در این پروژه می خواهیم الگوریتمی را پیاده سازی کنیم که قادر به تشخیص نوع پوشاک از بین مجموعه تصاویر پوشاک مختلف می باشد
۱. مقدمه
ما در این پروژه قصد داریم با استفاده از روش بهینه تعدادی تصویر لباس را با استفاده از برچسب گذاری در دسته های مختلف قرار دهیم.
امروزه الگوریتم ها و مدل های مختلف پژوهش های مبتنی بر شبکه عصبی، جای خود را در میان طبقه بندی تصاویر به خوبی باز کرده اند. هدف اصلی این الگوریتم ها این است که در شبکه های مصنوعی، ماشین به شکلی آموزش ببیند که در نهایت تشخیصی نزدیک مغز انسان داشته باشد . از بین انواع شبکه های عصبی، شبکه های عصبی کانالوشون )CNN )معمولا دقت خوبی را در طبقه بندی تصاویر ارائه می کنند .
در حقیقت استفاده از ویژگی های شبکه های عصبی کانالوشن به خوبی تنظیم شده با Linear SVM بهترین نتیحه را می دهد .
می توان چالش هایی که این مدل برای رویارویی با آنها طراحی شده است را به صورت زیر در نظر گرفت :
مقابله با مساله overfitting در طبقه بندی مجموعه تصاویر بزرگ .
در نمر گرفتن مدل های تدرتمندتر برای آموزش داده ها با استفاده از مجموعه های آموزشی بسیار بزرگ تر .
استفاده از GPU های کارآمد برای با بردن سرعت عملکرد.
۲. کارهای مرتبط
یادگیری عمیق بصورت گسترده در زمینه های گوناگونی از بینایی کامپیوتر همانند دسته بندی تصاویر (image classification) , تشخیص اشیاء (object detection) , قطعه بندی معنایی(semantic segmentation) و بازیابی تصاویر(image retrieval) و برآورد ژست انسان (human pose estimation) که فعالیتهایی کلیدی برای درک تصویر اند مورد استفاده قرار گرفته است که پروژه ی ما در حیطه ی دسته بندی تصاویر می باشد.
فعالیت دسته بندی تصاویر شامل برچسب گذاری تصاویر ورودی با یک احتمال از حضور دسته خاصی از اشیا بصری میشود. (یعنی آیا یک دسته خاص مثل سگ در یک تصویر وجود دارد یا خیر)
چندین روش برای دسته بندی تصاویر ارائه و ارتقا داده شده است که به اختصار به شرح زیر می باشد:
قبل از یادگیری عمیق , شاید محبوب ترین و پراستفاده ترین روشها در زمینه دسته بندی تصاویر (image classification) روشهای مبتنی بر bags of visual words یا به اختصار BoW بودند که ابتدا یک تصویر بصورت یک histogram از کلمات دیداری کوانتیزه شده(یعنی کلمات در قالب اعداد بیان شدند), و سپس بعنوان ورودی این histogram به یک دسته بندی کننده SVM تغذیه میشد. این معماری مبتنی بر آمار بدون ترتیب بود تا بتواند هندسه فضایی (spatial geometry) را در توصیف گرهای BoW ترکیب کند
روش بعدی این گونه بود که روش قبلی را با spatial pyramid ادغام کرد، به این معنی که که تعداد کلمات بصری درون یک مجموعه از زیر ناحیه های یک تصویر (image sub-regions) را بجای کل ناحیه شمارش میکرد .بعدا این معماری با import مسائل بهینه سازی sparse coding در ایجاد codebookها بیشتر بهبود پیدا کرد و توانست بهترین کارایی را در رقابت ImageNet در سال ۲۰۱۰ بدست آورد. Sparse coding یکی از الگوریتم های پایه یادگیری عمیق است و نسبت به الگوریتمهای دستی طراحی شده مثل HOGو LBP متمایزکننده تر(more discriminative) است.
در این مرحله روشهای مبتنی بر BoW تنها نگران آمار مرتبه ۰ بوده ( مثل تعداد کلمات بصری) و اطلاعات بسیار زیادی از تصویر را دور میریزند. روش ارائه شده توسط Perronnin بر این مشکل فائق آمده و آمار مرتبه بالاتری با استفاده از Fisher Kernel استخراج کرد و اینطور توانست به نتایج بسیارعالی در رقابت دسته بندی تصاویر در سال ۲۰۱۱ دست یابد. در این فاز, محققان میل به تمرکز بر روی آمار مرتبه بالاتر دارند که هسته اصلی یادگیری عمیق است
در این روش Krizhevsky با استفاده از آموزش یک شبکه CNN بزرگ بر روی دیتابیس ImageNet و کسب بهترین نتیجه در رقابت ImageNet سال ۲۰۱۲ توانست اثبات کند که شبکه های عصبی کانولوشن علاوه بر تشخیص ارقام دست نویس (۲۰) بخوبی میتوانند دردر حوزه دسته بندی تصاویر هم عمل کنند. این شبکه توانست با کسبtop-5 error rate 15.3%توانست به رتبه اول دست پیدا کرده و فعالیت چشمگیری در حوزه تحقیقات پیرامون شبکه های عصبی کانولوشن ایجاد کند
روش overfeat یک روش چندمقیاسه و پنجره لغزان (multiscale and sliding window) ارائه داد که قادر به یافتن مقیاس بهینه تصویر (optimal scale of the image) و انجام فعالیتهای گوناگون مثل دسته بندی , localization و کشف (detection) در آن واحد بود. این الگوریتم توانست نرخ خطای ۵تای اول (top-5 error rate) را به ۱۳٫۶% کاهش دهد . Zeiler هم تکنیک بصری سازی نوینی را معرفی کرد که باعث ارائه دیدی از کارکرد لایه های میانی شبکه میشد و بوسیله آن مدل جدیدی را تنظیم کرد که توانست AlexNet را شکست داده و به نرخ خطای ۵ تای اول ۱۱٫۷%رسیده و نفر اول رقابت ILSVRC در سال ۲۰۱۳ شود.
