به نام خدا
مسئله مورد مطالعه پروژه این است که با استفاده از اطلاعات فیلمها و امتیازاتی که در مجموعه داده MovieLens به هر فیلم توسط هر کاربر داده شدهاست و همچنین ویژگیهای کاربرها از جمله جنسیت، سن، شغل و محدوده جغرافیایی با استفاده از روشهای یادگیری ماشین به دستهبندی کاربران بر اساس امتیازی که به فیلمهای مشابه دادهاند بپردازیم و امتیاز هر فیلم توسط هر کاربر مجزا را پیشبینی نماییم.
۱. مقدمه
امروزه سیستم های توصیهگر همه جا وجود دارند اگر در آمازون به دنبال یک کتاب یا در فسیبوک به دنبال یک پست خاص باشید شما بدون اینکه در جریان باشید از سیستمهای توصیهگر استفاده میکنید .
در خرید آنلاین، مشتری به تعداد نامحدودی حق انتخاب خرید دارد هیچ کس زمان کافی برای امتحان تمام محصولات را ندارد.
سیستمهای توصیهگر نقش مهمی را در کمک کردن به کاربران در پیدا کردن محصول یا محتوای مورد علاقهشان دارد.
یکی از مشکلاتی که خیلی از افراد ممکن است داشته باشند پیدا کردن فیلم مورد علاقه آن هاست.بیشتر افراد به دلیل کمبود وقت ،عدم وجود حوصله کافی برای جست و جو و غیره به یک سیستم که با توجه به علاقه مندی ها قبلی آ ن ها بتواند فیلم مورد علاقه ان ها را پیشنهاد دهد.

سامانه پیشنهاد فیلم شاخه ای از سامانه های توصیه گر محسوب می شود.سامانه ی توصیه گر سامانه ای است که با بررسی رفتار کاربر خود، مناسب ترین داده را به وی پیشنهاد می نماید.هدف از این پروژه توسعه یک سامانه پیشنهاد فیلم میباشد که با استفاده از سابقه فیلمهای دیده شده توسط یک کاربر و امتیازات او به فیلمها، بتواند فیلمی را مطابق سلیقه کاربر به او پیشنهاد بدهد.
۲. کار های مرتبط
الگوریتم های زیادی برای ایجاد یک سیستم پیشنهادی وجود دارد که هرکدام مزیا و معایبی خاص خود را دارند مانند:
الگوریتم محتوا محور :
این روش به شباهت فیلم هایی که پیشنهاد شده اند تکیه می کند.
ایده کلی این روش این است که اگر شما یک فیلم را پسندیدید آنگاه فیلمی مشابه آن را نیز خواهید پسندید. هنگامی که بتوان به آسانی مشخصات مهم فیلم را استخراج کرد این روش به خوبی کار می کند.
در این روش شباهت بین کاربران نادیده گرفته میشود.
برای مثال این الگوریتم برای دو موسیقی به این شکل کار می کند:

حال می خواهیم شباهت دو موسیقی را نسبت به یکدیگر اندازه بگیریم:
برای هر کدام از ویژگی ها وزنی قائل می شویم
برای موسیقی های دیگر نیز همین روش را انجام می دهیم در نهایت به ماتریس زیر می رسیم :
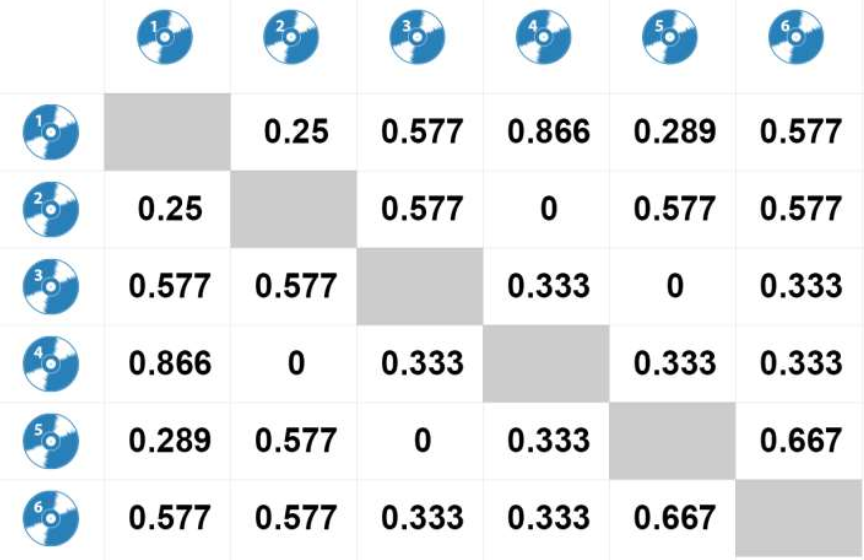
حال می توانیم به کاربر موسیقی که بیشترین تشابه به موسیقی مورد علاقه وی را دارد پیشنهاد بدهیم.
