آمریکا (MPAA) سازمانی است که رتبه بندی فیلم ها را تعیین می کند.این رتبه بندی ها نشان دهنده میزان خشونت و زبان در یک فیلم می باشد. پنج نشان برای هر یک از فیلم ها به طور عمده وجود دارد: R، PG، PG13، G و NR.امتیاز MPAA را برای هر فیلم با پنج مقدار باینری نشان داده است.
۳.۲.۳. ژانر
ژانر نوع محتوای موجود در یک فیلم را نشان می دهد. یک فیلم می تواند یک ژانر واحد داشته باشد؛ برای مثال Fish Tank فیلم منتشر شده در سال 2009 دارای ژانر درام است و یا می تواند شامل ژانر های متعدد باشد؛ مانند فیلم Exodus: Gods and Kings منتشر شده در سال 2014 دارای 3 ژانر است که شامل اکشن، ماجراجویی و بیوگرافی است.ژانرها خود دربرگیرنده انواع متفاوتی هستند که عبارتند از:اکشن، ماجراجویی، هیجان انگیز، بیوگرافی، جرم و جنایی، درام، ترسناک، کمدی،فانتزی،انیمیشن، رمز و راز، موسیقی، جنگ، مستند، عاشقانه، علمی تخیلی، غرب،خانواده، ورزش و کوتاه. برای نشان دادن ژانر برای هر یک از فیلم ها،20 متغیر باینری را به هر یک از آن ها اختصاص داده است.
۳.۲.۴. جوایز
جایزه اسکار وطلایی جزء معتبرترین جوایز فیلم ها هستند. بسیاری از فیلم ها برنده جایزه و تعدادی نامزد دریافت آن می شوند. حتی نامزد شدن، دستاورد بزرگی است.4 ارزش باینری برای نمایش جوایز برای برنده شدن و نامزدی در اسکار و طلایی اختصاص داده است.
۳.۲.۵. تعداد نمایش ها
هنگامی که یک فیلم منتشرمی شود،در سینماها به اکران در می آید. قبل از انتشار یک فیلم تصمیم گرفته شده است که به چه تعداد دفعات مورد نمایش قرار
می گیرد.از این خصوصیت در مجموعه داده ها استفاده کرده است.
۳.۲.۶. میزان فروش هفته اول
درآمد حاصل از فیلم در اکثر هفته ها ارزیابی می شود. درآمد تولید شده توسط یک فیلم در هفته اول انتشار آن به عنوان نام تجاری و از ویژگی های فیلم در
هفته آخر می باشد.
۳.۲.۷. بودجه فیلم
بودجه،مقدار منابعی است که در ساخت یک فیلم استفاده می شود. این مقدار،کل پولی است که درطول ساخت فیلم هزینه می شود. بودجه می تواند از چند هزار دلار تا چند میلیون دلار را دربرگیرد. بودجه یک ویژگی پیوسته است.
۳.۲.۸. تعداد آرا
کاربر می تواند به سایت IMDB وارد شود و فیلم ها را نقد و بررسی کند.هم چنین می تواند فیلم را در بازه بین 0 تا 10 امتیاز دهی کند . برای هر فیلم، تعداد آرا نیز موجود است که آن را می توان به عنوان یک ویژگی برای پیش بینی امتیاز فیلم در نظر گرفت .
۳.۳. کلاس بندی
تعداد بسیار زیادی ابزار داده کاوی وجود دارد. در این مقاله از ابزار WEKA استفاده کرده است.WEKA برای داده کاوی با مجموعه ای از الگوریتم های یادگیری ماشین مناسب است و می تواند طبقه بندی، پیش پردازش داده ها، خوشه بندی و ...را انجام دهد.در این مقاله ،از الگوریتم هایLogistic regression، وNaive Bayes بهره گرفته است.سپس هر یک از نتایج را با 10-fold cross validation مورد صحت قرار داده است.
نتایج simple logistic و logistic regression و Naive Bayes به ترتیب 84.34٪ و 84.15٪و79% شده است.نیز در برخی از طبقه بندی کننده های دیگر(classifiers)، مانند شبکه عصبی اجرا شده،اما هدف مورد نظر حاصل نشده است.با توجه به این که در مقاله [4] دقت 39% برای ماشین بردار پشتیبان و دقت 42.2% برای رگرسیون منطقی به دست آمده است،این آزمایش،نتیجه بسیار خوبی را در مقایسه با آن نشان داده است.
