۱. تعریف مسئله
پیدا کردن راه حلی برای تشخیص لبخند در تصاویر ورودی و دسته بندی آن در دو دسته smiling یا non smiling
۲. مقدمه
مشکلی که قراراست این مساله حل کند در واقع راهکاری است برای تشخیص لبخند در تصاویر
برای این کار راه های بسیار زیادی را خواندیم و بررسی کردیم
در واقع ما دو راه کلی داشتیم:
استفاده از روش های یادگیری ماشین
استفاده از روش های یادگیری عمیق
برای هر دو این روش ها تحقیق و بررسی های لازم انجام شد و دیتا ست های مورد نظر بررسی گردید.
تفاوت دو روش:
در روش اول نیاز بود که خودمان ویژگی(فیچر)استخراج کنیم ولی در روش دوم فیچر ها توسط شبکه به دست می آیند.
پس به این نتیجه رسیدیم که استفاده از روش دوم مناسب تر است.
این گزارش طراحی و پیاده سازی یک آشکارساز لبخند بر اساس شبکه های عصبی کانولوشن عمیق را توصیف می کند(deep convolutional neural networks)
۳. کارهای مرتبط
در ابتدا باید بگوییم که روش های دیپ لرنینگ صرفا یک سری متودولوژی هستند و درواقع مقالات و تحقیقات روی ماشین لرنینگ انجام میشود که در درون دیپ پیاده سازی شده و ما آنرا به صورت بلک باکس میبینیم .
۳.۱. مسئله ی های مرتبط با تشخیص لبخند مسئله های تشخیص حالت های صورت هستند
مقاله ها و تحقیقات زیادی روی تشخیص حالات صورت به طور آکادمیک انجام شده اند مانند [1] و [2] اما تحقیقات منحصرا راجع به تشخیص لبخند کمتر است و از همین ها استخراج میشود و الگوریتم smile shutter سونی در دسترس نیست.
شرکت مولفه سنجش Omran [3] اخیرا یک نرم افزار معیار و تشخیص لبخند release کرده است، که به طور اتوماتیک صورت ها را(چه یک نفر و چه بیشتر) تشخیص میدهد و یک smile factor برای آن درنظر میگیرد که عددی بین 0 تا 100 درصد است. Omran از تکنولوژی 3D face mapping استفاده میکند و ادعا دارد که نرخ تشخیص های آن بیشتر از 90 درصد است.
اما این هم در دسترس نیست و ما نمیتوانیم چگونگی آن را تست کنیم و با برنامه ی خود مقایسه کنیم.
الگوریتم معتبری که الان در دسترس است برای Sony DSC T300 است و ما میتوانیم برنامه ی خود را با آن تست و مقایسه کنیم و نشان دهیم که به طور مثال ما performance بهتری داریم یا خیر.
3.2. Face Detection and Smile Detection scholar [4]
این تحقیقات بسیار جذاب در دانشگاه ملی تایوان انجام شده است و مقاله هم مربوط به دو دانشجو از همان دانشگاه است (Yu-Hao Huang , Chiou-Shann Fuh)
مراحل تشخیص صورت آنها به شرح زیر است :
FACE DETECTION
1- Histogram Equalization (متدی است برای بهبود کیفیت و کنتراست عکس ها )
2- AdaBoost Face Detection (برای بدست آوردن real-time face detection)
FACIAL FEATURE DETECTION AND TRACKING
3- Facial feature location (همه ی فیچر های صورت به درد نمیخورد ودر واقع فقط از مفید ها استفاده کرده است مطابق شکل نقاط مهم صورت را تشخیص میدهد)
4- Optical flow(اپتیمال فلو در واقع پترن احساسات موجودیت هاست و اکثرا برای تشخیص احساس از این پترن استفاده میشود)
3 assumptions:
* brightness consistency -> یعنی روشنی یک منطقه ثابت باقی میماند
* spatial coherence -> همسایه های یک نقطه فیچر معمولا احساس یکسانی دارند
* temporal persistence -> احساسات یک نقطه فیچر باید به مرور تغییر کند
۳.۳. پروژه های مرتبط
همانطور که میدانید برای پروژه های دیپ لرنینگ کدهای مشابه زیادی هست و افراد زیادی روش های متفاوتی را به کار برده اند
ما از هیچکدام به طور مستقیم استفاده ای نکردیم و سعی کردیم باروش خودمان به بهترین جواب برسیم.
خیلی از معتبر ترین راه ها به درصدهای خیلی پایینی رسیده بودند.
به طور مثال این لینک نتایج این پروژه در دانشگاه تگزاس و توسط یک محقق دیپ لرنینگ انجام شده است.
روش کلی این سیستم مشابه است اما جرئیات و امکانات بیشتری (appو ..) دارد.
طبق داده های آماری خودشان درصد performance کارشان هم 58درصد است .
