با توجه به طیف وسیع و گسترده اسناد و متون در قالبهای دیجیتال، طبقه بندی متون نقش مهمی در استخراج اطلاعات و خلاصه سازی و بازیابی متن ایفا می کند. برای بازیابی آسان این اسناد دیجیتالی، این اسناد باید طبق محتوای آنها طبقه بندی شوند.
هر روز با متون مورد استفاده در موضوعات گستردهای مواجه هستیم، بعنوان مثال مقالات علمی، گزارش های خبری، نقد فیلم و تبلیغات و ... . دسته بندی متون کاربردهای زیادی مثل تشخیص موضوع اخبار، لحن نقد(مثبت یا منفی) و یا تشخیص زبان متن را ارایه میدهد.
هدف از این پژوهش ارائه و بررسی روشهایی برای کلاس بندی متون خبری از دو موضوع "ورزشی" و "سیاسی" است.
۱. مقدمه
۱.۱. روشهای مورد بررسی برای دستهبندی متون:
با رشد مداوم فناوری اینترنت و دسترسی آسان به آن، کاربردهای زیادی در بستر اینترنت گسترش یافتهاند. از جمله مهمترین این کاربردها، سایتها و مقالات خبری هستند که امروزه یکی از اصلیترین منابع خبری بشمار میروند. بنابراین دستهبندی این متون از اهمیت بالایی برخوردار است.
روشهای متنوعی برای دسته بندی موضوعی متون استفاده شده اند.
روش اول مورد استفاده در این مقاله، مبتنی بر ساختن مدلی از دادهها و دستهبندی متن بر اساس شباهتها و تفاوتهای آنها هستند. در این روش دستهبندی پدیدهها بر پایه احتمال وقوع یا عدم وقوع یک پدیده است. در این روشِ کلاسهبندی با دریافت یک مجموعه داده به عنوان دادههای تمرینی، آموزش داده میشود و شیوهی یادگیری در الگوریم به روش یادگیری با ناظر است. به طور کلّی این روش بر پایهی نظریهی بِیز در زمینهی آمار و احتمالات بنا شده است.
روش دوم استفاده از الگوریتم های یادگیری ماشین (MachineLearning) و حل مساله با استفاده از شبکههای عصبی میباشد. مدل استفاده شده در این راه حل، مدل پرسپترون چند لایه (MLP) است. یک شبکه عصبی مجموعه ای از واحدهای ورودی و خروجی متصل به هم است که در آن به هر ارتباط وزن مشخصی اختصاص داده میشود. در طول مرحله یادگیری، شبکه با تنظیم وزنها یاد میگیرد تا بتواند برچسب کلاس صحیحی از ورودی را پیشبینی کند. در ادامهی این پژوهش به بررسی دو روش گفته شده برای دستهبندی متون و مقایسه و ارزیابی این روشها پرداخته شده است.
۱.۲. مراحل پیادهسازی یک کلاسهبند متن:
بطور کلی برای دستهبندی متن مراحل زیر باید انجام شوند:
۱.۲.۱. جمع آوری دادهی تمرینی و آزمایشی
نیاز به جمع آوری دادهی متنی از دو کلاس مختلف داریم. روش بدست آوردن داده لازم از طریق اینترنت و از سایتهای خبری معتبر بوده است..
۱.۲.۲. پیش پردازش روی داده و آماده سازی برای اجرای الگوریتم
شامل تمیز کردن داده، حذف کلمات اضافی، ریشه یابی کلمات و ... .
۱.۲.۳. پردازش روی متن با استفاده از الگوریتم مورد نظر
این مرحله شامل پیادهسازی الگوریتم Naïve bayes و MLP است.
۱.۲.۴. ارزیابی نتایج و ارائه روشهایی برای بهتر شدن نتایج
روشهای زیادی برای ارزیابی نتایج وجود دارد، با این حال در این پروژه از سه معیار recall، precision و accuracy که سه روش متداول برای ارزیابی عملکرد الگوریتم هستند استفاده شده است.
