تشخیص پلاک خودرو
از اهداف اصلی این پروژه، پیادهسازی یک سامانه هوشمند بر پایه الگوریتم های پردازش تصویر و یادگیریی ماشین برای خواندن پلاک خودرو میباشد.

۱. مقدمه
تشخیص شماره پلاک خودرو سامانهای است برای خواندن پلاک خودرو با استفاده از نویسهخوان نوری (OCR)است. شماره پلاک خودرو یکی از مناسبترین اقلام اطلاعاتی جهت شناسایی خودروها میباشد، در اصل پلاک خودرو ها برای ماشین ها مثل یک شناسنامه عمل میکند. تشخیص پلاک خودرو (ANPR) از مهم ترین نیاز های سیستم های کنترل تردد مانند پاریگنک ها ، کنترل ترافیک و ... است .
برای استفاده از این سامانه، نیازی به نصب و تجهیز خودروها به وسیلهٔ دیگری (مانند GPS ) وجود ندارد. این سامانه با استفاده از دوربینهای مخصوص، تصویری از خودرو در حال عبور را گرفته و آن تصویر را جهت پردازش توسط نرمافزار تشخیص پلاک خودرو را ارسال میکند. روزانه صد ها و شاید هزاران تخلف ترافیکی روی میدهد و توسط دوربین های مخصوص ، تصویر خودرو های متخلف ضبط می شود .بررسی این تصاویر توسط نیروی انسانی کار غیر ممکن است و زمان و نیروی انسانی بسیار زیادی می طلبد.
از سامانه بالا می توان در موادر زیر استفاده شود :
کنترل ورود و خروج از محدوده طرح ترافیک و گرفتن جریمه در صورت تخلف
گرفتن عوارض به صورت خودکار
کنترل ترافیک
اندازهگیری سرعت خودروها
در کل تشخیص شماره پلاک خودرو سامانهای کاملاً مکانیزه است که با استفاده از پردازش تصویر خودروهای عبوری از یک مکان و ثبت توسط دوربین ها ، شماره پلاک آنها را استخراج میکند.
۱.۱. پردازش تصویر چیست ؟
پردازش تصاویر به موضوع پردازش تصویر های دیجیتال گفته میشود که شاخهای از هوش مصنوعی است که با پردازش سیگنال های دیجیتالی که توسط دوربین ها از تصاویر گرفته شده و ارسال میشود کار میکند. امروزه پردازش تصویر به دو شاخه تقسیم میشود یکی بهبود تصاویر و دیگر بینایی تصاویر است. به روش های برای بهتر کردن کیفیت دیداری تصاویر و اطمینان از نمایش درست آنها استفاده می شود بهبود تصاویر گفته میشود، در حالی که بینایی ماشین به روشهایی گفته میشود که به کمک آنها میتوان محتوای تصاویر را درک کرد تا از آنها در کارهایی چون رباتیک و محور تصاویر و تشخیص متن ها و ... استفاده کرد.
۱.۲. نویسهخوان نوری( یا OCR) چیست ؟
نویسه خوان نوری یا همان OCR، عبارتی است از تشخیص متن های در داخل تصاویر و تبدیل آن به متن است. عکس ها شامل پیکسل های است که توسط ترکیب رنگهای قرمز ،آبی ، و سبز تواید میشود. از دید انسان، یک عکس از یک کاغذ شامل متن ممکن است ارزش اطلاعاتی زیادی داشته باشد ویلی از دید برنامه تصویر یک تیکه کاغذ شامل متن با یک تصویر منظره تفاوتی ندارد، به دلیل اینکه هر دوی آنها شامل مجموعهای از پیکسلها هستند. برای اینکه بتوانیم از اطلاعات داخل کاغذ استفاده کنیم باید به روشی متنهای نوشته را تشخیص و حدا سازی کنیم، چنین کارهای توسط نرمافزارهای نویسه خوان نوری(OCR) انجام میشود.
۱.۳. شبکههای عصبی پیچشی(CNN) چیست ؟
شبکههای عصبی پیچشی(convolutional neural network) ردهای از شبکههای عصبی ژرف هستند که معمولاً برای انجام تحلیلهای تصویری یا گفتاری در یادگیری ماشین استفاده میشوند.شبکههای عصبی پیچشی به منظور کمینه کردن پیشپردازشها از گونهای از پرسپترونهای چندلایه استفاده میکنند.شبکههای عصبی پیچشی نسبت به بقیه رویکردهای دستهبندی تصاویر به میزان کمتری از پیشپردازش استفاده میکنند. این امر به معنی آن است که شبکه معیارهایی را فرامیگیرد که در رویکردهای قبلی به صورت دستی فراگرفته میشدند. این استقلال از دانش پیشین و دستکاریهای انسانی در شبکههای عصبی پیچشی یک مزیت اساسی است.
