تشخیص لبخند
در این پروژه میخواهیم با استفاده از روش های یادگیری عمیق، به تشخیص لبخند در چهره های افراد بپردازیم.
۱. مقدمه
امروزه ضرورت وجود سامانه های تشخیص و دسته بندی اشیا در زندگی افراد به شدت احساس میشود. یکی از این مسائل دسته بندی، تشخیص چهره و لبخند اشخاص در تصاویر و ویدیوها میباشد که در تکنولوژی های مربوط به تصویر، مانند دوربین های دیجیتال استفاده میشود. اما تشخیص لبخند چیست؟

۱.۱. تشخیص لبخند
یک تکنولوژی توانا در شناسایی لبخند زدن یا نزدن یک فرد از یک عکس دیجیتالی یا ویدئو میباشد. سیستم تشخیص لبخند، سیستمی است که بر اساس تکنولوژی هوش مصنوعی و الگوریتمهای یادگیری عمیق (Deep Learning) قادر به شناسایی وجود لبخند در افراد با دقت بالا میباشد. در بازشناخت تصویر یک چهره، تصویر ورودی با توجه به اطلاعات موجود در بانک اطلاعات، مورد شناسایی قرار میگیرد. این بانک شامل مشخصاتی از تصویر چهره افراد شناسایی شده است.
به طور کلی تشخیص چهره شامل دو مرحله است :
استخراج ویژگی (Feature Extraction) : فرایندی است که در آن با انجام عملیاتی بر روی دادهها، ویژگیهای بارز و تعیینکنندهٔ آن مشخص میشود. هدف استخراج ویژگی این است که دادههای خام به شکل قابل استفادهتری برای پردازشهای آماری بعدی درآیند . به عنوان مثال در پردازش تصویر، برای اینکه از روی الگوهای یک تصویر هویت یا خالق آن تصویر مشخص شود باید یک سری مشخصات عام یا خاص از دل تصویر بیرون کشیده شود.
کلاسه بندی (Classification)
یکی از اصلی ترین مفاهیم در مباحث یادگیری عمیق، شبکه عصبی است. در ذیل توضیحاتی در رابطه با شبکه های عصبی ارائه میشود.
۱.۲. شبکه عصبی
این سیستم از شمار زیادی عناصر پردازشی فوقالعاده بهمپیوسته با نام نورون تشکیل شده که برای حل یک مسئله با هم هماهنگ عمل میکنند و توسط سیناپسها (ارتباطات الکترومغناطیسی) اطلاعات را منتقل میکنند. در این شبکهها اگر یک سلول آسیب ببیند بقیه سلولها میتوانند نبود آن را جبران کرده، و نیز در بازسازی آن سهیم باشند. این شبکهها قادر به یادگیریاند. مثلاً با اعمال سوزش به سلولهای عصبی لامسه، سلولها یادمیگیرند که به طرف جسم داغ نروند و با این الگوریتم سیستم میآموزد که خطای خود را اصلاح کند. یادگیری در این سیستمها به صورت تطبیقی صورت میگیرد، یعنی با استفاده از مثالها وزن سیناپسها به گونهای تغییر میکند که در صورت دادن ورودیهای جدید، سیستم پاسخ درستی تولید کند.
۲. کارهای مرتبط
در گذشته ، عملیات مربوط به تشخیص اشیا به وسیله روش های کلاسیک پردازش تصویر مانند آشکارسازی لبه، Grayscale matching و یا روش های مبتنی بر موجک هار صورت میگرفت. ولی امروزه با پیشرفت تکنیک های یادگیری عمیق، کمتر از روش های کلاسیک استفاده میشود (هرچند که این روش ها در زیرساخت شبکه های عصبی وجود دارند. به عنوان مثال فیچرهای Haar-like یکی از بلوک های سازنده ی شبکه های عصبی پیچشی میباشند).
در یادگیری عمیق معمولا از سه نوع شبکه عصبی به شرح زیر استفاده میشود:
پرسپترون چندلایه : دسته ای از شبکه های عصبی هستند که شامل حداقل سه لایه گره می باشند. یک لایه ورودی و یک لایه پنهان و یک لایه خروجی که به جز گره ورودی هر گره یک نورون است که از یک تابع فعالسازی غیرخطی استفاده میکند.
شبکه عصبی پیچشی : گونه ای از شبکه های عصبی ژرف هستند که معمولا برای انجام تحلیل های تصویری و گفتاری در یادگیری ماشین استفاده می شوند.
شبکه عصبی پیچشی به منظور کمینه کردن پیش پردازش ها از پرسپترون چند لایه استفاده میکند. در این نوع از شبکه ها هر نورون به یک ناحیه محدود پاسخ میدهد که مجموع تمام آنها تمام نواحی را پاسخ می دهند .
شبکه های عصبی پیچشی نسبت به بقیه رویکردهای دسته بندی تصاویر به میزان کمتری از پیش پردازش ها استفاده میکنند. این بدین معنا است که این شبکه ها معیارهایی را فرا میگیرند که در روش های قبلی به صورت دستی فراگرفته میشدند.
یک شبکه عصبی پیچشی از یک لایه ورودی، یک لایه خروجی و تعدادی لایه پنهان تشکیل شده است. لایههای پنهان یا پیچشی هستند، یا تجمعی یا کامل.
لایههای پیچشی یک عمل پیچش را روی ورودی اعمال میکنند، سپس نتیجه را به لایه بعدی میدهند. این پیچش در واقع پاسخ یک تکنورون را به یک تحریک دیداری شبیهسازی میکند.
شبکههای عصبی پیچشی ممکن است شامل لایههای تجمعی محلی یا سراسری باشند که خروجیهای خوشههای نورونی در یک لایه را در یک تکنورون در لایه بعدی ترکیب میکند.