روش کلی ما اندکی شباهت دارد(همه ی روش های دیپ لرنینگ یک بیس ثابت دارند) اما در دیتاست و نحوه ی گزینش آن تفاوت داریم و ما از داده های dev نیز استفاده کرده ایم که به بهبود کارمان انجامید.[5]
۴. آزمایشها
درابتدا به بررسی مراحل کارمان میپردازیم و سپس آزمایش هایمان در ادامه قرار دارند:
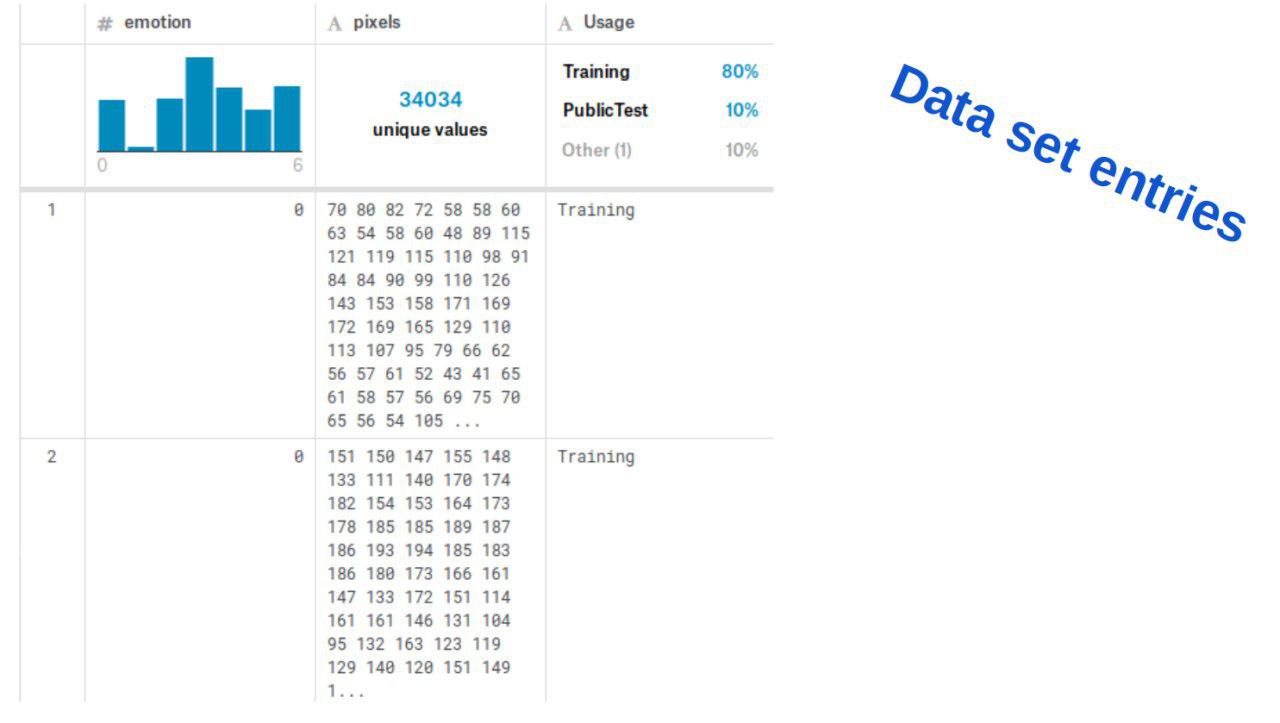
ابتدا انتخاب دیتا ست برای شناختن لبخند، آمار جامع از پایگاههای دادهای که در زمینه تشخیص بیان چهره محبوب هستند، تولید شد و نهایتا از دیتا ستfer2013 استفاده کردیم (از سایت kaggle)
لینک دیتا ست:https://www.kaggle.com/deadskull7/fer2013
| dev data | test data | train data |
| 12180 | 1505 | 1502 |
| 80% | 10% | 10% |
نمایی از دیتا ست و فیلدهای آنرا در شکل زیر مشاهده میکنید
۴.۱. مراحل کار
دو مرحله و الگوریتم اصلی برای این کار وجود دارد:
مرحله train
مرحله test
۴.۱.۱. مرحله train
قدم های زیر مراحل ما در ترین داده هستند:
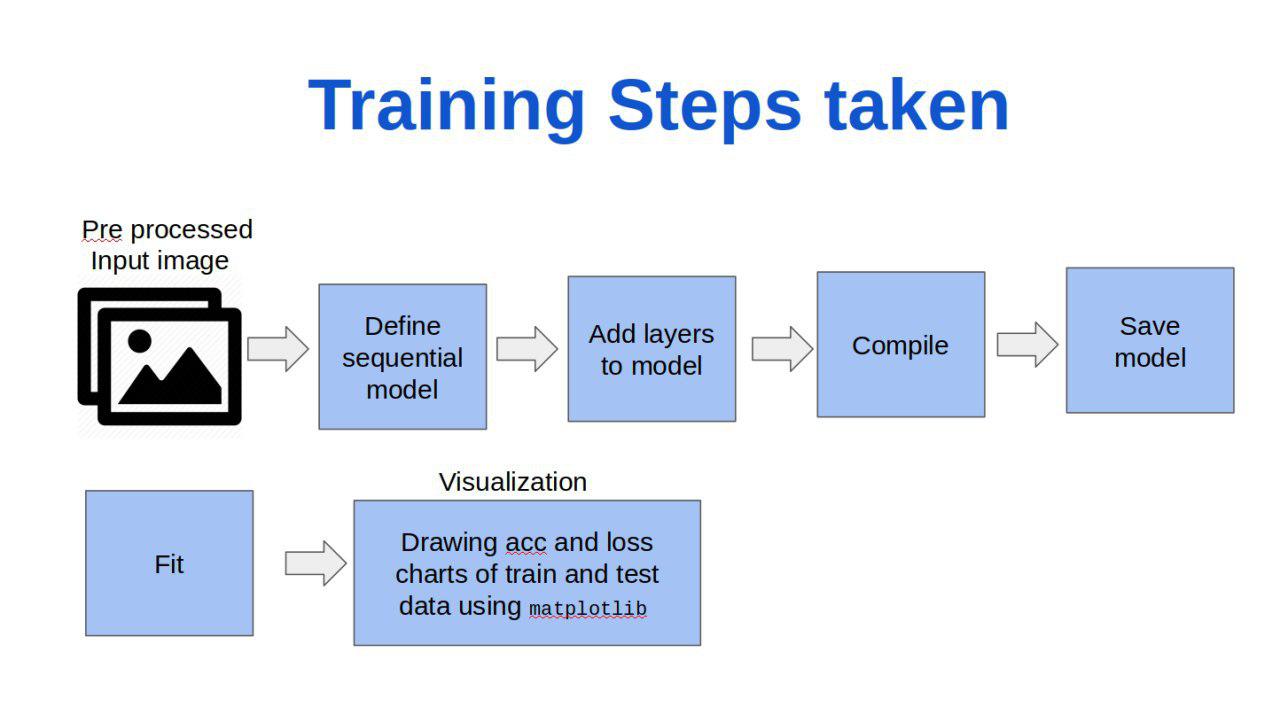
از توضیحات جرئیات کد پرهیز میکنیم چرا که آنها را در اسلایدی که برای روز ارائه آماده کرده بودیم نمایش دادیم و اکنون صرفا ابزار هایی را که استفاده کردیم نام میبریم:
با استفاده از ابزار keras در پایتون کد خود را پیاده سازی کردیم و از شبکه عصبی عمیق (CNN)استفاده کردیم.
تمامی مشاهدات و نمودار هایی که در اینجا میبینید نتیجه ی خروجی کد خودمان هستند و با کتابخانه ی "matplotlib" پیاده سازی شان کرده ایم.
در ضمن backend ما همان backend دیفالت کراس یعنی tensorflow است.
تابع بهینه ساز(optimizer) ما "adadelta" است .ابتدا به "adam"فکر کردیم و بنا به نتایجی که گرفتیم این بهینه ساز برای کار ما مناسب تر بود.
