همه روزه وقتی که ما در حال انجام کار هایی مثل خرید آنلاین ، مشاهده فیلم و گوش کردن به آهنگ هستیم یا حتی هنگام نوشتن یک مطلب در گوشی هوشمند خود از سیستم های پیشنهاد دهنده[۱] استفاده میکنیم. گسترش سیستم های پیشنهاد دهنده به حدی رسیده است که آن هارا در اکثر سایت ها میتوانید ببینید و بدون اینکه متوجه باشید شما دارید از آن ها استفاده میکنید.
چند دهه قبل مردم برای آشنایی با چیزهای جدید متکی به معرفی توسط خانواده و آشنایان خود بودند که به وی پیشنهاد بشود که فلان کتاب را بخر یا فلان جنس را مصرف کن. ولی اکنون با استفاده از سیستم های پیشنهاد دهنده میتوانند اطلاعات دقیق تری بدست بیاورند .
امروزه سایت ها و سیستم های مختلفی مانند Google ،Netflix ،Amazon, spotify با استفاده از الگوریتم های قدرتمند پیشنهاد دهی توانسته اند رضایت بیشتری از کاربران خود بدست بیاورند.
۱. مقدمه
با گسترش سرویس های پیشنهاد دهنده و همچنین زیاد شدن اطلاعات موجود در آن ها امروزه نگهداری و پردازش آن ها بسیار اهمیت پیدا کرده است. به صورتی که باید بتوانند در کمترین زمان مناسب ترین گزینه هارا پیشنهاد دهند.

در سیستم های پیشنهاد فیلم در سال های گذشته روش های مختلفی استفاده شده است. گاهی اوقات برای پیشنهاد فیلم از اطلاعات اختصاصی خود فیلم مانند موضوع ، کارگردان ، سوپراستار ها استفاده میشود و گاهی اوقات برای پیشنهاد از اطلاعات و امتیازاتی که دیگر کاربران به آن فیلم داده اند استفاده میشود.
۲. کار های مرتبط
امروزه برای پیشنهاد فیلم از روش های مختلفی استفاده میشود . در ادامه به معرفی این روش ها میپردازیم.
۲.۱. روش محتوایی [۲]:
این روش بر اساس اطلاعات خصوصی خود فیلم استفاده میکند و فیلم های شبیه به هم را به کاربران معرفی میکند. یعنی مثلا اگر شما فیلمی با کارگردان x رو ببینید به شما فیلم هایی از همان کارگردان پیشنهاد میکند . یا در صورتی که فیلمی کمدی ببینید فیلم های کمدی دیگر را به شما پیشنهاد میکند. در این روش اهمیتی ندارد که بقیه کاربران به این فیلم ها چه امتیازی داده اند و عملیات پیدا کردن فیلمهای مشابه صرفا براساس اطلاعات فیلم ها انجام میگیرد.
۲.۲. روش فیلتر مشارکتی [۳] :
روش فیلتر مشارکتی از بهترین روش هایی است که امروزه برای پیشنهاد فیلم استفاده میشود. در این روش بر اساس رفتارهای کاربرها نسبت به فیلمها تصمیم گیری میشود. مثلا اگر کاربر های الف و ب به تعدادی فیلم امتیازهای مشابه بدهند ، پیشبینی میشود در فیلم های دیگر هم امتیاز های شبیه به یکدیگر بدهند.
روش فیلتر مشارکتی خود به چند قسمت تقسیم میشود.
۲.۲.۱. بر اساس حافظه[۴]:
در این روش با توجه به امتیازاتی که هر کاربر به هر فیلم داده است جدولی مشابه به جدول زیر ساخته میشود و از این جدول برای انجام عملیاتهای مربوط به پیشبینی امتیازات استفاده میشود.

