۱. بازی تانک
در این پروژه که پیاده سازی عامل هوشمند بازی تانک با استفاده از یادگیری تقویتی نام دارد، بازی Tanks که به صورت Open Source در مخازن Unity موجود است را انتخاب شده که در ادامه به شرح توضیحات پیرامون بازی پرداخته شده است.
بازی در قالب موتور بازی سازی Unity پیاده سازی شده است.


در این بازی که یک نمای کلی از آن در تصویر بالا مشخص شده است، محیط بازی 3 بعدی است و 2 تانک می توانند آزادانه در آن حرک کنند و به سمت هم شلیک کنند و رقیب خود را از میدان خارج کنند. محیط کلی بازی 3 بعدی است ولی در واقع ما با یک محیط 2 بعدی سر و کار داریم. چون حرکت تانک ها فقط در دو جهت X و Z انجام می پذیرد. تنها حرکت 3 بعدی در این بازی، حرکت توپ شلیک شده از تانک است که آن هم در کنترل ما نیست.
۱.۱. حرکت تانک ها
هر تانک دارای یک موقعیت با مولفه های X و Z است که مقادیر آن ها پیوسته و در حوزه اعداد حقیقی است. پس در کل فقط مکان ها و حرکت های در راستای X و Z برای ما اهمیت دارند.

کد مربوط به حرکت هر تانک به شرح زیر است:
using UnityEngine;
namespace Complete{
public class TankMovement : MonoBehaviour {
public int m_PlayerNumber = 1;
public float m_Speed = 12f;
public float m_TurnSpeed = 180f;
public AudioSource m_MovementAudio;
public AudioClip m_EngineIdling;
public AudioClip m_EngineDriving;
public float m_PitchRange = 0.2f;
private string m_MovementAxisName;
private string m_TurnAxisName;
private Rigidbody m_Rigidbody;
private float m_MovementInputValue;
private float m_TurnInputValue
private float m_OriginalPitch;
private ParticleSystem[] m_particleSystems;
private void Awake (){
m_Rigidbody = GetComponent<Rigidbody> ();
}
private void OnEnable (){
m_Rigidbody.isKinematic = false;
m_MovementInputValue = 0f;
m_TurnInputValue = 0f;
m_particleSystems = GetComponentsInChildren<ParticleSystem>();
for (int i = 0; i < m_particleSystems.Length; ++i)
{
m_particleSystems[i].Play();
}
}
private void OnDisable (){
m_Rigidbody.isKinematic = true;
for(int i = 0; i < m_particleSystems.Length; ++i){
m_particleSystems[i].Stop();
}
}
private void Start(){
m_MovementAxisName = "Vertical" + m_PlayerNumber;
m_TurnAxisName = "Horizontal" + m_PlayerNumber;
m_OriginalPitch = m_MovementAudio.pitch;
}
private void Update(){
m_MovementInputValue = Input.GetAxis (m_MovementAxisName);
m_TurnInputValue = Input.GetAxis (m_TurnAxisName)
EngineAudio ();
}
private void EngineAudio (){
if (Mathf.Abs (m_MovementInputValue) < 0.1f &&
Mathf.Abs (m_TurnInputValue) < 0.1f){
if (m_MovementAudio.clip == m_EngineDriving){
m_MovementAudio.clip = m_EngineIdling;
m_MovementAudio.pitch = Random.Range (m_OriginalPitch - m_PitchRange,
m_OriginalPitch + m_PitchRange);
m_MovementAudio.Play ();
}
}else{
if (m_MovementAudio.clip == m_EngineIdling){
m_MovementAudio.clip = m_EngineDriving;
m_OriginalPitch + m_PitchRange);
m_MovementAudio.Play();
}
}
}
private void FixedUpdate (){
Move ();
Turn ();
}
private void Move(){
Vector3 movement = transform.forward * m_MovementInputValue *
m_Speed * Time.deltaTime;
m_Rigidbody.MovePosition(m_Rigidbody.position + movement);
}
private void Turn (){
float turn = m_TurnInputValue * m_TurnSpeed * Time.deltaTime;
Quaternion turnRotation = Quaternion.Euler (0f, turn, 0f);
m_Rigidbody.MoveRotation (m_Rigidbody.rotation * turnRotation);
}
}
}
۱.۲. سلامتی تانک ها
هر تانک همچنین دارای یک مشخصه سلامتی است که بازه مقدار آن از صفر تا 100 است. در شروع بازی تانک در حالت سلامتی کامل ( یعنی مقدار 100 قرار دارد ). و با برخورد هر توپ شلیک شده به تانک ها، بسته به موقعیت فرود توپ، مقداری از سلامتی تانک کم می شود و هرگاه این مقدار به صفر برسد، تانک از بین می رود و حریف به عنوان برنده اعلام می شود.

کد مربوط به سلامتی تانک ها به صورت زیر است:
using UnityEngine;using UnityEngine.UI;
namespace Complete{
public class TankHealth : MonoBehaviour{
public float m_StartingHealth = 100f;
public Slider m_Slider;
public Image m_FillImage;
public Color m_FullHealthColor = Color.green;
public Color m_ZeroHealthColor = Color.red;
public GameObject m_ExplosionPrefab;
private AudioSource m_ExplosionAudio;
private ParticleSystem m_ExplosionParticles;
private float m_CurrentHealth;
private bool m_Dead;
private void Awake(){
m_ExplosionParticles = Instantiate (m_ExplosionPrefab)
.GetComponent<ParticleSystem> ();
m_ExplosionAudio = m_ExplosionParticles.GetComponent<AudioSource> ();
m_ExplosionParticles.gameObject.SetActive (false);
}
private void OnEnable(){
m_CurrentHealth = m_StartingHealth;
SetHealthUI();
}
public void TakeDamage (float amount){
m_CurrentHealth -= amount;
SetHealthUI ();
if (m_CurrentHealth <= 0f && !m_Dead){
OnDeath ();
}
}
private void SetHealthUI(){
m_Slider.value = m_CurrentHealth;
m_FillImage.color = Color.Lerp (m_ZeroHealthColor, m_FullHealthColor
, m_CurrentHealth / m_StartingHealth);
}
private void OnDeath(){
m_Dead = true;
m_ExplosionParticles.transform.position = transform.position;
m_ExplosionParticles.gameObject.SetActive (true);
m_ExplosionParticles.Play ();
m_ExplosionAudio.Play();
gameObject.SetActive (false);
}
}
}
۱.۳. شلیک تانک ها
هر تانک می تواند به صورت متوالی و با یک فاصله زمانی مشخص اقدام به شلیک توپ کند. 2 مولفه در شلیک و حرکت توپ موثر هستند که شامل جهت شلیک ( یعنی همان جهت تانک در لحظه شلیک ) و شدت شلیک ( که توسط بازیکن و به میزانی که دکمه شلیک را نگه دارد ) می شود. شدت شلیک توپ دارای یک بازه مشخص است و این یعنی که قدرت شلیک نمی تواند از حدی کمتر و یا تا هر مقدار دلخواه زیاد باشد.