متریک بررسی ما نیز acuuracy میباشد.
تعداد ephoch ها : 50
سایز batch ؛ 128
نکته ی قابل توجه استفاده از dev data است به عنوان validation data
(همانطور که میدانید در اکثر کد ها ولیدیشن دیتا را همان دیتای تست میگذارند اما با بررسی فهمیدیم که اگر دیتایی غیر از تست باشد بهتر است
برای همین در دیتا ستی که انتخاب کردیم این نکته را لحاظ کردیم
دیتا ست ما دارای تگ public test و private test بود که به ترتیب آنها را به dev data و test data نسبت دادیم)
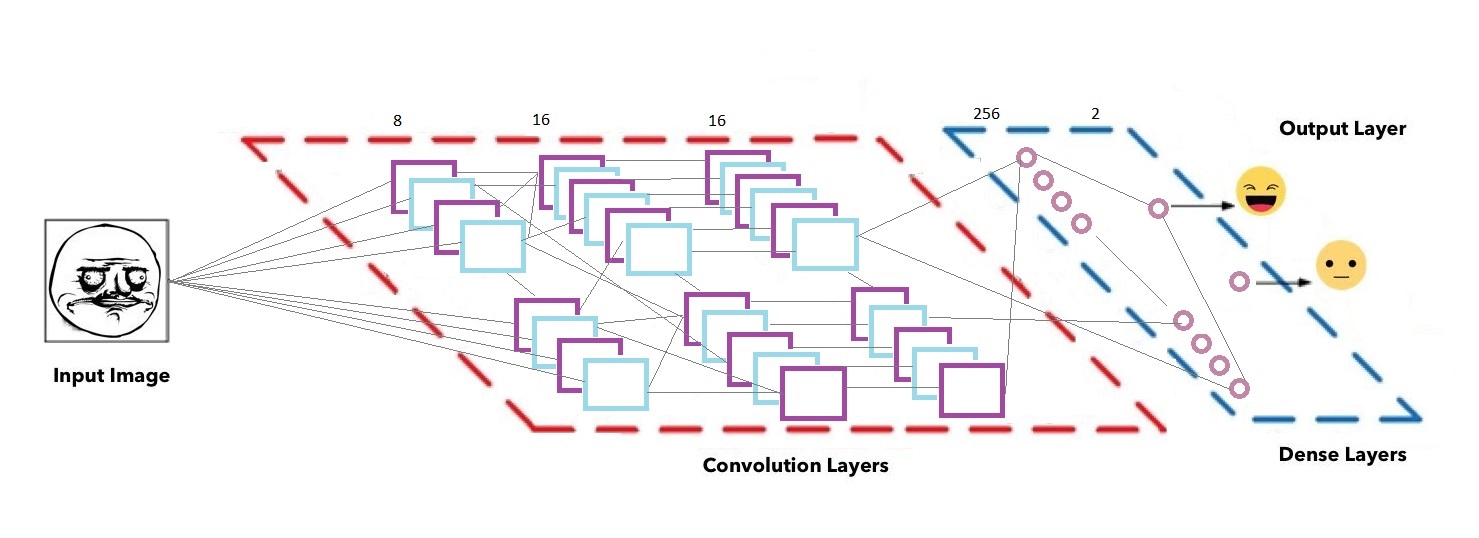
جزئیات شبکه عصبی
سه لایه Con2D و 2 لایه dense داریم(با فیلتر های 8 و 16 و 16 برای لایه های کانوولوشن)
برای تمامی لایه ها از maxpooling استفاده کرده ایم با سایز (2*2)
در دو قسمت کد هم از dropout های 0.25 و 0.5 برای جلوگیری از overfitting استفاده کردیم.
خروجی لایه دنس ما نهایتا یکی از دو کلاس smiling یا non smiling خواهد بود.
بخش ارزیابی مدل
با استفاده از ابزار callback کراس و به کار بردن modelcheckpoint بعد از هر epoch بهترین نتایج را (save_best_only) در مدل خود را ذخیره کردیم.
۴.۱.۲. مرحله test
قدم های زیر مراحل ما در تست داده هستند:
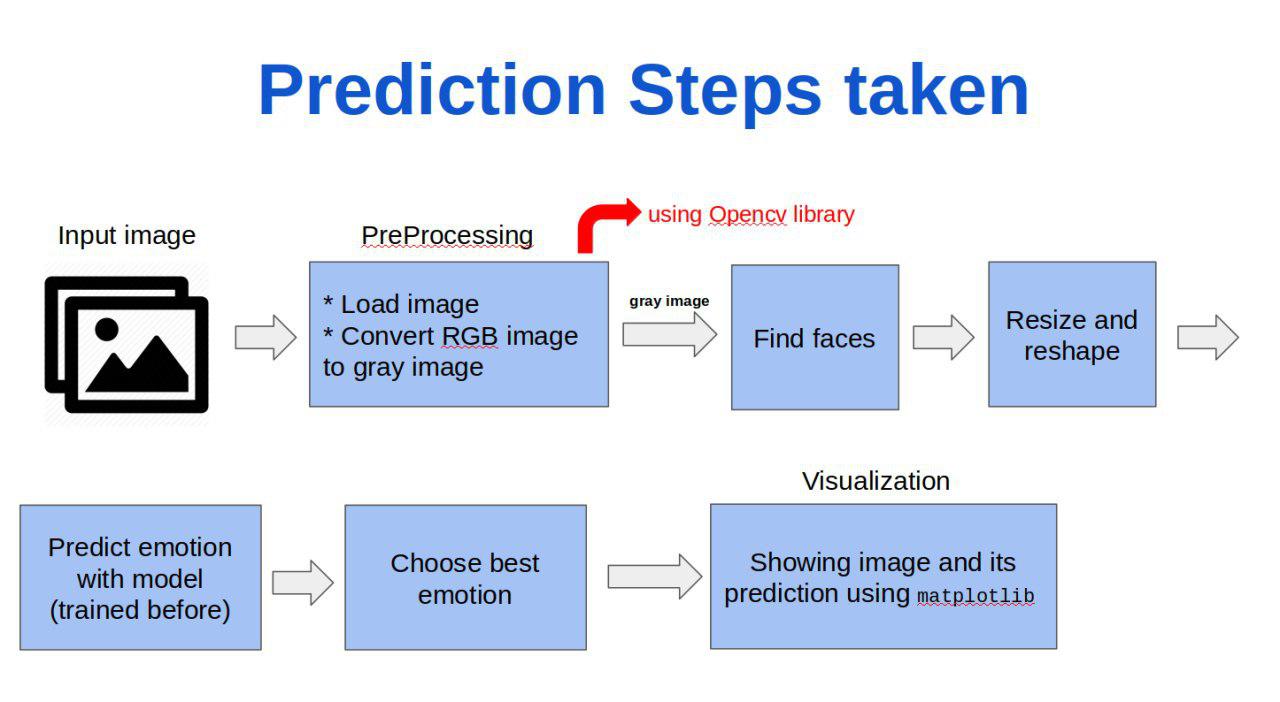
برای تست کردن برنامه کافیست دستور مقابل را بزنید:
python predict.py image_address
چالش های ما در پیاده سازی؛
همانطور که میدانید در روش های دیپ در ساختار شبکه عصبی یک سری اطلاعات عددی وجود دارد مثل تعداد فیلتر ها که هیچکس دقیقا از ابتدا نمیداند کدام بهتر است و ما تمامی حالت های ممکنه را چک کردیم تا به بیشترین acc و کمترین loss برسیم.