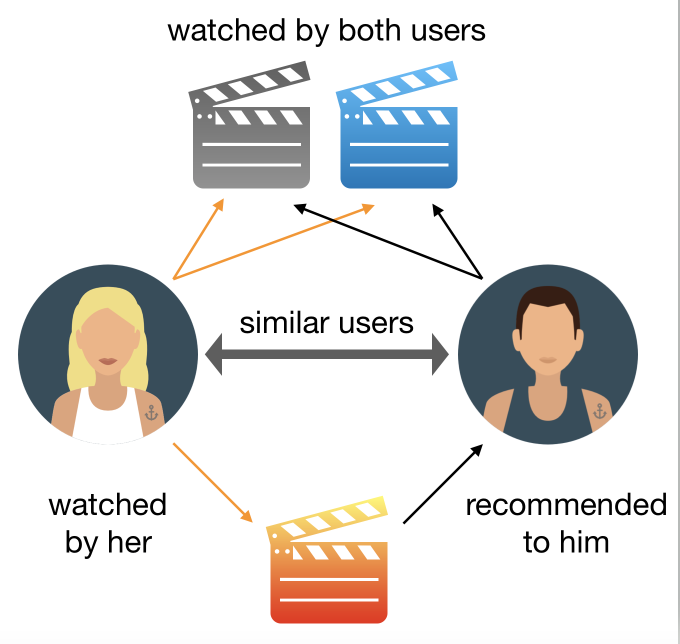
بر اساس کاربر ها [۵] :
کاربرهای مشابه به ما را پیدا میکند و فیلمهایی که آن ها دوست دارند را به ما پیشنهاد میدهد.
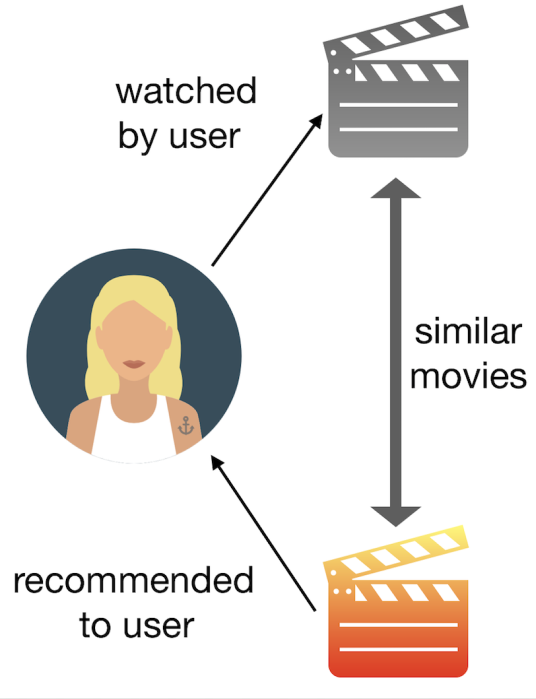
بر اساس فیلم ها [۶] :
فیلمهایی که به هم دیگر شبیه هستند را پیدا میکند و اگر ما فیلمی را دوست داشتیم ، فیلمهای مشابه به آن را به ما پیشنهاد میدهد.
محدودیت روش بر اساس حافظه:
بسیاری از خانههای جدول کاربر - فیلم که امتیاز هر کاربر به هر فیلمی که دیده است را نشان میدهد خالی هستند چون هر نفر تعداد محدودی از فیلمهارا دیده است و بنابراین بسیاری از خانه ها خالی هستند, پس با زیاد شدن حجم دیتاستهای ما جدول کاربر-فیلم ما به اصطلاح
sparseمیشود و در نتیجه سرعت عملیات ما بیهوده پایین میاید و به طور کلی میتوان گفت که استفاده از روشبر اساس حافظهدر سیستمهای بزرگ انتخاب مناسبی نیست .
۲.۲.۲. بر اساس مدل ساخته شده[۷]:
در این روش بر اساس اطلاعات امتیازاتی که داریم به ساخت یک مدل از امتیازات داده شده روی می آوریم و از آن مدل به عنوان جانشین جدول اصلی در عملیات بعدی استفاده میکنیم. روش های ساخت مدل بر اساس الگوریتم های یادگیری ماشین گسترش داده شده اند تا جدولی بسازند که بتوانیم امتیاز فیلم هایی که هنوز کاربر ها ندیده اند را پیشبینی کنیم.
الگوریتم خوشه بندی [۸]
یادگیری عمیق[۹]
تقسیم ماتریس [۱۰]
ما از روش سوم استفاده خواهیم کرد.
۳. آزمایش ها
۳.۱. آشنایی با دادهی موجود:
دادهای که در این پروژه توسط ما استفاده شده است دیتاست وبسایت MovieLens است که توسط تحقیقات گروه Grouplens در این وبسایت فراهم شده است .