معایب :
در این روش نیاز به ویژگی های یک آیتم داریم و استخراج همه ویژگی های یک آیتم کار سخت و در برخی از موارد نشدنی است. همچنین دقت این روش در صورتی که ویژگی ها به اندازه کافی زیاد نباشند پایین می باشد.
الگوریتم فیلتر مشارکتی :
روشی است برای پیشبینی خودکار در مورد علاقه یک کاربر که با جمع آوری اطلاعات در مورد علاقه کاربران زیادی بدست آمده است.
فرض اساسی در مورد فیلتر مشارکتی این است که اگر شخصالف در مورد یک موضوع نظر مشابهی با شخص ب داشته باشد احتمال این که شخص الف در مورد موضوعی دیگر نظری مشابه فرد ب داشته باشد بالاست.
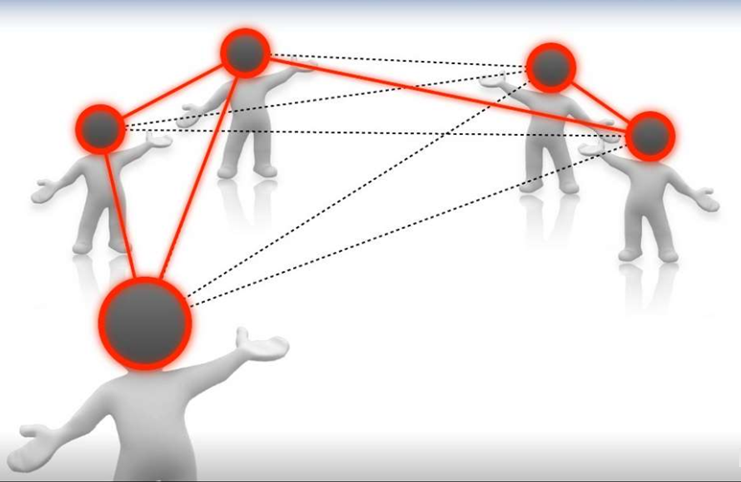
سه روش اصلی برای این الگوریتم وجود دارد:
در هر سه روش دو قدم اصلی وجود دارد:
چه تعداد کاربر یا فیلم در پایگاه داده شباهت به کاربر یا فیلم داده شده دارند.