به طور مثال یک نمونه ازاعداد قبلی را که گذاشتیم در زیر مشاهده میکنید و نمودار های آن هم موجود است(با اعداد 16 و32 و 32 )
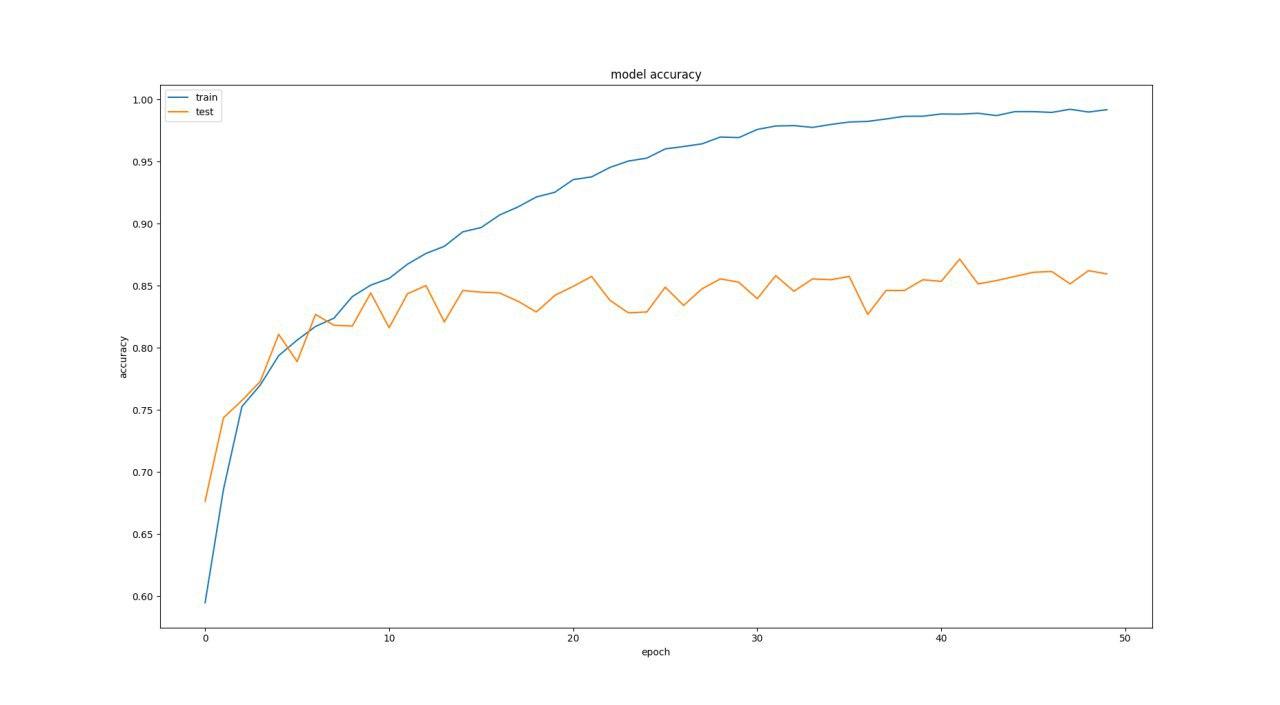
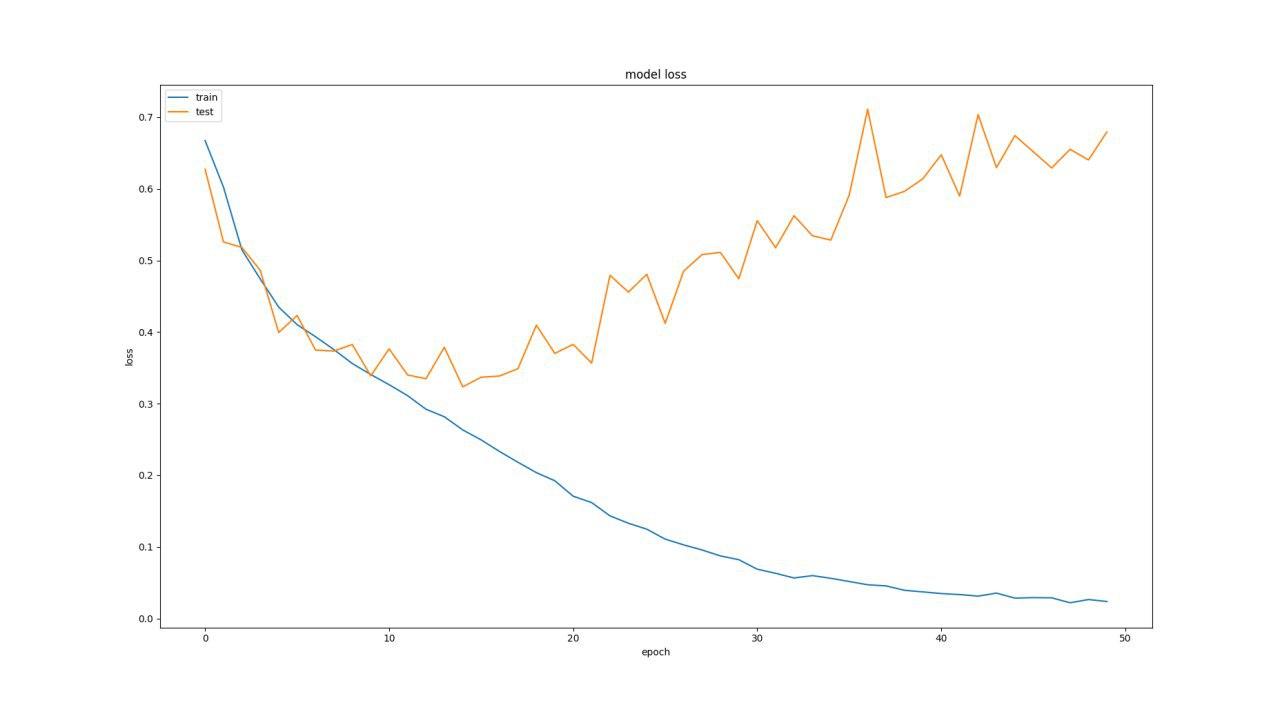
Test loss: 0.6608016912129234
Test accuracy: 0.8644518272425249
همانطور که میبینید درصد لاس بسیار زیادی داریم و اکیورسی هم زیاد ایده آل نیست.(لاس زیاد -اکیورسی کم - شبکه ی بزرگتر - تعداد پروسس های بیشتر- دقت تست پایینتر)
به طور مثال این سیستم عکس زیر را عادی تشخیص میداد در حالی که میخندد

پس به دنبال تعویض ساختار شبکه بودیم
تا به حالت (8و16و16) رسیدیم.