شبکه های عصبی بازگشتی : این شبکه ها در واقع برای پردازش سیگنال های دنباله دار به وجود آمدند. در یک شبکه عصبی معمولی تمام ورودی ها و خروجی ها مستقل از یکدیگر هستند،اما در بسیاری از موارد این ایده میتواند خیلی بد باشد. به عنوان مثال فرض کنید شما در یک جمله به دنبال پیش بینی کلمه بعدی هستید در صورتی که شبکه نتواند روابط بین کلمات را یاد بگیرد مسلما نمی تواند کلمه بعدی را به درستی پیش بینی کند.در واقع شبکه های عصبی بازگشتی همان شبکه های عصبی پیچشی با وجود حافظه میباشند.
پرسپترون چندلایه معمولا برای داده های برداری استفاده میشود در حالی که داده ما عکس میباشد پس برای مساله ما مناسب نمیباشد.
از شبکه های عصبی بازگشتی معمولا در پردازش زبان و جملات استفاده میشود و به خاطر اینکه داده ما عکس میباشد که به صورت یک سری پیکسل تجمعی میباشد در حالی برای این نوع شبکه ها بهتر است دیتا به صورت sequentialباشد.
از شبکه های عصبی پیچشی معمولا در رابطه با تصاویر و پردازش تصویر استفاده میشوند.همچنین در این شبکه ها به صورت تجمعی به داده ها نگاه میشود.
در تشخیص لبخند احتیاج به داشتن یک پیکسل و همچنین احتیاج به دانستن وضعیت پیکسل های اطراف آن داریم که با توجه به توضیحات بالا شبکه های عصبی پیچشی مناسب میباشند.
۲.۱. معماری شبکه های عصبی پیچشی :
در طی سال های گذشته، همواره تلاش محققان بر این بوده تا به ترکیب ایده آلی از لایه های مختلف در شبکه عصبی دست یابند که نتیجه مطلوب و accuracy بالایی دارند. 2 نمونه از این معماری ها عبارتند از :
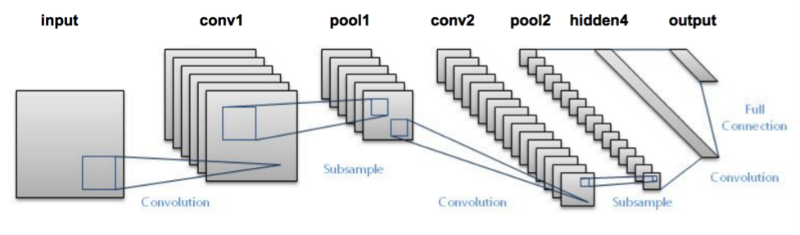
۱. معماری LeNet-5 : از ۷ لایه تشکیل شده است که به ترتیب زیر میباشند
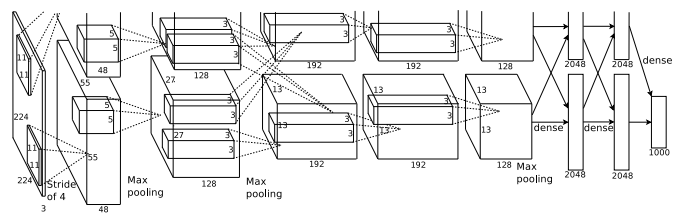
۲. معماری AlexNet : همانندLeNetمیباشد با این تفاوت که عمیق تر و اینکه هر لایه دارای فیلتر های بیشتر میباشد و لایه های پیچشی در کنار هم انباشته شده اند.
۳. راه حل ارائه شده
راه حل ما برای پیاده سازی شامل 4 مرحله میباشد.
۳.۱. پیش پردازش داده ها
برای آموزش دادن به هر ماشین یادگیری عمیقی، نیاز به یک دیتاست داریم که برای مساله ی مورد نظر ما طراحی شده باشد. در این مورد که مساله ی ما تشخیص لبخند است، باید دیتاستی متشکل از تعدادی عکس از چهره ی افراد به همراه برچسبی که مشخص میکند شخص در حال لبخند زدن است یا خیر، داشته باشیم. ما از دو دیتاست جداگانه برای این پروژه استفاده کردیم و پروژه را بر روی هر دو دیتاست به صورت جداگانه train و test کردیم (20% از داده ها برای تست و 80% برای یادگیری).
دیتاست GENKI-4k : ساخته شده توسط دانشگاه کالیفرنیا سن دیگو، شامل 4000 عکس.
´https://github.com/hromi/SMILEsmileD.git : دیتاستی شامل 13165 عکس.

ابتدا برای نرمال کردن سایز همه تصاویر، ابتدا همه آنها را به سایز 192*180 در می آوریم.
سپس با مقیاس 3 همه عکس ها را کوچک میکنیم تا بار پردازشی سیستم کمتر شود. یعنی عکس ها به اندازه ی 64*60 در می آید.
از آنجایی که رنگ در تشخیص فاکتور های لبخند تاثیری ندارد، فرمت عکس ها را از RGB به Grayscale تبدیل میکنیم.
در نهایت در هر عکس که به صورت مجموعه ای از پیکسل هاست، مقدار همه پیکسل ها را بر 255 تقسیم میکنیم.

۳.۲. آماده سازی مدل
در این مرحله ابتدا مدل LeNet-5 (که در قسمت کارهای دیگر توضیح داده شد) را پیاده سازی کردیم. در مرحله بعدی مدل خودمان را با الهام از LeNet-5 که داری یک لایه پیچشی و یک لایه تجمعی بیشتر و یک لایه FC کمتر نسبت به LeNet-5 است را پیاده سازی کردیم که به شکل زیر میباشد. در نهایت برای بررسی تاثیر activation بر کارکرد مدل، برخی activation های لایه ها را از relu به tanh تغییر دادیم.