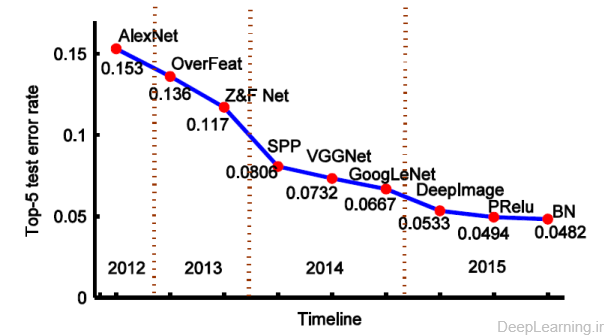
علیرغم ظرفیت بلقوه مدلهای بزرگ, آنها از مشکلات overfitting و underfitting در زمانهایی که داده آموزشی و یا زمان آموزش کم باشد رنج میبرند. به منظور جلوگیری از این کاستی ها, استراتژی های جدیدی (یعنی تصاویر عمیق (deep image) ) برای data augmentation و استفاده از تصاویر multi-scale توسعه یافته . تیم توسعه دهنده یک ابررایانه عظیم برای شبکه های عصبی عمیق ساختند و یک الگوریتم موازی بسیار بهینه را توسعه دادند . نتایج دسته بندی تقریبا ۲۰% بهبود نسبت به نتایج قبلی با نرخ خطای ۵ تای اول ۵٫۳۳% را نشان میداد.
۳. آزمایش ها
برای مشاهده ی جزئیات کد بهلینک گیت مراجعه نمایید.
طی سالهای اخیر, یادگیری عمیق در حوزه های مختلف بصورت گسترده مورد مطالعه قرار گرفته است و به همین دلیل تعداد زیادی از روش های مرتب با آن بوجود آمده است . این روش ها را می توان به 4 دسته مختلف تقسیم کرد که عبارتند از:
Convolutional neural networks
Restricted Boltzmann Machines :RBMS
Autoencoders
Sparse Coding
شبکه های CNN به طور کلی می توانند خروجی هایی که ممکن است برای واحد های بعدی مورد استفاده باشند را با استفاده از داده های ورودی محاسبه کنند.
این نورون ها همگام با هم کار می کنند تا مشکل مشخصی را حل کنند، یادگیری با مثال یک شبکه برای یک درخواست مشخص مثل تشخیص الگو ها یا طبقه بندی داده ها در طول یک پردازش یادگیری ایجاد می شود. همان طور که معرفی شود،
شبکه های عصبی کانالوشن در ابتدا برای کار بر روی عکس ها پیشنهاد شدند به این دلیل که آنها سعی در استفاده اهرمی از ویژگی طبیعی ایستا بودن عکس را داشتند.
در ادامه به توضیح برخی مفاهیم به کار رفته در شبکه های عصبی کانالوشن مرتبط با پروژه می پردازیم.
مجموعه داده
برای پیاده سازی این پروژه از کتابخانه ی numpy و مجموعه داده ی fashion_MNIST استفاده کرده ایم.این مجموعه داده شامل 60000 داده ی آموزشی و 10000 داده ی آزمایشی می باشد.
واحد های پردازشی
نورون های مصنوعی اصولا واحد های پردازشی هستند که بعضی عملیات محاسباتی را روی چندین متغیر ورودی انجام میدهند و معمولا یک خروجی محاسبه شده را در طول تابع فعال سازی تولید میکنند . به طور نوعی یک نورون مصنوعی یک بردار وزن ( wn ,…, w2 , w1=(w و بعضی متغیرهای ورودی ( xn ,… , x2 , x1=(X و یک آستانه یا جهت b یا bias را دارا می باشد.
z=f(X1W1 + X2W2 +....+XnWn+b)
در حالی که z و x و w وb به ترتیب بیان کننده ی خروجی و ورودی و وزن و آستانه میباشند. R→R(.):F تابع فعال ساز را بیان می دارد . به طور قراردادی، یک تابع غیر خطی برای (.)F درنمر گرفته می شود . توابع مورد استفاده زیادی به عنوان تابع فعال ساز وجود دارد، مانند: Sigmoid ، Herbolic و همچنین تابع اصلاح شده ی خطی .
