Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
ترجمه ی تصویر به تصویر دسته ای از مسئله های گرافیکی و بینایی است که هدف در آن یادگیری نگاشت بین دسته عکس ورودی و خروجی بااستفاده از مجموعه های دوتایی داده برای یادگیری است. هرچند برای خیلی از موارد دسته عکس های دوتایی برای یادگیری موجود نمیباشد. ما در این مقاله روشی را برای ترجمه عکسی در دامنه X به عکسی در دامنه Y ارائه میدهیم بدون داشتن دسته عکس های دوتایی مچ شده(paired) .هدف ما یادگیری نگاشت G:X->Y بااستفاده از الگوریتم رقابتی است به صورتی که که توزیع داده ای (G(X از Yغیرقابل تفکیک باشد.چون این نوع نگاشت به شدت غیر قطعی است ما این راه را با یک نگاشت معکوس همراه کردیم F:Y->X و یک سازش حلقه ای را به عنوان یک شرط اجباری معرفی کردیم یعنی F(G(X))->X (و برعکس) نتایج شامل انتقال استایل ,تبدیل فصول و بهبود عکس میباشد.
۱. مقدمه و معرفی
تصور کنید صحنات یا اشیایی را میخواهیم ببینیم که تا به حال ندیده ایم و یا تصور آن به شدت مشکل است و یا امکان به وجود آمدنشان تقریبا غیر ممکن است.برای مثال تصور یک منظره یا چهره از دیگاه یک هنرمند مشهور با سبک و سیاق نقاشی خاص خودش یا تصور تابستان در قطب جنوب و ...
هرچند برای مثال, تابستان شدن قطب جنوب را ندیدیم, اما میدانیم تابستان بودن چه خصوصیاتی دارد و هچنین قطب جنوب چه شمایلی دارد لذا میتوانیم خصوصیات را منتقل کنیم و تصویر جدید را خلق کنیم.
در این مقاله ما میخواهیم کار مشابه ای انجام بدهیم بدست آوردن خصوصیات منحصر به فرد یک دسته از تصاویر و پیدا کردن روشی برای انتقال این ویژگی ها و یا به عبارتی ترجمه ی آن ها در عکس های دیگر بدون داشتن هیچ مجموعه یادگیری دوتایی و نگاشت قبلی.
ما فرض میکنیم که یک ارتباط زیرین نهفته بین دو دامنه وجود دارد -برای مثال دو رندر متفاوت از یک صحنه- و تلاش میکنیم که آن را یاد بگیریم.

مسئله یادگیری یک نگاشت G بین دامنه تصاویر X به Y میباشد به طوریکه خروجی y' با تصاویر دامنه Y از نظر پراکندگی داده ای تفاوتی نداشته باشند.
لذا G بهینه دامنه X را به دامنه Y' طوری ترجمه میکند که Y' توزیع داده ای مشابه ای با Y دارد. هرچند این گونه ترجمه ها تضمینی برای معنی دار بودن ترجمه بین ورودی x و خروجی y نمیدهد. در عمل بهینه کردن این نوع یادگیری رقابتی ساده نیست و به مشکل همیشگی mode collapse برمیخوریم که یادگیری دیگر اثربخش نخواهد بود.
این مشکل می طلبد که ساختار های بیشتری را به الگوریتم اضافه کنیم, لذا ما چک میکنیم که ترجمه باید به صورت چرخشی سازگار باشد (cycle consistent)
این یعنی برای مثال اگر یک متن را از فارسی به انگلیسی ترجمه میکنیم هنگامی که متن تولید شده از انگلیسی به فارسی ترجمه میشود باید معنی یکسان با جمله ی اولیه فارسی داشته باشد.به زبان ریاضی اگر G:X->Y و F:Y->X باید F و G معکوس یکدیگر باشند.
ما این روش را با آموزش G و F و اعمال cycle consistency loss کامل میکنیم که هدف ما را به صورت کامل اغنا میکند.ما از این روش در حوضه های گوناگونی مثل انتقال حالت,دگرشکل سازی , تغییر فصل و بهبود کیفیت تصاویر استفاده میکنیم.
۲. کارهای مرتبط
GANs(Generative Adversial Networks)
این فیلد موفقیت های گوناگونی را در زمینه های تولید و ادیت عکس توسط ماشین کسب کرده است.کلید موفقیت در GAN ها یک بازی رقابتی است که سیستم را مجبور به تولید عکس هایی میکند که با واقعیت تمایز نداشته باشند.این متد به خصوص برای تولید عکس و محتوای گرافیکی مفید میباشد زیرا این همان هدفی است که گرافیک های کامپیوتری سعی در بهینه کردن آن دارند. ما هم از یک بازی رقابتی استفاده میکنیم برای اینکه عکس های نگاشت شده به دامنه مورد نظر با عکس های همان دامنه تفاوتی نداشته باشند.
