۱. چکیده
در بازی Flappy Bird شما وظیفه هدایت یک پرنده را بر عهده داشته و بایستی او را کنترل نمایید. در طول مسیر با موانع متعددی رو به رو خواهید شد که بایستی از آن ها عبور کنید . حواستان به لوله ها باشد و مراقب باشید که به آن ها برخورد نکنید

۲. مقدمه
یادگیری ماشین (Machine Learning) علم طراحی ماشینهایی است که با استفاده از دادههایی که به آنها داده میشود (نمونهها) و تجربیات خودشان عمل کنند، بدون آنکه همه اقدامات با بهرهگیری از برنامهنویسی به آنها داده شود. الگوریتمهای یادگیری ماشین در دستههای نظارت شده , نظارت نشده و تقویتی قرار دارند. این پروژه با استفاده از «یادگیری تقویتی» انجام شد.
در یادگیری تقویتی (Reinforcement learning | RL) در واقع میخواهیم موقعیت را به یک رفتار و عملکرد نظیر کنیم به طوری که بیشترین پاداش را دریافت کنیم. در این نوع یادگیری بر خلاف یادگیری های دیگر به یادگیرنده گفته نمیشود که عملکرد درست کدام است، بلکه این خود یادگیرنده است که باید با امتحان کردن رفتار های مختلف و دریافت پاداش درنظر گرفته شده در شرایط مختلف بهترین عمل را پیدا کند. در یادگیری به همراه ناظر یک مجموعه از داده های مطلوب به عامل داده میشود ولی در مسائلی که توسط یادگیری تقویتی حل میگردند پیدا کردن یک مجموعه از داده های مطلوب کار بسیار دشواری است زیرا این مسائل
عمداتاً از پیچیدگی بالایی برخوردارند و بسیار تعاملی هستند.
یکی از چالش های پیش رو در این نوع یادگیری انتخاب بین explore و exploit است. عامل باید با تکرار عمل های نسبتا مطلوب خود در گذشته دقت آنها را افزایش دهد اما از جهتی این کار باعث میشود که عامل از تجربه رفتار های جدید باز ماند.
درهوش مصنوعی (artificial intelligence)، عامل هوشمند (IA | Intelligent Agent) موجودیت خودکاری است که از طریق حسگرهای خود محیط را میبیند و با استفاده از محرکها اقداماتی را در محیط انجام میدهد و فعالیتهای خود را در مسیر کسب اهداف هدایت میکند. عاملهای هوشمند ممکن است از یادگیری یا دانش برای کسب اهداف خود بهره بگیرند. این عاملها ممکن است بسیار ساده یا خیلی پیچیده باشند.
ایده نهفته در یادگیری تقویتی آن است که یک عامل در محیط طی تعامل با آن و دریافت پاداش برای اقدامات خود، یاد بگیرد. مبحث یادگیری تقویتی از تعامل نوع
بشر با محیط و یادگیری بر اساس تجربیات خود، نشات میگیرد.
هدف ما در این بازی رسیدن از ابتدا به انتهای مسیر از طریق مسیر های مجاز است. کد ما باید این مسیر های مجاز را ارزیابی کرده و با الگوریتم های RLبا حالت بهینه از ابتدا به انتها برسد.
برای پیداکردن مسیر بهینه باید عامل بتواند موانع (لوله ها) را تشخیص بدهد در ازای دریافت مواد اولیه پاداش مثبت دریافت کند و در ازای رسیدن به حالات پایانی پاداش منفی دریافت کند (هزینه بپردازد) .