در این سایت دیتاستهای مختلفی مناسب برای پروژههای مختلف قرار داده شده است که ما در این پروژه از دیتاست 100k که از ۱۰۰,۰۰۰ نظر کاربران دربارهی فیلمهای مختلف تشکیل شده است استفاده کردهایم.
در این دیتاست اطلاعات مربوط به۱۰۰,۰۰۰ نظر که توسط ۹۴۳ کاربر مختلف به ۱۶۸۲ فیلم مختلف داده شده جمع آوری شده است. بخشی از دیتاست که توسط ما مورد استفاده قرار گرفته در هر سطر خود شامل اطلاعات مربوط به یک نظر توسط یک کاربر دربارهی یک فیلم است :
userId , movieId , rating , timestamp
۳.۲. استفاده از روش ((فیلتر مشارکتی)) به عنوان راه حل
در روش فیلتر مشارکتی ما در ابتدا یک ماتریس کاربر-فیلم میسازیم که هر مقدار هر درایهی ماتریس برابر است با مقدار امتیازی که آن کاربر به آن فیلم داده است.
همانطور که در بالا توضیح داده شد این ماتریس در دیتاست های دچار بزرگ مشکل sparsity میشود و به همین دلیل ما به جای استفاده از روش بر اساس حافظه از روش بر اساس مدل استفاده خواهیم کرد .
راههای مختلفی برای ساخت این مدل از روی ماتریس اصلی ما وجود دارد که ما از روش تقسیم ماتریس و به طور خاص تر از روش singular value decomposition استفاده میکنیم .
در روش singular value decomposition ما ماتریس کاربر-فیلم را به ۳ ماتریس P و Sigma و Q تقسیم میکنیم که شرح هرکدام از این ماتریسها به این صورت است :
ماتریس P: هر سطر این ماتریس دربرگیرندهی میزان علاقهی کاربر به هر
featureاست .ماتریس Q: هر سطر این ماتریس دربرگیرندهی میزان ارتباط فیلم به هر
featureاست .ماتریس Sigma: یک ماتریس قطری که هر درایهی روی قطر آن دربرگیرندهی میزان وزن آن
featureخاص است.
نکتهی مهم دربارهی ماتریس Sigma این است که این ماتریس قطری دربرگیرندهی وزنfeatureهایی است که حین عملیاتdecomposeکردن محاسبه میشوند, اینfeatureها الزاما قابل تفسیر به ویژگی های خاصی که ما از فیلم ها در ذهن داریم(مثلا اکشن یا کمدی) نیستند و توسط خود الگوریتمsingular value decompositionو برای انجام عملیات پیشبینی محاسبه و بهینه شدهاند.
برای محاسبهی ماتریسی که در برگیرندهی تخمینهای ما از امتیازهایی است که کاربر به فیلم داده است ابتدا ترانهادهی ماتریس Q را حساب میکنیم تا هر سطر آن نشان دهندهی میزان ارتباط هر فیچر به هر فیلم باشد سپس ماتریس R به این صورت محاسبه میشود .R = P * Sigma * Q^T
۳.۳. نحوهی تقسیم دیتای test و train
ما برای رسیدن به دقت خوبی در ارزیابیهای خود برای تقسیم دیتای خود از روش k-fold cross validation استفاده کردهایم که نحوهی کار آن به این صورت است که ابتدا دیتای خود را به k قسمت تقسیم میکنیم و یکی از این قسمتها را به عنوان دیتای test در نظر میگیریم و k قسمت دیگر را به عنوان دیتای train و این کار را برای k بار تکرار میکنیم تا همهی قسمتها یکبار به عنوان دیتای test استفاده بشوند و سپس از نتایج به دست آمده با توجه به متریکهایی که جلوتر توضیح داده خواهند شد میانگین گرفته میشود.

۴. نتایج
در این بخش ابتدا معیارهایی برای اندازهگیری سامانه بیان کرده و نتایج را محاسبه و گزارش میکنیم. سپس برای یکی از کاربر ها به ازای همه ی فیلم هایی که دیده است امتیازی که الگوریتم ما پیشبینی میکند را با امتیاز اصلی مقایسه میکنیم.