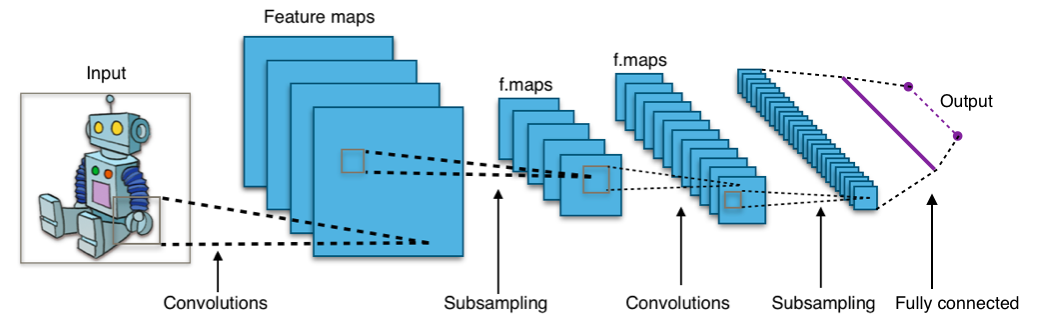
۲. کارهای مرتبط
تا به امروز برای حل این مسئله از راه زیادی استفاده شد است یکی از راه استفاده از ترکیب راه های RNN و CNN است. شبکههای عصبی بازگشتی (Recurrent Neural Network) برای دادههای ترتیبی استفاده میشوند که در آنها از خروجی قبلی، برای پیشبینی خروجی بعدی استفاده میشود. در این حالت، شبکهها در خودشان حلقههای تکرار دارند. این حلقهها که در نورونهای مخفی قرار دارند، بهشان این امکان را میدهند تا اطلاعات ورودیهای قبلی را برای مدتی ذخیره کنند تا بتوانند خروجیهای بعدی را پیشبینی کنند. خروجی لایهی مخفی مجددا t بار به لایهی مخفی ارسال میشود. این حالت تصویری شبیه به تصویر بالا است. خروجی یک نورون بازگشتی تنها زمانی به لایهی بعدی ارسال میشود که تعداد تکرار آن تمام شده باشد. در این حالت، خروجی جامعتر است و اطلاعات قبلی برای مدت بیشتری نگهداری میشوند.
در نهایت، خطاها براساس این بازگشتها تکثیر به عقب میشوند تا وزنها را بروزرسانی کنند.
به اینکار «تکثیر رو به عقب در زمان» (Back propagation through time یا به اختصار BPTT) میگویند.
با ترکیب این دو روش می توان راهی را در پیش گرفت که باعث کم شد loss مسئله میشود.
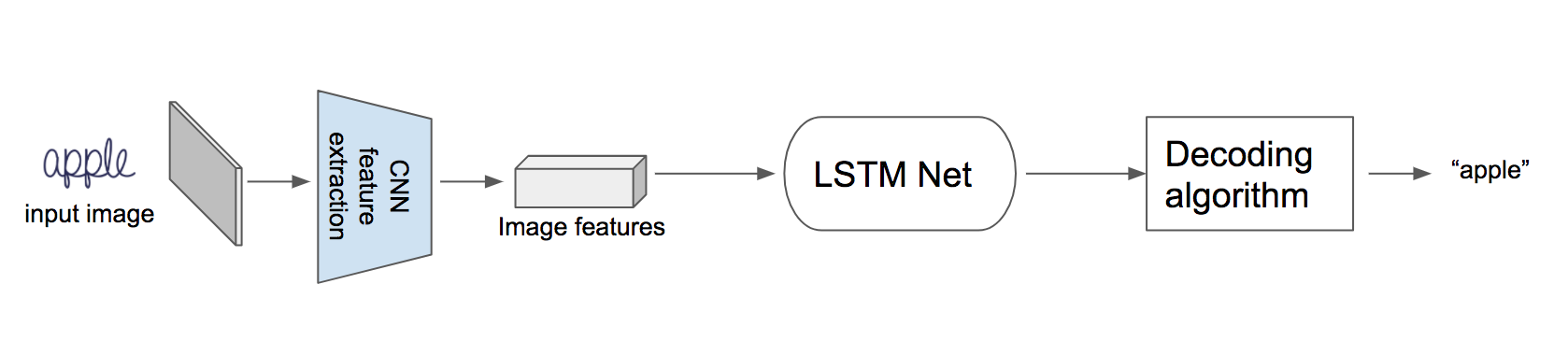
۳. حلمسئله
به طور کل راه حل ما شامل4 قسمت میباشد :
بازگزاری داده :بدین معنی که عکسها و جوابها را کنار هم قرار دهیم تا هنگام train & test بتوانیم ورودی و خروجی را مرتب کنیم.
