
چکیده
پروژه: تشخیص پلاک ماشین از روی تصویر پلاک با استفاده از الگوریتم های یادگیری عمیق و یادگیری ماشینی و همچنین الگوریتم های پردازش تصویری
دلایل انتخاب: علاقه ی شخصی اعظای تیم و معروف بودن صورت مسئله و وجود منابع زیاد مرتبط با آن
راه حل: بصورت خلاصه با استفاده از یادگیری عمیق
۱. مقدمه
تشخیص خودکار شماره پلاک خودرو سامانهای برای خواندن پلاک وسیله نقلیه با استفاده از نویسهخوان نوری است. شماره پلاک خودرو یکی از مناسبترین اقلام اطلاعاتی جهت احراز هویت خودروها میباشد. تشخیص خودکار شماره پلاک خودرو سامانهای کاملاً مکانیزه است که با استفاده از پردازش تصویر خودروهای عبوری از یک مکان، شماره پلاک آنها را استخراج میکند. برای استفاده از این سامانه، نیازی به نصب و تجهیز خودروها به وسیلهٔ دیگری (مانند GPS یا برچسبهای رادیویی- RFID Tag) وجود ندارد. این سامانه با استفاده از دوربینهای مخصوص، تصویری از خودرو در حال عبور اخذ میکند و آن تصویر را جهت پردازش توسط نرمافزار تشخیص پلاک خودرو به رایانه ارسال میکند. از این سامانه میتوان در زمینههای امنیتی و ترافیکی بسیار بهره گرفت.
کاربرد های سامانه تشخیص پلاک خودرو
کنترل و اخذ عوارض ورود به محدوده ی طرح ترافیک
اخذ عوارض جاده ها و بزرگ راه ها بصورت خودکار
محاسبه مدت سفر
اندازه گیری سرعت میانگین خودرو ها
کنترل عبور و مرور ها در پارکینگ های تجاری
کنترل درب منازل و ادارات بصورت اتوماتیک برای خودرو ها مجاز
۲. کارهـای مرتـبط
مسئله ی تشخیص پلاک پاشین به دلیل ماهیت آن مسئله ای است که بسیار به آن پرداخته شده است و مسئله ی پر کاربردی است که پیاده سازی های متعدد و مختلفی از آن موجود است.
الگوریتم های شخیص پلاک خودرو عموما با استفاده از ترکیب الگوریتم های RNN (Recurrent Neural Network) و CNN(Convolutional Neural Network) پیاده سازی می شوند که استفاده از یک شبکه ی عصبی RNN در کنار یک شبکه ی عصبی CNN را برای اینکار ملزم می دانند چرا که شبکه ی RNN به دلیل استفاده از داده های قبلی در تشخیص داده های بعدی در افزایش دقت در پردازش تصویر به شبکه ی CNN کمک می کند.
اصولا تمامی پیاده سازی های الگوریتم های پردازش تصویر در دنیای واقعی با استفاده از ترکیب این دو نوع شبکه ی عصبی صورت می پذیرد.
۳. راه حـل ارائـه شـده
راه حل نهایی ما در حل مسئله و پیاده سازی پروژه بشرح زیر می باشد :
دریافت داده های train و test (Validation)
پردازش و تغییر داده ها و آماده کردن آن ها برای دادن به شبکه ی عصبی
پردازش داده ها توسط شبکه عصبی
۳.۰.۱. تابع هزینه ( loss function ) :
برای محاسبه ی هزینه و دقت ما از تابع هزینه ی CTC loss function استفاده کردیم به دلایل زیر:
شروع متن در تصاویر مختلف متفاوت است و با استفاده از CTC این موضوع مرتفع می شود چرا که CTC در جاهای خالی ی تصویر CTC blank می گذارد.
ما ابتدا این پروژه را با استفاده از ترکیب شبکه های CNN و RNN (GRU) پیاده سازی کرده بودیم که یک کاراکتر ممکن بود چند گام زمانی را اشغال کند و با استفاده از CTC می توانستیم این مشکل را مرتفع کنیم چراکه این گام های زمانی کاراکتر تکراری را با هم ادغام می کرد.