پیاده سازی مدل طراحی شده خودمان:
...
from keras.models import Sequentialfrom keras.layers.core import Dense, Dropout, Activation
from keras import models
from keras import layers
from sklearn.model_selection import train_test_split
x_train = np.expand_dims(x_train, axis=-1)
(trainX, testX, trainY, testY) = train_test_split(x_train, y_train, test_size=0.20, random_state=1)
filters = 32
conv_size = 3
pool_size = 2
print(trainX.shape)
network = Sequential()
network.add(layers.Conv2D(filters,(conv_size,conv_size),activation="relu",input_shape=trainX.shape[1:]))
network.add(layers.MaxPooling2D((pool_size,pool_size)))
network.add(layers.Conv2D(filters*2,(conv_size,conv_size),activation="relu"))
network.add(layers.MaxPooling2D((pool_size,pool_size)))
network.add(layers.Conv2D(filters,(conv_size,conv_size),activation="relu"))
network.add(layers.MaxPooling2D((pool_size,pool_size)))
network.add(layers.Flatten())
network.add(Dense(64, activation='relu'))
network.add(Dense(number_of_categories, activation='softmax'))
۳.۳. یادگیری
در این مرحله با توجه به مدل های ساخته شده در قسمت قبل بر روی دو دیتاست جمع آوری شده learn میکنیم و از rmsprop و categorical_crossentropy به عنوان optimizer و loss function استفاده میکنیم.
