به نام خدا
محیط Box2D یکی از قسمت های کتاب خانه Gym می باشد و بازی Bipedal Walker یکی از مساله طراحی شده در این محیط است.
هدف مساله راه رفتن عامل این بازی است. [1]
۱. مقدمه
اهمیت حل این مساله ، با توجه به کاربرد آن در دنیای واقعی روشن می شود.
بسیاری از روبات هایی که شبیه انسان ساخته می شوند ، به راهکاری برای راه رفتن نیاز دارند.[2]
حل مساله Bipedal Walker می توان گام مهمی برای پیدا کردن این راهکار باشد.

۲. توضیح مساله
۲.۱. بررسی محیط
محیط یک فضای دوبعدی ، پیوسته ، کاملا قابل مشاهده ، تک عاملی ، قطعی و ایستا می باشد.
۲.۲. بررسی عامل
یک متحرک دارای یک بدنه و دو پا که هر پا دارای دو مفصل و دو بازو می باشد.
متحرک توانایی کنترل چرخش مفاصل خود را دارد و هدف او راه رفتن می باشد.

۲.۳. فضای حالت
شامل ۱۴ آیتم می باشد که عبارت اند از:
Hull Angle (-PI,PI)
Hull Angular Velocity (-inf,inf)
Vel_X (-1,1)
Vel_Y (-1,1)
Hip Joint 1 Angle (-inf,inf)
Hip Joint 1 Speed (-inf,inf)
Knee Joint 1 Angle (-inf,inf)
Knee Joint 1 Speed (-inf , inf)
Leg 1 Ground Contact Flag : 0 or 1
Hip Joint 2 Angle (-inf,inf)
Hip Joint 2 Speed (-inf,inf)
Knee Joint 2 Angle (-inf,inf)
Knee Joint 2 Angle (-inf,inf)
Leg 2 Ground Contact Flag : 0 or 1
۲.۴. فضای رفتار
شامل ۴ آیتم می باشد که عبارت اند از:
Hip_1 (Torque / Velocity) (-1,1)
Knee_1 (Torque / Velocity) (-1,1)
Hip_2 (Torque / Velocity) (-1,1)
Knee_2 (Torque / Velocity) (-1,1)
۳. یادگیری تقویتی
۳.۱. معرفی
یادگیری تقویتی [3] بخشی از یادگیری ماشین است که در آن هر حالت به یک رفتار نظیر می شود و به دنبال رسیدن به بیشترین پاداش هستیم.
در این روش یادگیری بر اساس تجربه خود عامل شکل می گیرد.
این روش در مسائل با پیچیدگی بالا کاربرد فراوان دارد.
۳.۲. یادگیری Q
در این روش مقادیر Q را به دست می آوریم.[4]
در هر بار تجربه عامل مقادیر Q برای رفتار a و حالت s به روز می گردد.
مقدار پاداش (R) توسط Gym محاسبه می شود.
همچنین آلفا ضریب تاثیر مقادیر قبلی و گاما ضریب تخفیف می باشد.
۴. توضیح راه حل
۴.۱. محدود کردن حالت ها
با توجه به بزرگ بودن فضای حالت و همچنین بی نهایت بودن و پیوسته بودن بازه اکثر آیتم ها ، باید مقادیر آیتم ها را گسسته و کران دار کنیم.
مثلا تمام آیتم های پیوسته را به ۰.۲ تقسیم می کنیم و بعد از تقسیم مقادیر بیشتر یا مساوی از ۱۰ را ، ۱۰ در نظر می گیریم و مقادیر کمتر یا مساوی ۱۰- را ۱۰- در نظر می گیریم.
۴.۲. ساخت نام هر حالت
مقادیر محدود شده را با "#" به هم چسبانده و یک رشته مانند رشته مقابل می سازیم.
state : [ 3.45495224e-01 -9.15948486e-02 2.79675465e-01 -3.00369054e-03 -4.61687744e-01 7.27696717e-02 -4.03230309e-01 1.00020337e+00 0.00000000e+00 -8.34906638e-01 -5.19156456e-05 -2.93411493e-01 -4.95322347e-01 0.00000000e+00] ============> 1#0#1#0#-2#0#-2#10#0#-4#0#-1#-2#0#
۴.۳. محدود کردن رفتار ها
با توجه به بزرگ بودن فضای رفتار و همچنین پیوسته بودن بازه آیتم ها ، باید مقادیر آیتم ها را گسسته کنیم.