دسترسی به فیلم بقیه کاربر ها و پیش بینی نمره ای کاربر به فیلم خواهد داد و مقایسه با میانگین نمرات همه کاربران و ماتریس تجزیه برای پیشنهاد ها
۳. آزمایش ها
استخراج داده: 6
1.تعریف متغیر ها برای ذخیره و بازیابی فایل ها :
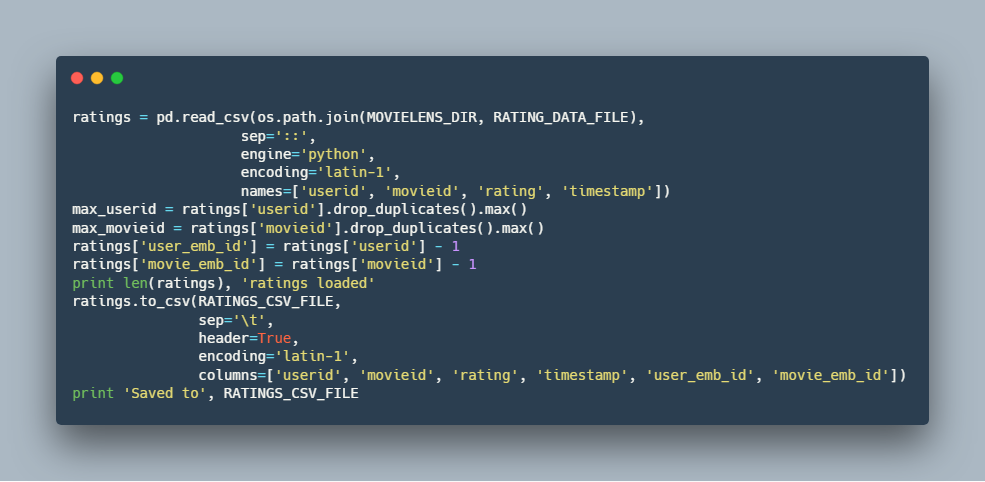
2.بارگذاری یک میلیون دیتا از سایت :
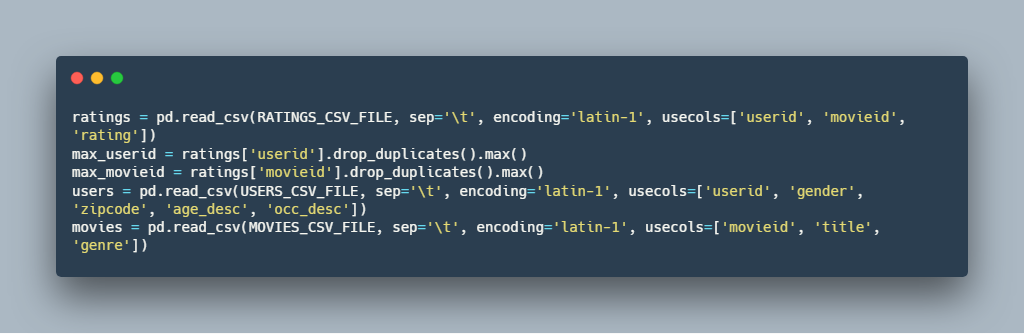
در این قسمت اطلاعات کاربران و همچنین فیلم ها و امتیازات هر کاربر بارگذاری می شود.