۴.۱. متریک های ارزیابی
ما برای بررسی درصد دقت سیستم خود از ۲ معیار precision , recall استفاده میکنیم:
تعداد آتیمهای پیشنهاد شده که مورد علاقهی کاربر بودند -> K
تعداد آیتم های پیشنهاد شده -> N
تعداد آتیمهای پیشنهاد شده که مورد علاقهی کاربر بودند -> K
تعداد آیتم های مورد علاقهی کاربر -> M
۴.۲. نتایج
برای بررسی اینکه الگوریتم ما چقدر دارد خوب عمل میکند ، به ازای k های مختلف دیتای خود را به test و set تقسیم میکنیم تا بتونیم بدست بیاوریم که کدام k برای اینکار مناسب تر است.
از آنجایی که برای هر سامانه ای دو مسئله خیلی مهم است ما دو نموار کشیده ایم.
1- دقت سامانه
2- سرعت سامانه
ابتدا نمودار دقت را بررسی میکنیم.
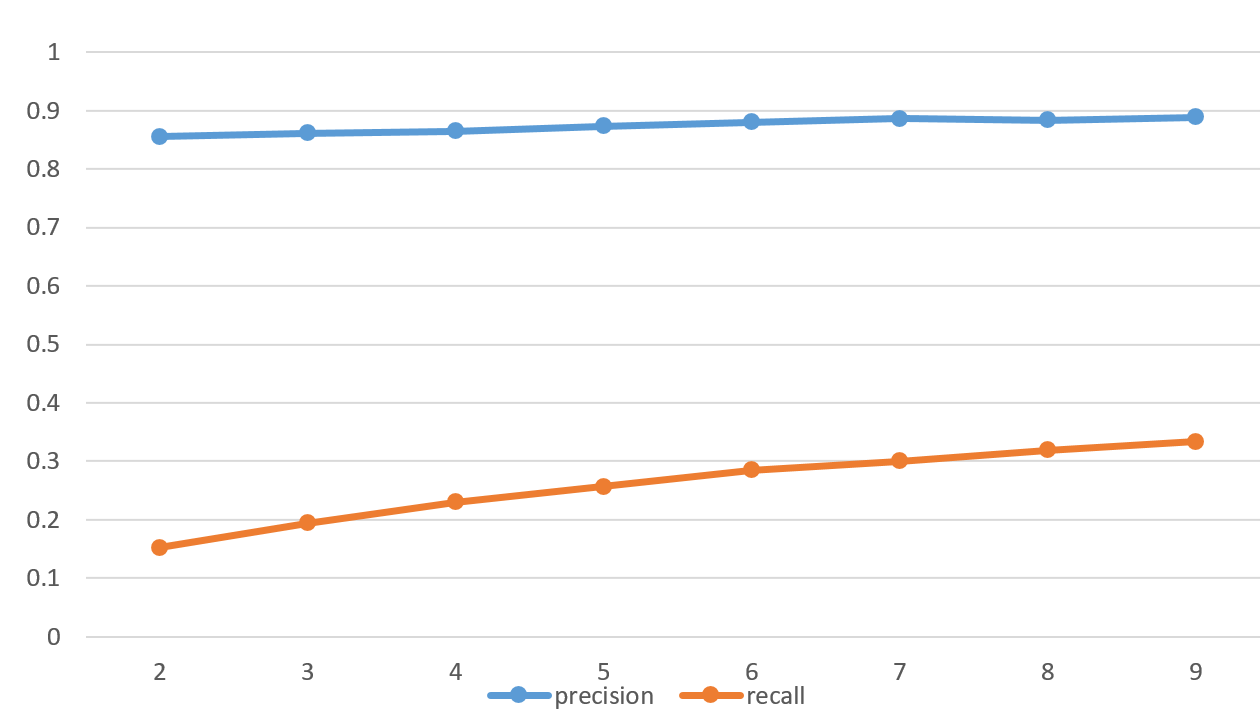
همانطور که مشاهده میکنید با افزایش k هر دو معیاری که در مرحله قبل معرفی کردیم ، افزایش پیدا میکنند ، پس دقت سامانه بیشتر میشود.
حال به بررسی نمودار زمان سامانه میپردازیم.