تمام آیتم ها را به ۰.۲۵ تقسیم می کنیم .
۴.۴. ساخت نام هر رفتار
مقادیر محدود شده را با "#" به هم چسبانده و یک رشته مانند رشته مقابل می سازیم.
action : [0.4, -0.4, 0.6, -0.2] ============> 1#-2#2#-1#
۴.۵. ساخت جدول سیاست
جدول سیاست در واقع یک دیکشنری است. کلید های این دیکشنری نام حالت هستند . هر نام حالت به یک دیکشنری برای رفتار ها ذخیره می شوند.
یک لیست شامل نام تمامی رفتار ها ساخته ایم و آن را لیست رفتار نام نهادیم.
کلید دیکشنری رفتار ، اندیس نام رفتار در لیست رفتار است. و ارزش آن همان Q است. بعد از هر بار تجربه این مقدار Q با توجه به فرمول زیر به روز می شود.
۵. چالش ها
۵.۱. پیوسته و بی کران بودن مقادیر
که همانطور که قبلا اشاره شد با تقسیم به اعداد کوچکتر از ۱ و ساخت رشته نام حالت ها و رفتار ها مشکل را برطرف کردیم.
۵.۲. اشغال فضای زیاد در حافظه
در ابتدا به جای دیکشنری رفتار ، از یک لیست به اندازه لیست رفتار استفاده شد که هر عضو آن مقدار Q مربوط به رفتار متناظر در لیست رفتار را نگهداری می کرد.
مزیت این پیاده سازی دسترسی سریعتر به مقادیر بود. ولی عیب آن اشغال فضای بسیار بالا در حافظه و پر شدن سریع حافظه بود.
برای مثال در هر ثانیه تقریبا ۱ مگابایت فضا اشغال می کرد.
بعدا این لیست با دیکشنری رفتار جایگزین شد. با اینکه سرعت دسترسی به اطلاعات کمتر شد ولی در مصرف حافظه صرفه جویی کردیم.
برای مثال بعد از تقریبا ۲۰ ساعت یادگیری تنها ۱۲۰ مگابایت حافظه اشغال شد.
۵.۳. یادگیری تکراری و بیش از حد حالات آموخته شده
بعد از گذشت مدت زیادی از یادگیری هنوز عامل بسیاری از حالات ساده را یاد نگرفته بود.
برای رفع این مشکل علاوه بر استفاده از ضریب شانس و انتخاب رفتار تصادفی راه حل زیر نیز به کار گرفته شد :
مقادیر miss و hit را برای رفتار ها و حالت ها اندازه گیری کردیم.
مثلا هر بار که به یک حالت جدید می رسیدیم ، مقدار state miss را یکی زیاد می کردیم و لی اگر این حالت را قبلا تجربه کرده بودیم ، مقدار state hit را یکی افزایش می دادیم.
متغیر Hit Ratio درصد برد است که هر چه بالاتر باشد به معنای کامل تر بودن یادگیری است. برای رفع مشکل یادنگرفتن بعضی حالات ساده این متغیر را محاسبه کردیم.
مشاهده شد که در بعضی حالات این مقدار بسیار زیاد - نزدیک ۹۵ درصد - و در بعضی حالات کم - نزدیک ۷۰ درصد - می باشد.
هم چنین در حالت هایی که کمتر تجربه شده اند مقدار Hit Ratio برای رفتار ها نزدیک ۳۰ درصد بود.
به این صورت توانستیم حالات پر تکرار را شناسایی کنیم و با ضافه کردن یک عبارت شرطی زمانی که آن ها را مشاهده می کردیم روند یادگیری را متوقف نموده و از ابتدا آغاز می کردیم تا حالت هایی که کمتر تجربه شده بودند ، اولویت یابند.
۵.۴. یادگیری کُند
با توجه به بزرگ بودن فضای حالت ، همچنان یادگیری سرعت کمی دارد.
برای کمک به روند یادگیری از یک سیاست درست و ثابت استفاده کردیم.