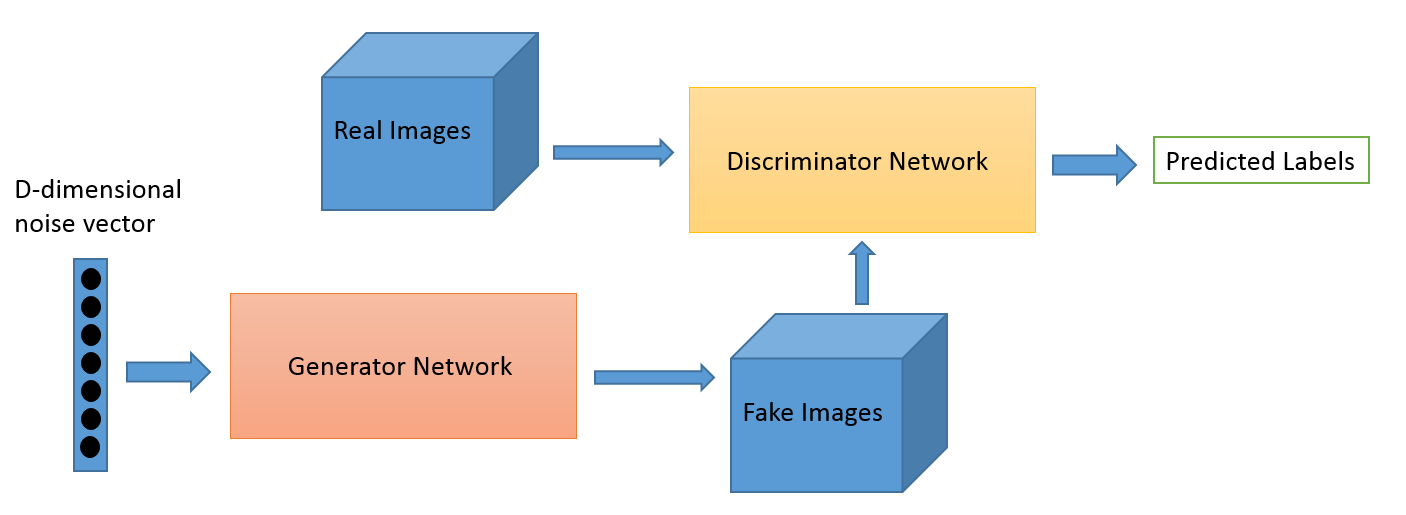
image-to-image translation
ایده ترجمه تصویر به تصویر اولین بار توسط Hertzman مطرح شد که یک روش غیر پارامتری را روی یک ورودی و خروجی آموزشی تکی اعمال میکند.روش های جدید تر توسط CNN ها برای ترجمه ی پارامتری از چند dataset ورودی-خروجی آموزشی استفاده میکنند.روش ما بر مبنای فریمورک "pix2pix" از Isola کار میکند که از یک شبکه ی رقابتی شرطی استفاده میکند تا نگاشت بین ورودی و خروجی را بیابد.ایده های مشابه برای کار های گوناگون انجام شده مثل تبدیل عکس به نقاشی و ... اما تفاوت کار ما این است که نگاشت را بدون یادگیری pair شده انجام میدهیم.
