چکیده
کنترل هوشمند چراغ راهنما یکی از مسائل حیاتی برای کارا یی یک سیستم حمل و نقل می باشد. این در حالیست که زمانبندی اکثر چراغ راهنماهای موجود در چهارراه ها به صورت دستی تنظیم می گردد. یک چراغ راهنمای هوشمند باید به گونه ای باشد که زمانبندی آن با تغییرات میزان ترافیک به صورت بی درنگ سازگار گردد. امروزه یکی از روش های معمول در کنترل هوشمند چراغ راهنما استفاده از یادگیری تقویتی عمیق می باشد و مطالعات اخیر حاکی از قابل اتکا بودن این روش می باشد. در این پروژه یک روش یادگیری تقویتی عمیق را جهت کنترل زمانبندی چراغ راهنما به کار برده ایم. شبیه سازی و پیاده سازی روش پیشنهادی را با استفاده از نرم افزار شبیه ساز ترافیک SUMO و زبان برنامه نویسی پایتون انجام داده ایم. به طور متوسط روش پیشنهادی به میزان 67 درصد نسبت به تنظیم زمانبندی چراغ راهنما به صورت دستی بهبود داشته است.
مقدمه
تراکم ترافیک به صورت قابل توجهی برای جوامع مختلف هزینه آور است. به عنوان مثال سال 2014 در کشور آمریکا، ترافیک به اندازه ی 124 بیلیون دلار هزینه در بر داشت[1]. بهبود شرایط ترافیک می تواند کارایی شهر و اقتصاد جامعه را بهبود بخشد و در نتیجه باعث تسهیل زندگی مردم یک جامعه گردد. یکی از راه حل های کاهش تراکم ترافیک، بهره گیری از علم هوش مصنوعی می باشد. امروزه بیشتر چراغ های راهنمای موجود در چهار راهها همچنان با قوانین دستی از پیش تعیین شده برای زمانبندی [3, 4]، کار می کنند و بر اساس اینکه ترافیک را به صورت آنلاین بررسی کنند، طراحی نگردیده اند. برای اینکه زمانبندی چراغ های راهنما بر اساس ترافیک در زمان واقعی تنظیم گردد، استفاده از تکنیک یادگیری تقویتی باب گردیده است. یادگیری های عمیق سنتی به 2 دلیل به سختی قابل اعمال می باشند.: (1) چگونگی بیان و مدل سازی محیط. (2) مدلسازی همبستگی بین محیط و فضای تصمیم. امروزه برای برطرف کردن این چالش ها، یادگیری تقویتی عمیق به صورت وسیعی مورد استفاده قرار می گیرد. شکل زیر ایده ی کلی روش یادگیری تقویتی عمیق (DQN) را نشان می دهد.
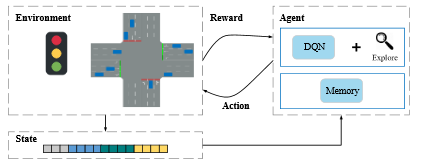
کارهای مرتبط
در این بخش ابتدا روش های متداول را برای کنترل زمانبندی چراغ راهنما معرفی می کنیم و سپس روش های یادگیری تقویتی ارائه شده برای کنترل چراغ های راهنما را معرفی می نماییم.
روش های اولیه ی ارائه شده برای کنترل چراغ راهنما را می توان به دو دسته تقسیم کرد. اولی کنترل از پیش تعیین شده ی سیگنال چراغ راهنما [5] که یک زمان ثابت برای چراغ سبز با توجه به پیشینه ی ترافیک در آن چهارراه در نظر گرفته می شد. دومی تحت عنوان وسایل نقلیه ی فعال می باشد که اطلاعات ترافیک را به صورت بی درنگ در نظر می گیرد[6]. این یک روش مناسب برای ترافیک نسبتا بالا است ولی با این حال تا حد زیادی به اعمال دستی قوانین نیازمند است. در این روش قوانین فقط حالت فعلی ترافیک را در نظر می گیرد و حدسی از وضعیت آینده ی ترافیک در چهارراه نمی تواند بزند.
اخیرا کارهایی که برای کنترل چراغ راهنما ارائه شده اند، از تکنیک های یادگیری تقویتی بهره می برند. بسیاری از روش ها محیط چهارراه را گسسته در نظر می گیرند که این امر حافظه ی زیادی را طلب می کند[7,8] اما نسبت به روش های اولیه که به صورت دستی قوانین را تنظیم می کردند ، کاراتر است.