۲. کارهای مرتبط
تا به امروز روشهای متفاوتی برای دستهبندی متون استفاده شدهاند بعنوان مثال در سال 1999 روشی دسته بندی متـون بـا اسـتفاده از بردارهـای فراوانـی ریشـه کلمـات انجـام شد[1]. در ســال 2001 در پژوهشی از شــبکه هــای عصــبی هیبرید به منظور دسته بندی متون استفاده شد[2].
بطور کلی برخی از روشهای موجود را بصورت زیر میتوان خلاصه کرد.
شبکههای عصبی ( عمیق ):
استفاده از انواع مختلف شبکههای عصبی برای ساخت مدل؛ و تشخیص و کلاسهبندی دادهها. این روش از قویترین و مهمترین روشهای Natural Language Processing و به صورت کلی تمامی زمینههای هوش مصنوعی است.
درخت تصمیم گیری:
در این روش ردهبند به کمک دادههای تمرینی، یک درخت تصمیمگیری تولید میکند و سپس در فاز آزمایش هر دادهی جدیدی که وارد میشود، از ریشهی درخت شروع میکند به حرکت کردن و در هر مرحله با انتخاب یکی از شاخههای درخت به یک سطح پایینتر در درخت میرود. آنقدر این مسیر ادامه پیدا میکند تا داده به یک برگ برسد و نهایتاً مقدار آن برگ، تصمیمی میشود که برای آن داده گرفته میشود.
الگوریتم SVM:
یکی از الگوریتم ها و روش های بسیار رایج در حوزه دسته بندی دادهها، الگوریتم SVM یا ماشین بردار پشتیبان است. بردارهای پشتیبان به زبان ساده، مجموعه ای از نقاط در فضای n بعدی داده ها هستند که مرز دسته ها را مشخص میکنند. هدف آن هم یافتن بهترین مرز در بین داده هاست.
الگوریتم KNN:
«k-نزدیکترین همسایگی» (k-Nearest Neighbors) یک روش غیر پارامتریک در دادهکاوی، یادگیری ماشین و تشخیص الگو است.
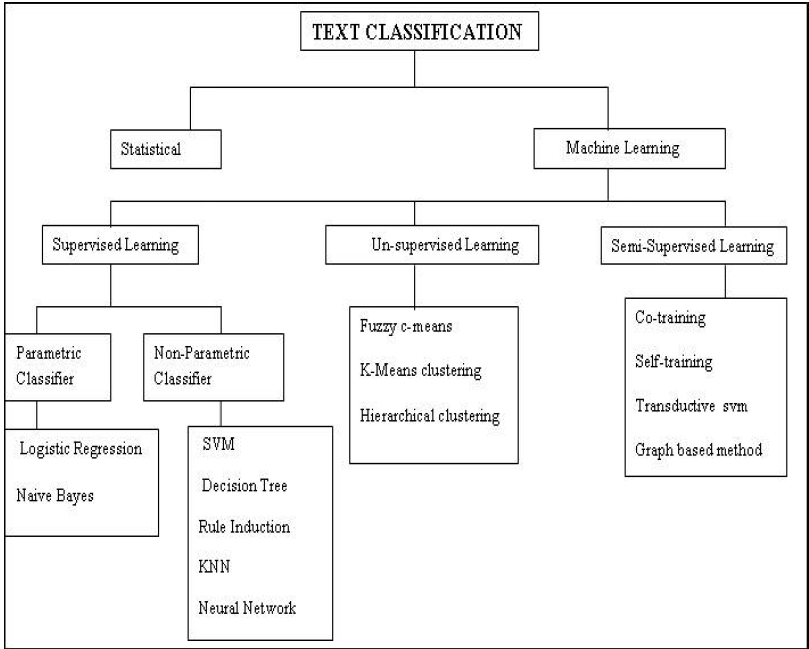
در شکل زیر تمامی روشهای مورد استفاده برای دستهبندی متون جمعبندی شدهاند که به برخی از آنها اشاره شد
۳. راه حل ارائه شده
۳.۱. روش Naïve Bayes:
۳.۱.۱. مراحل آماده سازی داده:
جمعآوری داده
دیتاست مورد استفاده از اخبار BBC شامل تعدادی فایل متنی از موضوعات ورزشی و سیاسی بدست آمد.