اصابت هر توپ به تانک و به هر سطح دیگر در نزدیکی تانک منجر به آسیب دیدن تانک می شود. حال تفاوتی نمی کند که توپ توسط خود بازیکن و یا توسط رقیبش شلیک شده باشد. پس شلیک توپ به سمت دیوار و یا هر سطح دیگر نزدیک تانک منجر به آسیب دیدن خودش می شود و تکرار ین حرکات اشتباه می تواند منجر به مرگ تانک بدون دخالت حریفش شود.

using UnityEngine;
using UnityEngine.UI;namespace Complete{
public class TankShooting : MonoBehaviour{
public int m_PlayerNumber = 1;
public Rigidbody m_Shell;
public Transform m_FireTransform;
public Slider m_AimSlider;
public AudioSource m_ShootingAudio;
public AudioClip m_ChargingClip;
public AudioClip m_FireClip;
public float m_MinLaunchForce = 15f;
public float m_MaxLaunchForce = 30f;
public float m_MaxChargeTime = 0.75f;
private string m_FireButton;
private float m_CurrentLaunchForce;
private float m_ChargeSpeed;
private bool m_Fired;
private void OnEnable(){
m_CurrentLaunchForce = m_MinLaunchForce;
m_AimSlider.value = m_MinLaunchForce;
}
private void Start (){
m_FireButton = "Fire" + m_PlayerNumber;
m_ChargeSpeed = (m_MaxLaunchForce - m_MinLaunchForce) / m_MaxChargeTime;
}
private void Update(){
m_AimSlider.value = m_MinLaunchForce;
if (m_CurrentLaunchForce >= m_MaxLaunchForce && !m_Fired){
m_CurrentLaunchForce = m_MaxLaunchForce;
Fire ();
}else if (Input.GetButtonDown (m_FireButton)){
m_Fired = false;
m_CurrentLaunchForce = m_MinLaunchForce;
m_ShootingAudio.clip = m_ChargingClip;
m_ShootingAudio.Play();
}
else if (Input.GetButton (m_FireButton) && !m_Fired){
m_CurrentLaunchForce += m_ChargeSpeed * Time.deltaTime;
m_AimSlider.value = m_CurrentLaunchForce;
}
else if (Input.GetButtonUp (m_FireButton) && !m_Fired){
Fire();
}
}
private void Fire (){
m_Fired = true;
Rigidbody shellInstance = Instantiate (m_Shell, m_FireTransform.position,
m_FireTransform.rotation) as Rigidbody;
shellInstance.velocity = m_CurrentLaunchForce * m_FireTransform.forward;
m_ShootingAudio.clip = m_FireClip;
m_ShootingAudio.Play ();
m_CurrentLaunchForce = m_MinLaunchForce;
}
}
}
۱.۴. مدیریت روند بازی
بازی در قالب راند های متوالی انجام می شود. در هر راند 2 تانک در موقعیت ابتدایی که از پیش برایشان تعریف شده ، با سلامتی کامل ، قرار میگیرند. و پس از چند لحظه که شماره راند نمایش داده شد، مبارزه آغاز می شود. تا قبل از لحظه شروع هیچ بازیکنی قادر به کنترل تانک خود نیست. در طول راند تانک ها با یکدیگر میجنگند و هرگاه هر یک از تانک ها حریف خود را از میان ببرد ، به عنوان برنده راند شناخته می شود و به امتیازش یک واحد اضافه میشود. در پایان هر راند هم به مدت چند ثانیه نام برنده و مجموع امتیازات 2 بازیکن نمایش داده می شود.


ممکن است که نتیجه نهایی یک راند به صورت مساوی ( Draw ) اعلام شود که این موضوع در دو حالت می تواند رخ دهد.
زمانی که هیچ تانکی در مدت زمان مشخص شده برای هر راند موفق یه پیروزی نشود.
زمانی که بلافاصله پس از مرگ یک تانک و تا زمانی که برنده اعلام می شود، تانک دیگر نیز به هر دلیلی از بین برود.

نمایی از بازی پس از مساوی شدن راند به دلیل از بین رفتن هر دو تانک
۲. هوشمند سازی بازی
تا این جا با مشخصات کلی بازی آشنا شدیم. تلاش ما در این پروژه برای هوشمند سازی بازی بوده است تا بازی بدون دخالت عامل انسانی انجام شود و عامل با هوش تر بتواند با انتخاب تصمیم های بهتر و اجرای آن ها پیروز شود.
برای این کار ، درست مشابه هر بازی دیگری که دارای هوش مصنوعی است ، نیاز به انجام یک سری وظایف به طور مرتب و دقیق است که پیاده سازی آن ها بر عهده ما بوده است.
۲.۱. مشاهده شرایط بازی و دریافت حالت کلی بازی
اولین کاری که باید صورت گیرد ، مشاهده شرایط و حالت بازی ( Observation ) است. در این مرحله ما اطلاعاتی کاربردی مانند موقعیت تانک بازیکن، موقیعت تانک حریف، شرایط سلامتی تانک بازیکن، جهت قرار گیری تانک بازیکن و ... را مشاهده و ضبط میکنیم.
۲.۲. تصمیم گیری و انجام اقدام مناسب
پس از انجام مرحله بالا، یعنی مشاهده حالت بازی، تانک بازیکن باید با توجه به شرایطی که مشاهده کرده است تصمیم گیری کند و کار درست را انجام دهد. در اینحا منظور از کار درست ، کاری است که منجر کسب بیشترین پاداش ( Reward ) شود.
با توجه به مشخصات بازی ، هر بازیکن می تواند 3 نوع کار مختلف را انجام دهد:
حرکت به سمت جلو یا عقب
چرخش به سمت چپ یا راست
شلیک توپ با شدت مناسب
دقت کنیم که در حالت غیر هوشمند و یا با حضور بازیکنان ، مراحل بالا توسط بازیکنان به صورت خودکار انجام می شود. هر چند آن ها دقیقا از انجام این پروسه آگاه نباشند.
۳. معرفی ML Agents
َبرای هوشمند سازی بازی از کتابخانه قدرتمند و جامع ML Agents که به صورت Open Source در اختیار توسعه دهندگان قرار داده شده است استفاده شده است. در ادامه گزارش به معرفی و شرح مختصر مشخصات این کتابخانه می پردازیم. اما برای مشاهده اطلاعات کامل تر میتوانید به لینک مخزن این کتابخانه در GitHub مراجعه نمایید : ML Agents
ابزار یادگیری ماشینی یونیتی یک افزونه متن باز است که بازی ها و شبیه سازی را به محیطی برای آموزش عامل های هوشمند تبدیل می کند. عامل ها می توانند با استفاده از الگوریتم های مختلفی مانند یادگیری تقویتی ، یادگیری تقلیدی ، شبکه عصبی و...با استفاده از یک API پایتون آموزش ببینند.