پباده سازی مرحله یادگیری:
...
network.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
history = network.fit(trainX, trainY, epochs=10)
۳.۴. ارزیابی
در این مرحله بر روی تست های جدا شده از دیتاست ها (که با داده های learn شده تفاوت دارند) به ازای تمام مدل ها ارزیابی انجام میدهیم و نتایج آن را ثبت میکنیم که در قسمت های بعد به تفضیل آمده است.
همچنین در اخرین مرحله با دادن دوتصویر دلخواه به سیستم نتیجه را میبینیم.
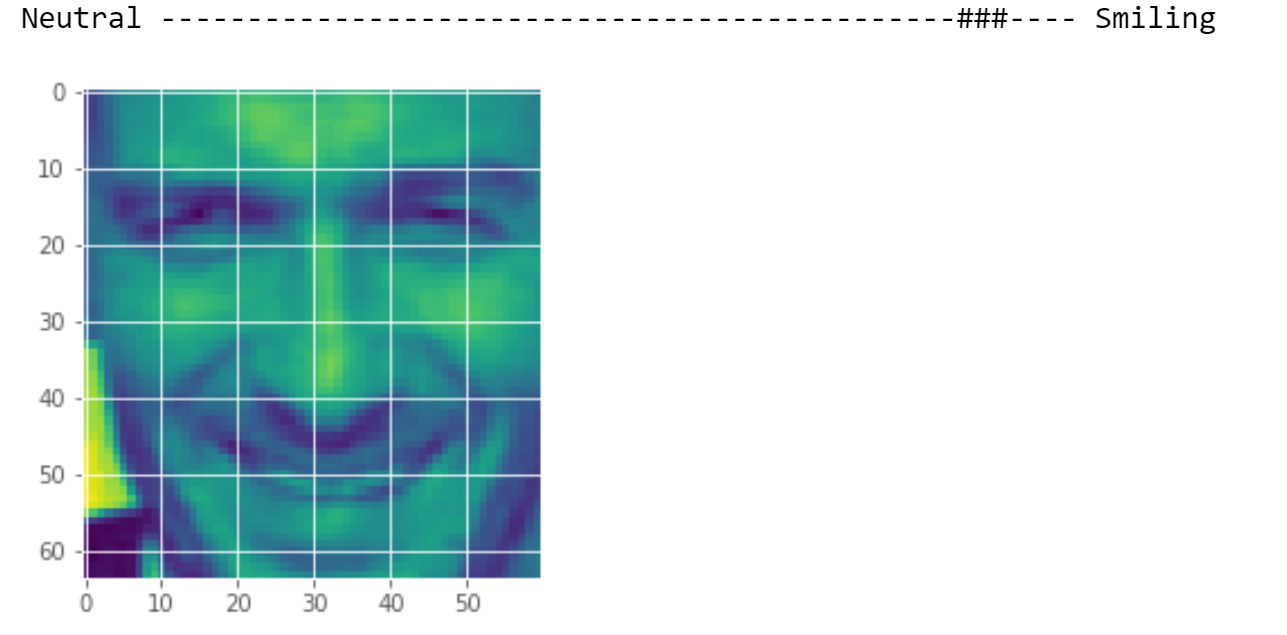
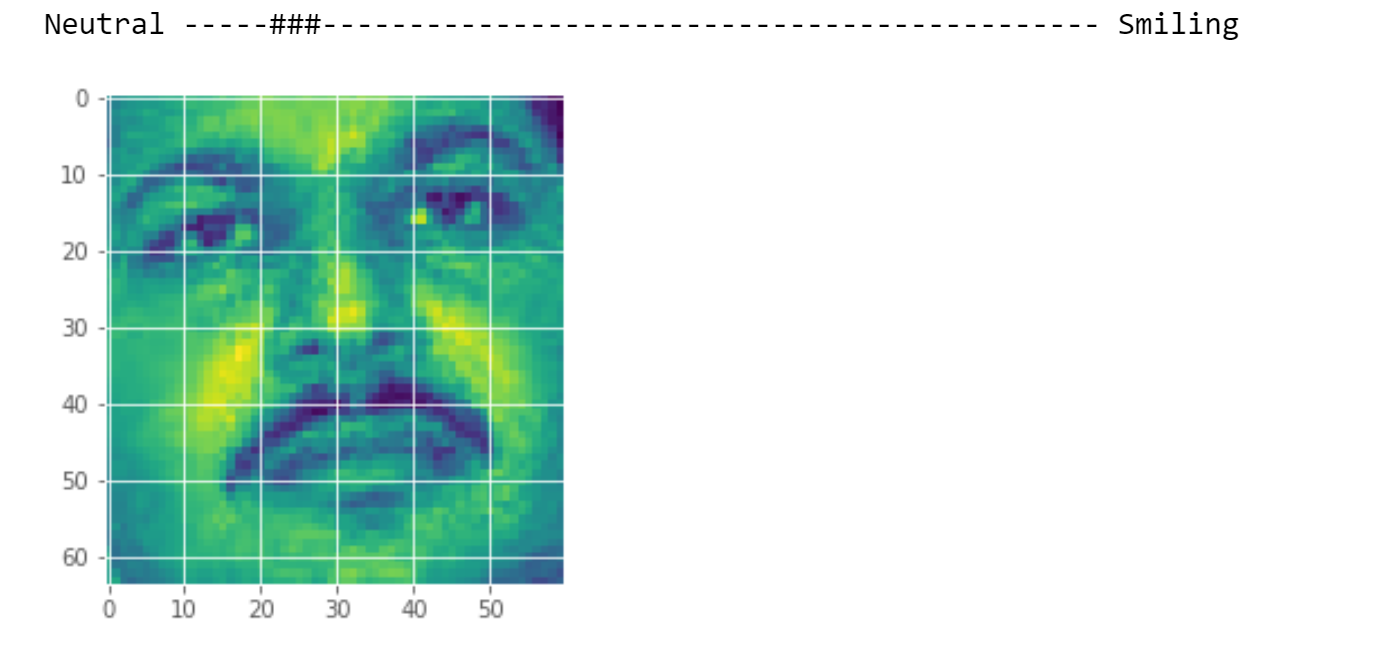
۴. آزمایش
برای اجرا از زبان python و محیط conda با requirement های زیر استفاده میکنیم:
conda==4.5.12
ipython==7.2.0
jupyter==1.0.0