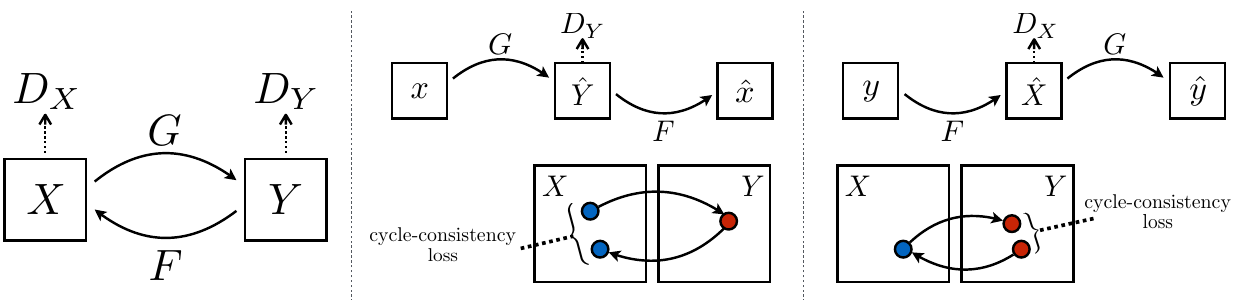
Cycle Consistency
این ایده که برای ریگولارسازی از خاصیت رفت و برگشتی استفاده کنیم ریشه قدیمی دارد.در بحث ترجمه ی زبان برای بهبود و معتبر سازی ترجمه از روش "back translation and reconciliation" بهره میگرفتند. اکه اخیرا cycle consistency های سطح بالاتری در 3D shape matching , dense semantic alignment و depth estimation استفاده میکنند .از این بین Zhou و Godard بسیار به کار ما شبیه هستند از آنجایی که هردو از cycle consistency loss برای کنترل CNN استفاده میکنند.ما هم از این روش برای چک کردن سازگاری نگاشت های G و F استفاده میکنیم.
۳. راه حل ارائه شده
ما برای راه حل پروژه بعد از تحقیق به الگوریتم cycleGAN رسیدیم که از دو gan تشکیل می شد که هر کدام از عکس هایی که به یکی از ان ها داده می شد دو بار با استفاده از ژنراتور ها به یکدیگر تبدیل می شوند و هر کدام از discriminator ها درصد خطا ها را تشخیص می دهند . در کل هدف این است که عکس را از یک دامنه به دامنه ی دیگری از دیتاست ببریم سرانجام عکس اولیه را دوباره بسازیم که این عملا ممکن نیست و عکس ساخته شده دارای کیفیت کمتر و دقت کمتریست، ولی با این وجود به دامنه ی اولیه بازگشته ایم و می توانیم loss function را حساب کنیم و عکس ایده آل یعنی عکس اولیه را بسازیم.
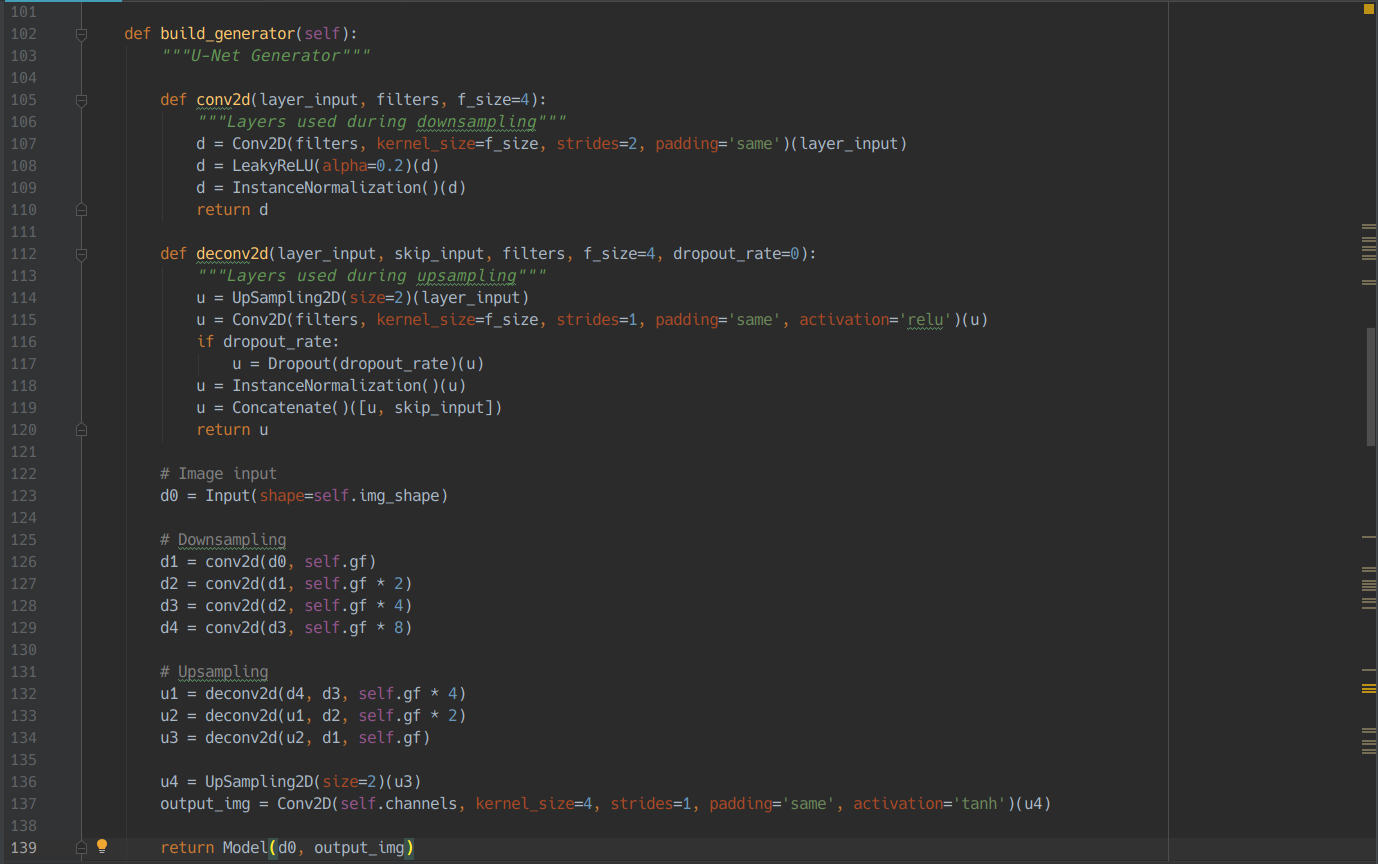
ما برای یافتن راه حل این مشکل ابتدا باید generator و discriminator را میساختیم.ابتدا generator که پیاده سازی دشوار و پیچیده ای داشت را انجام دادیم.وظیفه ی این واحد تولید عکس جدید با توجه به عکسی که به آن داده بودیم بود. پس ابتدا عکس را دریافت میکند و با اعمال لایه ها ی کانالوشنی feature های مهم و تاثیر گذار تشخیص داده شده را استخراج و هر بار فشرده تر میکنیم که به این کار Downsampling میگویند.