۳.۱. خصیصه های محیط در ML Agents
آموزش با استفاده از ML Agentsمی تواند به صورت های مختلفی انجام شود اما ایده کلی به این صورت است که در هر لحظه سه خصیصه (محیط) را مشخص کنیم :
مشاهده: مشاهد عامل می تواند به صورت دیداری یا عددی باشد. در مشاهده های عددی مقدار ویژگی ها از دید عامل اندازگیری می شود. مشاهده های دیداری عکس های از دید دوربین ها تولید می شود و دیده های عامل در هر لحظه گزارش می شود. برای مثال در عامل تانک در هر لحظه موقعیت خود ، موقعیت حریف ، مقدار سلامتی خود ، مقدار سلامتی حریف و محل توپ ها را به صورت داده های عددی دریافت می کند.
عمل : عملیات هایی که عامل می تواند در هر لحظه انجام دهد که می تواند به صورت پیوسته یا گسسته باشند. در محیط آموزشی تانک ها می تواند عمل های به جلو یا عقب رفتن ، چرخیدن و شلیک کردن را اجرا نمایند.
پاداش : یک مقدار عددی که نشان دهنده این است که عامل به چه اندازه عملکرد خوب یا بدی دارد.
۳.۲. آموزش عامل
پس از مشخص کردن این سه خصیصه می توان عامل را با انجام آزمایش های متعدد برای یافتن عمل های بهینه برای بیشینه کردن مقدار پاداش در آزمایش های بعدی انجام داد و نکته مهم در اینجا این است که عامل با بیشینه کردن مقدار پاداش خود در هر آزمایش نحوه رفتار در محیط را می آموزد. در یادیگری تقویتی رفتار آموخته شده را سیاست می نامند که به بیان ساده می توان آن را نسبت دادن مشاهده ها به عمل ها معرفی کرد.
۳.۳. اجزای کلیدی
افزونه ML Agents دارای سه بخش کلیدی است:
عامل ها : عامل ها به شی ای که نقش تولید مشاهده ها و انجام عملیات ها و دریافت پاداش را دارد متصل می شود. در محیط ما عامل ها به تانک ها متصل شده اند.
مغز ها : مغزها قسمتی هستند که منطق تصمیم گیری در آن قرار دارد. به این صورت که در هر مغز سیاست برای هر عامل مشخص می شود و هر عامل در برگیرنده یک مغز است. به صورت دقیق تر این جز مشاهده ها و پاداش ها را دریافت میکند و عمل را به عامل بر میگرداند.
آکادمی : آکادمی نقش راه اندازی علمیات مشاهده و تصمیم گیری را به عهده دارد. در هر آکادمی پارامتر های محیط میتواند مشخص شود.
در هر محیط بازی یک آکادمی و چندین عامل که هر یک به یک عامل متصل شده اند وجود دارد و همچنین این امکان وجود دارد که عامل هایی که مشاهده و عمل های یکسانی دارند به یک مغز متصل شوند.
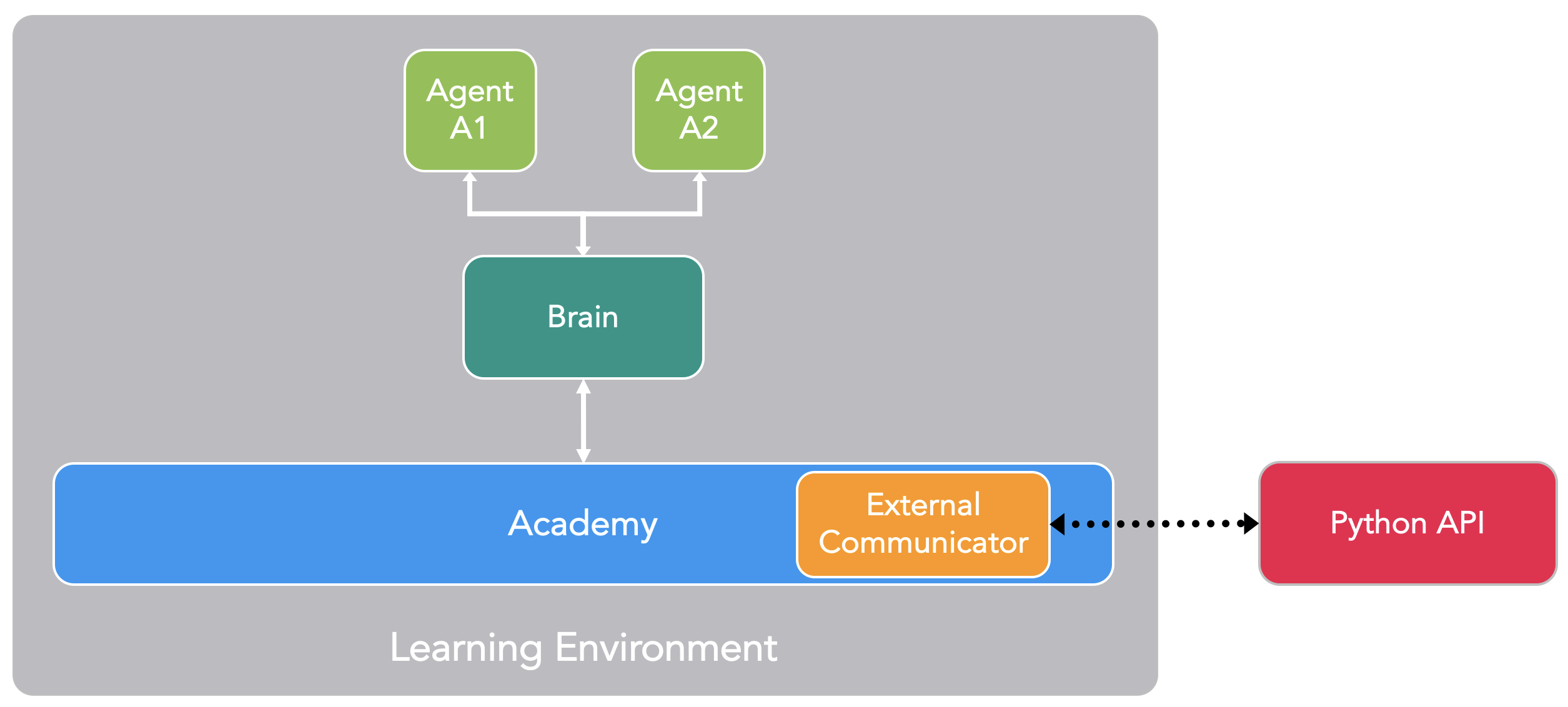
اجزای تشکیل دهنده ML Agents
۳.۴. مغز ها چگونه عامل ها را کنترل می کنند؟
درعمل سه نوع مغز وجود دارد:
یادگیری : در این حالت تصمیم ها با استفاده از یک مدل جا سازی شده TensorFlow گرفته می شوند به این صورت که مدل TensorFlow نشان دهنده سیاست های آموخته شده است و مغز به صورت مستقیم از این مدل برای تصمیم گیری استفاده می کند.