بر این اساس ما ازالگوریتم Q-Learning استفاده می کنیم:
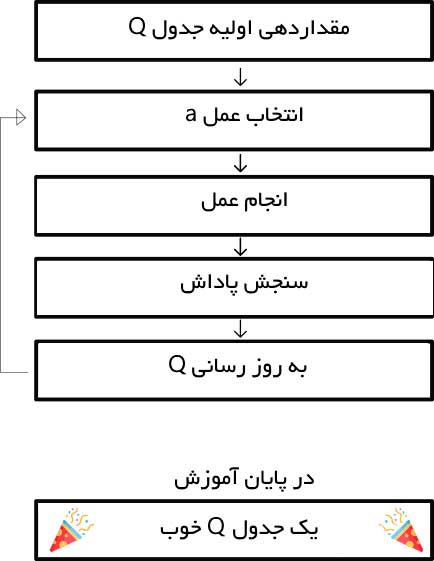
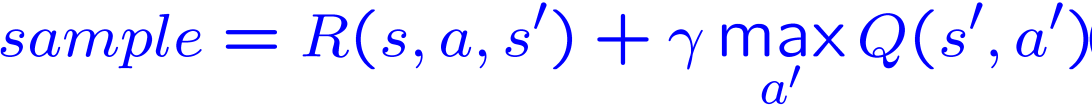
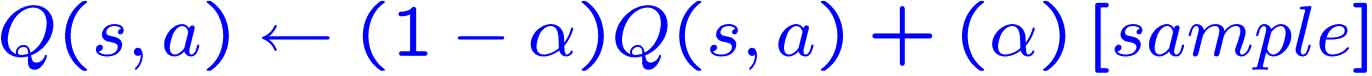
یک نرخ جستوجوی «اپسیلون» تعیین میشود که در آغاز برابر با 0.01 قرار داده میشود. این، نرخ گامهایی است که عامل به طور تصادفی انجام میدهد. در آغاز، این مقدار باید بیشترین ارزش ممکن باشد، زیرا عامل هیچ چیز درباره ارزشهای موجود در Q-table نمیداند. این یعنی نیاز به جستوجوهای زیاد و انتخاب
تصادفی اعمال توسط او است.یک عدد تصادفی تولید میشود. اگر این عدد بزرگتر از اپسیلون بود، استخراج انجام میشود (این یعنی از آنچه در حال حاضر مشخص است برای انتخاب بهترین عمل در هر گام استفاده میشود). در غیر این صورت، جستوجو صورت میپذیرد.
ایده آن است که باید یک اپسیلون بزرگ در ابتدای راه آموزش Q-function وجود داشته باشد. سپس، به تدریج و پس از آنکه اطمینان عامل در تخمین Q-valueها افزایش یافت، مقدار آن کاهش پیدا کند.
۳. آزمایش ها
نکته اولی که در آزمایش الگوریتم های یادگیری تقویتی وجود دارد این است که مانند بسیاری از الگوریتم های دیگر یادگیری ماشین هیچ داده اولیهای در دسترس نیست. زیرا این الگوریتم ها برای محیط های بسیار تعاملی مناسب هستند که نمیتوان عمل بهینه را تخمین زد. پس تنها راهی که وجود دارد این است که عامل خود وارد محیط شود و شروع به آزمایش کند و از محیط جزا یا پاداش دریافت کند. راه سریع تری که وجود دارد استفاده از محیط های شبیه سازی شده است.
محیط flappy birds علاوه بر مد قابل مشاهده یک مد برای شبیه سازی دارد که به سرعت انجام میشود و قابل مشاهده نیست. ما برای تست الگوریتم های یادگیری تقویتی از مد شبیه سازی استفاده میکنیم که بتواینم تعداد تست بیشتری را انجام دهیم. ما برای آزمایش عملکرد عامل آن را در محیط قرارداده و امتیازی که جمع آوری میکند و تعداد اکشنهای آن را یادداشت میکنیم .
نحوه امتیازدهی:
عامل به ازای رد کردن هرلوله یک امتیاز مثبت و به ازای برخورد به یک لوله 5امتیاز منفی دریافت میکند و بازی تمام میشود.حرکت های مجاز:
عامل برای حرکت 2 عمل اصلی حرکت به جلو بالا و پایین را دارد. همچنین با یک سرعت ثابت به جلو حرکت میکند.
برای حرکت عامل از الگوریتم Q-Learning استفاده کردهایم. برای تبدیل محیط به مدل مارکوف هر حالت را با توجه به 8 فاکتور تولید کرده ایم که عبارت اند از: فاصله ی طولی نا لوله ی بعد، ارتفاع عامل، فاصله عرضی تا بالا و پایین لوله ی بعد، فاصله عرضی تا بالا و پایین لوله ی بعد از آن و سرعت عامل.