در آزمایشی که در مقاله [5]مطرح شد،برای پیش بینی امتیاز فیلم،نزدیک به 7 ویژگی استفاده شده است که می توان با کاهش بعد به وسیله PCA ویا الگوریتم انتخاب ویژگی به نتایج بهتری دست یافت.
برای به دست آوردن نتایج بهتر شاید بتوان از روش های دیگر یادگیری ماشین از جمله ماشین بردار پشتیبان (SVM)و یا ماشین بردار پشتیبان دوقلو برای بهبود یا افزایش سرعت پاسخگویی بهره برد.
۴. ماشین بردار پشتیبان
ماشین بردار پشتیبان، یک الگوریتم یادگیری ماشین با نظارت است که می تواند برای طبقه بندی یا رگرسیون استفاده شود. با این حال، در مسائل طبقه بندی به کار می رود . در این الگوریتم، ما هر یک از آیتم های داده را به عنوان یک نقطه در فضای n بعدی (که n تعداد ویژگی های شما است) درنظر میگیریم.سپس، طبقه بندی را با یافتن ابر صفحه انجام می دهیم که این دو کلاس را کاملا از هم متمایز می کند.شکل 1 بیانگر این موضوع می باشد.
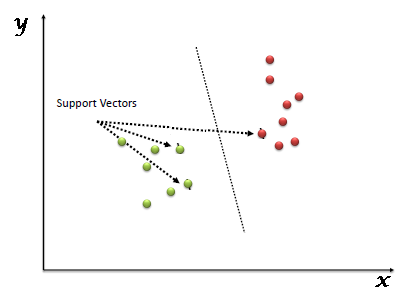
این روش اولین بار توسط Boser و همکاران به عنوان یک روش دو کلاسه ارائه شد.[6] این روش نیاز به تعیین توزیع آماری داده ها ندارد و از داده های آموزشی
برای آموزش طبقه بندی کننده استفاده می شود. فرض کنید برای یک تصویر که از d کانال تشکیل شده باشد. x_i بردار ویژگی پیکسل i ام باشد. دراینصورت
یک ابرصفحه بهینه برای یک مجموعه داده آموزشی داده شده به صورت \{(x_i,y_i),.......(x_2,y_2),(x_1,y_1) \} که در آن y_i \in \{1,-1 \}تصویر شده به فضای هیلبرت توسط یک نگاشت غیرخطی ایجاد می کند . این ابر صفحه جدایی بین نمونه های کلاس ها را در فضای ویژگی چند بعدی بیشینه میکند. همچنین با اجازه دادن به میزان کمی خطا در جدایی بین نمونه های آموزشی در کلاسها، ابرصفحه ی بهینه با بیشینه نمودن حاشیه و کمینه نمودن جمع خطاهای وارد شده بدست می آ ید . بنابراین SVM رابطه (1)را حل میکند،

که w وزن تابع خطی تصمیم گیر درH و به عنوان بردار عمود بر ابرصفحه و b میزان بایاس و یک مقدار ثابت بوده به طوری که ||b||wفاصله بین ابرصفحه و مبدا را نشان می دهد. epsilon\متغیر خطا می باشد. و C پارامتر تنظیم بوده که میزان عمومیت پذیری را تنظیم می کند . مساله بهینه سازی رابطه (1) با استفاده از تابع دوگانه لاگرانژ که به صورت رابطه (2)تعریف میشود، قابل حل است.

که در آن متغیرهای مجازی \alpha_i ضرایب لاگرانژ بوده و فقط برای بردارهای پشتیبان غیرصفر می باشد. ضرب داخلی نمونه ها در فضای ویژگی میتواند بدون در اختیارداشتن تابع نگاشت \phi، بطور مستقیم از داده ها در فضای اصلی با استفاده از تابع کرنل محاسبه شود. بنابراین رابطه (2) با استفاده از روش کرنل به صورت را بطه (3) نوشته می شود .

بعد از حل مساله بهینه سازی، ضرایب \alpha_i همانطور که در [7 ] توضیح داده شده است،تعیین شده و پس از آن تابع تصمیم گیری برای طبقه بندی هر بردار دلخواه x توسط رابطه (4) بیان می شود.