بازیکن : در این حالت وردی از صفحه کلید دریافت می شود و یک بازیکن هدایت عامل را بر عهده دارد و مشاهده و پاداش های دریافت شده برای هدایت عامل استفاده نمی شوند.
ابتکاری : در این حالت تصمیم گیری ها با استفاده از رفتارهای از پیش کد شده انجام می شوند.
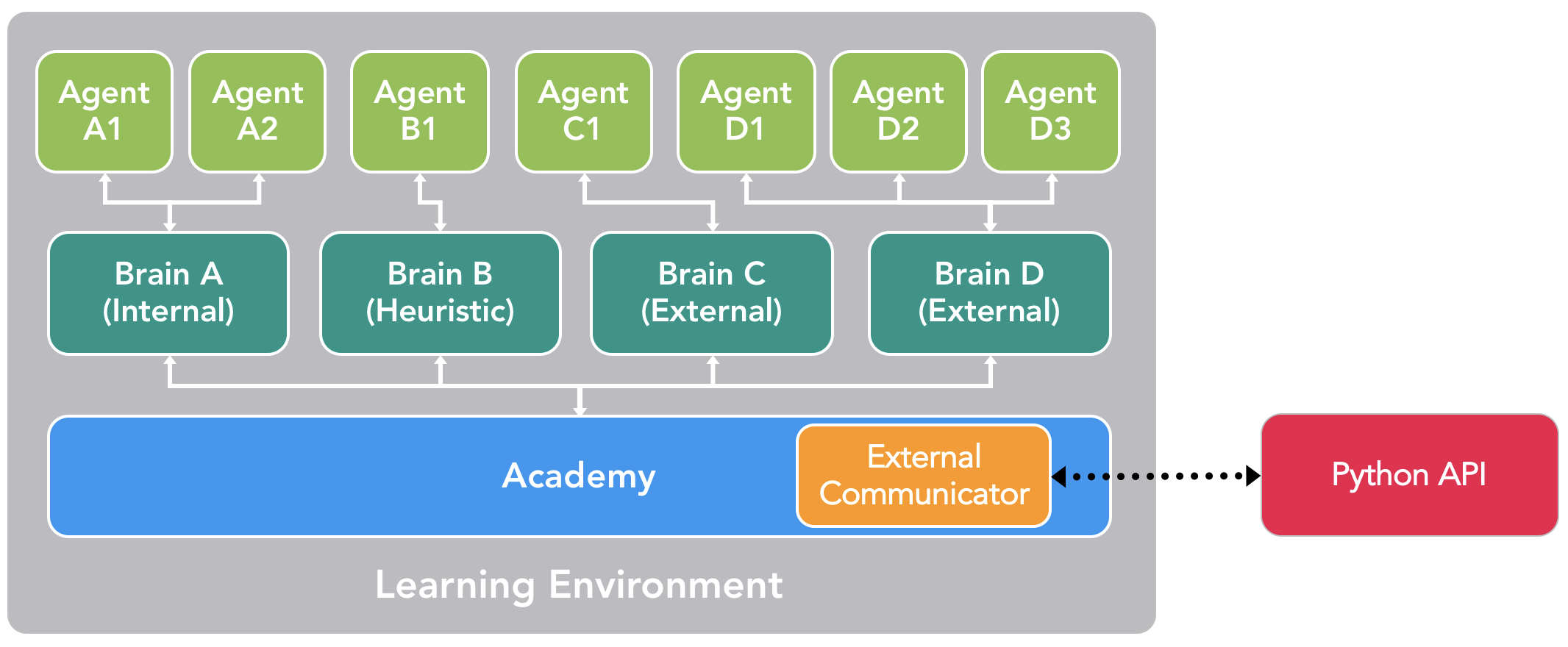
انواع مغزها در ML Agents
۳.۵. نحوه آموزش با استفاده از ML Agents و نقش API پایتون و ارتباط دهنده خارجی
با توجه به توضیحاتی که در بخش قبل داده شد شاید این نتیجه را گرفته شود که API پایتون فقط برای مغز یادگیری استفاده می شود اما مغز های بازیکن و ابتکاری را هم می توان به صورتی تنظیم کرد که مشاهدات و پاداش ها را به API پایتون ارسال کنند.
همانطور که اشاره شد ابزار ML Agents الگوریتم های مختلفی برای آموزش عامل ها پیاده سازی کرده است که فقط میتوان با استفاده از مغز یادگیری از آنها استفاده کرد.
به صورت دقیق تر در هر مرحله عامل ها مشاهده های خود را به API پایتون با استفاده از ارتباط دهنده خارجی ارسال میکنند وAPI پایتون با پردازش مشاهده ها عمل را به عامل باز میگرداند و در حین آموزش API پایتون ساسیت های بهینه را برای هر عامل می آموزد. برای آموزش عامل ها در بازی تانک از PPO استفاده شده است.
