۱. مقدمه
ارتباط مبتنی بر متن به یکی از رایج ترین شکل بیان ، تبدیل شده است. ایمیل ها، پیام های متنی، توییت (tweet)، و غیره ... وضعیت های ما را به صورت روزانه بیان میکند و یک جور داده های متنی ساختار نیافته است که تجزیه و تحلیل مقدار زیادی از این داده های متنی در حال حاضر یک روش کلیدی برای
درک آنچه که مردم فکر می کنند میباشد .[15]
توییت در توییتر به ما کمک می کند موضوعات مطرح در اخبار جهان را پیدا کنیم. نظرات در مورد آمازون به کاربران کمک می کند تا محصولات با بهترین امتیاز را خریداری کنند. این نمونه هایی از سازماندهی و ساختار دانش است که نشانگر نقش پردازش زبان طبیعی (NLP) است.NLP زمینه ای در علوم رایانه ای است که بر تعامل بین کامپیوترها و انسان تمرکز دارد. تکنیک های NLP برای تجزیه و تحلیل متن مورد استفاده قرار میگیرد .[15]
در این پروژه با استفاده از توسعه مدل زبانی(NLP)، الگوریتمی طراحی و پیادهسازی میکنیم که بتواند کلمهای از یک جمله را که ناپدید شده است به صورت هوشمند و به درستی حدس بزند.
برای این کار نیاز به روش های پردازش متن داریم که با استفاده از آنها بتوانیم متن را پردازش کرده و کلمه حذف شده را حدس بزنیم .که در ادامه به توضیح آنها میپردازیم .
۲. کارهای مرتبط
ابتدا باید گفت که در هر شبیه سازی و حل مسئله، یک مدل سازی اولیه لازم است. این مدل سازی ممکن است ریاضی، فیزیکی، تجسمی و یا به هر گونه دیگر متناسب با ماهیت شبیه سازی یا حل مسئله باشد. برای مثال، وقتی شما می خواهید یک پدیده فیزیکی را شبیه سازی کنید و یا یک مسئله فیزیک را حل کنید، ابتدا سعی می کنید، شرایط را در غالب یک مدل ریاضی یا تجسمی، مجرد کنید. بدین معنی که اجزای بدون اهمیت آن را کنار بگذارید و با تنها مهم ترین عوامل را در بررسی خود تأثیر دهید. بدین ترتیب، با تقریب بالایی توانسته اید نزدیک جواب را پیدا کنید.[3]
حال به معرفی چند اصطلاح میپردازیم:
زبان طبیعی : زبان طبیعی زبانی است که در تعاملات اجتماعی روز مره ما با استفاده از آن می نویسیم و صحبت می کنیم.
پردازش زبان طبیعی یا NLP : این ادعا را دارد که با خودکار کردن پردازش زبان ، سیستم های مفیدی بر پایه این توصیفات را میتواند بوجود بیاورد. هدف از پردازش زبان طبیعی این است که کامپیوترها از زبان طبیعی به عنوان ورودی و خروجی استفاده نمایند.و کاربرد هایی از قبیل زیر دارد:
1- کاربرد های بر پایه متن.
2- فهم زبان طبیعی.
3- سیستم های مکالمه.
4- چند بعدی.
برای مطالعه بیشتر درباره NLP میتوانید به [7] مراجعه نمایید.
مدل سازی زبان طبیعی : یعنی بیاییم و روابط و قواعد زبان را به طور هدفمند، ساده کنیم تا به ابزاری برسیم که بتوان از آن برای بررسی زبان و یا استفاده یا حتی تولید آن استفاده کرد.بسیاری از این مدل ها، از یک پس زمینه ریاضی مانند گراف، احتمالات و ... .برخوردار هستند، مدل زبانی( Language Model ) ، مدل کردن نحوه رخداد توالی کلمات در زبان است و 2 نوع دارد :
1- مدل زبانی ساختاری : با استفاده از تعدادی قواعد زبانی، نحوه توالی لغات را مشخص میکند.[3]
2- مدل زبانی آماری :مدلسازی آماری زبان به توسعه مدلهای آماریای گفته میشود که میتوانند کلمهی بعدی را در یک توالی از کلمات تخمین بزنند. این مدلها چند کلمه قبلی را به عنوان ورودی دریافت میکنند و حدس میزنند چه کلمهای ممکن است کلمه بعدی باشد.[8]
مدلسازی آماری زبان به هر جمله یک احتمال اختصاص میدهد و آن احتمال، احتمال وقوع همچین جملهای در آن زبان است. علاوه بر تخصیص احتمال به هر جمله، این مدلها احتمال حضور یک کلمه در یک توالی، به شرط دانستن کلمههای قبلی، را تخمین میزد.[8]همچنین میتوان گفت به یک دنباله از کلمات زبان مانند W=w1w2…wm یک مقدار احتمال P(W) نسبت میدهد و در ترجمه ، خطایابی و تشخیص گفتار کاربرد دارد .[3]
در ادامه انواع مدل های زبانی آماری را توضیح میدهیم :
۲.۱. روش NGRAM :
فرض کنید که یک سری اشیا یا نشانه ها و یا هر چیز دیگری داشته باشیم. هر کدام از این ها را به صورت یک رأس در گراف تصور کنید که می تواند به رأس دیگری یال جهت دار داشته باشد. این یال جهت دار، نشان دهنده یک نوع رابطه است که با توجه به مورد دلخواه ما می تواند معانی متفاوتی داشته باشد. مثلاً در مورد زبان، می تواند توالی دو کلمه باشد (اگر کلمه ای بعد از کلمه دیگری بیاید، یک یال از اولی به دومی وجود دارد).