۵. آزمایش ها
در بخش کارهای مرتبط از الگوریتم ها و روش های مختلفی در مقالات متفاوت برای پیاده سازی بهره گرفته شده است.اما با توجه به پژوهش هایی که در رابطه با موضوع پیش بینی فیلم انجام'داده ایم ،رویکردی که برای این پروژه تعبیه شده است،استفاده از الگوریتم (SVM (Support Vector Machines یا همان ماشین بردار پشتیبان است.
کار الگوریتم ماشین بردار پشتیبان،طبقه بندی یا کلاس بندی (classification)می باشد.در این آزمایش،خروجی ها که در واقع همان امتیاز فیلم ها می باشند،در بازه ی صفر تا ده هستند که آن را به چهار کلاس طبقه بندی می کنیم:
فیلم های ضعیف (0-2.4)
فیلم های متوسط (2.4-5)
فیلم های خوب (5.1-7.4)
فیلم های عالی (7.4-10)
اما اشکالی وجود دارد و آن این است که خروجی های ما داده هایی پیوسته می باشند و کلاس SVM،تنها داده های باینری را می پذیرد.در واقع الگوریتم SVM دو کلاسه می باشد.لذا به هریک از این کلاس ها،یک مقدار تخصیص می دهیم(1 به فیلم های ضعیف و به همین ترتیب برای عالی ترین فیلم ها عدد 4 را مقداردهی می کنیم).اما در حال حاضر چهار کلاسه هستیم.به همین دلیل باید از الگوریتم های Multiclass استفاده نماییم.روش های Multiclass عبارتند از:
روش One vs All
در این روش هر کلاس در مقابل سایر کلاس ها آموزش داده می شود. به داده های مربوط به خود کلاس برچسب 1 +و داده های سایر کلاس ها برچسب 1 -نسبت داده می شود. اگر تعداد کلاس ها N باشد، N ماشین بردار پشتیبان آموزش داده می شود که هر یک متناظر با یکی از کلاس ها می باشد.پس از آموزش کلاس ها در مرحله تست، هر یک از نمونه های تست به تمامی N ماشین بردار پشتیبان اعمال می شود، کلاس برنده کلاسی است که SVM آن بیشترین میزان خروجی را داشته باشد. در صورت زیاد بودن داده های آموزشی و تعداد کلاس ها، زمان آموزش ماشین بردار پشتیبان طولانی خواهد بود.ما از این روش برای انجام این آزمایش استفاده نموده ایم.

۵.۱. انتخاب ویژگی
برای این آزمایش از مجموعه داده ای که دراینجا قرار دارد،استفاده می شود.این مجموعه شامل 5000 فیلم می باشد.با استفاده از تابع dropna داده های missing یا در واقع داده هایی که بعضی از ویژگی هایشان وجود نداشت را از بین بردیم که در نهایت تعداد داده های ما حدود 2000عدد می شود.در این آزمایش 75% داده ها به عنوان یادگیری(Train) و 15% آن ها را برای آزمایش(Test)قرار می دهیم.حال با توجه به میزان تاثیر هر ویژگی در پیش بینی امتیاز فیلم ، ویژگی های زیر را برای مدل سازی روش خود به کار می بریم :
۵.۱.۱. بودجه فیلم
بودجه یک فیلم،همان طور که پیشتر گفته شد،شامل تمام هزینه های حاصل از ساخت یک فیلم می باشد که ویژگی پیوسته ای است.بودجه جزو مهم ترین ویژگی های اثرگذار بر کیفیت فیلم و در نتیجه ی آن،امتیاز فیلم می باشد.
۵.۱.۲. محبوبیت
محبوبیت را می توان جزو ویژگی های مهم یک فیلم تلقی نمود.میزان علاقه مردم و محبوبیت آن در بین شان می تواند تاثیر چشمگیری برروی امتیاز آن فیلم داشته باشد.این نوع داده ای،عددی می باشد.
۵.۱.۳. میزان درآمد
درآمد یک فیلم همان طور که نامش پیداست،همان پولی است که از فروش و اکران و نمایش آن به دست می آید.معمولا درآمد یک فیلم با کیفیت آن فیلم متناسب است.هرچه فیلم بهتر باشد،میزان درآمد حاصل از آن بیشتر است و بالعکس.لذا جزو ویژگی های های مهم به شمار می آید.
۵.۱.۴. زمان اجرا
تعداد دفعاتی که یک فیلم بر روی پرده سینما به اکران درآمده است.این ویژگی می تواند فاکتور خوبی برای پیش بینی امتیاز فیلم محسوب شود.