لازم به ذکر است که برخی از فیلم ها ویژگی و یا امتیاز ندارند.
برای آسان تر کار کردن با فریم ورک کراس 7 کار های زیر نیز انجام گرفت :
تعیین حداکثر تعداد کاربر
تعیین حداکثر تعداد فیلمی که امتیاز دهی شده است
اضافه کردن یک ستون برای فیلم یا کاربرانی که اطلاعاتی در مورد آنها وجود ندارد.
امتیازات :
کاربران :
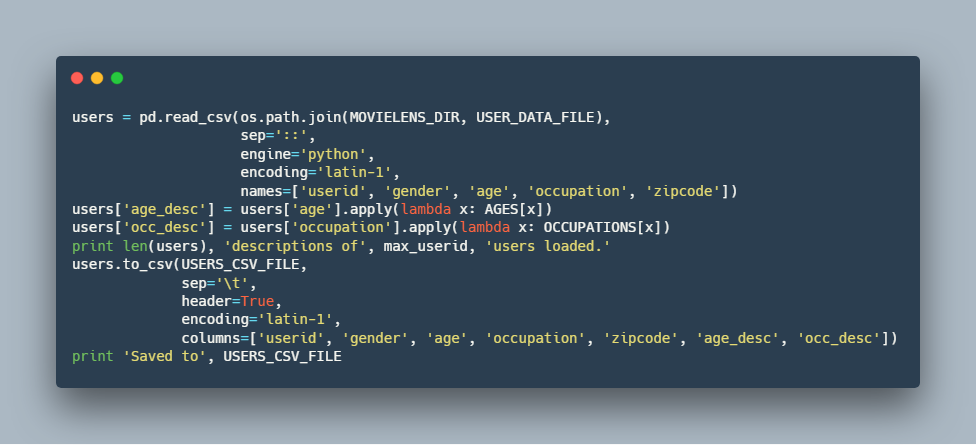
فیلم ها :
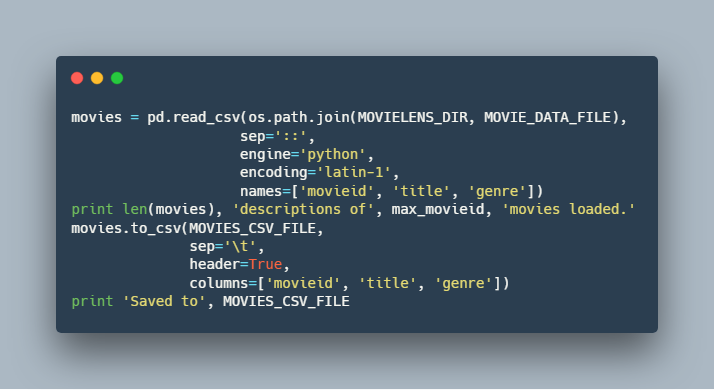
یادگیری مدل : 8
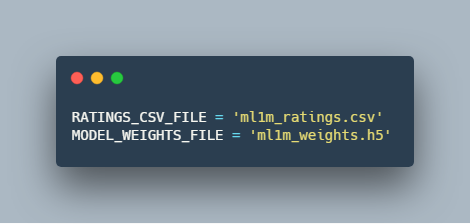