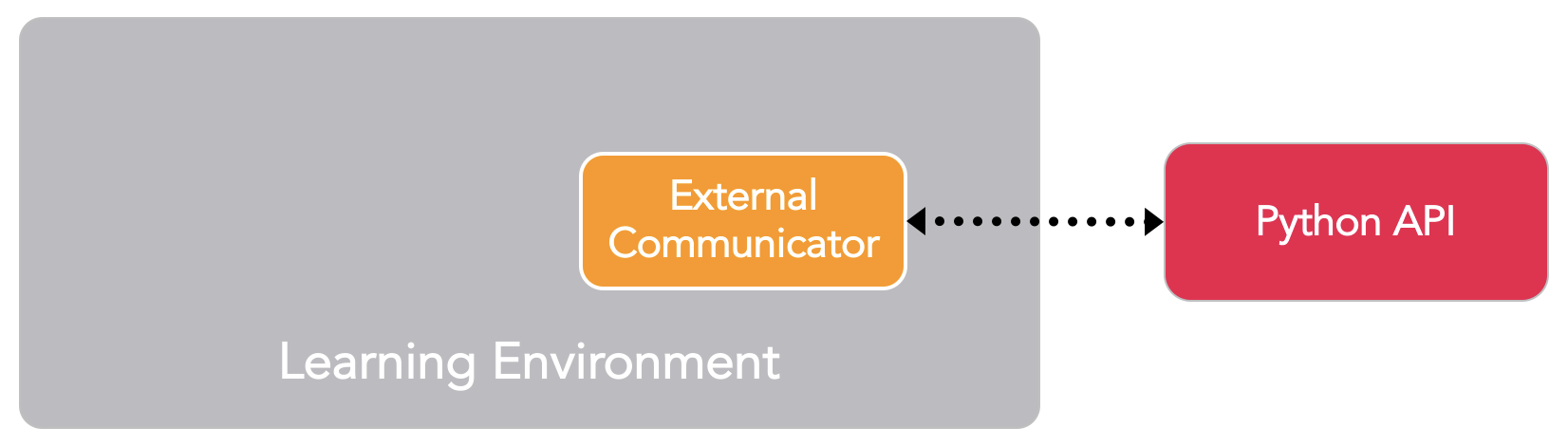
۴. روش PPO در یادگیری تقویتی
روش های شبیه سازی سیاست از پایه های جدید ترین پیشرفت های حاصل شده در استفاده از شبکه های عصبی برای کنترل کردن عامل های هوشمند در محیط هایی همچون بازی ها و شبیه سازی های سه بعدی هستند اما بدست آوردن نتیجه مناسب با استفاده از این الگوریتم ها با توجه به وابستگی آنها به اندازه قدم ها کار سختی است. همچین در این الگوریتم ها احتیاج به یک ماتریس در درجه 2 داریم که برای برای مسائل با با فضای بزرگ مناسب نیستند و به همین دلیل محاسبات پیچیده ای در دنیای واقعی دارند. در الگوریتم بهینه سازی سیاست های مبدایی به ازای پیاده سازی سخت محدودیت ها ، آنها را به صورت فرمول شده و بعنوان یک پنالتی در روش جای میدهیم و در نتیجه میتوان از می توان از بهینه ساز هایی با درجه 1 مانند روش نزول گرادیان استفاده کرد، هر چند این امکان وجود دارد که محدودیت ها هر چند یکبار دچار تغییر شوند اما هزینه آن به مراتب از محاسبات پیچیده کمتر است.
۴.۰.۱. مفاهیم ابتدایی الگوریتم
*چگونه می توان سیاست ها را به حداکثر پاداش رساند؟*
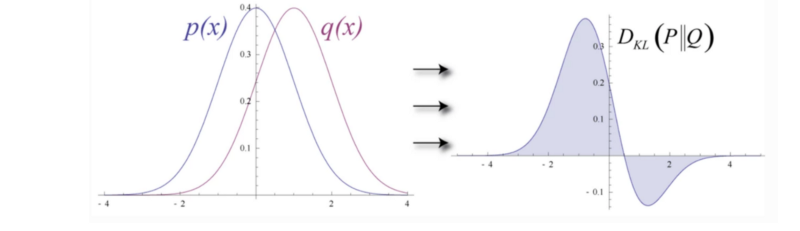
یکی از راه های موجود برای اینکار استفاده از الگوریتم های کوچک کردن و حداکثر سازی (Minorize-Maximization) است ، این راهکار به صورت تکرار شونده انجام می شود به این صورت که در هر مرحله کران پایین تابع مقدار پاداش محلی را تقریب میزند.
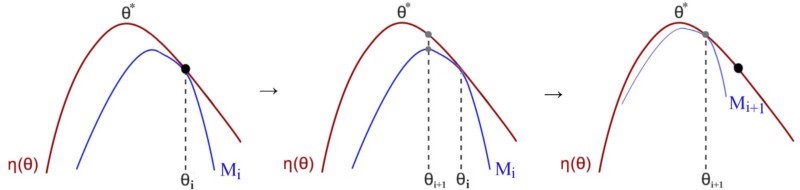
در مرحله اول مقدار کران پایین M برای η در سیاست مشخص شده پیدا می شود. سپس مقدار M بهینه سازی می شود و به عنوان سیاست مرحله بعد انتخاب می شود و دوباره این عملیات ادامه پیدا می کند تا جایی که مقدار ساسیت همگرا شود.
دو راهکار اصلی برای بهینه سازی وجود دارد :
استفاده از جسجتو های خطی مانند نزول خطی گرادیان: در این روش ابتدا سمت حرکت مشخص می شود و یک قدم به اندازه مشخص برداشته می شود که در صورتی که طول این قدم ها کوتاه باشد زمان زیادی برای پیدا کردن مسیر صرف می شود و در صورتی که طول قدم ها زیاد باسد امکان انحراف از مسیر وجود دارد و همچنین در صورتی که هیچکدام از مشکلات ذگر شده بوجود نیاید امکان این وجود دارد که حرکت از یک مکان بد شروع شود و باعث ضرر به کارایی راهکار می شود.
محدوده های اطمینان: در این روش ابتدا مقدار حداکثرید قدم ها مشخص می شود و سپس بهینه ترین نقطه در محدوده انتخاب می شود و ادامه جستجو از آن نقطه انجام می شود. مقدار حداکثری قدم ها در این روش در ابتدا به صورت تصادفی انتخاب می شود و سپس به صورت پویا تغییر می کند به این صورت که اگر مقدار فاصله نقطه بهینه جدید از قبلی زیاد شود از طول قدم ها کاسته می شود و بر عکس.
در الگوریتم بهینه سازی سیاست های مبدایی از واگرایی KL استفاده شده است. در این روش اختلاق بین دو توزیع مختلف داده اندازه گیری می شود :
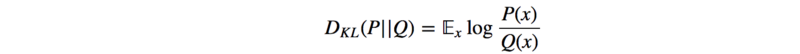
الگوریتم بهینه سازی سیاست های مبدایی
و این روش برای انازه گیری اختلاف بین دو سیاست بازسازی شده است و همچنین دو سیاست نباید از یکدیگر دور باشند.
و در آخر با استفاده از این روش می توان مقدار M را از معادله زیر بدست آورد.
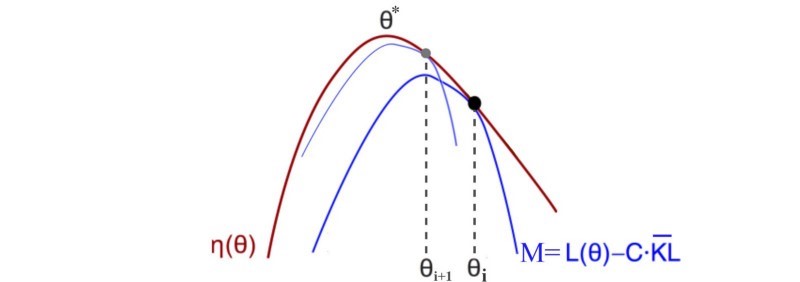
که در آن L(θ) برابر
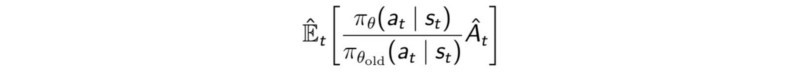
و قست دوم واگرایی KL است.
