طراحی سیستم تخمین قیمت مسکن در تهران تا هم فروشنده از قیمت حدودی ملک خود آگاه شود و هم خریدار بازه ی قیمت مسکن مورد نظرش را بداند
۱. مقدمه
خرید و فروش مسکن در شهر های بزرگ و پرجمعیت همیشه بازار پررونقی داشته اگر تجربه خرید و فروش در این بازار را داشته باشید متوجه میشوید که
قیمت نهایی خانه ها وابسته به عوامل زیادی فراتر از متراژ خانه است و تخمین قیمت هر خانه نیازمند آگاهی دقیق و تجربه بالا است.
در این مقاله سعی شده تا با استفاده از اطلاعات جمع آوری شده و استفاده از پارامترهای مختلف از قبیل متراژ و طبقه و محله و ... به تخمین قیمت هر واحد مسکونی پرداخته شود.
تخمین قیمت با استفاده از این متغیرات نیاز به تجربه زیادی دارد که نیازمند سال های بسیار کار در این زمینه است ولی این مقاله سعی دارد که کامپیوتر با استفاده ازالگوریتم های یادگیری ماشین 1 به تخمین قیمت مسکن همانند یک دلال حرفه ای مسکن بپردازد.
۱.۱. رگرسیون
حل مسئلههای تخمین با یادگیری ماشین و عموماً مسائلی که در آن داده های قبلی وجود دارد که ماشین توسط آن داده قبلی ردیف های بعدی را تخمین میزند معمولا با الگوریتم های پسرفتی یا regression انجام می گیرد.
پسرفتی یا regression چیست؟!در الگوریتم های regression ماشین داده های قبلی را تحلیل کرده و توسط آن مدلی میسازد و الگو را یاد می گیرد، سپس توسط آن مدل با احتمال خوبی داده های بعدی را تخمین می زند. به طور ساده regression یک ابزاری یادگیری ماشین است که کمک میکنند با یادگیری روابط بین متغیر هدف (خروجی) و متغیرهای دیگر (ورودی) - که از داده های آماری قبلی به دست آمده -را پیشبینیکنیم.با این تعریف متغیر هدف ما که قیمت مثلا یک خانه است به متغیرهای دیگری همچون تعداد اتاق ها، متراژ، همسایگی آن خانه، منطقه و ... بستگی دارد. اگر ما یادگیری ماشین را به این متغیر ها اعمال کنیم میتوانیم ارزش یک خانه را در یک منطقه جغرافیایی مشخص محاسبه کنیم.عملکرد پسرفت ساده است : توسط داده های قبلی کافیست رابطه بین متغیر هدف و متغیرهای دیگر را پیدا کرده و این رابطه را در داده های مشاهده شده واقعی اعمال می کنیم.برای اینکه نشان بدهیم پسرفت چگونه کار می کنند مثالی ساده می زنیم :در محاسبه قیمت یک ملک (متغیر هدف) فقط یک متغیر را در نظر می گیریم و آن هم مساحت آن خانه است (متغیر های دیگر).منطقی است که قیمت خانه ها رابطهی خطی با مساحت دارند. پس :y = k0 + k1 * xکه در آن y قیمت ملک و x مساحت آن است.حال کافیست با استفاده از الگوریتم های regression ضرایب k0 و k1 را بدست بیاوریم و در پیشبینی بعدی از آن استفاده کنیم.
۱.۲. شبکه عصبی
شبکههای عصبی مصنوعی یا شبکههای عصبی صناعی 2 یا به زبان سادهتر شبکههای عصبی سیستمها و روشهای محاسباتی نوین برای یادگیری ماشینی و در انتها اعمال دانش به دست آمده در جهت بیشبینی پاسخهای خروجی از سامانههای پیچیده هستند. ایدهٔ اصلی این گونه شبکهها تا حدودی الهامگرفته از شیوهٔ کارکرد سیستم عصبی زیستی برای پردازش دادهها و اطلاعات( به منظور یادگیری و ایجاد دانش قرار دارد. عنصر کلیدی این ایده، ایجاد ساختارهایی جدید برای سامانهٔ پردازش اطلاعات است.