بعد از اینکه Downsampling انجام شد هر کدام از این فیلتر ها را اکنون باید با استفاده از تکنیک های Upsampling جزئیات لایه مورد نظر را بیشتر کنیم.به طور کلی Upsampling به بزرگ کردن و افزایش جزئیات یک تصویر کوچک تر و حتی رمز گشایی پیکسل های آن می گویند.لایه های deconv2d ابتدا وردوی را Upsample2D میکند که در اینجا یعنی بزرگ کردن ابعاد عکس سپس ان را از یک فیلتر Conv2D عبور داده و سپس لایه را nromalize کرده و سرانجام این لایه به دست آمده را با لایه ای که قبلا در مرحله کانوالو کردن از آن استفاده کردیم را به هم متصل می کند. در نهایت دوباره لایه به دست آمده را Upsample2D کرده و سرانجام یک لایه فیلتر کانوالو از آن عبور داده و با عکس اولیه به عنوان model خروجی می دهیم.
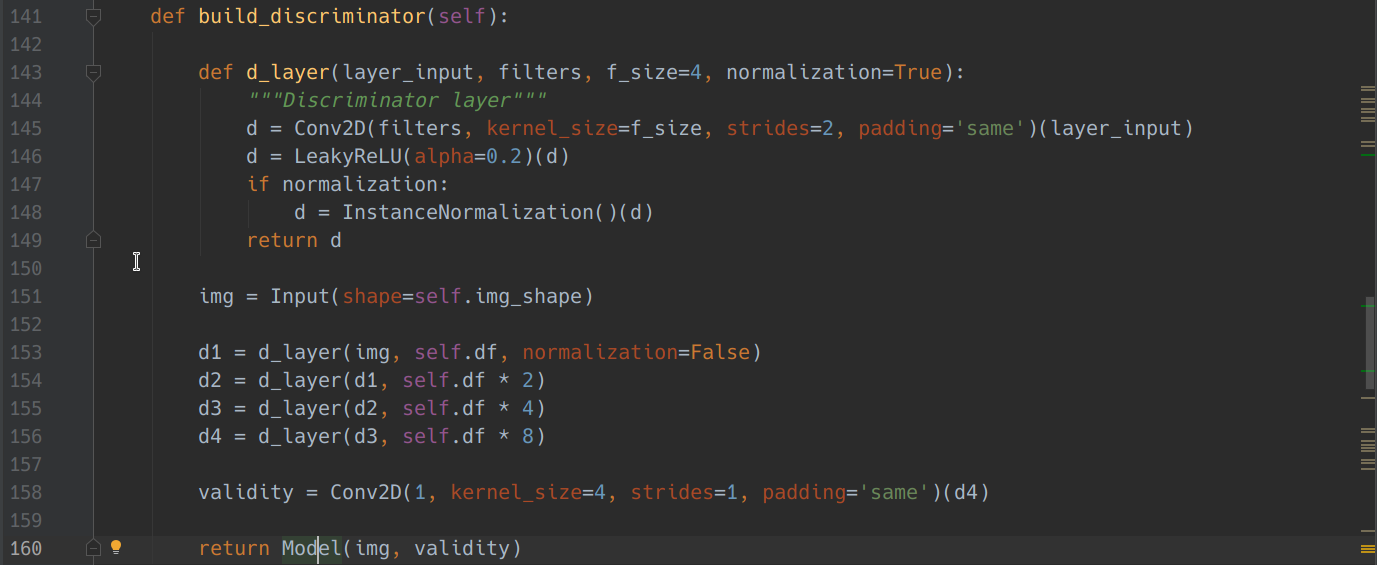
پس از ساختgenerator ،واحد discriminator را که پیاده سازی آن نسبتا راحت تر از generator بود را طبق کد زیر ساختیم در واقع این شبکه عصبی مانند شبکه های عصبی معمولی یک عدد بین ۰ تا ۱ به ما میدهد که تعیین میکند این عکس واقعی است یا خیر.پس عکس بعد ار اینکه به generator داده شد به discriminator داده میشود و طبق شکل زیر این واحد از ۴ لایه داخلی که در هر کدام از آن ها را Conv2D اعمال میکنیم و سپس activation function انتخابی را استفاده میکنیم.(LeakyRelu).علت انتخاب این نوع activation function این بود که ما همواره یک سری نویز در تصاویر داریم و با حذف شدن کل تصاویر ممکن است قسمتی از جزئیات اصلی تصویر نیز حذف شود و discriminator در انتخاب خود دچار اشتباه شود به همین دلیل از این تابع به جای تابع Relu استفاده کردیم چون تابع Relu جزئیات با اعداد منفی که در واقع یک سری از feature ها با مقدار منفی در هر sample هستند را به طور کلی صفر میکند و این در تشخیص جزئیات تصویر discriminator را دچار اشتباه میکند.