قطعه کدی [5] را استفاده کردیم که با استفاده از شرط های زیاد و پیچیده ، برای هر حالت یک رفتار تولید می کند و عامل با استفاده از آن رفتار ها می تواند به شیوه خوبی راه برود. با کمک این کد یادگیری را آغاز کردیم و عامل به جای مراجعه به جدول ، از این کد کمک می گرفت و رفتار را انتخاب می کرد. بعد از انجام رفتار و دریافت پاداش ، جدول بروزرسانی می شد. می توان گفت این کار نوعی یادگیری منفعلانه می باشد.
۶. راه حل های دیگر
۶.۱. یادگیری عمیق-تقویتی
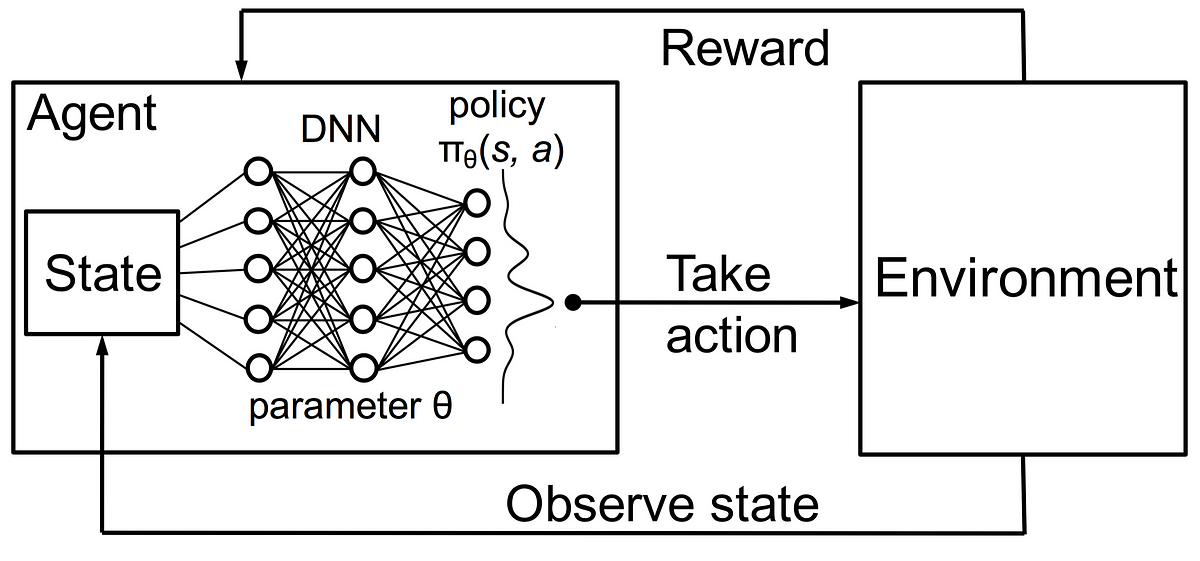
یادگیری عمیق-تقویتی [6] ترکیبی از یادگیری عمیق و یادگیری تقویتی می باشد. این روش می تواند مسائل نسبتا پیچیده را به راحتی حل کند. برای مثال ما صفحه بازی را در اختیار یک شبکه عصبی قرار می دهیم. در پایان این شبکه برای ما یک رفتار تعیین می کند. با اجرای این رفتار ما پاداش را بدست می آوریم و با استفاده از آن وزن های شبکه عصبی را بروزرسانی می کنیم.
۶.۲. الگوریتم های POET
الگوریتم های Paired Open-Ended Trailblazer که به اختصار POET خوانده می شوند[7] ساخته آزمایشگاه هوش مصنوعی Uber هستند که در طول تحقیقاتشان ، نتایج را روی Bipedal Walker نیز اعمال کرده اند .

۷. مراجع:
Our Code In GitHub
[1] https://gym.openai.com/envs/BipedalWalker-v2/
[2] https://www.bostondynamics.com/atlas
[3] https://medium.freecodecamp.org/an-introduction-to-reinforcement-learning-4339519de419
[4] https://medium.freecodecamp.org/diving-deeper-into-reinforcement-learning-with-q-learning-c18d0db58efe
[5] https://github.com/openai/gym/blob/master/gym/envs/box2d/bipedal_walker.py از خط ۵۰۶ تا آخر
[6] https://skymind.ai/wiki/deep-reinforcement-learning
[7] https://arxiv.org/abs/1901.01753