این سیستم از شمار زیادی عناصر پردازشی فوقالعاده بهمپیوسته با نام نورون تشکیل شده که برای حل یک مسئله با هم هماهنگ عمل میکنند و توسط سیناپسها ارتباطات الکترومغناطیسی) اطلاعات را منتقل میکنند. در این شبکهها اگر یک سلول آسیب ببیند بقیه سلولها میتوانند نبود آن را جبران کرده، و نیز در بازسازی آن سهیم باشند. این شبکهها قادر به یادگیریاند. مثلاً با اعمال سوزش به سلولهای عصبی(لامسه، سلولها یادمیگیرند که به طرف جسم داغ نروند و با این الگوریتم سیستم میآموزد که خطای خود را اصلاح کند. یادگیری در این سیستمها به صورت تطبیقی صورت میگیرد، یعنی با استفاده از مثالها وزن سیناپسها به گونهای تغییر میکند که در صورت دادن ورودیهای جدید، سیستم پاسخ درستی تولید کند
۲. کارهای مرتبط
با استفاده ازالگوریتم های یادگیری ماشین و الگوریتم های رگرسیون SVM , PLS و LSSVM اقدام به تخمین قیمت کرده است [1]
با استفاده از الگوریتم های SVP و Random forest قصد پیاده سازی سیستم تخمین قیمت مسکن کرده اند.[2]
۳. آزمایشها
برای حل این مساله از شبکه های عصبی مصنوعی استفاده شده و برای اندازه گیری دقت هر کدام از ازمایش ها, MAE , MAPE و MSE اندازه گیری می شوند. شرح آزمایش ها به صورت زیر است:
۳.۱. شبکه کم لایه سبک
| MAPE | MSE | MAE |