۵.۱.۵. تعداد آرا
در قسمت کارهای مرتبط توضیح داده شده است.
۵.۱.۶. کارگردان
هر فیلم دارای یک کارگردان است که وظیفه هماهنگی و تولید یک فیلم را به عهده دارد.به طور طبیعی،فیلم هایی با کارگردانان معروف و مشهور مخاطب بیشتری دارند و استقبال از آن ها بیشتر است.لذا ویژگی مهمی برای پیش بینی تلقی می شود.اسم کارگردان،داده ای عددی نمی باشد.لذا باید به یک داده عددی تبدیل شود.
۵.۱.۷. بازیگر نقش اول
یکی از عوامل درخشش و جذب مخاطب به یک فیلم،نقش آفرینی سوپراستارهای مطرح در آن می باشد.بنابراین بازیگر نقش اول ،نقش مهمی در کیفیت فیلم دارد.لذا از آن به عنوان یک ویژگی استفاده می کنیم.چون بازیگر نقش اول یک داده ی عددی نیست،باید آن را به یک داده عددی تبدیل نماییم.
شرح جزییات پیاده سازی
زبان پایتون به دلیل داشتن کتابخانه ها (Libraries)و ماژول های (Modules)متعدد و نیز انعطاف پذیری آن،مورد توجه دانشمندان علم داده کاوی قرار گرفته است.لذا ما در این برنامه نیز با همین زبان پیاده سازی کردیم تاسرعت و کارایی طبقه بندی خود را افزایش دهیم .
در این پروژه ما از تعدادی ماژول و کتابخانه به شرح زیر استفاده نمودیم که عبارت اند از:
1.ماژول pandas: با استفاده از این ماژول،داده هایمان را که از نوع csv می باشد،خوانده وبه نوع DataFrame تبدیل می کنیم تا بتوانیم با آن ها کار کنیم.
ماژول sklearn :این ماژول ،بسیار پرکاربرد است.در داخل این ماژول کلاس های متنوعی وجود دارد که ما از تعدادی از آن ها استفاده کردیم.در کتابخانه ای با نام sklearn.svm کلاس SVC وجود دارد .این کتابخانه شامل تمامی الگوریتم های SVMمی باشد. یکی دیگر از موارد استفاده شده،تابع train_test_split است که داده ها را به نسبتی که تعیین می کنیم به دو قسمت train و test تبدیل می کند.accuracy_score تابعی می باشد که دقت برنامه را اندازه می گیرد و درصدی را گزارش می دهد.این تابع دو پارامتر Y_Predict و Y_Real را به عنوان ورودی دریافت می کند.کلاس دیگر همان Multiclass می باشد که در قسمت قبل دلیل استفاده از آن توضیح داده شده است.در آخر برای ارزیابی ضربدری(cross validation)با استفاده از کلاس KFOLD تمام داده های dataset را مورد train و test قرار می دهیم.لذا جواب دقیقی از دقت برنامه به ما می دهد.
ماژول numpy:این کلاس که با زبان C نوشته شده است،در مورد کار با آرایه ها بسیار سریع و کاربردی است.
ماژول time:این تابع زمان کلاس بندی(classification) را مشخص می کند.
کد برنامه که در سایت github قرار داده شده است،در اینجا قابل مشاهده است.
به طور کلی،در ابتدا پس از خواندن مجموعه داده،داده های از جاافتاده را حذف می کنیم.به دلیل عددی نبودن دو ویژگی کارگردان و بازیگر ،ابتدا اسم کارگردان وبازیگر هر فیلم را از tmdb_5000_credits استخراج می کنیم.سپس با استفاده از تابع ()pd.unique آن ها را به داده عددی تبدیل می کنیم .
name_direc=pd.unique(data['directer'].values.ravel())
data['directer']=data['directer'].replace(name_direc,np.arange(0,924))
name_char=pd.unique(data['char1'].values.ravel())
data['char1']=data['char1'].replace(name_char,np.arange(0,788))
سپس برچسب کلاس و7 ویژگی داده را انتخاب کرده و با استفاده از تابع ()pd.replace مقادیر پیوسته برچسب را به مقادیر گسسته تبدیل می کنیم .