همچنین به جز لایه اول که input میگیریم نمونه ها را normalize میکنیم که بار محاسباتی مسئله را نیز می کاهد.در نهایت تابع بار دیگر یک فیلتر کانالوشنی روی لایه آخر اعمال کرده و به همراه ورودی آن را مدل کرده و به شبکه عصبی پاس می دهیم.
بحال فرض کنید ما دیتاستی از عکس های زمستان و تابستان داریم و قصد داریم عکس های تابستان را به عکس های زمستان و عکس های زمستان را به عکس های تابستان تبدیل کنیم. بعد از اینکه واحد generator و discriminator را ساختیم با استفاده از شبکه عصبی به دست آمده عکس های تابستان را به generatorAB میدهیم که وظیفه آن تولید عکس زمستان است.به صورت تقریبا همزمان عکس های زمستان را به generatorBA می دهیم که وظیفه ی آن تولید عکس تابستان است.حال هر کدام از این عکس های fake به discriminator های خود ارسال می شوند و discriminator عددی بین ۰ تا ۱ تولید می کند که میزان واقعی بودن هر کدام از عکس ها را مشخص می کنددر اینجا به اختصار فرآیند عکس اول را توضیح می دهیم..Loss این قسمت از تبدیل عکس، از طریق فرمول زیر محاسبه می شود:
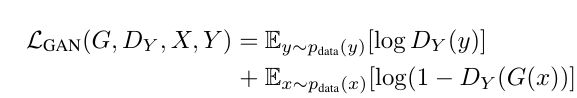
بعد از این تبدیل،عکس را با استفاده از generatorBA دوباره به تابستان تبدیل می کنیم و دوباره Loss این قسمت را به صورت مشابه با در فرمول بالا جایگذاری میکنیم. بعد از این که عکس به دست آمد با استفاده از فرمول MAE ، تفاوت این عکس تابستانی با عکس اولیه ورودی را حساب می کنیم و Loss این قسمت از تبدیل عکس نیز به دست می آید.با استفاده از فرمول زیر:
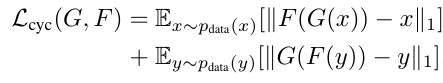
سر انجام برای محاسبه Loss Function از فرمول زیر استفاده می کنیم:
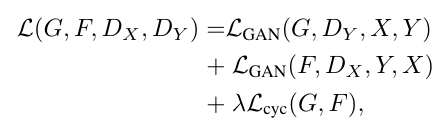
در واقع این فرمول در optimization و آپدیت کردن وزن ها استفاده می شود..