|---|---|---|
| 0.101 | 0.045 | 34.297 |
۳.۲. شبکه چندلایه سنگین
| MAPE | MSE | MAE |
|---|---|---|
| 0.098 | 0.064 | 31.326 |
۳.۳. شبکه کم لایه سنگین
| MAPE | MSE | MAE |
|---|---|---|
| 0.107 | 0.053 | 36.672 |
۳.۴. شبکه چندلایه سبک
| MAPE | MSE | MAE |
|---|---|---|
| 0.107 | 0.055 | 40.374 |
۴. نمونه
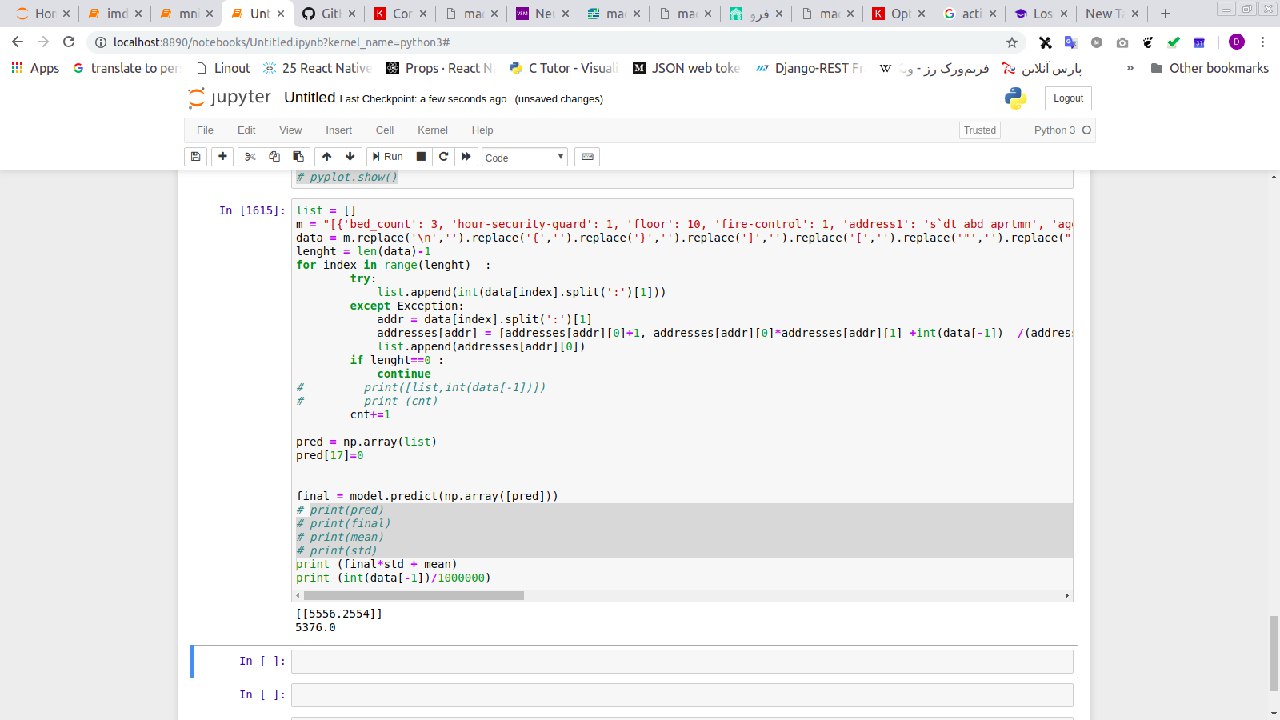
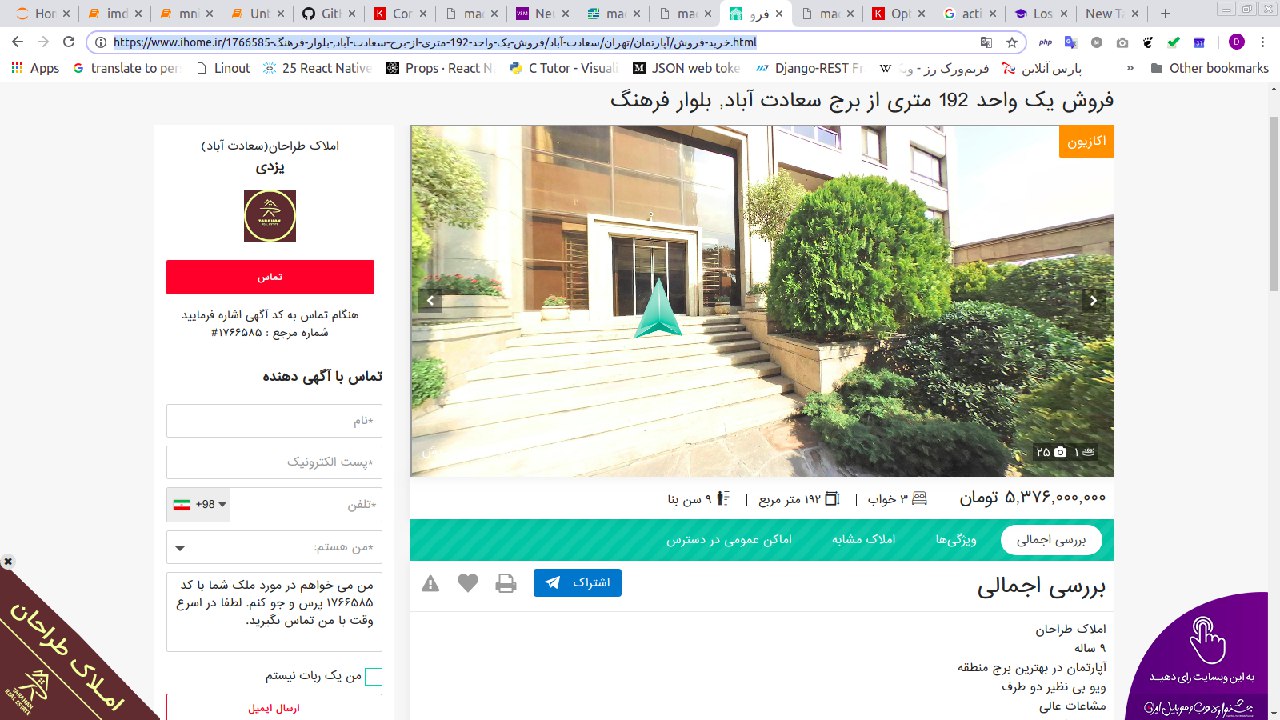
در تصاویر بالا قیمت موجود در سایت و مقدار تخمین زده شده توسط سیستم قابل مشاهده است
۴.۱. ماژول های استفاده شده
keras
numpy
tensorFlow
۵. چالش ها
۵.۱. مسایل
۵.۱.۱. ساخت شبکه مناسب
انتخاب شبکه مناسب با اندازه و نوع شبکه لازمه اجرای دقیق تخمین است
۵.۱.۲. انتخاب سایز epoch و batch
سایز ها در زمان تمرین و دقت سیستم بسیار تاثیر دارند و میتوانند مانع overfitting شوند
۵.۱.۳. ساختن دیتاست دنیای واقعی
دیتا ست های موجود در سایت های مختلف کاملا مشخص و از قبل حل شده اند سعی کردیم که مساله ای در سطح دنیای واقعی پیاده سازی کنیم
۵.۲. نکات راهگشا
۵.۲.۱. در اکثر سوالات رگرسیون ۲ لایه میانی برای جواب کافی است
۵.۲.۲. تعداد نورون ها در لایه های میانی نباید از تعداد نورون های ورودی بیشتر باشد