در روش بالا L مقدار سودمندی مورد انتظار محلی در سیاست کنونی است است. در این روش مقدار سیاست جدید با استفاده از نسبت سیاست قبلی و جدید محاسبه می شود و همچنین از معادله سودمندی مورد نظر به جای ئاداش مورد نظر استفاده می شود تا از مقادیر مختلف بدست آمده کم شود.
*محاسبه سیاست بهینه

و سپس با استفاده از بسط تیلور نتیجه زیر بدست می آید :

این روش شامل محاسبه یک ماتریس درجه دو است که پیچیدگی را تا مقدار زیادی افزایش می دهد. برای رفع این مشکل میتوان هر از چند گاهی تصمیم های بد سیاست پیش رفت ولی درجه محاسبات را با استفاده از روش هایی مانند کاهش تصادفی گرادیان (stochastic gradient descent) به یک کاهش داد و همچنین برای اطمینان از اینکه مقدار در محدود اطمینان بهینه می شود محدویت ها سادتر فرض می شوند در نتیجه احتمال انتخاب تصمیمات غلط کاهش می یابدو در نهایت با فرض کردن محدودیت ها بعنوان یک پنالتی فرمول نهایی به صورت زیر می شود.
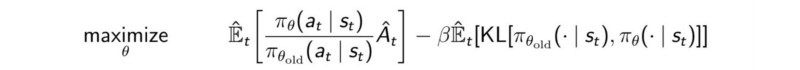
که β وزن پنالتی را مشخص می کند.
\الگوریتم محاسبه بهینه سازی سیاست های مبدایی با استفاده از پنالتی KL :*

۵. استفاده از یادگیری تقلیدی
در روش های یادگیری تقویتی بهینه سازی سیاست ها هدف اصلی است اما دریادگیری تقلید ، تقلید از یک حرفه ای هدف است.
۵.۱. یادگیری تقویتی :
۵.۲. یادگیری تقلیدی :

با توجه به این که فضای حالت مسئله بسیار گسترده بود و متغییر های زیادی دریادگیری عامل تاثیر داشتند درنتیجه برای بهبود و افزایش سرعت یادگیری عامل از از یک مغز بازیکن به عنوان آموزش دهنده و از یک مغز یادگیری به عنوان شاگرد استفاده شده است به این صورت که حرکات انجام شده توسط آموزش دهنده به صورت یک مدل TensorFlow ذخیره شده است و برای آموزش شاگرد استفاده می شود.
۶. استفاده از کتابخانه ML Agents در بازی تانک
برای برقراری ارتباط بین بازی و کتابخانه ML Agents باید همه ی اجزایی که در بالا ذکر شده است پیاده سازی شوند و مقادیر مختلف پارامتر های آنان تنظیم شوند.
۶.۱. آکادمی
برای وصل نمودن آکادمی به بازی ، کافی است که یک GameObject به نام آکادمی در بازی ساخته شود و یک اسکریپت به آن متصل شود.
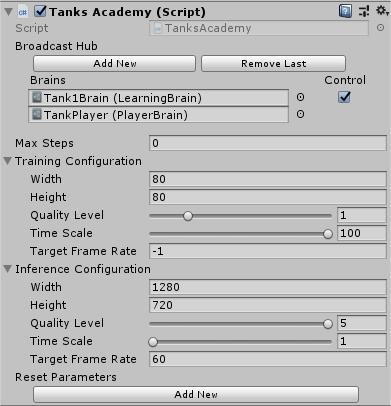
همان طور که در تصویر بالا قابل ملاحظه است، باید مغزهای مختلفی که برای یادگیری از آن ها استفاده شده است در Broadcast Hub قرار داده شوند تا ارتباط آن ها با API پایتون برقرار شود.
اسکریپت آکادمی از کلاس Academy ارث بری می کند و چند تابع برای چرخه حیات بازی و عملیات یادگیری در آن پیاده سازی می شود. شرح کد آکادمی در ادامه قرار داده شده است.
using UnityEngine;using MLAgents;public class TanksAcademy : Academy {
public override void InitializeAcademy(){
Monitor.SetActive(true);
Debug.Log("Academy initialized");
}
public override void AcademyReset(){}
public override void AcademyStep() {}
}
۶.۲. عامل
برای پیاده سازی عامل باید توابع مشخصی را در کلاس عامل، که از کلاس Agent ارث می برد، پیاده سازی کرد و این اسکریپت را به عاملی که مدنظر ما در بازی است متصل کرد. به نوعی می توان گفت که این قسمت مهم ترین بخش کار است. در کلاس عامل که کد کامل آن در ادامه آورده شده است، چندین کار مهم صورت میگیرد.
ارسال مشاهدات (Observations) به API پایتون: در فاز ابتدایی این پروژه 4 مشخصه از بازی برای مشاهده توسط عامل تعریف شده بود. 2 مشخصه شامل مولفه های مکانی تانک بازیکن و 2 مشخصه شامل مولفه های مکانی تانک رقیب، مشاهدات را تشکیل می دهند.
انجام عمل: طبق تعداد اعمالی که برای هر مغز تعریف می شود، API پایتون به همان تعداد اعداد اعشاری در بازه -1 تا +1 را در قالب یک آرایه به تابع AgentActions به عنوان پارامتر پاس میدهد و هر پارامتر باید بر اساس نقش خود استفاده شده و عمل مورد نظر را انجام دهد.
۷. چالش های پروژه
بدلیل وجود فضای حالت گسترده آموزش دادن عامل ها عملی بسیار زمان گیر است و یادگیری عامل ها به زمان زیادی نیاز دارد زیرا به تعداد مشاهدات زیادی احتیاج دارد تا به خوبی بتواند محیط بازی را بشناسد.
در صورتی که تعداد خصیصه های قابل یادگیری زیاد شود باعث کند شدن عملیات یادگیری می شود ، زیرا با تغییر هر یک از این خصیصه ها حالت های جدیدی برای عامل به وجود می آید که با آنها مواجه نشده است و امکان تصمیم گیری اشتباه وجود دارد و در صورتی که تعداد خصیصه ها کم باشد امکان این وجود دارد که عامل به خوبی آموزش نبیند.
برای حل این دو مشکل اول از از روش یادگیری تقلیدی استفاده کردیم که باعث شد عامل دید بهتری نبست به محیط پیدا کند و بتواند وزن های بهتری برای خصیصه ها انتخاب کند.