ما برای بهینه سازی نورون ها در شبکه عصبی از adam optimizer استفاده کردیم که از جمله بهترین optimizer ها در شبکه های عصبی مربوط به پردازش تصویر است.این الگوریتم در واقع مشتق شده از الگوریتم momentum optimizer و RMSprop می باشد و از روش backpropagation در طول بهینه سازی استفاده می کند و فقط فرمول های آن برای بهینه سازی فرق می کند.
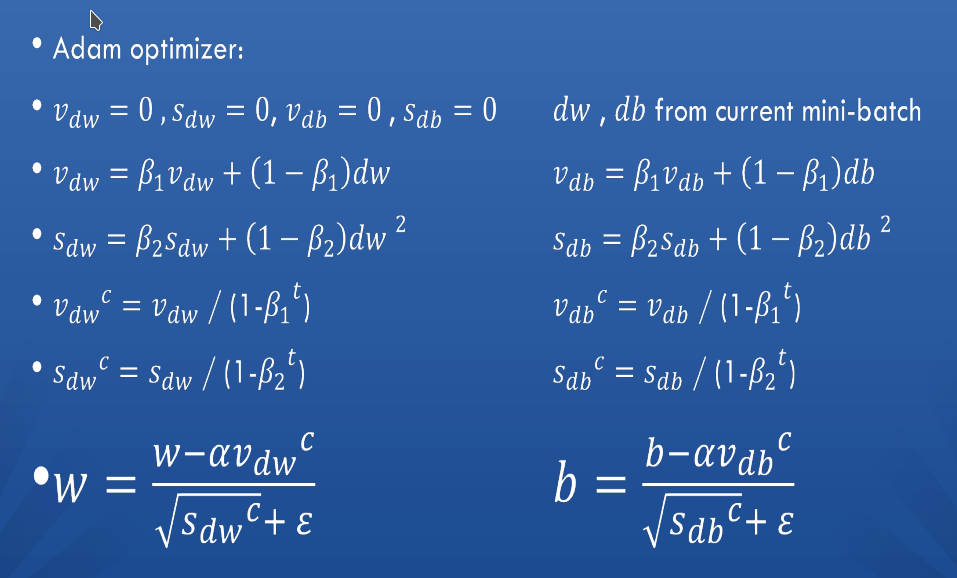
۴. آزمایش ها
با توجه به درصد دقت های جمع آوری شده در dataset apple2orange میتوان فهمید که راه حل ما موثر بوده و با افزایش زمان learn شدن و تعداد epoch ها با تقریب خوبی درصد دقت بالا رفته است.
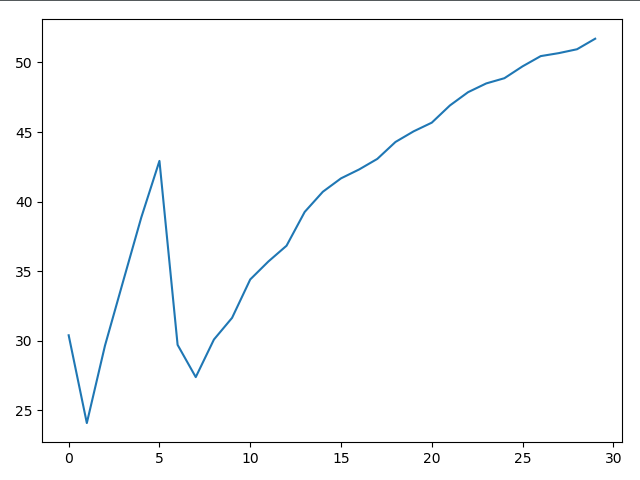
مطمئنا با افزایش طول epoch ها به طور کلی میزان یادگیری نیز افزایش می یابد و این درصد به بالای۹۰ می رسد.
همچنین با استفاده از تست دیتاست های مختلف بر روی شبکه ی عصبی نمودار های زیر به دست آمدند.