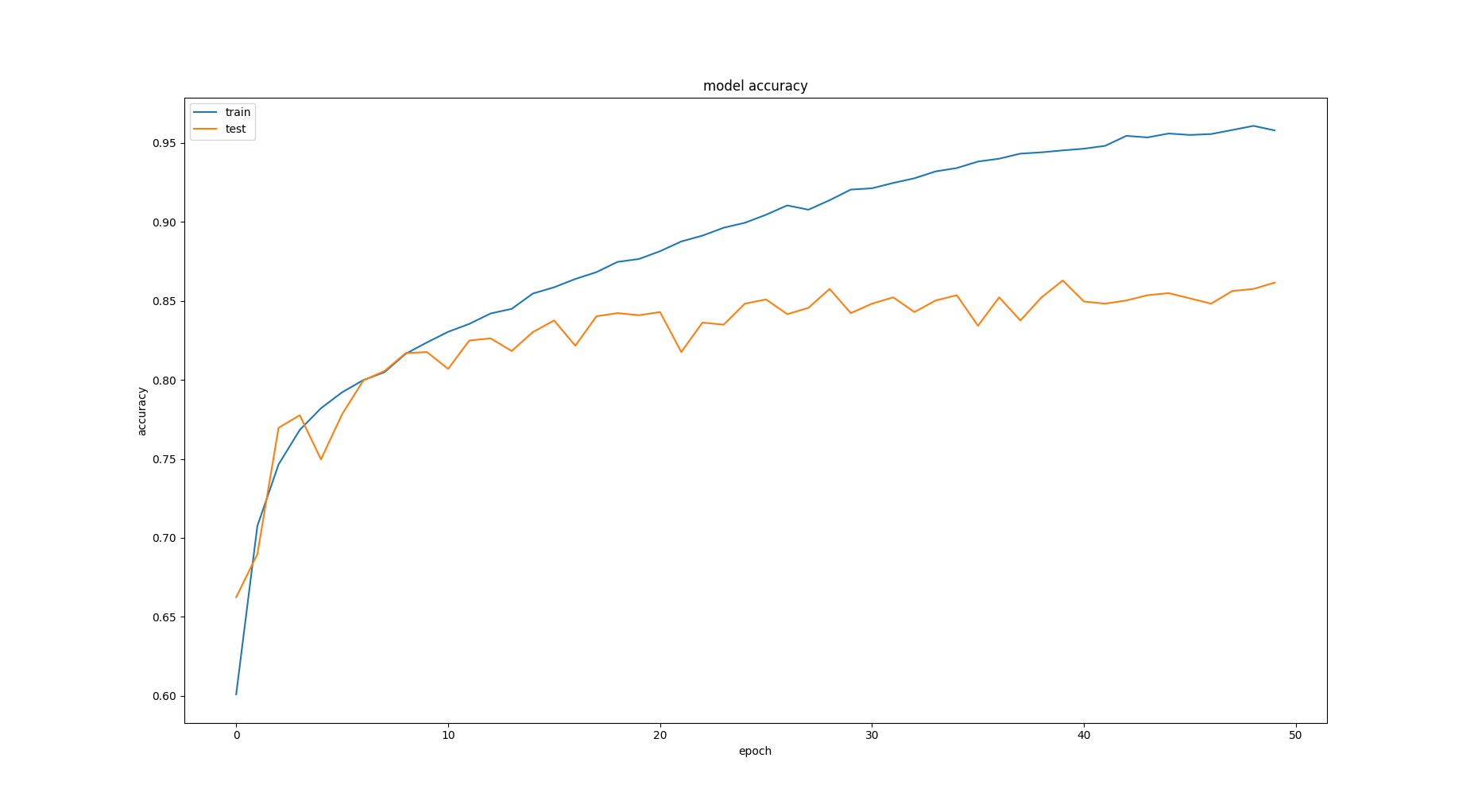
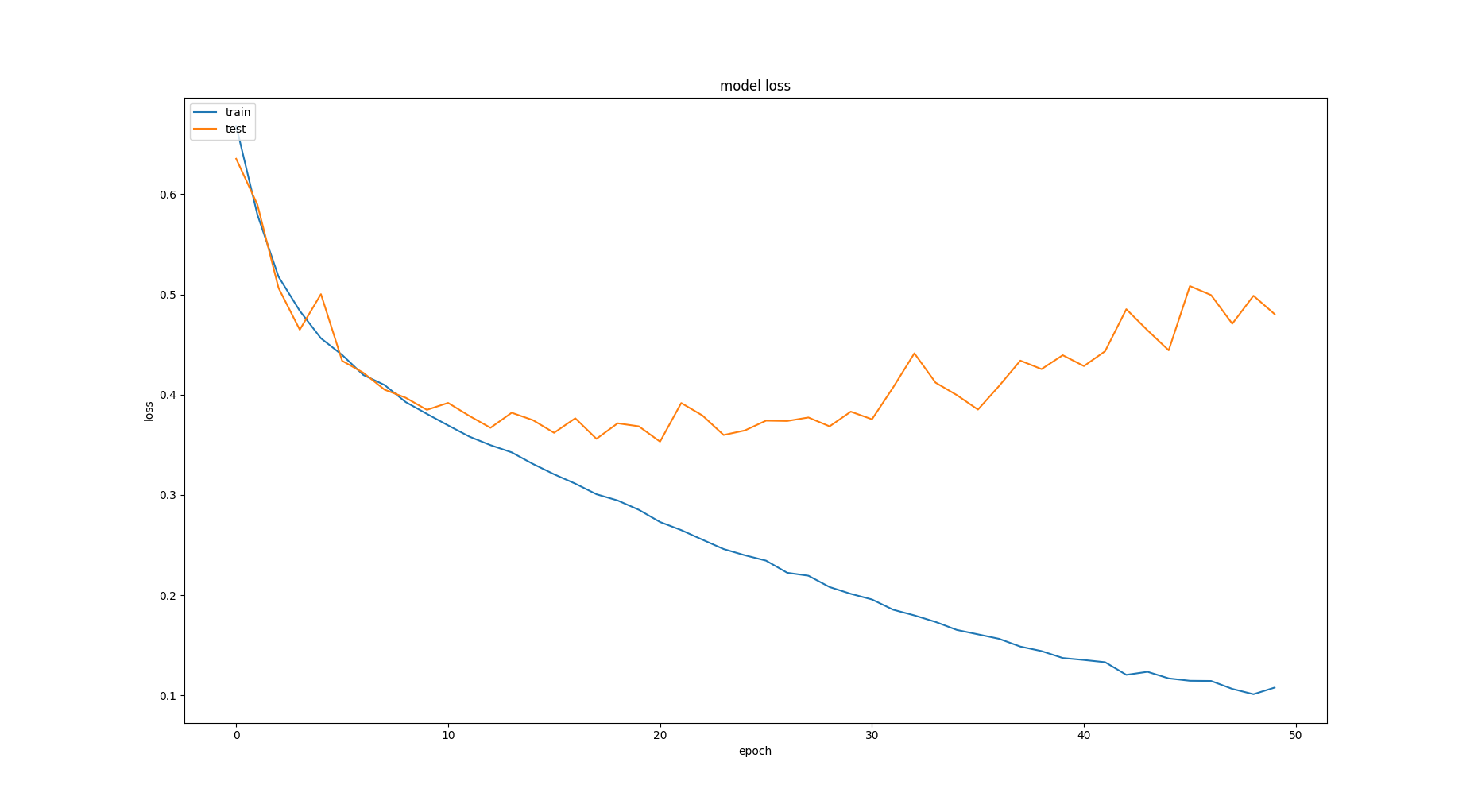
همانطور که میبنید به درصدهای زیر رسیدیم که به نسبت حالت های پیش بسیار بهتر بودند.
۴.۲. نتایج مشاهدات
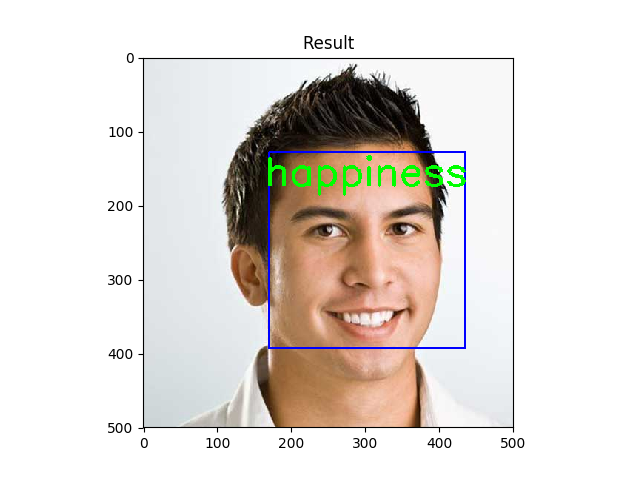
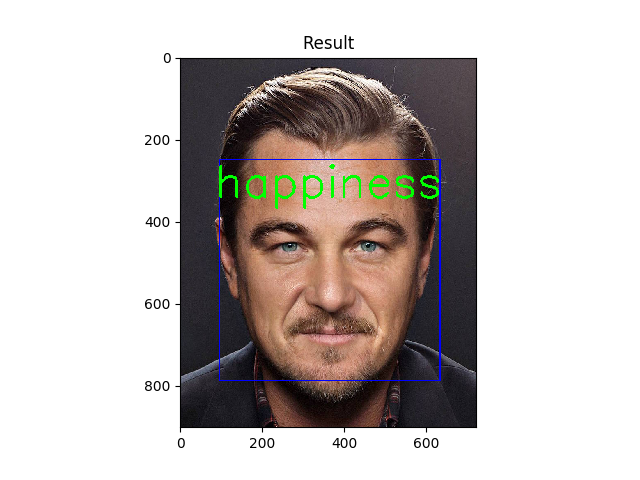
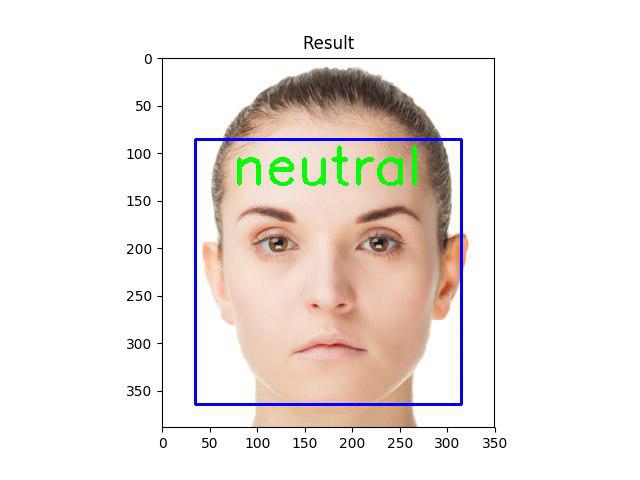
نمونه ای از داده هایی که سیستم ما به درستی تشخیص داده