ارتفاع عامل به بازه های 16تایی تقسیم شده است. فاصله طولی تا لوله بعد به بازه های 20تایی تقسیم شده است. فاصله طولی تا دولوله بعد به بازه های 512تایی تقسیم شده است. فاصله عرضی تا پایین و بالای لوله بعد به بازه های 20تایی تقسیم شده است. فاصله عرضی تا پایین و بالای دولوله بعد به بازه های 40تایی تقسیم شده است. سرعت عامل هم به بازه های 4تایی تقسیم شده است.

مقدار آلفا با استفاده از فرمول زیر بروزرسانی میشود :

مقدار اپسیلون هم با استفاده از فرمول زیر بروزرسانی میشود :

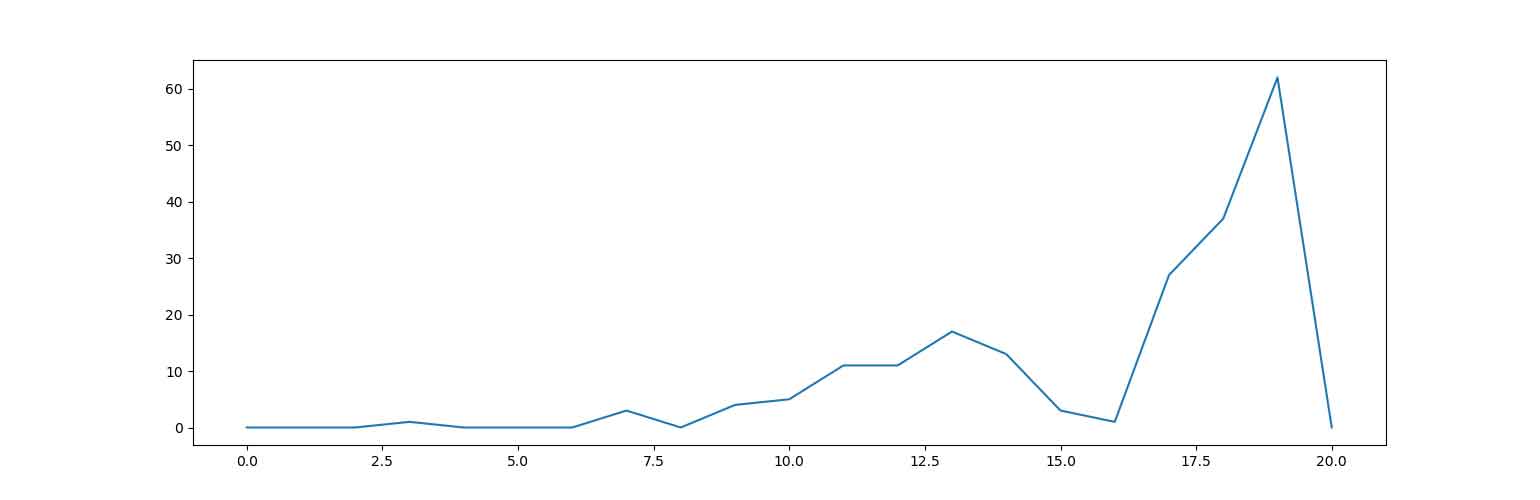
عملکرد عامل به ازای episodeهای مختلف در نمودار های زیر آمده است :
نمودار 1- تعداد اکشن های عامل بر اساس تعداد episode ها
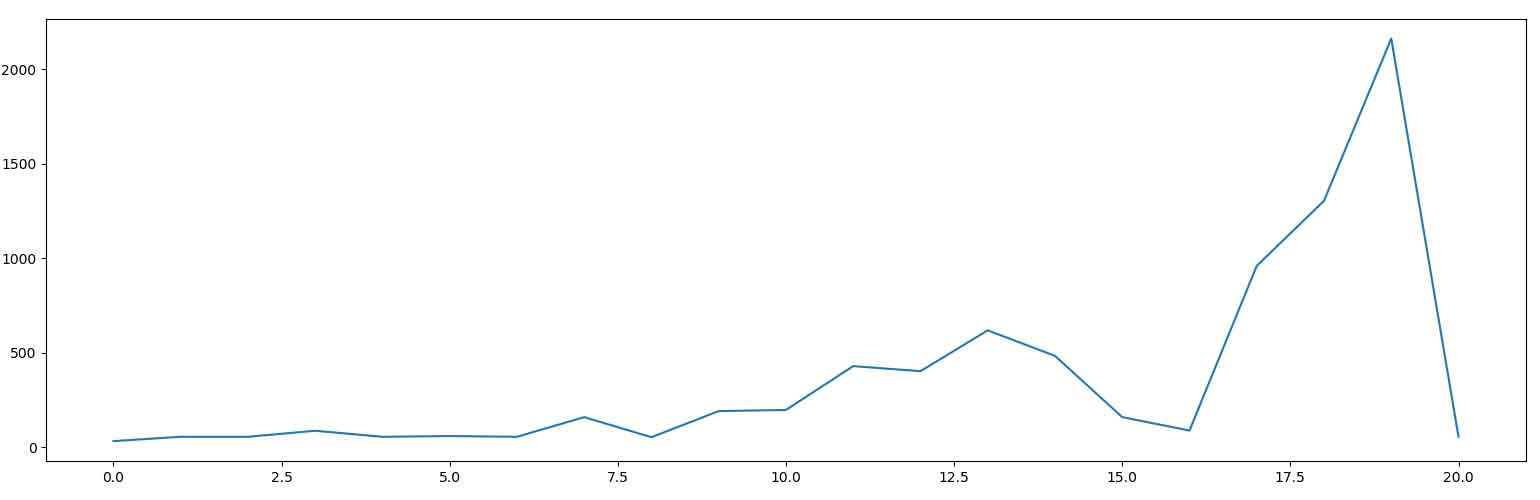
نمودار 2- پاداش دریافتی عامل بر اساس تعداد episode ها
نمونه خروجی :
Episode 500 finished after 62.000000 time steps
cumulated reward: -5.000000
exploring rate 0.500000
learning rate 0.500000
Episode 1000 finished after 62.000000 time steps
cumulated reward: -5.000000
exploring rate 0.500000
learning rate 0.500000
Episode 1500 finished after 62.000000 time steps
cumulated reward: -5.000000
exploring rate 0.500000
learning rate 0.500000
Episode 2000 finished after 62.000000 time steps
cumulated reward: -5.000000
exploring rate 0.500000
learning rate 0.500000
Episode 2500 finished after 62.000000 time steps
cumulated reward: -5.000000
exploring rate 0.432779
learning rate 0.500000