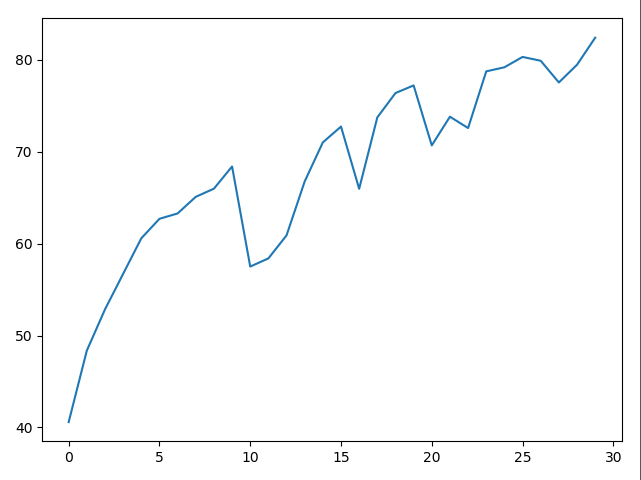
پس دیتاست مورد استفاده نیز در مسئله تبدیل عکس نیز مؤثر می باشد به طور مثال در این دیتاست با وجود اینکه سیستم فقط ۳۰ epoch توانسته learn کند و درصد دقت به بالای ۸۰٪ رسیده است.
همچنین با مقایسه دو نمودار زیر که یکی با استفاده از Adam optimizer و دیگری با RMSprop learn شده اند تفاوت درصد دقت آن ها را متوجه شد.
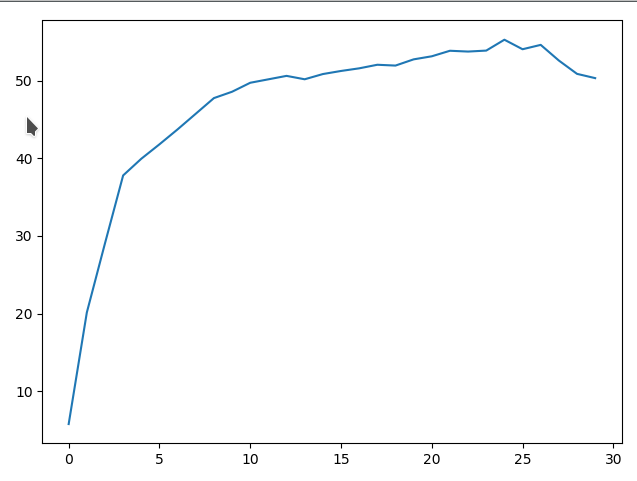
با ماقایسه دو تصویر بالا می بینیم که نمودار RMSprop به دلایل نامعلومی پس از مدتی درصد دقت خود را از دست داده شاید به خاطر overfit کردن بر روی قسمتی از دیتاست درصدش بالا رفته است ولی Adam optimizer به صورت کلی روند رو به رشدی داشته است.پس بهتر است از الگوریتم Adam استفاده کنیم.
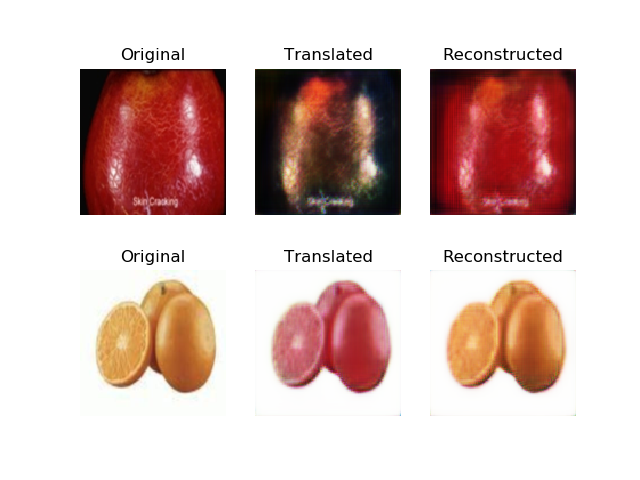
مقایسه دو عکس(در هر دو عکس عکس بالایی) یکی تبدیل یافته با RMSprop و دیگری تبدیل یافته با Adam optimizer
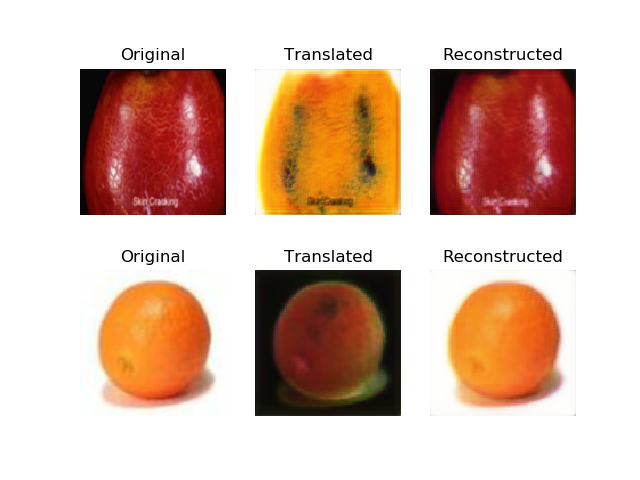
۵. تحلیل و تفسیر نتایج و چالش ها
هدف این پروژه به صورت کلی تبدیل عکس با یک سری از ویژگی به عکس به سری ویژگی های دیگر می باشد و به طور خاص برای تبدیل تصویر به تصویر در حالتی که تصویر ها یک به یک نیستند طراحی شده است.در واقع در یک سری از جاها مانند تبدیل عکس گورخر به اسب این یک به یکی معنی ندارند چرا که ما نمی توانیم تصویر یک اسب و گورخر با تصویر پس زمینه یکسان و اندازه یکسان بیابیم.در واقع سیستم در این پروژه دو عکس میگیرد و با هر کدام با استفاده از generator های مخصوص آن عکس،یک عکس fake میسازد که نهایتا با استفاده از شبکه های عصبی با تقریب خوبی عکس واقعی به نظر می آید و عکس در واقع تبدیل یافته ی یک عکس با یک سری ویژگی به همان عکس با ویژکی های یکسان می باشد. شاید اگر از optimizer بهتری استفاده می کردیم و تعداد فیلتر ها برای هر کدام از generatorها و discriminator ها را افزایش می دادیم و یا تعداد لایهی آن ها را افزایش می دادیم نتایج بهتری می گرفتیم ولی باید توجه داشت ما با همین پیاده سازی حداقلی نیز مشکل gpu و زمان طولانی پردازش داشتیم چه برسد به آن تغییرات.