# our labeles to predict imdb rate
label=data1[['vote_average']]
# our numeric features to predict data
feature=data[['budget','popularity','revenue','runtime','vote_count','char1','directer']]
# label of vote_averages
for i in label['vote_average']:
if i <= 2.4:
label=label.replace (i,10)
elif 2.4<i<=5:
label=label.replace(i,20)
elif 5.1<=i<7.4:
label=label.replace(i,30)
elif 7.4<=i<10 :
label=label.replace(i,40)
label=label.replace([10, 20, 30, 40],[1, 2, 3, 4])
در نهایت داده های test وtrain را از هم جدا کرده و به کلاس بند OVA-SVM می دهیم.سپس برای دستیابی به نتایج واقع بینانه تر،با استفاده از الگوریتم KFOLD cross validation داده ها را مورد ارزیابی قرار می دهیم.
# K-Fold Cross validation, divide data into K subsets
k_fold = KFold(10)
i = 1
acc_list = []
# Train and test SVM K times
for train_index, test_index in k_fold.split(feature):
# Extract data based on index created by k_fold
X_train = np.take(feature, train_index, axis=0)
X_test = np.take(feature, test_index, axis=0)
X_train_label = np.take(label, train_index, axis=0)
X_test_label = np.take(label, test_index, axis=0)
result2= OneVsRestClassifier(SVC(kernel='rbf'))
result2.fit(X_train,X_train_label)
result_df=result2.predict(X_test)
acc_sc = accuracy_score(X_test_label, result_df)
acc_list.append(acc_sc)
۶. نتایج
در نمودار زیر نتایج این آزمایش و مقاله های [4] و [5] آمده است.ما در این آزمایش به دقتی معادل 83% رسیده ایم.در حالی که مقاله [4] دقتی معادل 39% به دست آورده است.این موضع نشان دهنده این است که ما در این پروژه ویژگی های مهم تری را برای پیش بینی امتیاز فیلم در نظر گرفته ایم.همچنین دقت به دست آمده بسیار نزدیک به نتایج مقاله [5] می باشد که حاکی از عملکرد مناسب برنامه ی ما می باشد.

۷. کارهای آینده
شاید بتوان برنامه را با روش های دیگر Multiclass مانند DAG پیاده سازی نمود تا به نتایج دقیق تر و بهتری دست پیدا کرد.هم چنین می توانیم با استفاده از الگوریتم ماشین بردار پشتیبان دو قلو (TSVM) نتایج بهتری با دقت و سرعت بیشتر را به دست آورد.نیز می توان با استفاده از الگوریتم های تکاملی مانند PSO وPCA ویژگی های برتر را انتخاب نمود.
۸. مراجع
[1] Asur, S., & Huberman, B. A. (2010, August). Predicting the future with social media. In Web Intelligence and Intelligent Agent Technology (WI-IAT), 2010 IEEE/WIC/ACM International Conference on (Vol. 1, pp. 492-499). IEEE.
[2] Mestyan, M., Yasseri, T., & Kertész, J. (2013). Early prediction of movie box office success based on Wikipedia activity big data. PloS one, 8(8), e71226.
[3] Asad, K. I., Ahmed, T., & Rahman, M. S. (2012, May). Movie popularity classification based on inherent movie attributes using C4. 5, PART and correlation coefficient. In Informatics, Electronics & Vision (ICIEV), 2012 International Conference on (pp. 747-752). IEEE.
[4] Nithin VR, 2Pranav M, 3Sarath Babu PB, 4Lijiya.Predicting Movie Success Based on IMDB Data.Volume: 03, June 2014, Pages: 365-368.International Journal of Data Mining Techniques and ApplicationsISSN: 2278-2419 .
[5] Latif, M. H., & Afzal, H. (2016). Prediction of movies popularity using machine learning techniques. International Journal of Computer Science and Network Security (IJCSNS), 16(8), 127.
[6]Boser, B. E., Guyon, I. M., & Vapnik, V. N. (1992, July). A training algorithm for optimal margin classifiers. In Proceedings of the fifth annual workshop on Computational learning theory (pp. 144-152). ACM.
[7]Lee, J. S., Hoppel, K. W., Mango, S. A., & Miller, A. R. (1994). Intensity and phase statistics of multilook polarimetric and interferometric SAR imagery. IEEE Transactions on Geoscience and Remote Sensing, 32(5), 1017-1028.
۸.۱. پیوندهای مفید
Predicting Movie Success Based on IMDB Data,By Nithin VR, Pranav M, Sarath Babu PB, Lijiya A, Department of CSE, National Institute of Technology, Calicut, 2014 لینک