یکی از دیگر از چالش های مهم مشخص کردن پاداش مناسب برای عامل است که در صورتی که نسبت پاداش ها مناسب نباشد یا ارتباط درستی بین عملیات انجام شده و پاداش وجود نداشته باشد باعث می شود تا عامل به خوب نتواند آموزش ببیند و سیاست های غلط انتخاب کند
در مرحله بعدی بهینه سازی پارامترهای یادگیری است که باید با توجه به فرضیات اولیه مقدار آنها انتخاب می شد. برای بهبود این پارامترها با توجه نتایج خروجی نمودار و برداشت هایی که از آنها بدست آمد مقدار جدیدی برای پارامتر ها انتخاب شد.
۸. نتایج بدست آمده
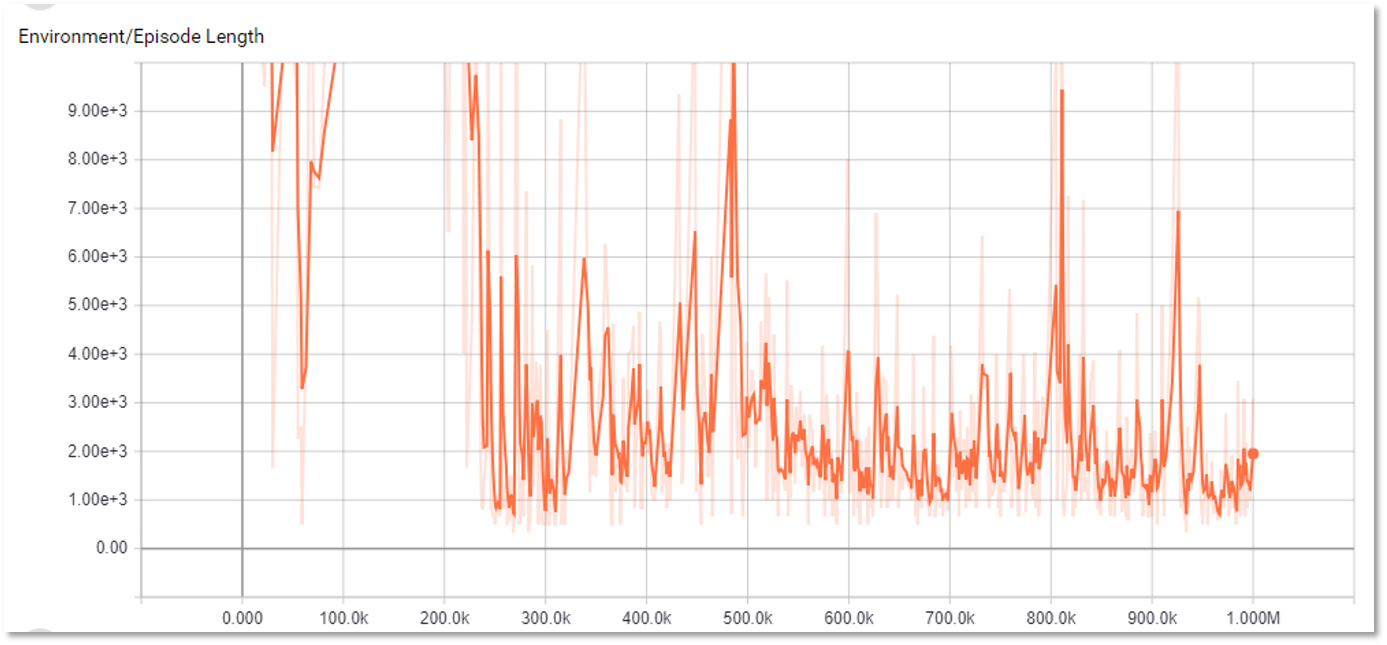
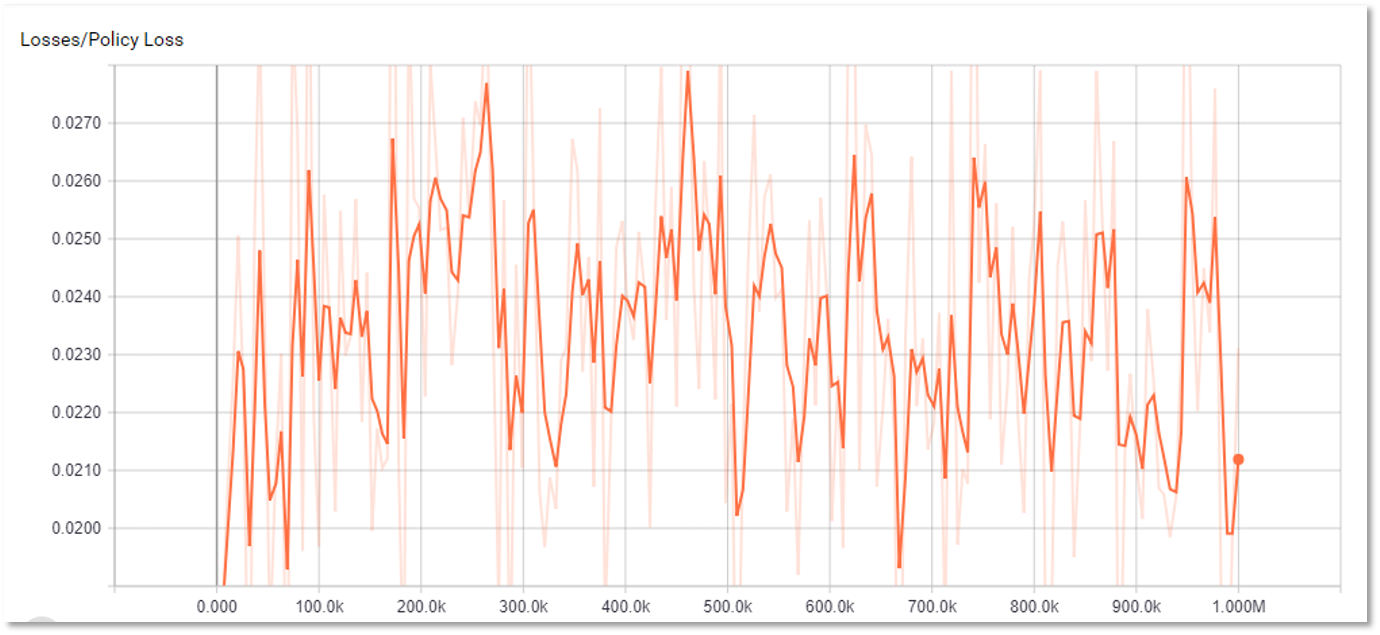
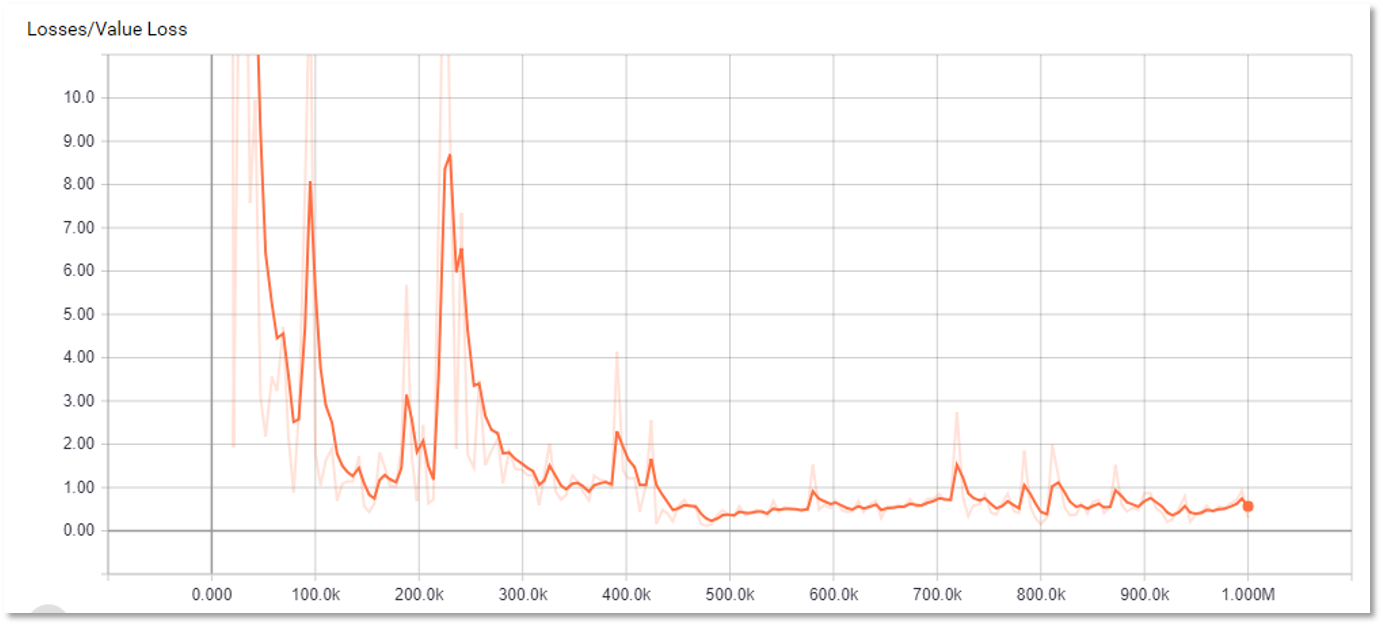
در این قسمت نمودارهای مربوط به مراحل یادگیری نمایش داده شده است. 4 نمودار اول مربوط به یک جلسه یادگیری است که شامل 2 میلیون مرحله یادگیری است.