است را مشاهده میکنید(این تصاویر اسکرین شات خروجی کد ما و کاملا واقعی هستند):

تصاویری که در سیستم مابه عنوان ورودی های نامعتبر شناخته میشوند:
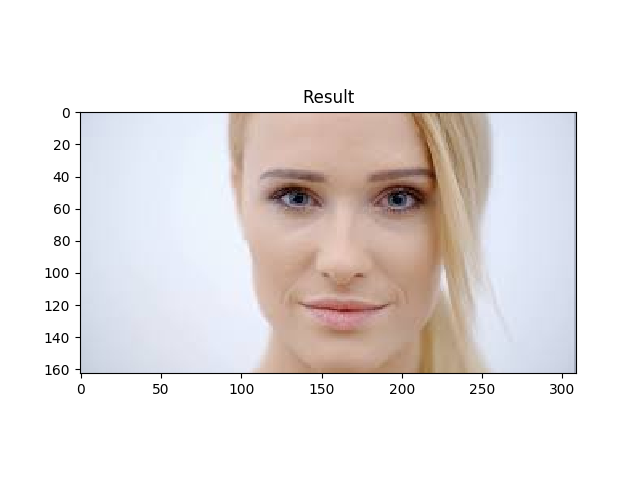
دلیل آن کامل نبودن صورت در عکس است .(ابزار openCv صورت نصفه را تشخیص نمیدهد )
خروجی های غلط
همانطور که میدانید کار ما با درصد خطایی همراه است چون به accuracy صد در صد نرسیده ایم.