به یک توالی n تایی از این رأس ها، n-gram می گوییم (توالی های 3gram، 2gram و ... داریم). در این مدل، یک مجموعه داده های آماری بسیار بزرگ نیاز داریم که هر کدام مجموعه ای از این نشانه ها به همراه روابط بین آن ها است. برای مثال، در مورد یک زبان خاص، یک سری متن به آن زبان می باشد. حال، روابطی در این مدل تعریف می شود که می توان با استفاده از آن، درستی یک توالی خواص از این نشانه ها را بررسی کرد.[3]
در حالت کلی، احتمال درستی در n-gram به صورت رابطه زیر است:

این الگوریتم برای بررسی مجاورت دو رشته استفاده می شود. مجموعه N-gram شامل دنباله های n تایی یک رشته است.[20]
مثال: رشته information که بصورت زیر است:
info – nfor – form – orma – rmat – mati – atio – tion
روش کلی بدین صورت است که ابتدا تمامی N-gram ها را تولید می کنیم و آن ها را اندیس گذاری می کنیم. وقتی خواستیم یک کلمه را اصلاح کنیم همین کار را با آن کلمه می کنیم.[20]
برای این کار دو روش وجود دارد:
1- ابتدا N-gram های کلمه را پیدا می کند و آن ها را با N-gram های دیکشنری مقایسه می کند و نزدیکترین کلمه ی درست را پیدا می کند.[20]
2- ابتدا کلمات مشابه کلمه اشتباه را با استفاده از الگوریتم Leveshtein برای یک فاصله ویرایشی معین، پیدا می کند سپس برای هر کدام از آن ها N-gram ها را تولید می کند، هر کدام از کلمات که تعداد بیشتری N-gram مشابه با کلمه اشتباه داشته باشد را به عنوان پیشنهاد ارائه می کند.(برای کشف غلط های ناشی از جای خالی کار می کند)[20]
۲.۲. روش Bag of Word :
فرض کنید فرهنگ لغتی داریم با N کلمه و لغت که به ترتیب الفبایی مرتب شده اند و هر لغت یک مکان مشخص در این فرهنگ لغت دارد. حال برای نمایش هر کلمه، برداری در نظر میگیریم با طول N که هر خانه آن، متناظر با یک لغت در فرهنگ لغت ماست که برای راحتی کار فرض می کنیم شماره آن خانه بردار،
همان اندیس لغت مربوطه در این فرهنگ لغت خواهد بود . با این پیش فرض، برای هر لغت ما یک بردار به طول N داریم که همه خانه های آن بجز خانه متناظر با آن لغت صفر خواهد بود. در خود ستون متناظر با لغت عدد یک ذخیره خواهد شد.(One-Hot encoding) با این رهیافت، هر متن یا سند را هم میتوان با یک بردار نشان داد که به ازای هر کلمه و لغتی که در آن به کار رفته است ، ستون مربوطه از این بردار برابر تعداد تکرار آن لغت خواهد بود و تمام ستون های دیگر که نمایانگر لغاتی از فرهنگ لغت هستند که در این متن به کار نرفته اند، برابر صفر خواهد بود .
یک مثال ساده در این زمینه :
(1) John likes to watch movies. Mary likes movies too.
(2) John also likes to watch football games.
که bag of word این دو جمله مجموعه(به اصطلاح بردار ) زیر میشود :
["John","likes","to","watch","movies","Mary","too","also","football","games"]
سپس تعداد تکرار هر کلمه از مجموعه خود را به ازای هر جمله همانند زیر مینویسیم :
(1) [1, 2, 1, 1, 2, 1, 1, 0, 0, 0]
(2) [1, 1, 1, 1, 0, 0, 0, 1, 1, 1]
با یک مثال دیگر این مفهوم را بیشتر توضیح می دهیم . فرض کنید که دو جمله زیر را داریم :
Sentence 1: “The cat sat on the hat”
Sentence 2: “The dog ate the cat and the hat”
برای این دو جمله فرهنگ لغت ما عبارت خواهد بود از : { the, cat, sat, on, hat, dog, ate, and }
و نمایش صندوقچه کلمات این دو جمله طبق توضیح از قرار زیر است :
Sentence 1: { 2, 1, 1, 1, 1, 0, 0, 0 }
Sentence 2 are: { 3, 1, 0, 0, 1, 1, 1,1}
با این روش ما دو بردار عددی داریم که حال می توانیم از این دو در الگوریتم های عددی خود استفاده کنیم. با وجود سادگی این روش ، اما معایب بزرگی این بر آن مترتب است. مثلاً اگر فرهنگ لغت ما صد هزار لغت داشته باشد ، به ازای هر متن ما باید برداری صد هزارتایی ذخیره کنیم که هم نیاز به فضای ذخیره
سازی زیادی خواهیم داشت و هم پیچیدگی الگوریتم ها و زمان اجرای آنها را بسیار بالامی برد .
از طرف دیگر در این نحوه مدلسازی ما فقط کلمات و تکرار آنها برای ما مهم بوده است و ترتیب کلمات یا زمینه متن (اقتصادی ، علمی ، سیاسی و …) تاثیری در مدل ما نخواهدداشت .
به این روش نمایش متون، صندوقچه کلمات یا Bag Of Words می گوییم که بیانگر این است که برای هر لغت در صندوقچه یا بردار ما، مکانی درنظر گرفته شده است . Bag of word model یک نمایش ساده است که در پردازش زبان طبیعی و بازیابی اطلاعات مورد استفاده قرار میگیرد .