در کل از نمودارهای زیر می توان نتیجه گرفت که یادگیری در روند صعودی قرار داشته است، اما به دلیل وسعت بسیار زیاد فصای حالات، یادگیری به یک حالت پایدار و مفید نرسیده است و بعضی پارامتر ها صرفا بر اساس شانس در نوسان قرار دارند.
همان طور که از نمودار اول قابل مشاهده است پس از مدتی که از یادگیری گذشته است، مقدار پاداش از منفی به صفر نزدیک شده است و سپس مثبت شده است. اما به دلیل وسعت فضای حالات، یادگیری به مرحله ای نرسیده است که حداکثر پاداش در هر مرحله کسب شود.
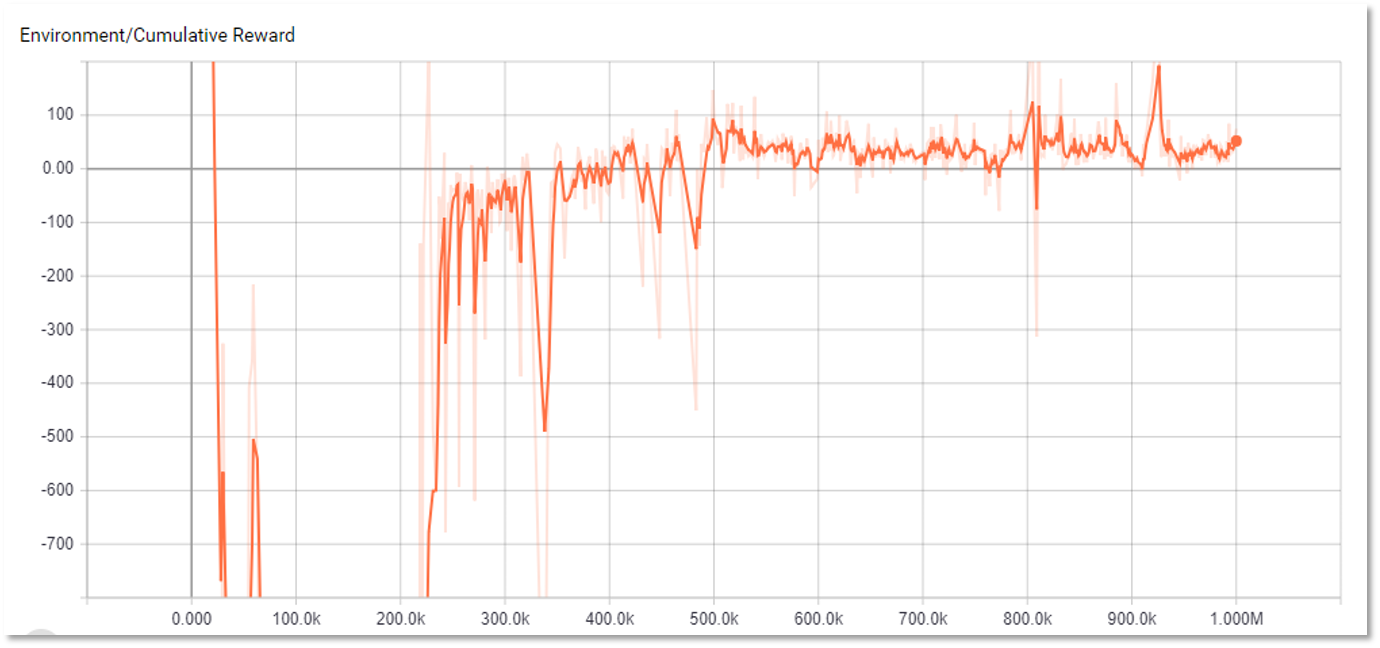
در نمودار دوم که مربوط به مدت زمان راند بازی شده در هر مرحله از یادگیری است، مشاهده می شود که نوسان بسیار زیادی وجود دارد. این به آن معنی است که یادگیری بازی به مرحله ای نرسیده است که طول هر راند به کمترین مقدار ممکن برسد و مدت زمان هر راند صرفا بر اساس شانس مشخص شده است.
۹. منابع
Project Repository in GitHub
https://github.com/Unity-Technologies/ml-agents/tree/master/docs
https://arxiv.org/pdf/1707.06347.pdf