تمام این روش ها محیط ترافیکی ایستا را در نظر می گیرند و از این رو تقریبا دور از واقعیت هستند. علائه بر آن، این روش ها فقط پاداش را در نظر می گیرند و سازگاری الگوریتم ها با ترافیک واقعی را نادیده می گیرند.
روش پیشنهادی
تعریف مسئله:
تعریف مسئله بدین صورت است که کل زمان انتظار خودروها کمینه گردد. منظور از کل زمان انتظار ، مدت زمانی است که خودروها پشت چراغ قرمز منتظر می مانند. برای حل این مسئله از Q-learning استفاده می کنیم که در این حالت یک عامل هوشمند که همان کنترل کننده ی چراغ راهنما باشد، بنا به حالتی (state)که در آن قرار دارد، عملی (action) را انجام می دهد که بیشترین پاداش (reward) را دریافت کند. زوج حالت-عمل را مقادیر Q می گوییم که در هر گام مقدار آن ها آپدیت می شود تا زمانی که به یک مقداری همگرا شوند تا یک سیاست(policy) ایده آل پیدا شود.
در ادامه به بیان جزئیات روش پیشنهادی می پردازیم.
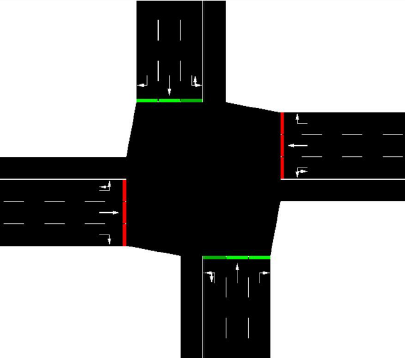
مطابق شکل ۲ یک چهار راه طراحی کردیم که هر خیابان دارای ۳ لاین می باشد که لاین سمت راست مخصوص گردش به راست ، لاین وسط مخصوص حرکت مستقیم و لاین چپ مخصوص حرکت به سمت چپ می باشد. و همچنین از یک لاین آزاد برای حمل و نقل عمومی جهت تخلیه ی بار ترافیکی استفاده می شود. همین مدل ساده شرایط کافی را برای تست الگوریتم ما فراهم می کند.
ما سیگنال کنترل ترافیک (عملکرد چراغ راهنما) را مطابق با الگوریتم یادگیری تقویتی مدلسازی نموده ایم که عامل هوشمند ما در اینجا در هر مرحله ی زمانی ...,t=0,1,2 با چهارراه تعامل برقرار نموده و هدف از این تعامل کاهش کل زمان انتظار می باشد. بدین شکل که ابتدا عامل حالت چهارراه را در زمان t مشاهده نموده و سپس سیگنال های ترافیکی را انتخاب و فعال می کند. پس از حرکت وسایل نقلیه تحت فرمان سیگنال های ترافیکی، حالت چهارراه به حالت بعدی تغییر می یابد. همچنین عامل با انتخاب عمل خود و فعال نمودن سیگنال های ترافیکی،در پایان زمان t یک پاداش دریاف می کند که در ادامه به جزئیات نحوه ی تعلق پاداش خواهیم پرداخت.
حالت های چهارراه:

مطابق شکل 3، چهارراه به قطعات مختلف بخش بندی شده است و در هر قطعه معیارهای سرعت و مکان تعریف می کنیم. در واقع دو ماتریس سرعت و پوزیشن خواهیم داشت که ماتریس پوزیشن شامل اعداد 0 و 1 استو ماتریس سرعت بین عدد صفر و 1 نرمال سازی شده است. بنابراین حالت چهارراه دارای دو ماتریس خواهد بود.
اکشن های عامل:
عامل حالت را مشاهده می کند و یکی از این 2 عمل را انجام می دهد. 1- چراغ سبز برای خیابان عمودی 2- چراغ سبز برای خیابان افقی .
در هر زمان تغییر حالت نیاز است.قبل از انجام تغییر حالت نیاز به گذاربه حالت بعدی را داریم. گذار موارد زیر را شامل می شود:
تغییر چراغ به زرد برای وسایل نقلیه ای که به صورت مستقیم در حال حرکت اند.
تغییر چراغ به قرمز برای وسایل نقلیه ای که به صورت مستقیم در حال حرکت هستند.
تغییر چراغ به زرد برای وسایل نقلیه ای که در حال رفتن به سمت چپ هستند.
تغییر چراغ به قرمز برای وسایل نقلیه ای که در حال رفتن به سمت چپ هستند.
مدت زمان چراغ سبز 10 ثانیه و مدت زمان چراغ قرمز 6 ثانیه می باشد. بنابراین در هر بخش از زمان عامل باید برای حفظ یا تغییر حالت فعلی تصمیم بگیرد.