در این مدل یک متن ( یک جمله یا یک سند ) نشان دهنده ی کیفی (چند مجموعه ای ) از کلمه هایش بدون در نظر گرفتن نکات گرامر و جفت های مرتب کلمه به استثناء تکرارات آنها میباشد.[5]
۲.۳. روش word to vec :
نکته : تا قبل از استفاده از شبکههای عصبی مصنوعی، استفاده از N-Gram رایجترین روش براش ساخت مدل زبان بود. اما اخیرا استفاده از شبکههای عصبی مصنوعی در ساخت مدلهای آماری زبان اخیرا رایج شده است و میشه گفت بهترین روش حال حاضر است چون این روشها نتایج بهتری نسبت به روش های قدیمیتر گرفتهاند. شاید بتوان گفت مهمترین ویژگی این روش که باعث شده است از روشها قبلی پیشی بگیرد قابلیت تعمیم آن باشد.[8]
در این روش به کمک شبکه عصبی یک بردار با اندازه کوچک و ثابت برای نمایش تمام لغات و متون در نظرگرفته شده و با اعداد مناسب در فاز آموزش مدل یا training برای هر لغت این بردار محاسبه می شود. در این بردار هر ستون ، نمایشگر کلمه یا ویژگی خاصی نیست و فقط یک عدد را نمایش می دهد. اگر این بردار را ۴۰۰ تایی فرض کنید، یک فضای ۴۰۰ بعدی خواهیم داشت که هر لغت در این فضا یک نمایش منحصر بفرد خواهد داشت. برای افزایش دقت این روش، مجموعه داده اولیه که برای آموزش مدل مورد نیاز است، باید حدود چند میلیارد لغت را که درون چندین میلیون سند یا متن به کار رفته اند، در برگیرد. بعد از ایجاد بردارهای مرتبط با هر لغت، برای نمایش برداری هر متن یا خبر ، می توان بردار تک تک کلمات به کار رفته در آنرا یافته و میانگین اعداد هر ستون را به دست آورد که نتیجه آن یک بردار برای هر متن یا سند خواهد بود.
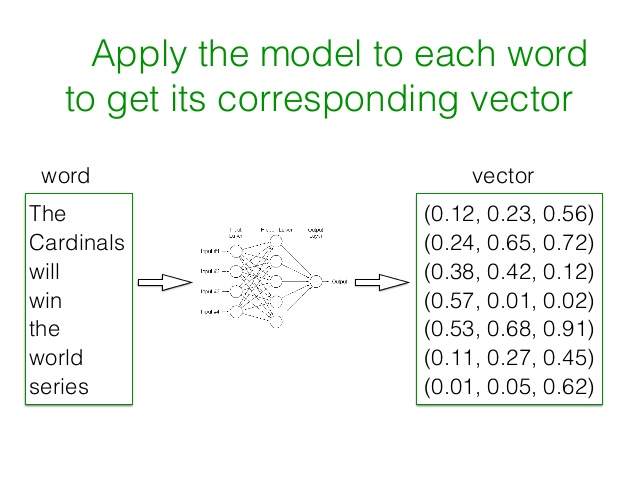

برای ساخت بردار 2 روش وجود دارد :
۲.۳.۱. در روش کیف لغات پیوسته (CBOW) :
ابتدا به ازای هر لغت یک بردار با طول مشخص و با اعداد تصادفی (بین صفر و یک) تولید می شود. سپس به ازای هر کلمه از یک سند یا متن، تعدادی مشخص از کلمات بعد و قبل آنرا به شبکه عصبی می دهیم (به غیر از خود لغت فعلی) و باعملیات ساده ریاضی، بردار لغت فعلی را تولید می کنیم (یا به عبارتی از روی کلمات قبل و بعد یک لغت، آنرا حدس می زنیم) که این اعداد با مقادیر قبلی بردار لغت جایگزین می شوند. زمانی که این کار بر روی تمام لغات در تمام متون انجام گیرد، بردارهای نهایی لغات همان بردارهای مطلوب ما هستند.برای مطالعه بیشتر درباره روش cbow میتوانید به [2] مراجعه نمائید.
۲.۳.۲. روش Skip-gram :
برعکس این روش کار می کند به این صورت که بر اساس یک لغت داده شده ، می خواهد چند لغت قبل و بعد آنرا تشخیص دهد و با تغییر مداوم اعداد بردارهای لغات، نهایتا به یک وضعیت باثبات می رسد که همان بردارهای مطلوب ماست.[5]
نحوه کار این دو روش را در شکل زیر می توانید ببینید :

۲.۴. شبکه Multilayer perceptron یاMLP
دارای سه یا چند لایه است. ازیک تابع فعال غیرخطی (عمدتا تنگستن هجایی یا تابع منطقی) استفاده می کند که طبقه بندی داده هایی را که به طور خطی قابل جدا شدن نیستند اجازه میدهد. هر گره در یک لایه به هر گره در لایه زیر متصل می شود و شبکه را به طور کامل متصل می کند. به عنوان مثال، برنامه های کاربردی پردازش زبان طبیعی چندلایه[10] (NLP) عبارتند از تشخیص گفتار و ترجمه ماشین
۲.۵. شبکه عصبی مصنوعی (CNN)
یک شبکه عصبی مصنوعی (CNN) حاوی یک یا چند لایه کانولولوژیک است که با هم تلفیق می شوند و یا به طور کامل متصل می شوند و از تنوع چندلایه ای ادراک های مورد بحث در بالا استفاده می شود. لایه های متخلخل از یک عملیات کانولاسیون برای گذراندن ورودی از نتیجه ، به لایه بعدی استفاده می کنند. این عملیات اجازه می دهد تا شبکه با پارامترهای بسیار کمتر عمیق تر شود.[10]
شبکه های عصبی برتر نتایج برجسته ای را در برنامه های تصویری و گفتاری نشان می دهد. یون کیم[9] در شبکه عصبی مصنوعی برای طبقه بندی جمله، فرایند و نتایج وظایف طبقه بندی متن را با استفاده از CNN توصیف می کند.و یک مدل ساخته شده در بالای word2vec را ارائه می دهد، یک سری آزمایشات را با آن انجام می دهد و آن را در برابر چند معیار آزمایش می کند، نشان میدهد که مدل عالی عمل می کند.در متن Understanding from Scratch، Xiang Zhang و Yann LeCun، نشان می دهد که CNN ها می توانند بدون آگاهی از کلمات، عبارات، احکام و سایر ساختارهای نحوی یا معنایی با توجه به زبان انسانی عملکرد فوق العاده ای کسب کنند.