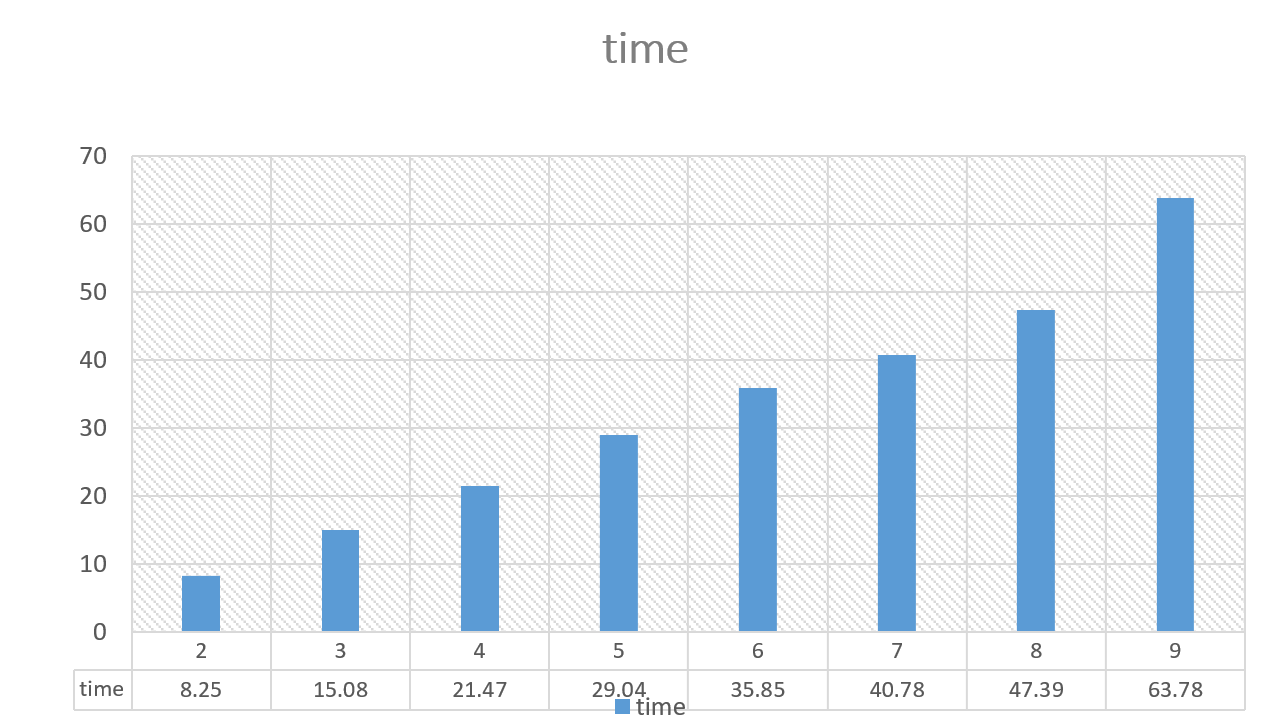
مشاهده میکنیم که با افزایش k مدت زمان اجرای برنامه ما افزایش پیدا میکنید و سیر صعودی به خود میگیرد. چون که تعداد قسمت های ما زیاد میشود و بنابراین عملیات های بیشتری باید انجام دهد پس سیر صعودی زمان منطقی به نظر میاید. اما از آن جایی که سرعت سامانه یکی از مسائل مهم است باید k را عددی انتخاب کنیم که برآیند هردو نمودار در حالت بهینه خود باشد.
با نتایجی که بدست آوردیم بهترین گزینه برای k عدد های ۵ و ۶ هست.
حال به ازای کاربر شماره ۹ تعدادی از فیلم هایی که وی دیده است را به کمک سیستم پیشنهاد دهنده امتیازش را تخمین میزنیم و با امتیاز اصلی که خود کاربر ۹ به آن داده است مقایسه میکنیم.
در تصویر زیر امتیاز اصلی کاربر ۹ و تخمین سیستم مارا به فیلم هایی که قبلا خود کاربر دیده است را میتوانید ببینید.