میتوانستیم در محاسبه loss کلی از MSE استفاده کنیم به جای MAEاما MAE به نظر معیار بهتری می آمد چون که می توانیم اختلاف پیکسل به پیکسل هر sample را داشته باشیم با این روش. هدف پروژه یادگیری یک سری خاصیت کلی از محیط هاست و با افزایش دیتاست بالطبع درصد دقت آن نیز افزایش می یابد.در این پروژه ما توانستیم با وجود دیتاست کم و سخت افزار نامناسب برای یادگیری و همچنین مشکلات google colab و استفاده از gpu سریع تر به نتایج نسبتا خوب و شگفت انگیزی برسیم.از جمله نتایجی که از ران کردن پروژه گرفتیم این بود که تعداد بتچ ها باید با توجه به دیتاست انتخاب شود.مثلا برای دیتاست تبدیل فصلی به فصل دیگر وارد کردن دیتا به صورت بتچ با سایز نسبتا بالا و آپدیت کردن جمعی آن ها نتیجه بهتری میدهد در حالی که برای دیتاست سیب به پرتقال batch با سایز کم و حتی load کردن به صورت single مناسب تر به نظر می رسید که با توجه به نبود زمان ،نتوانستیم همه ی نتایج را به صورت آماری در بیاوریم.همچنین افزایش تعدادepoch ها با تقریب خوبی باعث افزایش دقت می شود.





۶. آینده کار
می شود روی این پروژه کار کرد و بتوان فیلم های گرفته شده را نیز از یک فرمت به فرمت دیگر تبدیل کرد یا یک ویژگی را از فیلمی با این فیلم ادغام کرد و به طور مثال یک فیلم به صورت نقاشی ون گوک یا monet داشت.همچنین می توان از این زمینه در پیش بینی تغییرات محیطی همانند روز و شب،بارندگی و آفتابی،برفی و ساحلی و ... استفاده کرد.احتمالا می توان با اضافه کردن یه راس دیگر در این حلقه دقت آن را در مقیاس بزرگ تری از دیتا ست بالا برد مثلا حلقه سه تایی از gan ها که generator هر کدام عکس را از دامنه به دامنه ای دیگر از تصاویر می برند.این کار ممکن است در افزایش دقت و دقیق تر شدن loss function مؤثر باشد.
۷. ابزار ها و مراجع
ابزار های و تکنولوژی های مورد استفاده ما عبارت اند از
Keras
Python
Tensorflow(Keras's backend)
Google Colab
Github
همچنین برای رفتن به آدرس repository پروژه لینک زیر را کلیک کنید.
https://github.com/aryana761227/cycleGAN
مراجع مورد استفاده ما