تجزیه معنایی ، تشخیص پارافرز ، تشخیص گفتار نیز کاربرد CNNs هستند.[10]
۲.۶. شبکههای عصبی بازگشتی(RNN)
شبکههای عصبی متداولی که تاکنون متخصصان یادگیری ماشین از اونها استفاده میکردند نمیتوانستند به این صورت شبیه انسان عمل کنند و این یک نقصان بزرگ برای این شبکهها محسوب میشود. برای مثال فرض کنید مدلی که شما ساختید قرار است مشخص کند در هر لحظه از فیلم چه اتفاقی در حال افتادن است. مشخص نیست شبکههای عصبی قدیمی چطور میتوانند از اطلاعاتی که در صحنههای قبلی فیلم به دست آوردهاند برای تشخیص نوع اتفاق در صحنههای بعدی فیلم استفاده کنند. شبکههای عصبی بازگشتی (Recurrent Neural Network) برای برطرف کردن این مشکل طراحی شدند. در حقیقت شبکههای عصبی بازگشتی در خودشان شامل یه حلقه بازگشتی هستند که منجر میشود اطلاعاتی که از لحظات قبلی بدست آوردیم از بین نروند و در شبکه باقی بمانند.
بعضی مواقع ما فقط نیاز داریم فقط به اطلاعات گذشته نزدیک نگاه کنیم تا متوجه اطلاعات حال حاضر بشویم. برای مثال، فرض کنید ما مدلِ زبانیای ساختهایم که تلاش میکند کلمه بعدی را با توجه به کلمات قبلیای که در اختیارش قرار دادیم پیشبینی کند. اگر ما میخوایم آخرین کلمه در جمله «ابرها هستند در آسمان» را پیشبینی کنیم، ما به اطلاعات اضافیِ دیگری نیاز نداریم و تقریباً میشود گفت واضح است که کلمه بعدی «آسمان» است. در موارد مشابه این مثال، که فاصله بین اطلاعات مرتبط و جایی که به این اطلاعات نیاز داریم خیلی کم است ،شبکههای عصبی بازگشتی میتوانند یاد بگیرند که از این اطلاعات استفاده کنند.
۲.۷. شبکههای LSTM
که خلاصه شده عبارت "Long Short Term Memory" هستند، [12]نوع خاصی از شبکههای عصبی بازگشتی هستند که توانائی یادگیری وابستگیهای بلندمدت را دارند. برای مطالعه بیشتر درباره معرفی شبکه ها برای اولین بار میتوانید به [11] مراجعه نمایید .
همه شبکههای عصبی بازگشتی به شکل دنبالهای (زنجیرهای) تکرار شونده از ماژولهای (واحدهای) شبکههای عصبی هستند. در شبکههای عصبی بازگشتی استاندارد، این ماژولهای تکرار شونده ساختار سادهای دارند، برای مثال تنها شامل یک لایه تانژانتِ هایپربولیک (tanh) هستند.[12]

شبکههای LSTM نیز چنین ساختار دنباله یا زنجیرهمانندی دارند ولی ماژولِ تکرار شونده ساختار متفاوتی دارد. به جای داشتن تنها یک لایه شبکه عصبی، ۴ لایه دارند که طبق ساختار ویژهای با یکدیگر در تعامل و ارتباط هستند.[12]

عنصر اصلی LSTMها سلول حالت (cell state)است که در حقیقت یک خط افقی است که در بالای شکل قرار دارد.
سلول حالت را میتوان به صورت یک تسمه نقاله تصور کرد که از اول تا آخر دنباله یا همان زنجیره با تعاملات خطیِ جزئی در حرکت است (یعنی ساختار آن بسیار ساده است و تغییرات کمی در آن اتفاق میافتد).[12]

همچنین این توانائی را دارد که اطلاعات جدیدی را به سلول حالت اضافه یا اطلاعات آن را حذف کنید. این کار توسط ساختارهای دقیقی به نام دروازهها (gates)
انجام میشود.دروازهها راهی هستند برای ورود اختیاری اطلاعات. آنها از یک لایه شبکه عصبیِ سیگموید (sigmoid) به همراه یک عملگر ضرب نقطه به نقطه تشکلیل شدهاند.

برای مطالعه بیشتر درباره شبکه عصبی LSTM به [12] مراجعه نمایید.