برای پیدا کردن عکس هایی که خروجی اشتباه میدهند از train وtest وdev کدی نوشتیم که عکس های اشتباه را برایمان ذخیره کند
در پروژه در فولدر های train_mistaksو test_mistakes و dev_mistakes پوشه هایی به نامهای whوwnوجود دارد:
آنهایی که happy بودند و neutral تشخیص داده شدند =wh
آنهایی که neutral بودند و happy تشخیص داده شدند = wn
با استفاده از این اطلاعات به یک سری کار محاسباتی پرداختیم تا از نتایج خود مطمئن شویم.
در واقع میخواستیم ببینیم آیا این تعداد غلط به تعداد کل همان درصد خطایی که سیستم به ما داده میشود یا نه .

به طور مثال عکس بالا در حال لبخند است ولی در سیستم ما اشتباه ترین شده است(خطای مربوط به ترین)

این عکس هم حالت عادی است اما به عنوان خروجی لبخند در تست ما وجود دارد(خطای مربوط به تست)
نمونه های کاملتر عکس ها برای هر سه دسته را هم در گیت و هم در فایل پی دی اف ارائه مان میتوانید مشاهده کنید
بخش محاسبات
TRAIN
total train dataset = 12180
total mistakes = wh + wn = 71 + 102
error percentage = (173/12180)100 = 1.42
correctness = 100 - 1.42 = 98.58
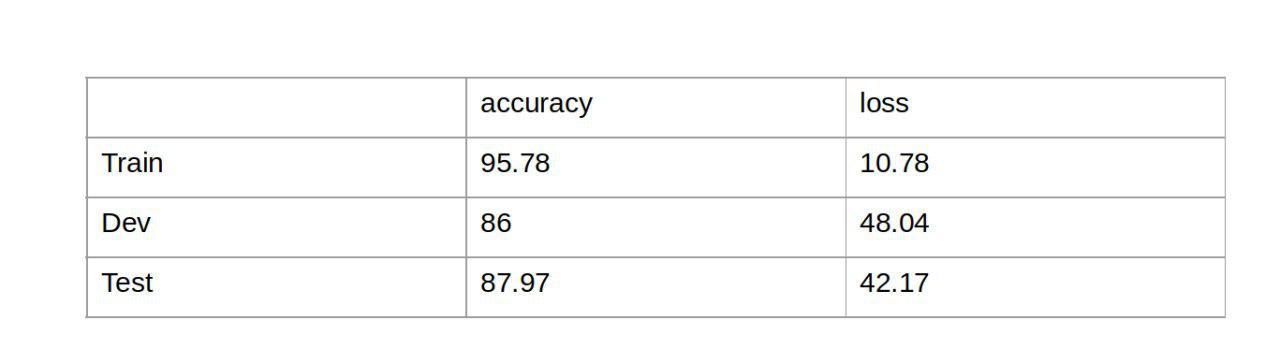
train accuracy = 95.78
علت تفاوت اندک : 2 3 درصد تفاوت دلیلش میتواند این باشد که در واقع acc در هر batch به طور میانگین گرفته میشود و در این حجم زیاد داده میانگین با داده اصلی تفاوت دارد و مطمئنا 2-3 درصد خطا را به همراه دارد.
در واقع accuracy درست سیستم ما 98.58 است اما کراس به ما 95.78 خروجی داد که با توجه به دلیل بالا منطقی است.
TEST
total test dataset = 1505
total mistakes = wh + wn = 80+113
error percentage = (193/1505)100 = 12.82
correctness = 100 - 12.82 = 87.18
test accuracy = 87.97
همانطور که میبیند در دیتای کمتر (تست) درصد خطا بسیار کمتر است و نتایج خیلی نزدیک و شبیه هستند.
DEV
total dev dataset = 1502
total mistakes = wh + wn = 94 + 112
error percentage = (206/1502)*100 = 13.71
correctness = 100 - 13.71 = 86.29
dev accuracy = 86
و در این حالت هم به برابری رسیدیم.
هم چنین با ابزار های visualization تمامی فیلتر هارا به صورت عکس نشان داده ایم (model.get_weight)
به طور مثال این 8 عکس فیلتر های لایه ی اول هستند:

برای عکس زیر نیز فیلتر های سه لایه را برای یک عکس(اولین عکس از بالا) خروجی گرفتیم که میتوانید مشاهده کنید:



۴.۳. سیستم RealTime
محاسبه Response Time
برای همه ی این مراحل در کدمان محاسبه ی response time هم در نظر گرفتیم که از کارایی سیستم خود مطمئن شویم(تمامی نمودار ها و داده های زیر هم خروجی کد خودمان هستند .)