تابع اصلاح شده ی خطی ، بیشترین موردی است که در پروژه استفاده شده است. نورون هایی با این مشخصات وقتی که با دیگر نورون ها مقایسه میشوند ، چندین مزیت دارند: 1)بهتر کار میکنند طوری که از اشباع برنامه در حین پردازش یادگیری دوری میکنند
2)موجب عدم تراکم در واحدهای مخفی میشوند
3)مانند توابع Sigmoid و Tanh دچار مشکل ناپدید شدن شیب نمیشوند.
واحد پردازشی که از تابع اصلاح گر به عنوان تابع فعال ساز استفاده می کند، RELU نامیده میشود.
فرمول آن به صورت زیر می باشد:
a=f(z)=max(0,z)
اجزای شبکه
در میان انواع مختلف لایه ها، مسئولیت استخراج ویژگی ها از عکس ها با لایه ی کانالوشن است.لایه های اول معمولا ویژگی های سطح پایین مانند لبه ها و خط ها و گوشه ها را دریافت می کنند در حالی که بقیه لایه ها ویژگی های سطح بالا مانند قواعد، اشیا و شکل ها را دریافت می کنند . پردازشی که در این لایه انجام می شود می تواند به دو فاز تقسیم شود:
1)گام کانالوشن که یک پنجره با اندازه ثابت با یک Stride( گام یا فاصله مشخص بین مرکز پنجره و مرکز عکس )روی
عکس اجرا می شود و محدوده مورد نظر را تعریف می کند
2 )مرحله پردازش که از پیکسل موجود در پنجره به عنوان ورودی برای نورون ها استفاده می کند که سر انجام عمل استخراج ویژگی را از آن ناحیه مورد نظر انجام می دهد . اصولا در مرحله ی آخر، هر پیکسل در وزن متناظر با خودش ضرب می شود و خروجی نورون را تولید می کند، بنابراین تنها یک خروجی جدید کوچکتر از عکس اصلی را بدست می دهد. اکثر این ویژگی ها شبیه به هم هستند زیرا که هر پنجره می تواند پیکسل های پنجره دیگر را نیز در خود داشته باشد . تغییرات ویژگی ها بوسیله ی یک سری از عملیات ها روی ویژگی مشخص یک ناحیه خاص از عکس ایجاد شده است . مشخصا پنجره ی با اندازه ی ثابت روی ویژگی های استخراج شده با لایه کانالوشن اجرا میشود و در هر مرحله عملیات بهینه سازی می شود . روی لایه های pooling دو عملیات وجود دارند .
عملیات بیشترین و عملیات میانگین، که بیشترین مقدار و مقدار حد وسط به ترتیب را روی ویژگی مورد نظر انتخاب میکند.
این عملیات تضمین میکند که حتی وقتی که ویژگی های عکس تغییرات و چرخش های کوچکی را داشته باشند ، همچنان نتیجه یکسان بماند ، که برای تشخیص و طبقه بندی اشیا ویژگی بسیار مهمی محسوب می شود.
آموزش داده
روال کلی کار در این برنامه به این صورت است که، تعدادی تصویر را دریافت می کند، سپس با استفاده از الگوریتم شبکه عصبی کانالوشن یا یادگیری عمیق ، ویژگی ها را از تصاویر استخراج می کند و خروجی را به SVM می دهد. SVM براساس این ویژگی ها روی تصاویر آموزش می دهد و یک مدل برای خودش تولید می کند و سپس محاسبه می کند که تصاویر با چه ویژگی ها در چه دسته هایی قرار گیرند.
ارزیابی داده
اطلاعات بدست آمده بسیار مبهم می باشد زیرا نیاز به تفسیر دارند . در سیستم بازیابی اطلاعات باید هر چه بهتر اطلاعات را مدل کرد تا ابهام در درک اطلاعات توسط سیستم کمتر شوند . به همین علت در سیستم های بازیابی اطلاعات ، معیار دقت و بازخوانی و معیارهایی شبیه به آنها به عنوان معیارهای اصلی ارزیابی به کار میروند . به منظور ارزیابی نتایج روش پیشنهادی از معیار های 1)معیار دقت : تعداد مستندات بازیابی شده واقعاً با ربط باشند یا بعبارت دیگر نزدیک بودن مقدار اندازه گیری به یکدیگر خواه واقعیت را نشان دهد، خواه نشان ندهد 2 )معیار بازخوانی 3)معیار صحت : نزدیکی مقدار اندازه گیری شده به
مقدار واقعی یعنی مقداری که ما به آن اطمینان داریم .
به طور خلاصه در روش پیاده سازی با الگوریتم CNN به این گونه عمل کرده ایم که تصاویر ورودی را از دو لایه convolution و pooling عبور داده و در نهایت نتیجه را به لایه fully connected منتقل کرده ایم و از Linear SVM به عنوان طبقه بندی نهایی استفاده می کنیم.