پاداش
برای عامل با هر عملش یک پاداش در نظر می گیریم. عامل سعی دارد تا تراکم ترافیک را با کاهش زمان انتظار خودروها کاهش دهد. ما در هر گام 2 مشاهده در نظر می گیریم. مشاهده ی اول در آغاز یک گام زمانی و مشاهده ی دوم در پایان یک گام زمانی می باشد. در هر مشاهده ما زمان انتظار وسایل نقلیه را ثبت می کنیم. R1 و R2 به ترتیب میزان زمان انتظار برای مشاهده ی اول و دوم می باشند. در نهایت میزان پاداش از رابطه ی زیر بدست می آوریم:
R=R1-R2
با توجه به رابطه ی فوق بدیهی است که هرچه میزان پاداش بیشتر گردد،میزان زمان انتظار در حالت بعدی کمتر خواهد بود.
تعیین سیاست
برای تعیین سیاست عامل برای انجام اکشن، از شبکه ی عصبی استفاده می کنیم و مقدار W هایی که برای شبکه ی عصبی بدست می آوریم،در واقع همان Policy می باشد.
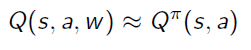
مقدار LOSS نیز طبق Q-Learning محاسبه می شود که به صورت زیر است.
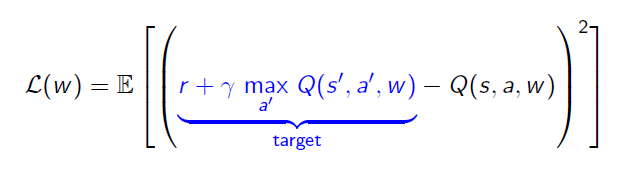
در این پروژه ما معادله ی فوق را با استفاده از آموزش شبکه ی عصبی عمیق با ساختار مطابق شکل زیر تقریب می زنیم.
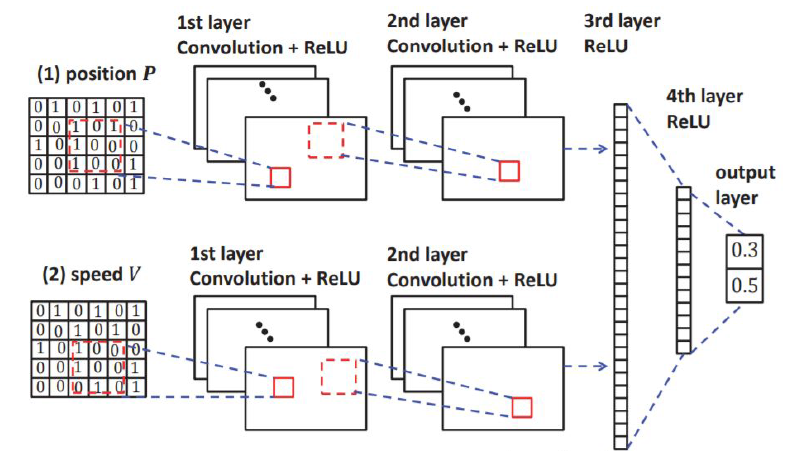
چنانچه در شکل 4 مشاهده می کنیم، لایه ی اول این شبکه ی عصبی عمیق از 16 لایه ی 44 تشکیل شده است و در این مرحله از Relu به عنوان تابع فعال ساز استفاده می کنیم. لایه ی دوم از از 32 فیلتر 22 تشکیل می شود که در این لایه هم از Relu به عنوان تابع فعال ساز استفاده می کنیم. لایه ی سوم و چهارم به صورت fully connected به ترتیب با سایز 128 و 64 می باشند. لایه ی نهایی لایه ی خطی است که خروجی Q می تواند مقادیر مربوط به هر اقدامی که عامل می تواند انجام دهد را دارا باشد.
آزمایش ها و تفسیر و نتیجه گیری
برای ارزیابی الگوریتم خود،یک چهارراه را با استفاده از نرم افزار SUMO شبیه سازی کردیم. SUMO یک نرم افزار open-source جهت شبیه سازی ترافیک شهری می باشد. زبان برنامه نویسی مورد استفاده ی ما در این پروژه ، پایتون است. ما همچنین SUMO TRACI را برای کنترل ترافیک در زمان اجرا را بهره گیری نموده ایم. برای هر شبیه سازی و اجرا 2000 اپیزود را اجرا نمودیم که هر اپیزود شامل 1000 الی 1200 وسیله ی نقلیه را شامل می شد. نمودار زیر میانگین میزان پاداش را برای 5 بار اجرای بنامه به اندازه ی 2000 اپیزود را نشان می دهد.