1.تعریف متغیر ها برای بازیابی اطلاعات استخراج شده در قسمت قبل
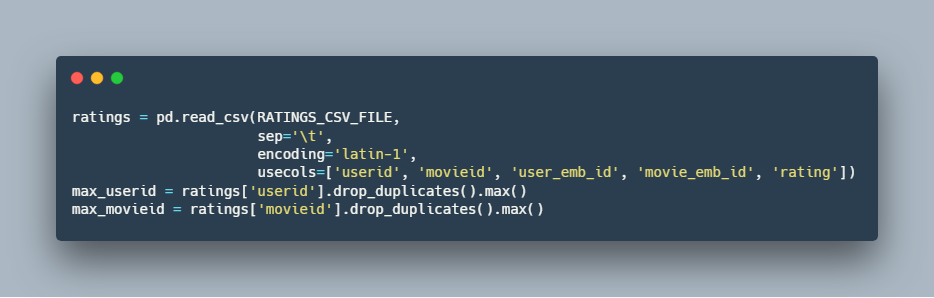
2.بارگذاری اطلاعات
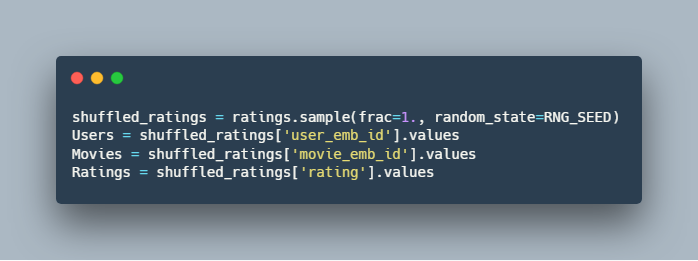
3.ساخت مجموعه یادگیری :9
4.تعریف و یادگیری مدل :
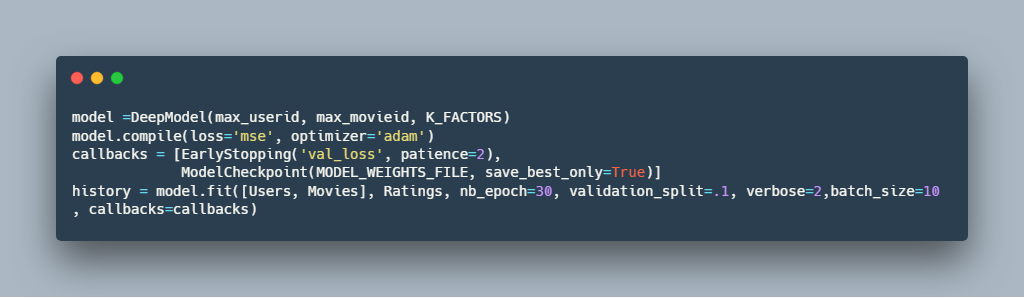
توصیه گر: 10
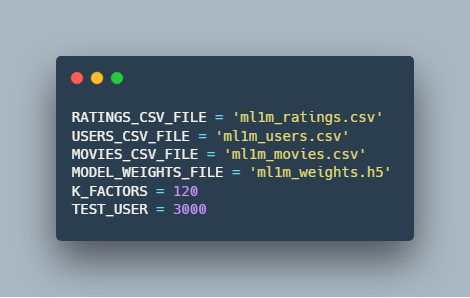
1. تعریف متغیر ها برای بازیابی اطلاعات :
2.بارگذاری اطلاعات:
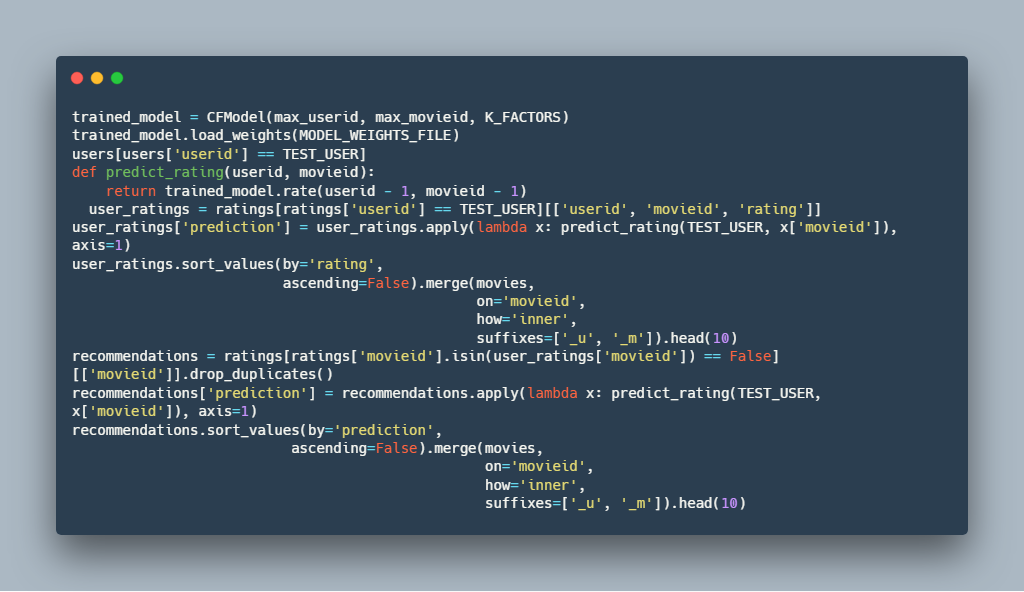
3.توصیه به کاربران :
تعریف دو مدل یادگیری :