۲.۸. شبکه های عصبی ضعیف
علاوه بر شبکه های عصبی عمیق، مدل های کم عمق نیز ابزار محبوب و مفیدی هستند. [7]به عنوان مثال، word2vec یک گروه از مدل های دو لایه کم عمق است که برای تولید کلمه های تعبیه شده استفاده می شود.،همانطور در دربالا اشاره کردیم word2vec یک قسمت بزرگ متن را به عنوان ورودی ، وارد می کند و یک فضای بردار ایجاد می کند .[13] هر کلمه ای در بدنه متن، بردار مربوطه در این فضا را دریافت می کند. ویژگی متمایز آن این است که کلمات از مفاهیم متداول در بدنه متن نزدیک به یکدیگر در فضای بردار قرار دارند.[7]
۲.۹. الگوریتم های ریشه یابی
ریشه یابی لغات نه به معنای زبان شناسی آن ، بلکه به معنای دسته بندی کلمات در گروه های معنایی یکسان، امری است که در بسیاری از زمینه های پردازش زبان طبیعی مدنظر می باشد.ریشه کلمات به معنی حذف پیشوند و پسوند و علامت جمع و غیره ...میباشد و کلماتی که دارای یک ریشه هستند معمولا از لحاظ معنایی تفاوت چندانی ندارند .پیدا کردن ریشه کلمات آنجا کاربرد دارد که بخواهیم یک جای خالی را با کلماتی که میتوانند در آن جای خالی قرار بگیرند پر کنیم .
آن چیزی که میبایست به یک الگوریتم ریشه یابی کلمه اضافه شود تا الگوریتمی برای حل مساله مورد بحث ما باشد یافتن جای خالی به صورت خودکار و هوشمندانه است .
در بین کلماتی مانند related , relational , relation , relating ریشه تمامی این کلمات relate میباشد .
انواع الگوریتم ریشه یابی :
۲.۹.۱. الگوریتم های مبتنی بر دیکشنری :
این الگوریتم ها کاملترین الگوریتمهای ریشه یابی هستند و دارای مشکلاتی نظیر :
قابلیت گسترش پایین (no scalability)
ناتوانی در دسته بندی کلمات در گروه های معنایی همسان
درجه زمانی و مکانی بسیار بالا[19]
۲.۹.۲. الگوریتم های مبتنی بر قانون :
این الگوریتمها، بر روی به دست آوردن ریشه ی کلمات از طریق تعدادی قوانین از پیش تعیین شده کار می کنند.
قوانین موجود ساختارهای زبانشناسی نیستند.
مشکلات روش قبل را ندارند.
از لحاظ مؤفقیت از درصد پایینی برخوردار هستند.
از این دسته الگوریتمها می توان به الگوریتمهای معروف Porter و Lovins و Krovetz... بر روی زبان انگلیسی و الگوریتم ریشه یابی کاظم تقوی و ... بر روی زبان فارسی اشاره کرد.[19]
الگوریتم porter:
ریشه یاب پورتر ریشه یاب کاهش دهنده ادغامی برای زبان انگلیسی است .این ریشه یاب بصورت مرحله ای(5 مرحله که در هر مرحله قوانین خاصی اِعمال می شود) و خطی می باشد که در ادامه به این مراحل اشاره می کنیم. در هر مرحله عملیات کاهش یا افزایش روی کلمات صورت می گیرد.
در زبان انگلیسی یک حرف بی صدا(Consonant) در یک کلمه حرفی غیر از A,E,I,O,U و Y بعد از یک حرف صدادار است.(واقعیت آن است که تعریف حرف بی صدا بصورت بازگشتی در اینجا باعث مبهم شدن تعریف حرف بی صدا نمی شود). بنابراین در TOY حروف بی صدا T و Y هستند و در SYZYGY حروف بی صدا S و Z و Gمیباشند.[19]
CVCV ... C
CVCV ... V
VCVC ... C
VCVC ... V
[C]VCVC ... [V]
مراحل این روش :
در مرحله اول بیشتر با قسمت سوم افعال و صورت جمع کلمات سروکار داریم مثل:
SSES -> SS
caresses -> caress
IES -> I
ponies -> poni
SS -> SS
caress -> caress
در مراحل 2 و3 و 4 هم به صورت مشابه قوانین مختلفی استفاده می شود تا به ریشه مورد نظر نزدیک تر شویم مثل :
2 : (m>0) ATIONAL -> ATE
relational -> relate
(m>0) TIONAL -> TION
conditional -> condition
3: <-(m>0) ATIVE
formative -> form
(m>0) ALIZE -> AL
formalize -> formal
4 : <- (m>1) IBLE
defensible -> defens
(m>1) ATE ->
activate -> activ
تا اینجا تمامی پسوندها حذف شده است و آنچه که مانده کمی از مراحله تصفیه (مرحله 5) است. در این مرحله هم عملیاتی نظیر قوانین زیر صورت می گیرد.
5:<-(m>1) E
probate -> probat

در الگوریتم porter هیچ توجه ای به پیش وند ها نمی شود که باعث می شود که نتایج کمی نادرست باشد ولی در عمل این مسئلة چندانی نیست چونکه وجود پیشوند احتمال کاهشها و ادغامهای نادرست را کاهش می دهد.
الگوریتم کاظم تقوی برای زبان فارسی
این الگوریتم شباهت زیادی به الگوریتم پورتر در انگلیسی دارد و بر مبنای ریخت شناسی میباشد.
هر دو ریشه یاب به دنبال پسوندهای خاصی جستجو می کنند و مراحل مختلفی را بر طبق لیست قوانین پسوندی پشته گذاری شده طی میکنند. . با این حال تفاوتهای مهمی بین این دو الگوریتم وجود دارد.