که بعدا بدلیل اینکه نتایج بسیار خوبی با این تابع می گرفتیم پس از حذف لایه GRU نیز به استفاده از CTC ادامه دادیم.
۳.۱. دریافت داده ها
ابتدا داده های train و test (همان val در دیتاست) را از دیتاست دریافت می کنیم و سپس بررسی میکنیم که در لیبل های دیتاست ها چه کاراکتر هایی به کار رقته است و ضمنا بررسی می کنیم که کاراکتر های استفاده شده در tarin و test همخوانی داشته باشند
Max plate length in "": 8
Max plate length in "": 8
Letters in train and val do match
Letters: 0 1 2 3 4 5 6 7 8 9 A B C E H K M O P T X Y
قابل ذکر است که توزیع دیتاست کلی به صورت زیر است:
کل دیتاست: 12K
دیتاست train: 10.5K
دیتاست test(val) : 1K
دیتاست test برای بررسی و رسم پلات : 0.5K
۳.۲. پردازش و تغییر داده ها و آماده کردن آن ها برای دادن به شبکه ی عصبی
در این مرحله داده ها پردازش می شوند تا آماده ی دادن به شبکه ی عصبی شوند.
تصاویر به اندازه ی ۱۲۸ در ۶۴ تفییر سایز داده می شوند
لیبل ها انکود می شوند و به یک لیست یا ایندکس های متناظر مپ می شوند
سایز ورودی به loss function مشخص می شود
Text generator output (data which will be fed into the neutral network):
1) the_input (image)

2) the_labels (plate number): A024AK54 is encoded as [10, 0, 2, 4, 10, 15, 5, 4]
3) input_length (width of image that is fed to the loss function): 30 == 128 / 4 - 2
4) label_length (length of plate number): 8
۳.۳. پردازش داده ها توسط شبکه عصبی
در این مرحله شبکه ی عصبی ساخته می شود و مدل های دیتا به آن داده می شود.
شبکه ی عصبی مورد استفاده یک شبکه ی عصبی CNN است و از شبکه ی عصبی RNN در آن استفاده نشده است.
در این شبکه ی عصبی از لایه های InputLayer و Conv2D و MaxPooling2D و Reshape و Dense و Activation استفاده شده است که با معماری زیر در شبکه قرار گرفته اند :
Layer (type) Output Shape Param #
=================================================================
the_input (InputLayer) (None, 128, 64, 1) 0
_________________________________________________________________
conv1 (Conv2D) (None, 128, 64, 16) 160
_________________________________________________________________
max1 (MaxPooling2D) (None, 64, 32, 16) 0
_________________________________________________________________
conv2 (Conv2D) (None, 64, 32, 16) 2320
_________________________________________________________________
max2 (MaxPooling2D) (None, 32, 16, 16) 0
_________________________________________________________________
reshape (Reshape) (None, 32, 256) 0
_________________________________________________________________
dense1 (Dense) (None, 32, 32) 8224
_________________________________________________________________
dense2 (Dense) (None, 32, 23) 759
_________________________________________________________________
softmax (Activation) (None, 32, 23) 0
=================================================================
Total params: 11,463
Trainable params: 11,463
Non-trainable params: 0
۴. آزمـایش هـا