ساختن شبکه عصبی : شبکههای عصبی شامل راسها و یالها(وزنها) میباشند که اطلاعات مورد نیاز برای پیدا کردن کاراکترها در خود ذخیره میکنند و بعد از یک سری پیمایش (batch size) اطلاعات شبکه را بروز رسانی میکنند.
آموزش شبکه عصبی
ارزیابی شبکه
۳.۱. بارگزاریداده :
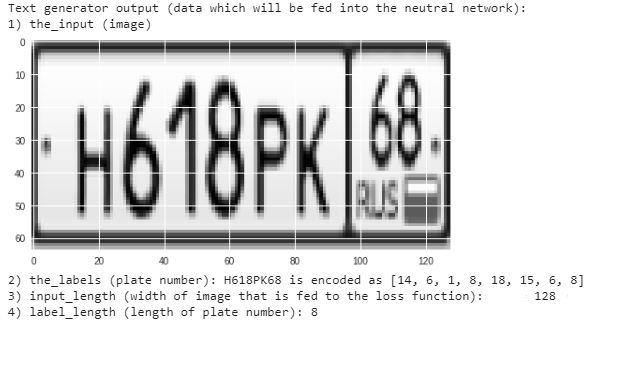
ابتدا باید داده های موجود را پردازش کنیم تا بدانیم پلاک های ما شامل چه اعداد و حروفی میباشند , همینطور بدانیم هر پلاک شامل چند کاراکتر میباشد.

بعد از اتمام مرحله اول آدرس هر عکس و جواب متناظر آنها که در فایل json وجود دارند را به شبکه عصبی خود متصل مینماییم .
بدین ترتیب که هر json حاوی اطلاعاتی از عکس مانند جواب تصویر ,طول تصویر , عرض تصویر میباشد.
برای اینکه کار در پیمایش عکس راحت تر شود عکس را به صورت سیاه و سفید تبدیل میکنیم و اندازه ی طول و عرض تمام تصاویر را یکی مینماییم.
همچنین برای انجام راحت شدن محاسبات در شبکه عصبی , به جای آنکه کاراکتر حروف را به شبکه منتقل کنیم , به هر حرف یک عدد تصخیص میدهیم.
۳.۲. ساختن شبکه عصبی
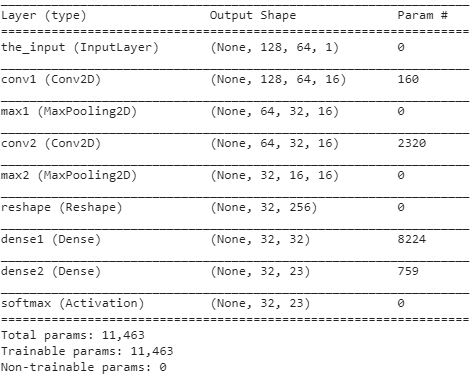
برای ساختن شبکه عصبی از شبکه عصبیConvolutional neural network)CNN) استفاده میکنیم .این شبکه قالبا برای مسئلههای حاوی عکس استفاده میشوند.
شبکه ما از 3 نوع لایه Conv2D و MaxPooling2D و Activation کمک گرفتیهایم.
لایه Conv2D :یک عمل پیچش را روی ورودی اعمال میکنند، سپس نتیجه را به لایه بعدی میدهند. این پیچش در واقع پاسخ یک تکنورون را به یک تحریک دیداری شبیهسازی میکند.
2.لایه MaxPooling2D : لایهConv2D شامل لایههای تجمعی میباشد که خروجیهای خوشههای نورونی در یک لایه را در یک تکنورون در لایه بعدی ترکیب میکند.لایه MaxPooling2D از حداکثر مقدار بین خوشههای نورونی در لایه پیشین استفاده میکند.