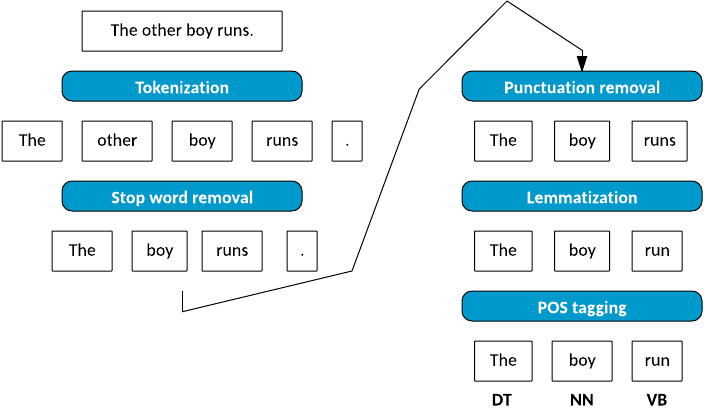
پیش از آغاز کار با دادهها، میبایست عملیات پیش پردازش متن انجام شود. این کار باعث میشود تا دادههای ما در قالبهای مناسب قرار گیرند و دادههای اضافی کمتر شوند یا از بین روند (مثلاً میتوان غلط املایی را تشخیص داده و آن را تصحیح کنیم تا در پردازش آن متن، ما را دچار اشتباه نکند.). این کار باعث میشود تا کلمات خاص کمتری در مراحل بعد مورد پردازش قرار گیرند که سرعت و دقت پردازش را بالا میبرد.
عملیات پیش پردازش متن طی مراحل زیر پیادهسازی شد:
حذف حروف بزرگ
در این مرحله تمامی کلمات به lower case تبدیل شدند تا در تشخیص کلمات یکسان دچار خطا نشویم. بعنوان مثال دو کلمه مقابل یکسان در نظر گرفته شوند : People و people .
حذف ارقام
در این مرحله تمامی ارقام که تاثیری در روند دستهبندی ندارند حذف شدند.
حذف stop word ها
بعضی کلمات بی معنی و اضافی مانند حروف ربط و حروف اضافه ( a, and, the, this, ... ) از متن حذف شدند.
نشانهگذاری - Tokenizing
تشخیص صحیح تمام کلمات درون یک جمله. به عنوان مثال جملهی "The latest international news from Sky" باید به صورت زیر در بیاید:
['latest', 'international', 'news', 'from', 'Sky'']
ریشهیابی - Stemming
یافتن ریشهی کلمه میتواند ما را به بخش اصلی یک کلمه برساند و دایرهی تصمیمگیری ما برای یک کلمه را کوچکتر و دقیقتر کند. به عنوان مثال با حذف "s" جمع از پایان کلمات و یا حذف "ing" میتوان کلمات را به ریشهی اصلی تبدیل کرد.
ریشهیابی - Lemmatization
فرآیند گروهبندی کلمات یکسان با شکلهای متفاوت است تا بتوان آنها را به عنوان یک آیتم مورد بررسی قرار داد.