برای مثال الگوریتم ریشه یاب پورتر به منظور تخمین محتوای اطلاعات، الگوی حروف صدادار و بی صدا را تشخیص می دهد؛ اما در فارسی بسیاری از حروف صدادار نوشته نمی شوند، بنابراین ریشه یاب فارسی از طول رشته برای تعریف کران پائین محتوای ریشه استفاده می کند.( در حال حاضر مینیمم طول ریشه 3 است).این محدودیت در بعضی موارد باعث خطا میگردد بخصوص زمانیکه یک زیررشته که قسمتی از یک کلمه کوتاه است ، به اشتباه به عنوان یک پسوند در نظر گرفته شود. تفاوت دیگر این دو الگوریتم ان است که این الگوریتم بر خلاف الگوریتم پورتر ، پیشوندها را هم شناسایی می کند.[19]
الگوریتم کراوتز
این الگوریتم برای زبانهایی که ساخت کلمات در آنها قانونمند است، کارائی خوبی را نشان داده است.
الگوریتم کراوتز پسوند و پیشوند کلمات را بررسی می کند و در ماشینهای مترجم کارائی خوبی را نشان داده است.
اولین کاربرد این ایده برای زبان انگلیسی معرفی شده است. صرف افعال زبان انگلیسی و همچنین افزودن s/es به انتهای اسامی برای جمع بستن آنها مورد بررسی قرار می گیرد. همانطور که ملاحظه می شود این تغییرات نقش کلمات را تغییر نمی دهند، به همین دلیل برای ماشین های مترجم مناسب هستند.
الگوریتم کراوتز تعدادی از پسوندها را مورد بررسی قرار می دهد و در هر مرحله با زدودن پسوند یافت شده، ریشه بدست آمده را مورد بررسی قرار می دهد. در صورتیکه این ریشه در فرهنگ لغات موجود باشد، عمل ریشه یابی متوقف می شود.
گاهی افزودن یک پسوند باعث تغییراتی در ساختار یک کلمه می شود برای کشف چنین کلماتی در صورتیکه ریشة کلمه در فرهنگ لغات نباشد، بر روی کلمه یک سری تغییراتی اِعمال می کند تا هنگامی که ریشه در فرهنگ لغات یافت شود.[19]
| find stem | main stem | WORD |
|---|---|---|
| Goe | go | Going |
| Bee | be | Being |
در جدول بالا برخی از موارد عدم کارکرد صحیح الگوریتم کراوتز در انگلیسی را میبینید.
فاصله لوناشتاین یا فاصله ویرایش
در نظریه داده و علوم کامپیوتر متری برای محاسبه میزان تفاوت میان دو رشته است.[21]
فاصله لوناشتاین بین دو رشته بوسیله کمترین تعداد عملیات مورد نیاز برای تبدیل یک رشته به رشته دیگر معین میشود.
به عنوان مثال فاصله لون اشتاین بین "kitten" و "sitting" برابر 3 است. [21]
همانطور که میبینیم حداقل سه ویرایش برای تبدیل یکی به دیگری وجود دارد و کمتر از آن ممکن نیست:
kitten → sitten(با جایگزینی 's' به جای 'k')
sitten → sittin(با جایگزینی 'i' به جای 'e')
sittin → sitting(با وارد کردن 'g' در انتها)
۳. مراحل قبل از پیاده سازی
یکی از کار هایی که میبایست انجام شود این است که یک الگوریتم را با چه ابزاری پیاده سازی میکنیم که در ادامه به توضیح آن میپردازیم :
۳.۱. پلتفرم NLTK :
یک پلتفرم برجسته برای ساخت برنامه های پایتون جهت کار کردن با داده های زبان انسان می باشد، NLTK یک واسط است که استفاده از آن خیلی ساده میباشد و برای بیش از 50 مجموعه نوشته ها (corpora یا corpus ) و منابع لغوی و وابسته به فرهنگ لغت مانند WordNet ، همراه با مجموعه کتابخانه هایی از پردازش متون برای طبقه بندی(classification)، توکن کردن(tokenization)، ریشه یابی لغات (stemming)، پارس کردن(parsing)، به دست آوردن تگ لغات فراهم شده است.[14]
این پلتفرم برای سیستم عامل های Windows، Mac و لینوکس سازگار هست و لازم به ذکر هست که پروژه ای کاملا رایگان و متن باز هست.[14]
برای مطالعه بیشتر درباره این پلتفرم میتوانید به این کتاب مراجعه نمایید.