۵.۲.۳. اساس عملکرد optimizer ها و تاثیر آنها بر روند تمرین داده
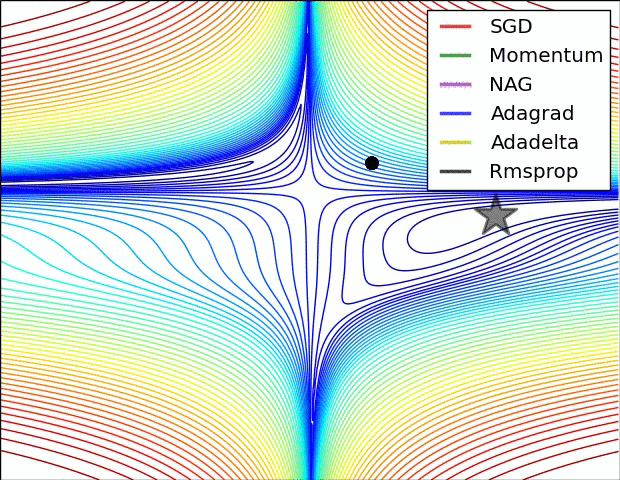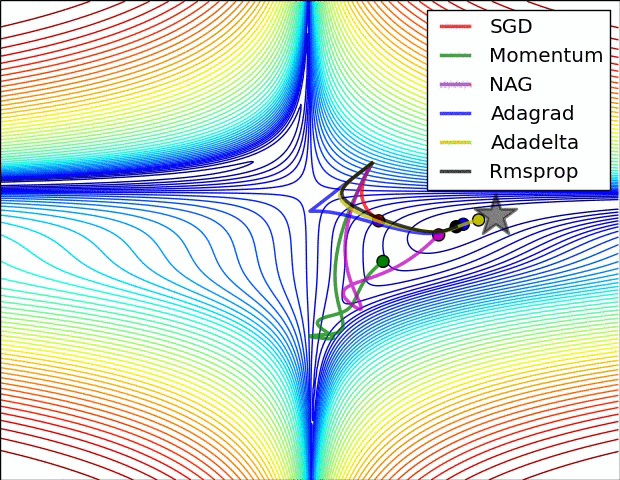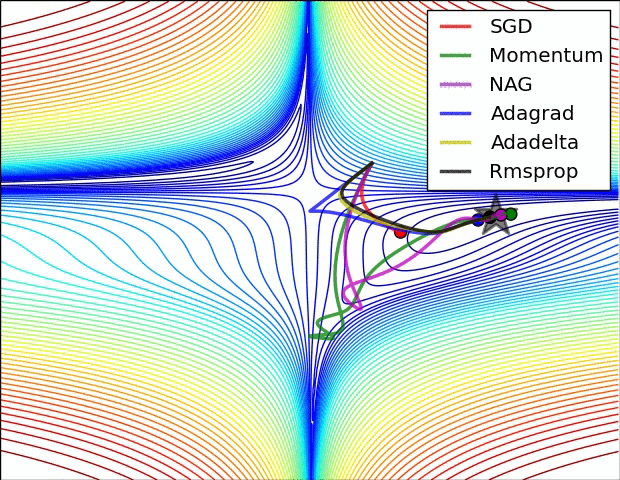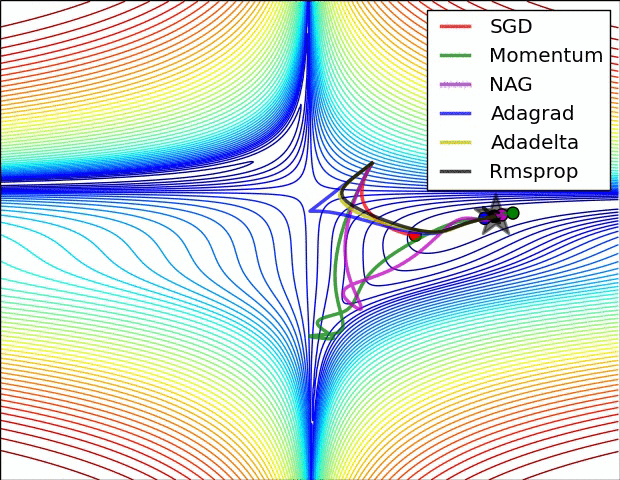
با توجه به نمودار بالا بهینه گر 3 RMSPROP مورد انتخاب ما بود
۶. دیتاست 4
دیتاست استفاده شده در پروژه حاصل scrapper برروی سایت ihome) است و اطلاعات از این سایت جمع اوری شده
و سپس پس از پردازش 5و تبدیل هر یک از مشخصه ها به عدد به شبکه ورودی داده شده است
از جمله داده مورد های پردازش شده این است که در این دیتاست با توجه به محله مسکن مورد نظر میانگین قیمت واحد متر مربع آن محاسبه شده و به جای ادرس آن مورد قرار میگیرد
۷. کارهای آینده
۷.۱. جمع آوری دیتاست
دیتاست جمع آوری شده باید گسترش داد و از چندین منبع استفاده کرد
۷.۲. بهبود مدل شبکه
مدل استفاده شده نهایی قابل بهبود است تا نتایج بهتری به دست آید
۸. مراجع
[1] Predicting house prices using Ensemble Learning with Cluster Aggregations Johan Oxenstierna
[2] Housing Value Forecasting Based on Machine Learning Methods Jingyi Mu,1Fang Wu,2and Aihua Zhang
.
Machine Learning
Artificial Neural Network
optimizer
Dataset
Process