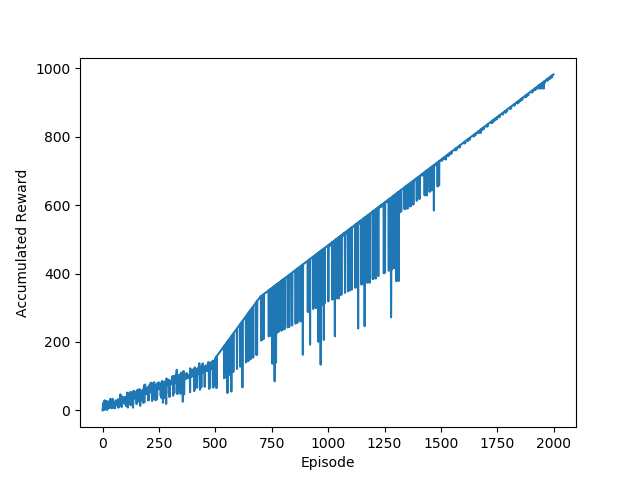
با توجه به شکل 5 می بینیم که روند نمودار صعودی بوده و این نشان دهنده ی این است که پاداش روند صعودی داشته و در نتیجه زمان کل انتظار وسایل نقلیه رو به کاهش است. پس این نتیجه میتواند بسیار مطلوب باشد.
مقدار زمان کل انتظار به دست آمده توسط نرم افزار SUMO برای حالتی که تنظیمات چراغ راهنما به صورت ثابت و دستی از قبل انجام شده باشد، برابر 342200
می باشد در حالی که در روش ارائه شده در این پروژه، در بهترین حالت برابر 94560 و در بدترین حالت برابر 133400بدست آمده است. در نتیجه حدود 73 درصد در بهترین حالت و حدود 62 درصد در بدترین حالت بهبود داشتیم.
در نتیجه در این پروژه یک الگوریتم یادگیری تقویتی را برای کنترل چراغ راهنمای چهارراه ها ارائه داده ایم که به صورت قابل توجهی شاهد افزایش کارایی زمانی آن نسبت به تنظیمات دستی و از قبل تعیین شده ی چراغ راهنما بوده ایم.
کارهای آتی
در این پروژه فقط یک چهارراه شبیه سازی شد و سیستمدارای یک عامل بود. اما در واقعیت امر این چنین نیست و یک شهر دارای شبکه ای از چهارراه است که زمان انتظار واسایل نقلیه ی عبوری از آن ها بر یکدیگر تاثیر دارند. بنابراین بهتر ایت تا این روش را بر روی چند چهار راه به صورت همزمان اجرا کنیم. به عبارتی الگوریتم را از حالت تک عامله به سیستم چند عامله (multi agent system) ارتقا بخشیم.
منابع
[1] Monireh Abdoos, Nasser Mozayani, and Ana LC Bazzan. 2013. "Holonic multiagent system for traffic signals control". Engineering Applications of ArtificialIntelligence 26, 5 (2013), 1575–1587.
[2] Hua Wei, Guanjie Zheng, Huaxiu Yao, Zhenhui Li, IntelliLight: "A Reinforcement Learning Approach for Intelligent Traffic Light Control", in Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD'18), London, UK, August 2018.
[3] Alan J Miller. "Settings for fixed-cycle traffic signals". Journal of the Operational
Research Society 14, 4 (1963), 373–386.
[4] Elise van der Pol and Frans A Oliehoek. 2016. Coordinated Deep Reinforcement Learners for Traffic Light Control. NIPS
[5] Francois Dion, Hesham Rakha, and Youn-Soo Kang. "Comparison of delay estimates at under-saturated and over-saturated pre-timed signalized intersections". Transportation Research Part B: Methodological 38, 2 (2004), 99–122.
[6] Isaac Porche and Stéphane Lafortune. . "Adaptive look-ahead optimization of traffic signals". Journal of Intelligent Transportation System 4, 3-4 (1999), 209–254.
[7] Bram Bakker, Shimon Whiteson, Leon Kester, and Frans CA Groen. "Traffic light control by multiagent reinforcement learning systems". In Interactive Collaborative Information Systems. Springer, 475–510. 2010.
[8] Baher Abdulhai, Rob Pringle, and Grigoris J Karakoulas. "Reinforcement learning for true adaptive traffic signal control". Journal of Transportation Engineering. 2003.