Keras==2.2.4
matplotlib==3.0.2
numpy==1.15.4
Pillow==5.3.0
opencv-python==4.0.0.21
scipy==1.1.0
برای تست به نتایج زیر میرسیم:
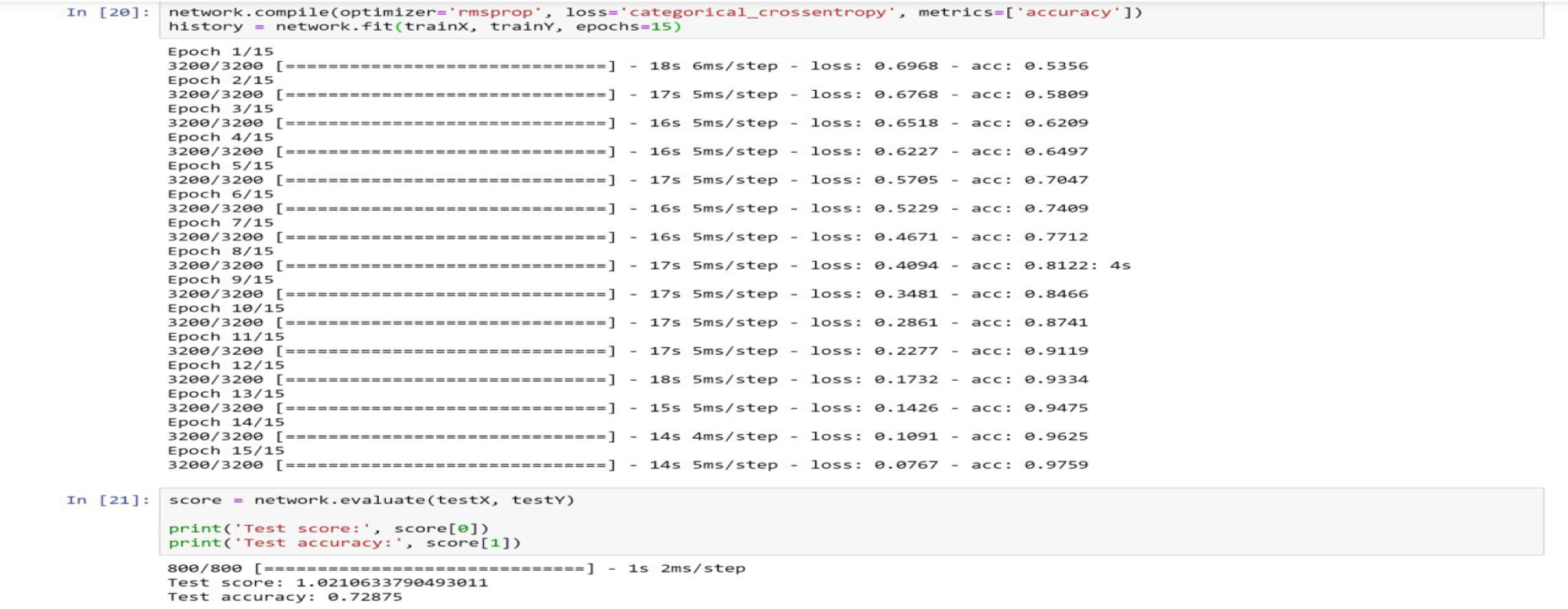
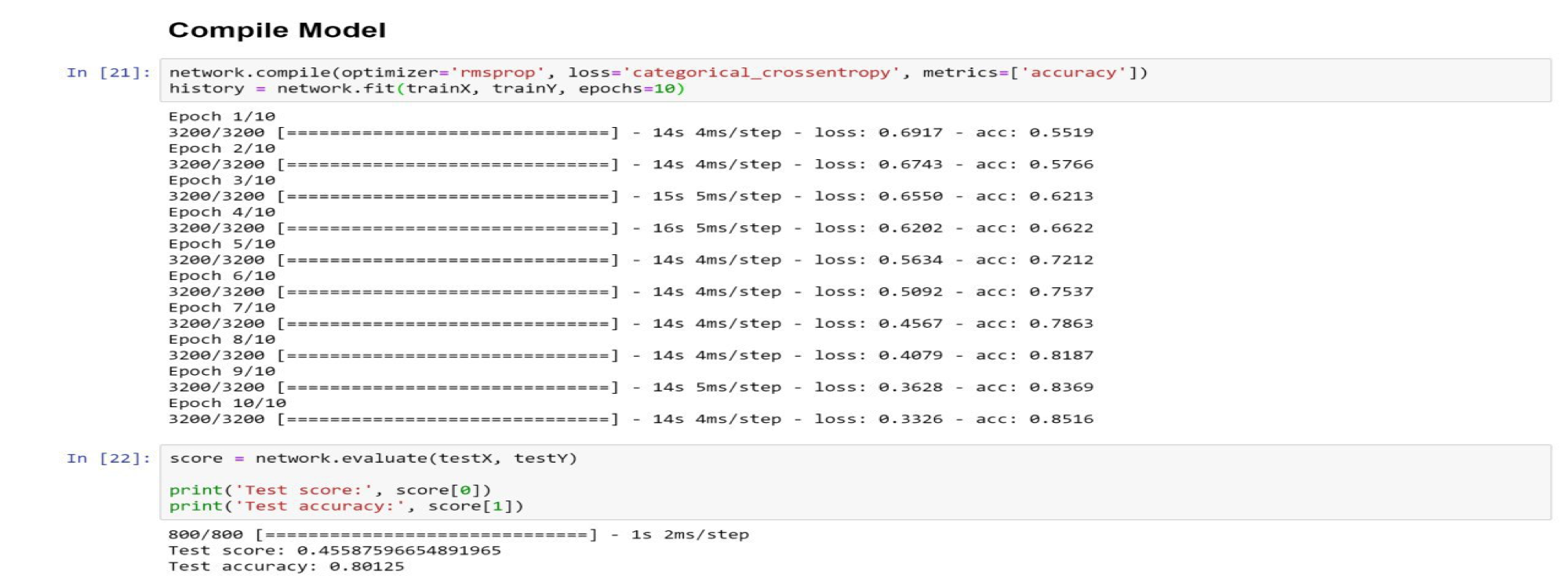
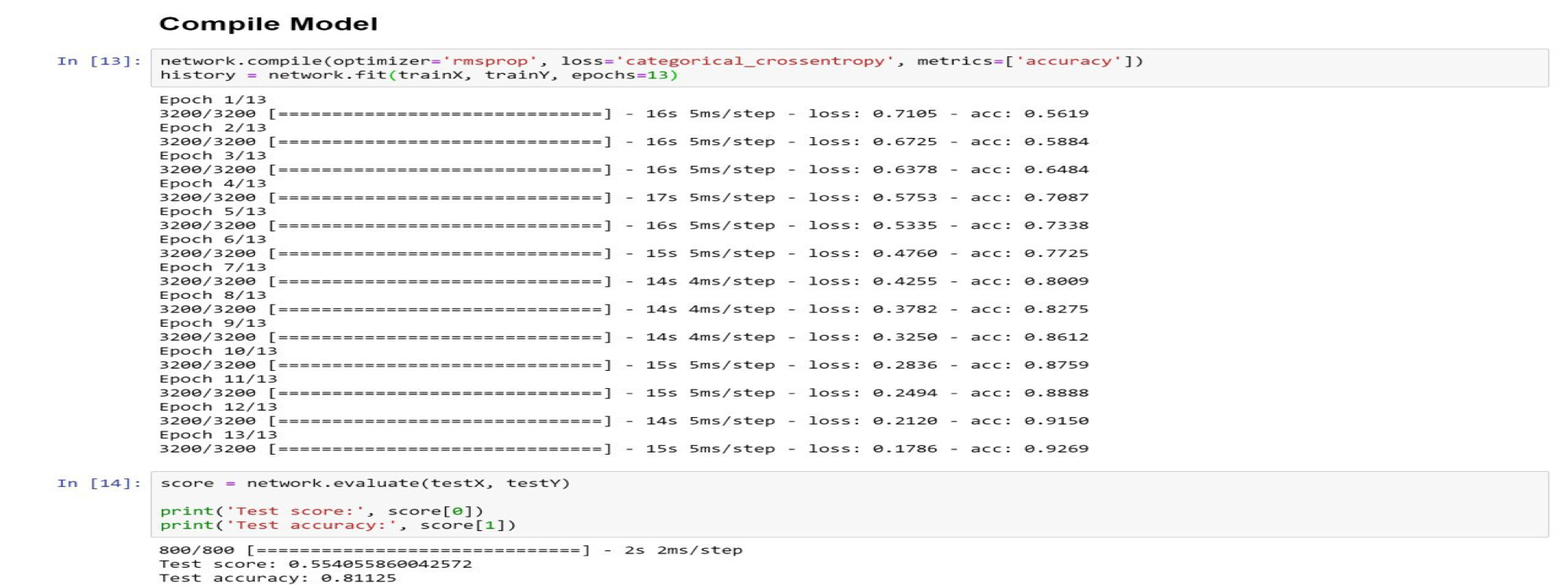
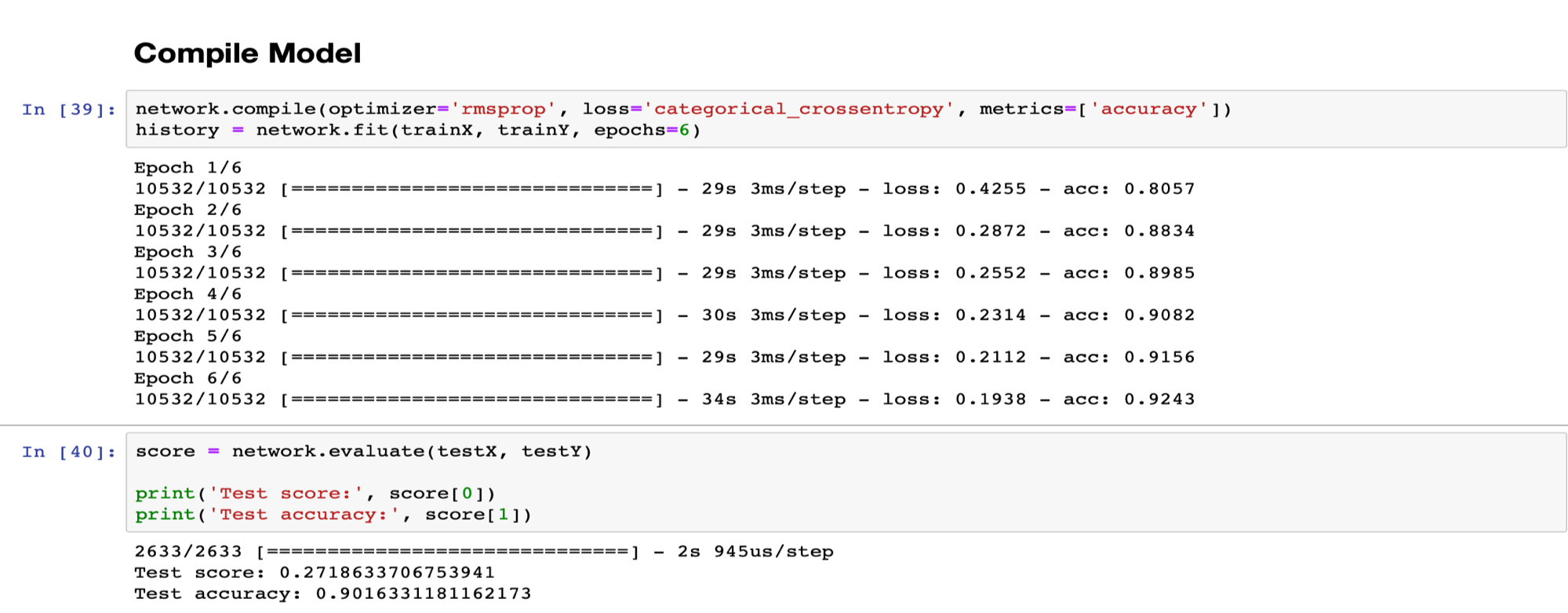
در دیتاست دوم به دلیل اینکه تعداد عکس ها بسیار بیشتر است، برای جلوگیری از overfit کردن مدل از تعداد epoch کمتر استفاده میکنیم.
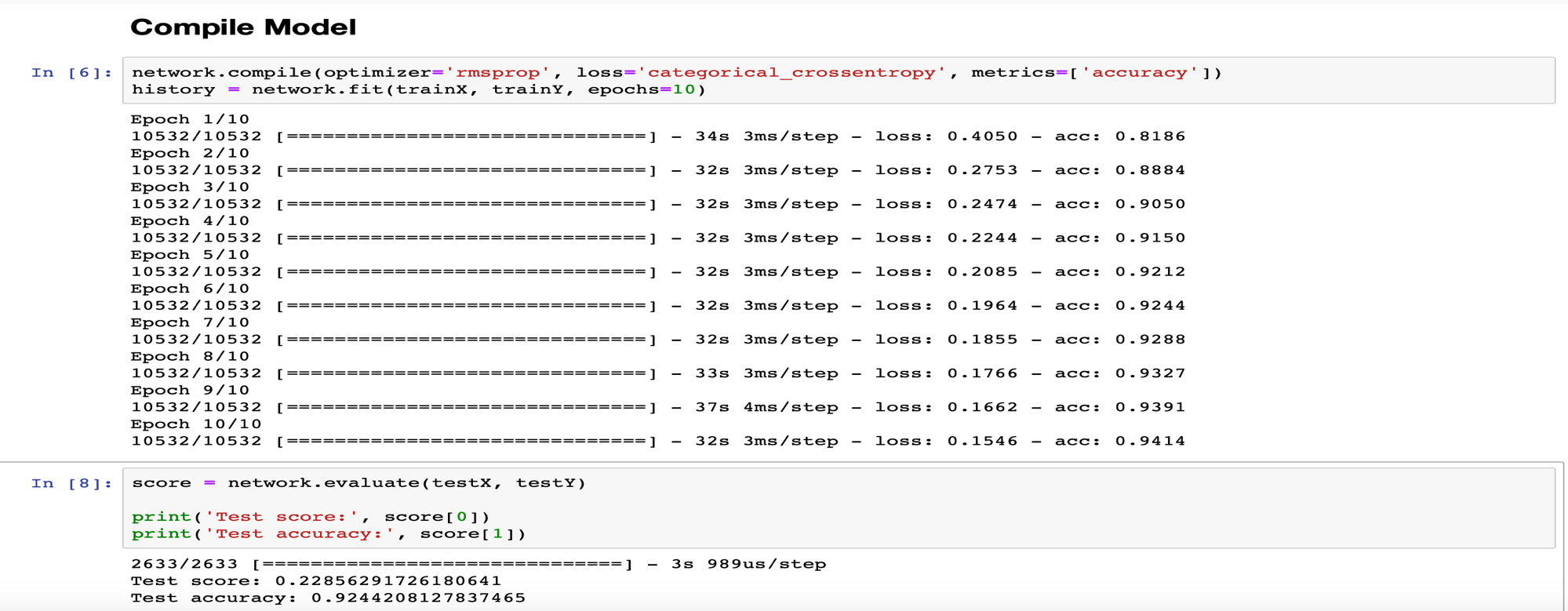
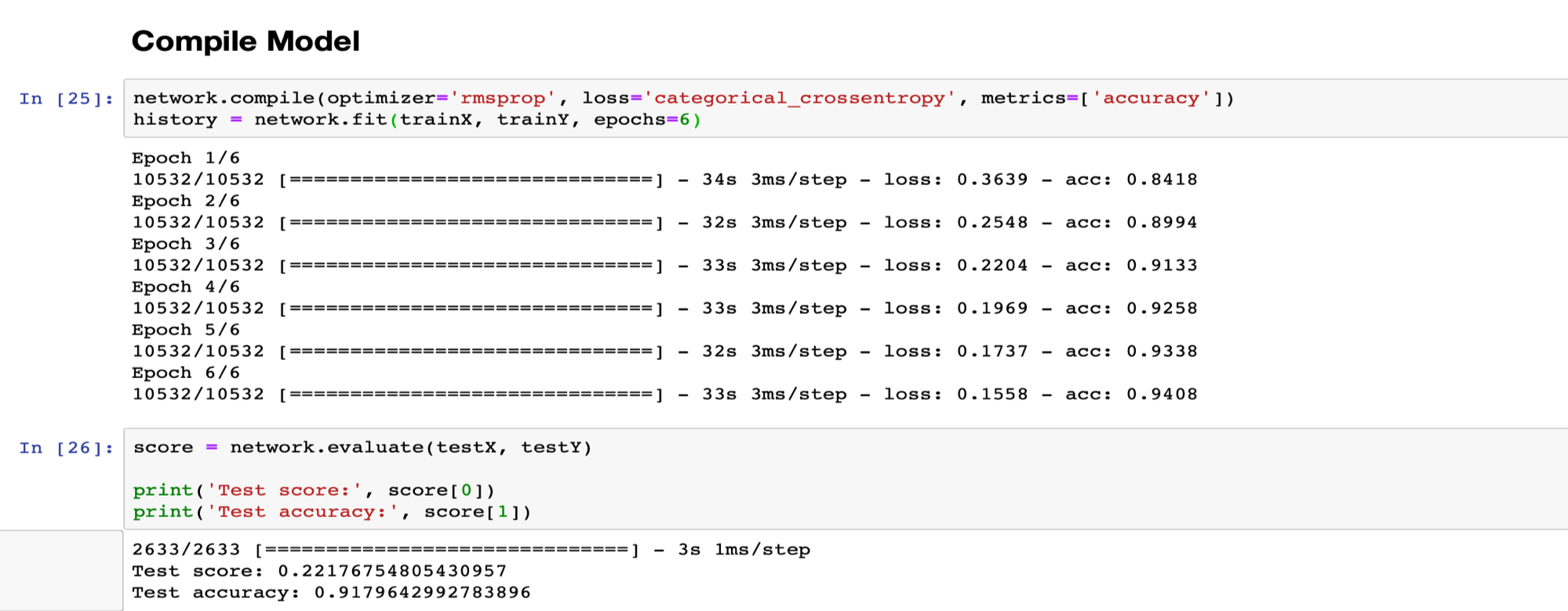
۵. تحـلیل و تفسیر نـتایج
نتایج به دست آمده طی آزمایشات و تست ها را میتوان از چند جهت بررسی و تفسیر کرد.