برای اجرای نهایی سیستم پس از آزمون و خطا ها ما برای دریافت بهترین نتیجه از ۴ epoch استفاده کردیم و پس از epoch دوم سیستم دقتش ثابت شد و تغییری نکرد و به دقت بسیار خوب loss: 0.0045 رسید اما قبل از آن آزمایش دیگری با استفاده از ۲ لایه GRU انجام دادیم که نتایج آن قابل قبول بود اما بهترین نتیجه نبود و جزییات ریز و دقیق آن به صورت زیر بود:
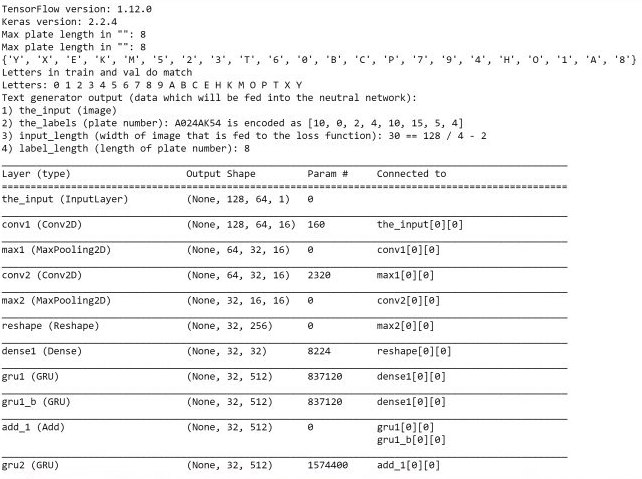

و آزمایش نهایی بدون لایه های GRU و با استفاده از ۴ EPOCH و با ریز جزییات زیر بهترین نتایج را داد که بصورت دقیق قابل مشاهده است:
Layer (type) Output Shape Param #
=================================================================
the_input (InputLayer) (None, 128, 64, 1) 0
_________________________________________________________________
conv1 (Conv2D) (None, 128, 64, 16) 160
_________________________________________________________________
max1 (MaxPooling2D) (None, 64, 32, 16) 0
_________________________________________________________________
conv2 (Conv2D) (None, 64, 32, 16) 2320
_________________________________________________________________
max2 (MaxPooling2D) (None, 32, 16, 16) 0
_________________________________________________________________
reshape (Reshape) (None, 32, 256) 0
_________________________________________________________________
dense1 (Dense) (None, 32, 32) 8224
_________________________________________________________________
dense2 (Dense) (None, 32, 23) 759
_________________________________________________________________
softmax (Activation) (None, 32, 23) 0
=================================================================
Total params: 11,463
Trainable params: 11,463
Non-trainable params: 0
و نتیجه ی آن :
Epoch 1/4
10281/10281 [==============================] - 382s 37ms/step - loss: 0.3607 - val_loss: 1.5033e-04
Epoch 2/4
10281/10281 [==============================] - 386s 38ms/step - loss: 0.0045 - val_loss: 8.6403e-05
Epoch 3/4
10281/10281 [==============================] - 392s 38ms/step - loss: 0.0045 - val_loss: 8.4615e-05
Epoch 4/4
10281/10281 [==============================] - 391s 38ms/step - loss: 0.0045 - val_loss: 7.8257e-05
قابل ذکر است که در این حالت سیستم Over Fit نمی کند و دقت آن پس از دو Epoch ثابت می شود.
۵. تحـلیل و تفسیر نـتایج
برای ترسیم خروجی سیستم از کتابخانه ی matplotlib در پایتون استفاده کردیم و برای داده های دیتاست test نمودار مربوطه ی آن را با مقادیر خروجی رسم می کنیم و سپس آن را با به لیبل متناظر دیکود می کند و نمایش می دهد که چند نمونه مانند زیر است:


تصاویر موجود در دیتاست ما همگی دارای ساختار و قالب ثابت هستند که توسط Supervise.ly ساخته شده اند و به شکل زیر هستند:

به دلیل ثابت بودن قالب پلاک ها و فرمت کاراکتر ها در دیتاست(۲ عدد - ۲ آلفابت - ۳ عدد - ۱ آلفابت) و همچنین اینکه نیاز به پیدا کردن پلاک در تصویر نیست و داده ها فقط تصویر پلاک هستند نیاز به استفاده از GRU نیست و الگوریتم ما در شرایط مشابه بهترین عملکرد را دارد ولی برای استفاده از دیتاست هایی که باید پلاک را در تصویر ابتدا پیدا کرد و سپس حروف آن را تشخیص داد باید لایه های RNN هم به شبکه ی عصبی ما اضافه شود تا نتایج خوبی حاصل شود ضمن اینکه نیاز به تغییر loss function نخواهد بود و با استفاده از لایه های RNN نیز CTC بهترین گزینه است.