در اینجا دو مدل پیاده سازی شده اند.
فیلتر مشارکتی :
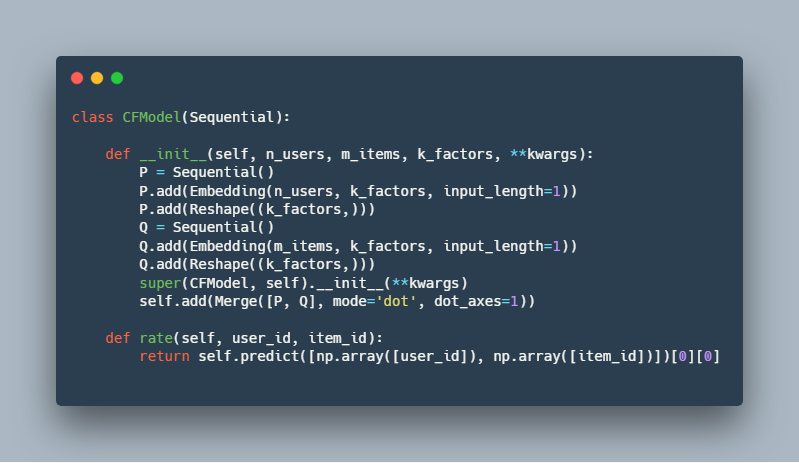
یادگیری عمیق :
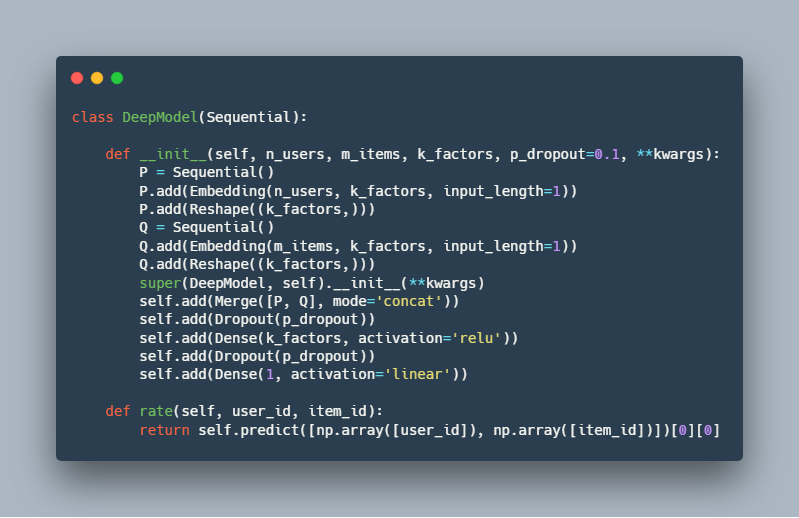
۴. نتایج
نتایج به دست آمده با توجه به ویژگی های متفاوت:
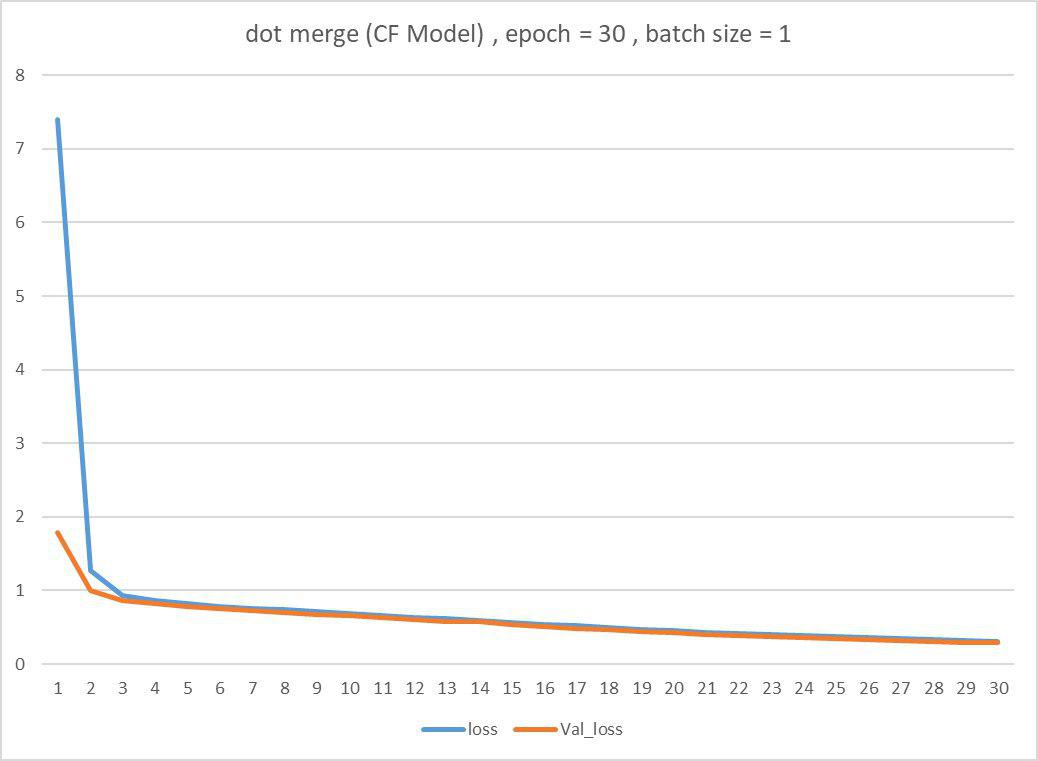
1. CFModel , epoch=30 :
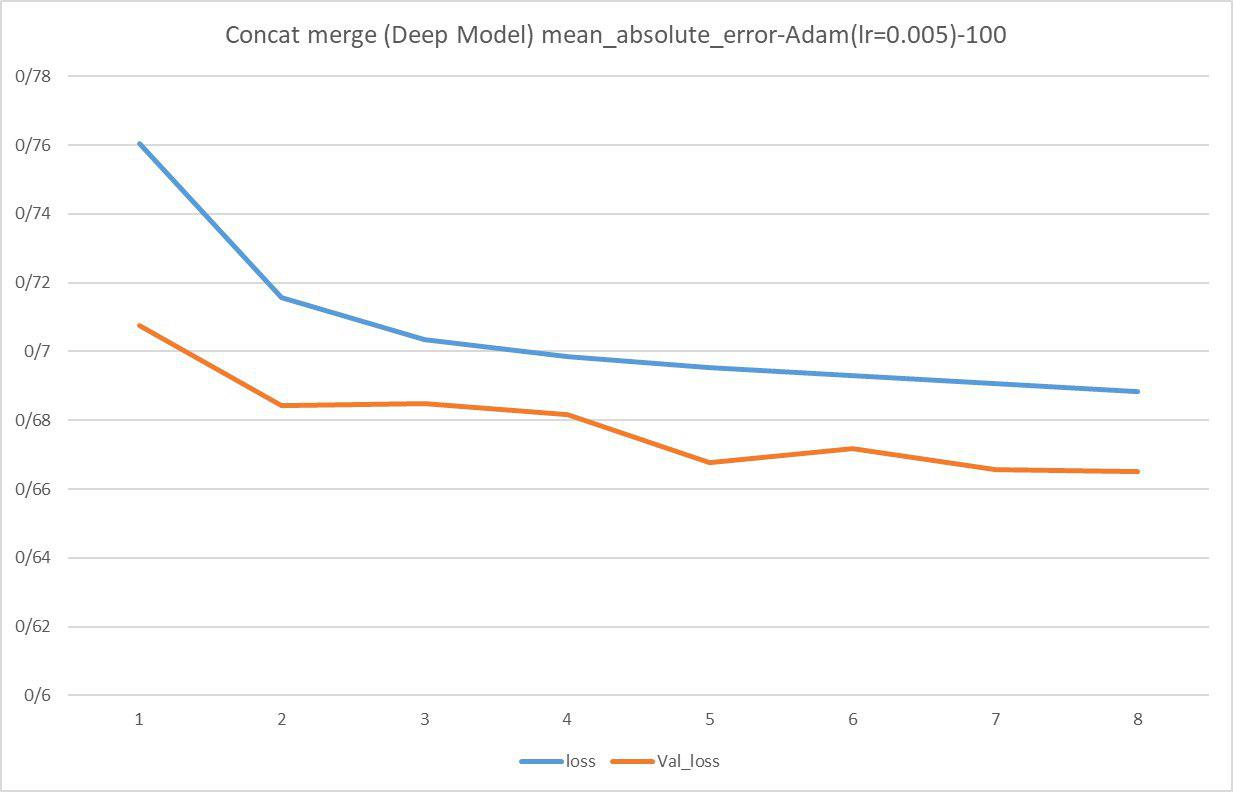
2.DeepModel , epoch=8 , loss = mean_absolute_error , optimizer = Adam , batch_size = 100 :
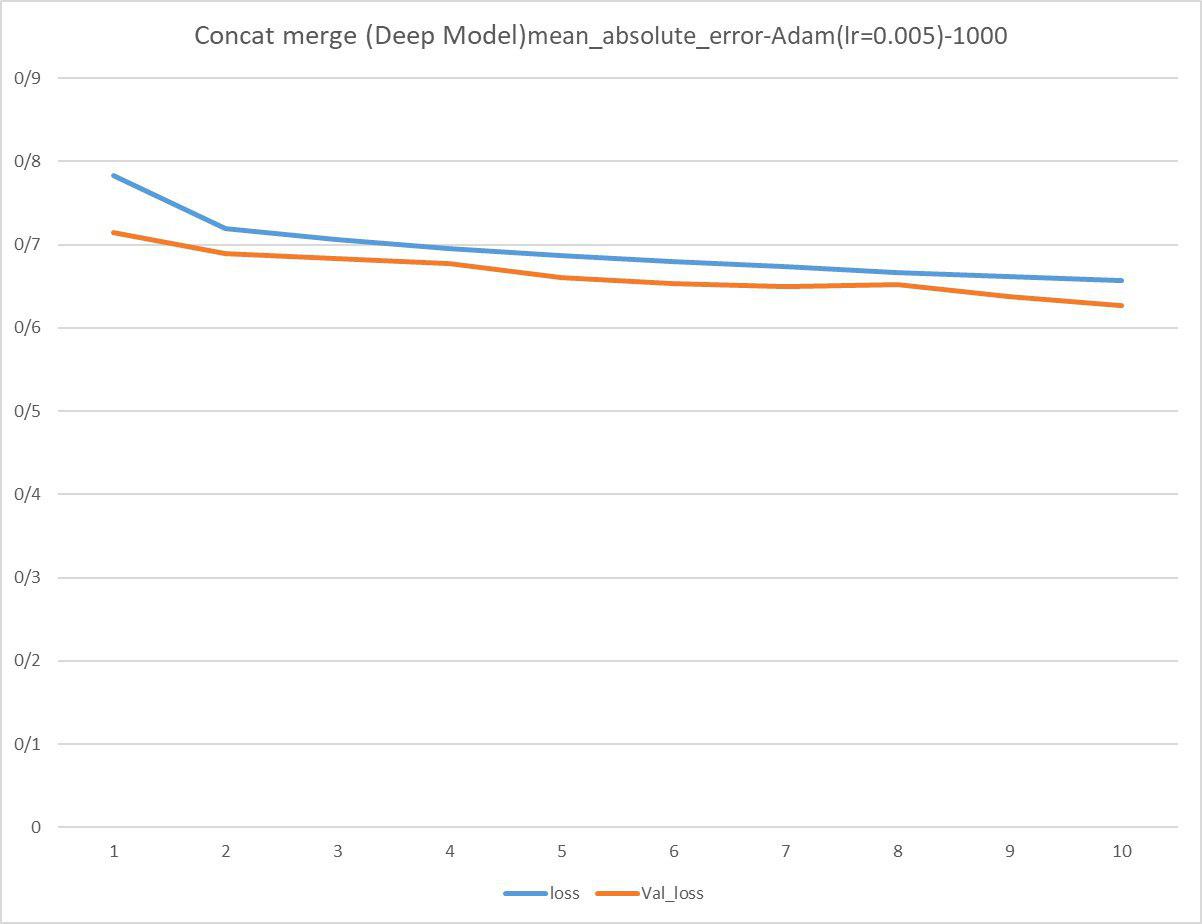
3.DeepModel , epoch = 10 , loss = mean_absolute_error , optimizer = Adam , batch_size = 1000 :
۵. کار های آینده
استخراج اطلاعات بیشتر
استفاده از سایت های دیگر و ترکیب اطلاعات آنها برای بهبود نتایج
حل مسئله شروع سرد 11 با استفاده از الگوریتم های ترکیبی مانند الگوریتم های هیبریدی
استفاده از مدل یادگیری عمیق با ویژگی های متفاوت و ...
۶. مراجع
Recommender system: Wikipedia (https://en.wikipedia.org/wiki/Recommender_system)
Collaborative filtering: Wikipedia (https://en.wikipedia.org/wiki/Collaborative_filtering)
Cold start: Wikipedia (https://en.wikipedia.org/wiki/Cold_start_(computing)))
Recommending movies with deep learning http://blog.richardweiss.org/2016/09/25/movie-embeddings.html
منبع کد پروژه : https://github.com/alidehestani76/MovieRating
Content Base
Collaborative Filtering
Users
Items
Deep Learning
Parse Data
keras
Training Model
Training Set
Recommender
ُCold Start