۳.۲. ماژول Scipy
ماژولSciPyیک ماژول پایتون می باشد که امکان دستکاری در ارایه های n بعدی را به آسانی و با سرعت فراهم می سازد. همچنین روتین ها و روال های عددی نیز همچون روتین هایی برای انتگرال گیری عددی و بهینه سازی در این ماژول بصورت یک امکان موثر و بسیار کاربرپسند اضافه شده اند. SciPy ماژول هایی برای بهینه سازی، جبر خطی، ادغام و دیگر وظایف مشترک در علم داده ها را به عهده دارد.[16]
۳.۳. ماژولMatplotlib
ماژولMatplotlib
ماژولی برای تصویر سازی و ویژوالیزیشن می باشد. Matplotlib این امکان را به شما می دهد که به سرعت یافته های خود را به صورت گراف و نمودار در آورده و فیگورهای حرفه ای بسازید. با استفاده از این ماژول می توانید از هر جنبه ای که بخواهید اشکال خود را بسازید و سفارشی سازی کنید.[16]
۳.۴. ماژول Scikit-Learn
ماژول Scikit-Learn
یک ماژول پایتون برای یادگیری ماشینی می باشد که بر روی SciPy سوار می شود. این ماژول مجموعه ای از الگوریتم های معروف یادگیری ماشینی می باشد که از طریق یک رابط کاربری سازگار به کاربران ارائه شده است. در اینجا میتوانید نیم نگاهی به سری الگوریتم های موجود در این ماژول بپردازید.[16]
۳.۵. ماژول Statsmodels
ماژول Statsmodelsماژول و مدلی برای پایتون می باشد که به کاربران خود اجازه میدهد در اطلاعات خودبه اکتشاف بپردازند، مدل های آماری را ارزیابی کنند و تست های آماری بگیرند.[16]
۳.۶. کتابخانه PyBrain
کتابخانه PyBrain مخفف یادگیری تقویتی، هوش مصنوعی و شبکه عصبی مبتنی بر پایتون می باشد (Python-Based Reinforcement Learning, Artificial Intelligence, and Neural Network). این کتابخانه، کتابخانه ای متن باز می باشد که مخصوصا برای شبکه های عصبی و آموزش بدون نظارت مورد استفاده قرار می گیرد.[16]
۳.۷. کتابخانه Gensim
کتابخانه Gensim یک کتابخانه برای مدل سازی موضوعی می باشد و بر روی Numpy و Scipy سوار می شود.[16]
۴. مجموعه داده
اکثر برنامه های پردازش زبا نهای طبیعی به یک پیش پردازش برای استخراج کلمات متن و تشخیص عبارات احتیاج دارند. هدف اصلی و نهایی قطعه بندی عبارات، به دست آوردن کلمات معنی دار همراه با پیشوندها و پسوندهایشان است و این فعالیت متناسب با زبان های طبیعی مختلف می تواند سخت یا آسان باشد. در زبان فارسی به علت وجود فاصله و نیم فاصله،عدم توجه کاربران به فاصله گذاری ها و نبود قواعد دقیق در نوشتن کلمات چندقسمتی، تشخیص و قطعه بندی کلمات چندقسمتی و مرکب با مشکلات و پیچیدگی های خاص خود روبه رو است.[18]
وجود رسم الخط های مختلف و سبک های نگارش متفاوت در زبان فارسی باعث شده فاصله، معیار قطعی و دقیقی برای تشخیص مرز کلمه نباشد. به طور کلی می توان گفت به تعداد افراد جامعه سبک های نگارش و رسم الخط های مختلف وجود دارد. دو نوع فاصله درون کلمه و برون کلمه در متون نوشتاری زبان فارسی وجود دارد که در متون تایپی به ترتیب از نیم فاصله و فاصله استفاده می شود. وجود این دو نوع فاصله گذاری باعث شده کلمه ای مانند "می رفت" را بتوان به سه صورت "می رفت"، "می رفت" و میرفت" نوشت.اکثر کاربران به فاصله گذاری ها توجه نمی کنند و همچنین قواعد دقیقی در نوشتن کلمات چندقسمتی وجود ندارد که باعث بروز مشکلات متعددی در قطعه بندی می شوند [ 17]. همچنین زبان فارسی میان اشکال ابتدایی،میانی و انتهایی اغلب حروف بر حسب موقعیت آنها در یک کلمه تمایز قائل می شود. از این روست که وجود یک تا چهار مدل مختلف برای کاراکترها، موجب پیچیدگی در تشخیص برخی کلمات می شود. از دیگر مشکلات می توان به حروف و کلمات واردشده از زبان عربی به زبان فارسی اشاره کرد. برای مثال صداهای همزه و تنوین باعث می شوند کلمات "پائیز" و "پاییز" یا "حتماً" و "حتما" به دو شکل نوشته شوند.[18]
از این رو بر آن شدیم تا فعلا داده های زبان انگلیسی را انتخاب کنیم و آن را مد نظر قرار دهیم .
داده های این مساله یک بخش بزرگ از جملات انگلیسی است که توسط Chelba و همکارانش تهییه شده است . که ما باید فقط جملات را در مجموعه آموزشی برای ساختن مدل مورد استفاده قرار دهیم.[1]
در این مجموعه داده یک کلمه از هر جمله در مجموعه آزمون حذف شده است .[1] مکان کلمه حذف شده به طور تصادفی به صورت یکنواخت انتخاب شد و هیچ وقت اولین و آخرین کلمه ی جمله نیست (در این مجموعه داده، آخرین کلمه همیشه یک دوره است).
شرح فایل train.txt - مجموعه آموزشی، حاوی مجموعه ای بزرگ از احکام انگلیسی است و test.txt - مجموعه تست، شامل تعداد زیادی جمله که از هر جمله ، یک کلمه حذف شده است.[1]
۵. پیاده سازی
در این پروژه با استفاده از فاصله لون اشتاین و ngram به پیاده سازی مساله پرداخته ایم . که فایل پیاده سازی شده در اینجا قرار داده شده است .
فایل قرار داده شده در گیت هاب شامل 2 بخش است :1- mainFile.py این بخش همان فایل اصلی است که در آن به پیاده سازی مساله ی یافتن جای خالی
پرداخته شده است .
2- فایل minitrain.txt که همان مجموعه داده ای است که در بالا ذکر کردیم اما به علت حجم بسیار زیاد آن مجموعه داده ، همه آن را استفاده نکردیم و تنها از بخشی از آن استفاده کردیم و فایل minitrain.txt شامل 87 جمله اول از فایل train.txt است .
۵.۱. روش پیاده سازی
چون ما میخواهیم جای خالی درون یک جمله را پیدا کنیم پس با دو مساله رو به رو هستیم . یکی پیدا کردن جای خالی به طور هوشمند و دومی یافتن کلمه مناسب برای پر کردن آن جای خالی .