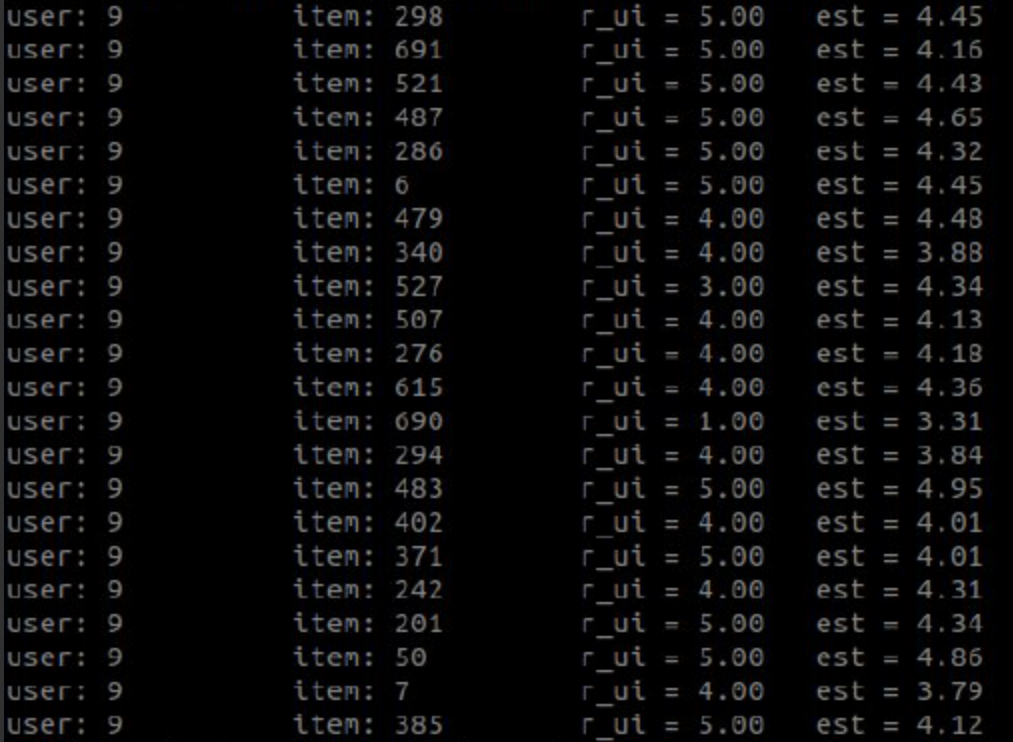
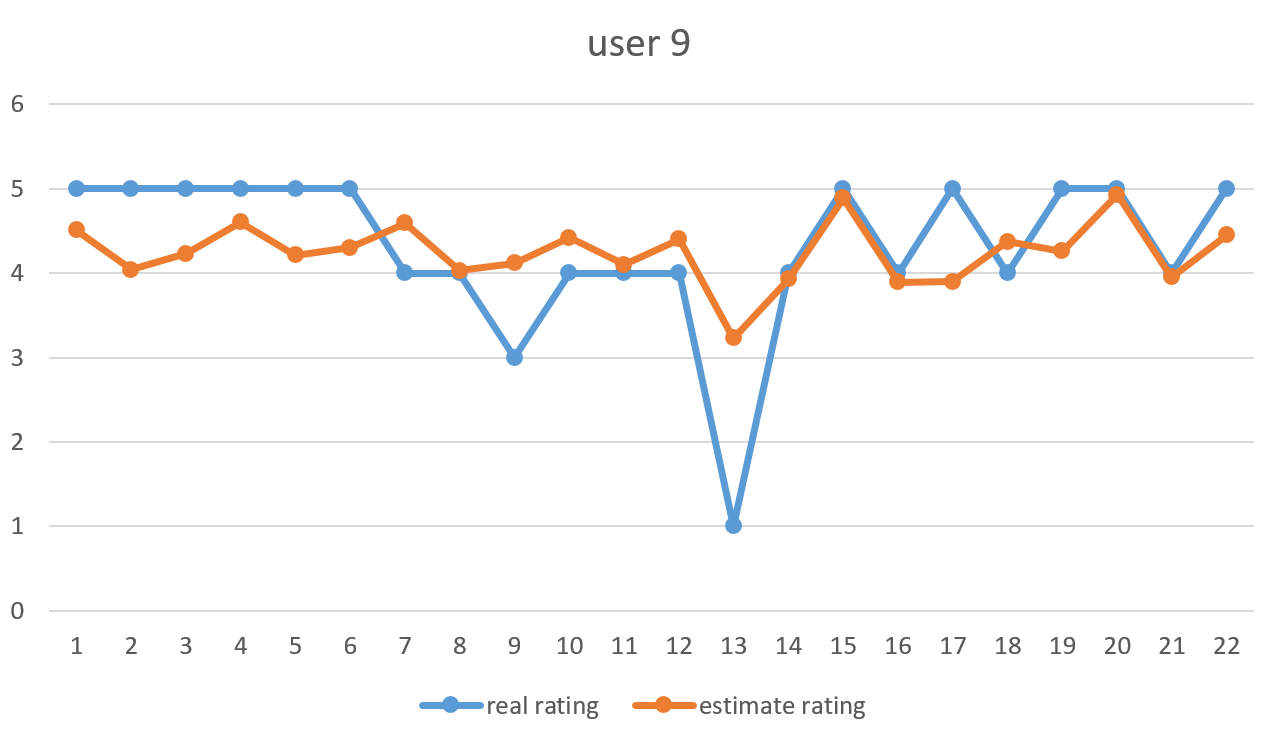
همانطور که مشاهده میکنید در جاهایی که امتیاز داده شده توسط کاربر ۵ بوده سیستم ماه هم یک عدد نزدیک به ۵ رو پیشنهاد داده است یا هنگامی امتیاز اصلی کم شده تخمین سیستم هم کاهش داشته است.
۵. آینده
به عنوان کار های آینده میتوان از یکی دیگر از روش های یادگیری ماشین که یادگیری عمیق هست استفاده کرد. این روش تنها روشی است که نتایج بهتر از SVD را میتواند به ما بدهد.
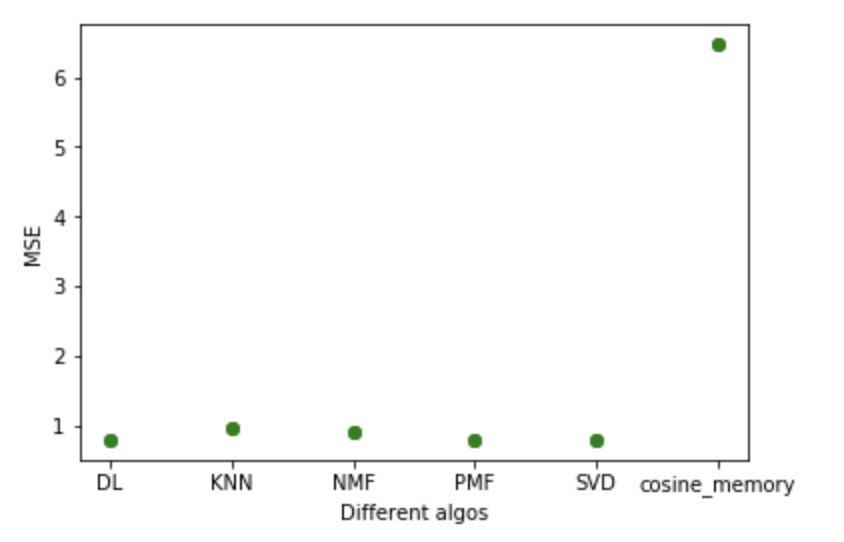
همچنین استفاده از روش های ترکیبی[۱۱] که همزمان از دو روش فیلترمشارکتی و روش محتوایی استفاده میکند یکی از برنامه های آینده است. این روش میتواند در زمان های مختلف بنابر وضعیت و تعداد کاربر ها و فیلم ها تصمیمات بهینه بگیرد.
۶. مراجع
towardsdatascience - implementations of collaborative filtering
medium - machine learning for recommender systems
datacamp - recoomender system in python
medium - 4 recommendation engines
kerpanic - guide to surprise
medium - easy guid fo bilding collaborative system
buzzard - SVD
coursera - matrix factorization
hackernoon - collaborative SVD
understanding matrix factorization
algorithm evaluation
Recommendation systems
Content based
Collaborative filtering
Memory based
Item based
User based
Model based
Clustering based
Deep learning
Matrix factorization
Hybrid model