در وهله اول، بارزترین نکته ای که به نظر میرسد، اختلاف قابل توجه بین دقت عمل دو ماشینی است که بر روی دو دیتاست مختلف train شده اند. به جهت یادآوری ذکر میشود که دیتاست اول شامل 3200 و دیتاست دوم شامل 10532 عکس برای یادگیری بوده اند و دیتاست دوم نه تنها شامل تعداد عکس بیشتری بود، بلکه عکس های مناسب تری هم در آن وجود داشت.
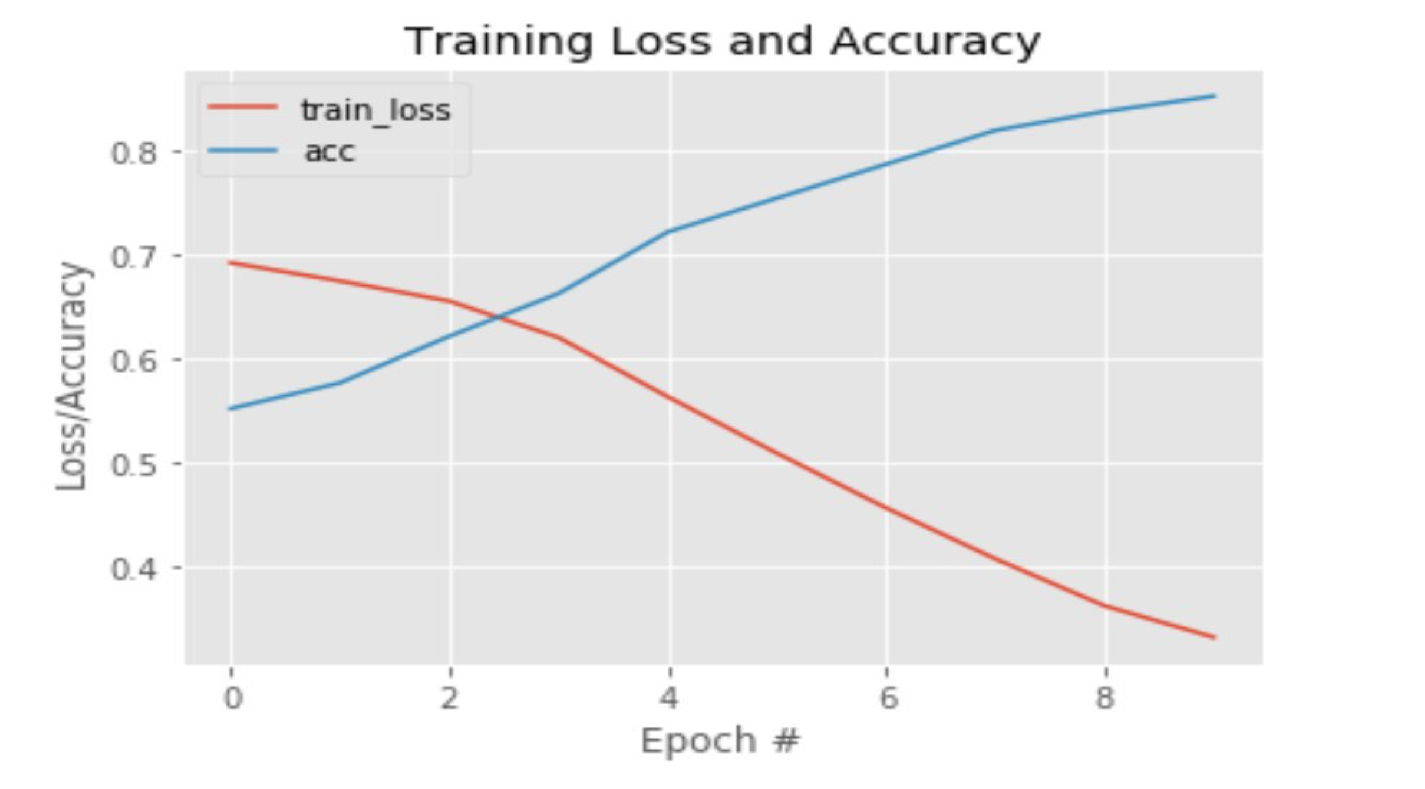
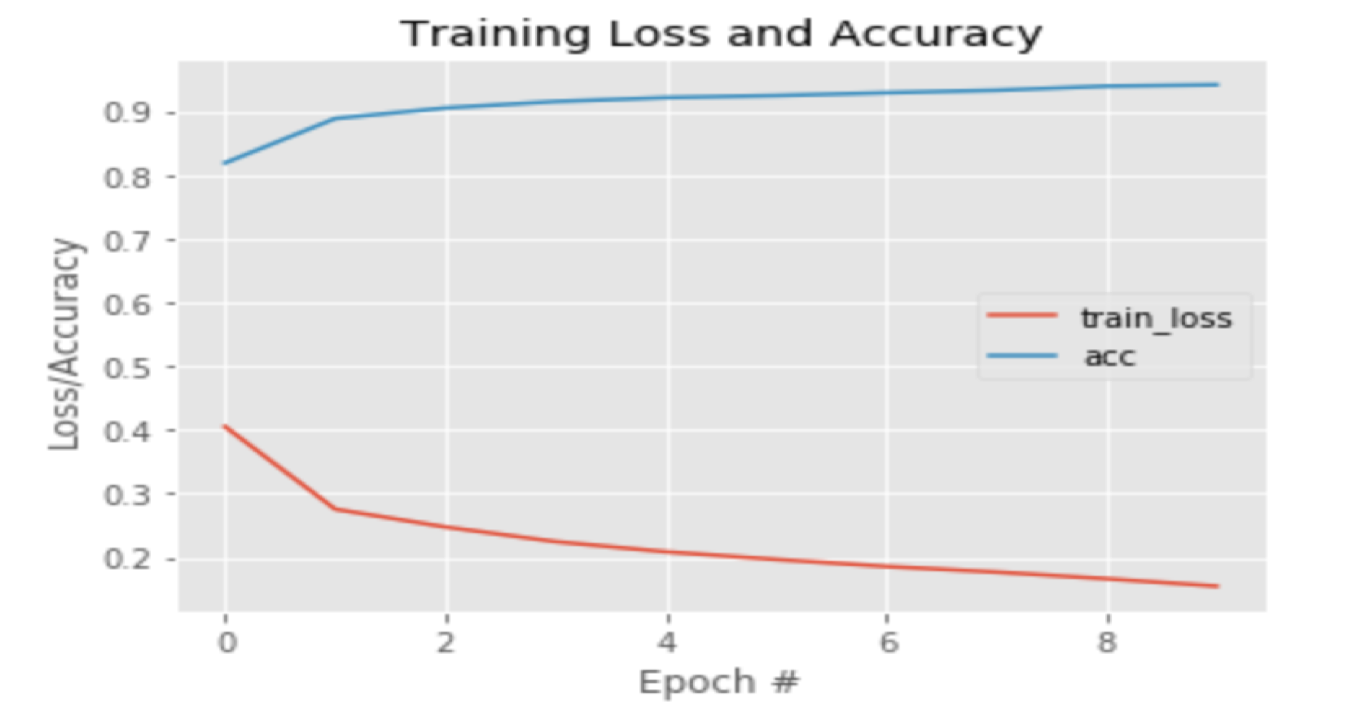
همانطور که از نمودارهای این دو مشخص است، میتوان به وضوح به اهمیت وجود یک دیتاست مناسب و خوب در فرآیند یادگیری پی برد. همانطور که مشاهده میشود، در هنگام یادگیری بر روی دیتاست اول، دقت اولیه بسیار پایین میباشد و تعداد epoch خیلی زیادی لازم است تا ماشین به دقت خوبی برسد. در صورتیکه در نمودار دوم میبینیم که اختلاف بین دقت ابتدایی و انتهایی بسیار کمتر از حالت پیشین است.
نکته دیگر، عملکرد بهتر معماری ما نسبت به معماری LeNet میباشد. این برتری به خصوص بر روی دیتاست اول که دیتاست ضعیف تری است، به خوبی نمود پیدا میکند. چرا که LeNet تنها به 72% دقت در فرایند ارزیابی رسیده ولی معماری ما به 80%. این اختلاف دقت را میتوان نتیجه ی افزودن یک لایه ی Convolution و یک لایه MaxPooling دانست و در نتیجه به تاثیر هر چه بیشتر لایه های Convolution در تشخیص الگوهای موجود در عکس ها پی برد.
۶. منابع
Our github link : https://github.com/oghahroodi/smile-detector