پس یک جمله از مجموعه داده به عنوان ورودی از کاربر میگیریم که یک کلمه از آن حذف شده و آن را tokeninze میکنیم که برای هر پردازش متنی ، token کردن ضروری است
۵.۱.۱. جدا سازی متن یا Tokenization:
جداسازی متن یا Tokenization عبارت است از تقسیم بندی متن به واحد های کوچکتر که اغلب این واحدهای کوچک کلمات هستند. اما در برخی از موارد تعریف کلمه و محدوده آن عملی مشکل است. token واحدی ازمتن بوده که دارا خصوصیات زیر می باشد:
هر مجموعه از کاراکترهای پیوسته یک token می باشد. این کاراکترها حتی می توانند عدد نیز باشند.
محدوده یک token میتواند یک کاراکتر فضای خالی، کاراکتر انتهای خط و یا علامت گذاری های انتهای جمله باشد.
گاهی اوقات کاراکتر فضای خالی و علامت گذاری ها محدوده کلمه یا token نیستند.
که در این پروژه هر مجموعه از کاراکتر های پیوسته یک token است و مرز 2 token با فاصله مشخص میشود . سپس به وسیله ی الگوریتم ngram مجموعه ای از token ها یک ngram را میسازند . برای مثال در جمله" I love flower" جداسازی متن یا Tokenization برابر با موارد زیر میشود :
['I','love','flower]
و همچنین 2gram آن برابر با ['I love' , ' love flower] میشود .
که در این پروژه پس از چندین بار آزمایش به این نتیجه رسیدیم که 6gram نتیجه بهتری را به ما میدهد . نتایج آزمایش های قبلی بدین شرح است :
| n | نتیجه به درصد | تعداد کل آزمایش | تعداد نتایج غلط | تعدادنتایج درست |
|---|---|---|---|---|
| 3 | 16 | 10 | 9 | 1 |
| 5 | 60 | 10 | 4 | 6 |
| 6 | 80 | 10 | 2 | 8 |
پس از 6gram کردن جمله نوبت به انجام همین عمل روی جملات مجموعه داده یا همان فایل minitrain.txt است . یعنی ابتدا هر جمله آن را در نظر گرفته و آن را tokenize میکنیم سپس 6gram آن را میسازیم وبعد به سراغ مقایسه میرویم .
در مرحله مقایسه ، فاصله لون اشتاین تمام 6gram های جمله ای که کاربر وارد کرده محاسبه شده و همچنین فاصله لون اشتاین تمام 6gram های جمله اول در مجموعه داده محاسبه میشود .
سپس به مقایسه این فاصله ها میپردازیم و فاصله ای که کمتر از بقیه بود درون لیست میماند و بعد به سراغ مقایسه فاصله های لون اشتاین 6gram های جمله دوم با جمله ورودی میپردازیم و همینجور تا آخر ...
در نهایت 6gram ای که در لیست مانده به لیست نهایی اضافه میشوند . و در انتها 6gram های اضافی مثل جملاتی که دوبار تکرار شده اند ، حذف شده و جمله نهایی که جای خالی آن نیز پر شده نمایش داده میشود .
برای مثال در تصویر شماره 1 یک نمونه از اجرای برنامه است که در آن جمله ی "What a sobering contrast between the in Lebanon and the mood in Israel !" توسط کاربر وارد شده که کلمه ی celebrations از آن حذف شده و سپس برنامه ، این جمله را با افزودن کلمه ای که کاربر آن را حذف کرده، به جمله اصلی و در واقع ، یافتن جای خالی به صورت هوشمند و پرکردن آن با کلمه ی مناسب نمایش میدهد.

همچنین در تصویر شماره 2 کاربر جمله ی "Only now is the accelerating ." را وارد کرده که پس از تشخیص جای خالی و پر کردن آن جمله ی Only now is the Porsche accelerating . نمایش داده شده است .

۶. کار های آینده
بهتر است تا سایر الگوریتم ها را بررسی کرده و نتایج آن را با هم مقایسه کرده تا الگوریتم بهتر و کاراتری را بیابیم.
۷. مراجع
فهرست ارجاعات
[1] Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn: One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling, CoRR, 2013.
[2]Alex Minner : word2vec tutorial part 2 the continuous bag of word model,18 may 2015
[3] ngram مدل زبانی
[4]انواع مدل های زبانی
[5] word to vec توضیح الگوریتم
[6]روش های هموارسازی
[7]تاریخچه NLP
[8]مدل سازی آماری زبان
[9]Yoon Kim, New York University:Convolutional Neural Networks for Sentence Classification,October 25-29, 2014
[10]هفت نوع شبکه های عصبی مصنوعی برای پردازش زبان طبیعی
[11]معرفی شبکه ها برای اولین بار
[12]Understanding LSTM Networks
[13]برآورد موثر بازنویسی کلمه در فضای بردار
[14]آشنایی با پلتفرم nltk در پایتون
[15]How To Work with Language Data in Python 3 using the Natural Language Toolkit (NLTK)
[16]کتابخانه های مفید پایتون
[17] س. م. غفوری، س. راحتی، م. ر. پهلوان نژاد و ع. عظیمی زاده، "نرمال ساز متون فارسی،" پانزدهمین کنفرانس بین المللی سالانه انجمن کامپیوتر ایران، تهران، اسفند 1388.
[18]محمدمهدی میردامادی، علی محمد زارع بیدکی و مهدی رضائیان؛"قطعه بندی عبارات متون فارسی با استفاده از شبکه های عصبی"؛ نشریه مهندسی برق و مهندسی کامپیوتر ایران، ب- مهندسی کامپیوتر، سال 11 ، شماره 2، زمستان 1392.
[19] توضیح الگوریتم های ریشه یابی
[20]بررسی عملکرد موتور های جستجو
[21]فاصله لون اشتاین