3.لایه Activation : ما از SoftMax Activation استفاده کردیم .در یادگیری ماشین به منظور انجام طبقهبندی از تابع بیشینهٔ هموار استفاده میشود. به طور مثال در صورتی که n کلاس مختلف وجود داشته باشد و الگوریتم یادگیری ماشین به طور مستقیم احتمال حضور ورودی در هر کدام از این کلاسها را تولید نکند و به جای آن، برداری از n عدد حقیقی که متناظر با امتیاز قرارگیری ورودی در هر دسته است، خروجی دهد، میتوان از تابع زیر برای تبدیل امتیازهای حقیقی به احتمال استفاده کردبدین ترتیب شرایط تعریف یک تابع جرم احتمال قرارگیری در [0,1] و جمع احتمالات برابر با ۱ رعایت خواهد شد:
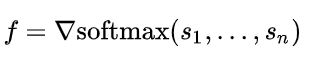
ساختار شبکه عصبی
تذکر
تابع activation در تمامی لایهها "relu" میباشد.
۳.۳. آموزش شبکه
در این مرحله دادههای مربوط آموزش به شبکه عصبی داده میشود و شبکه آنها را پیمایش میکند و سعی در بهتر کردن وزنها در شبکه دارد.
نکته دیگری که وجود داراد وجود Validation Data میباشد که بدین صورت میباشد که بعد از هر epoch از Validation data به عنوان تست استفاده میشود که قدرت شبکه را بررسی کند.
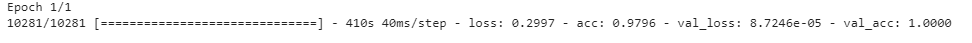
۳.۴. ارزیابی
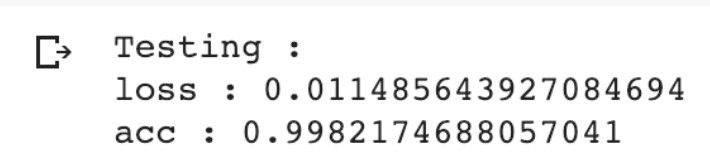
در این مرحله باید شبکه ای که در مراحل قبلی ،آموزش داده شده است را مورد آزمایش قرار بدهیم ، برای این کار در قدم اول باید عکس های متفاوتی نسبت به مرحله یادگیری به شبکه داد بشود سپس مانند مراحل قبلی باید عکس ها رو مناسب برای شبکه کرد ،عکس ها رو یک اندازه میکنیم سپس آنها را سیاه و سفید میکنیم و به داخل شبکه قرا میدهیم و جواب های زیر را خواهیم گرفت:


این سامانه به گونه ای نیست که تمام پلاک ها را درست تشخیص دهد. (به دلیل اینکه به lossصفر نرسیده اییم برای همین جواب ها ممکن درست نباشد.) مانند نمونه زیر :


در مرحله اخر می توان گفت جواب نهایی loss وacc ما بر اساس تست های مختلف رو نمونه های مختلف با اندازه های مختلف به صورت زیر میباشد:

تذکر
به علت اینکه دیتا مورد استفاده از دیتا آماده نبوده , ما از توابع آماده model.fit و model.evaluate استفاده نکردیم و تابع fit و evaluate را خودمان پیاده سازی کردیم که در قسمت آموزش و ارزیابی وجود دارند .
۴. کارهای آینده
تا اینجا ما توانستیم نتایج به نسبت خوبی را به دستآوریم. ولی بهتر از دیتاست های متفاوت و فارسی استفاده کنیم و یکی از کارهای دیگری که میتوان انجام این است الگوریتم را پیشرفت دهیم و بتوانیم با عکس های مختلف بتوانیم تست کنیم و در هر عکس بتوانیم چند پلاک تشخیص داده شود.
یکی از اصلی ترین کار ها تشخیص قاب خودرو برروی خودرو میباشد. بدین معنی که دز عکسی که ماشین وجود داشته باشد ابتدا ما پلاک ماشین را پیدا کنیم و بعد از آن اعداد پلاک را پیدا کنیم.
۵. منابع
https://hackernoon.com/latest-deep-learning-ocr-with-keras-and-supervisely-in-15-minutes-34aecd630ed8