آنالیز های مربوط به سرعت و کارایی(performance):
سیستم ما همانگونه که در عکس های زیر مشاهده میکنید هرتعداد صورت در عکس باشد (اگر مجاز باشد ) تشخیص میدهد
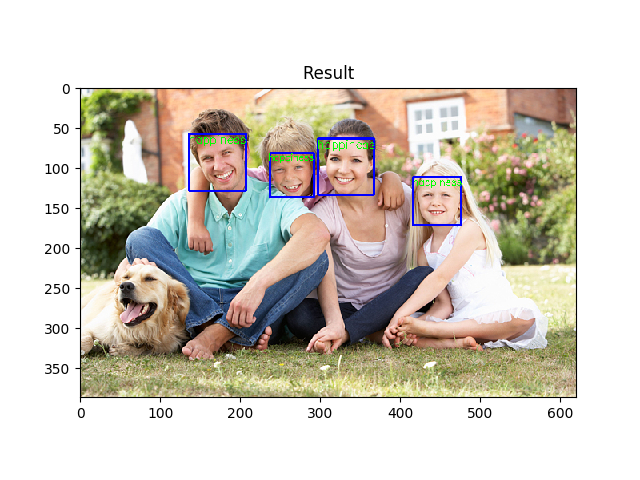
image size : 640 480
number of faces = 4
max response_time = 0.18397s

image size : 640 480
number of faces = 4
max response_time = 0.3157s
دلیل عدم تشخیص آن دو صورت -> زاویه دار بودن آن(داده ورودی غیرمجاز)
در واقع opencv صورت های زاویه دار را تشخیص نمیدهد.

image size : 1131* 679
number of faces = 12
max response_time = 0.4209s
برنامه ی ما سیستم real time را هم پشتیبانی میکند به طوری که میتوانید با استفاده از webcam تصویر خود را به کد ما داده و در لحظه خروجی آنرا روی صفحه ببینید.
کافیست دستور روبرو را اجرا کنید :
python webcam.py
برای این کار باز هم ResponseTime را محاسبه کردیم و در بازه ی طولانی تست انجام شد و نتایج همیشه خوب و سریع و نزدیک به هم بودند
که در تصویر زیر میتوانید مشاهده کنید:
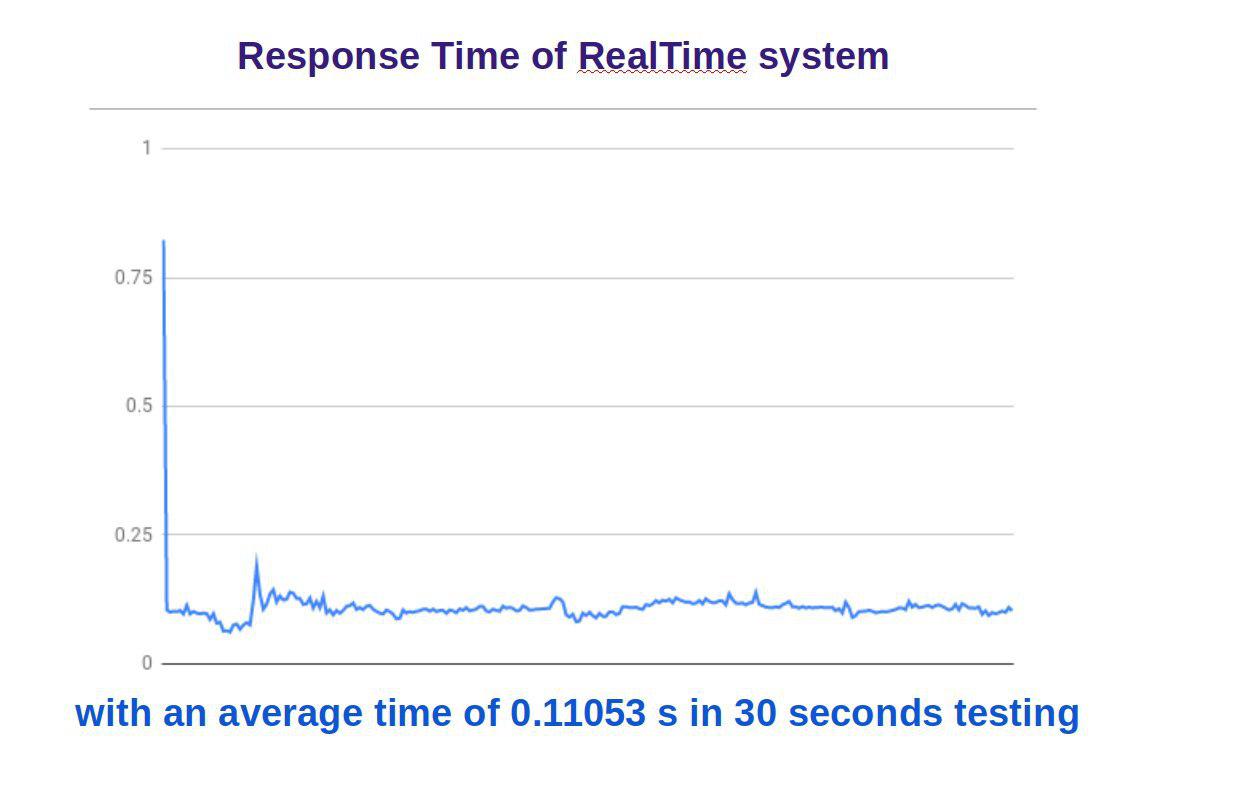
زمان پاسخ سیستم به طور میانگین 0.11053 ثانیه میباشد.
علت صعود لحظه ی اول و زمان ابتدایی نزدیک 0.8 ثانیه فقط setup اولیه ی دوربین است.
۵. کارهای آینده
ایده های دیگر ما برای آینده این است که حالتهای دیگر صورت را هم به کدمان اضافه کنیم و در واقع یک سیستم facial expression recognition داشته باشیم با کارای و سرعت خوب همانند الان و هم چنین دقت بالا در ترین و تست .
احتمالا همه ی چیز هایی که برای کلیه ی حالتهای صورت بخواهیم موجود نباشد و دوست داشتیم با استفاده از ماشین لرنینگ خودمان یک سری ویژگی(feature extraction) به آن اضافه کنیم (خط های صورت و روش landmarks)
هم چنین بتوانیم به حالتی برسیم که سیستم ما happy بودن و درعین حال non-smiling را نیز تشخیص دهد.
۶. مراجع
[1] M. Pacntic, S. Member, and L. J. M. Rothkrantz "Automatic analysis of Facial Expressions: The State Of The Art", IEEE Transactions on Pattern Analysis and Machine intelligence, Vol. 22, pp. 1424-1445, 200.
[2] B. Fasel and R. E. Schapire, "A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting, "Journal of Computer and System Sciences", Vol. 55, No. 1, pp. 119-139, 1997
[3] Omron, "OKAO Vision,”
http://www.omron.com/r_d/coretech/vision/okao.html, 2009
[4] https://www.csie.ntu.edu.tw/~fuh/personal/FaceDetectionandSmileDetection.pdf
[5] https://github.com/topics/smile-detection