Episode 3000 finished after 62.000000 time steps
cumulated reward: -5.000000
exploring rate 0.366032
learning rate 0.500000
Episode 3500 finished after 62.000000 time steps
cumulated reward: -5.000000
exploring rate 0.309580
learning rate 0.500000
Episode 4000 finished after 59.000000 time steps
cumulated reward: -5.000000
exploring rate 0.261834
learning rate 0.500000
... در ادامه :
Episode 12000 finished after 62.000000 time steps
cumulated reward: -5.000000
exploring rate 0.017951
learning rate 0.500000
Episode 12500 finished after 62.000000 time steps
cumulated reward: -5.000000
exploring rate 0.015182
learning rate 0.500000
Episode 13000 finished after 74.000000 time steps
cumulated reward: -4.000000
exploring rate 0.012841
learning rate 0.500000
... و در ادامه :
Episode 49500 finished after 627.000000 time steps
cumulated reward: 10.000000
exploring rate 0.010000
learning rate 0.500000
۴. پیوندهای مفید:
https://medium.freecodecamp.org/an-introduction-to-q-learning-reinforcement-learning-14ac0b4493cc
https://www.cse.unsw.edu.au/~cs9417ml/RL1/algorithms.html
https://blog.faradars.org/reinforcement-learning-and-q-learning/
https://skymind.ai/wiki/deep-reinforcement-learning
http://en.wikipedia.org/wiki/Reinforcement_learning
۵. مراجع:
Richard S. Sutton and Andrew G. Barto."Reinforcement Learning An Introduction"
Algorithms for Reinforcement Learning - Csaba Szepesvári