۳.۱.۲. مرحله پردازش داده
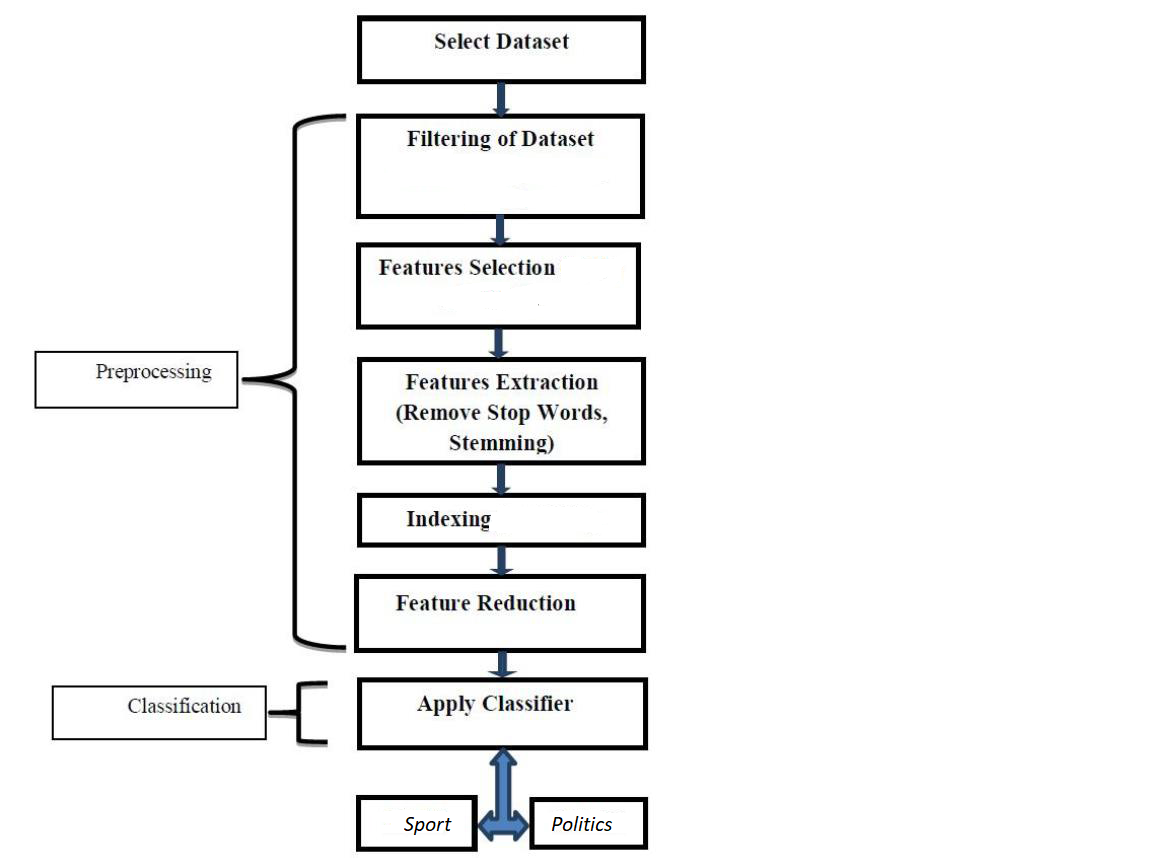
در این روش به این صورت عمل میکنیم که داده تمرینی را در اختیار الگوریتم قرار میدهیم تا فرآیند یادگیری انجام شود. بعد از این مرحله وارد فاز آزمودن میشویم و با دیتای جدید که 10% از دیتاست کلی ما را تشکیل میدهد، عملکرد الگوریتم را بررسی میکنیم.
برای پیادهسازی الگوریتم Naïve Bayes ابتدا تعداد تکرار تمامی کلمات را ذخیره کرده و احتمال هر کلمه را در دسته مربوطه محاسبه میکنیم. این اطلاعات را در یک ساختار داده مانند دیکشنری نگهداری میکنیم.
در فاز آزمودن، احتمال هر جمله را از ضرب احتمال تک تک کلمات آن جمله در دو کلاس بدست میآوریم و در نهایت جمله را به کلاسی با احتمال بیشتر نسبت میدهیم.
احتمال هر کلمه برای وجود در هر کلاس را با قاعده بیز بصورت زیر محاسبه میکنیم.

بطور کلی فلوچارت این روش را میتوان بصورت زیر نشان داد:
۳.۱.۳. مرحله ارزیابی
در این مرحله به بررسی عملکرد الگوریتم و ارائه روشهایی برای بهبود الگوریتم پرداختیم.
برای ارزیابی معیارهای precision و recall و F1 که از معیارهای رایج در ارزیابی مسائل دسته بندی هستند استفاده کردیم.
معیار precision : از بین مواردی که مدل به عنوان درست حدس زده است چه کسری واقعا درست بوده است.(tp/ tp+ fp )
معیار recall:از بین موارد واقعا درست، مدل چه کسری از آنها را پیدا کرده است. ( tp / tp + fn )
معیار F1: تعادل متقارن بین recall و precision.
نتایج بدست آمده در نمودارهای زیر مشخص شدهاند.
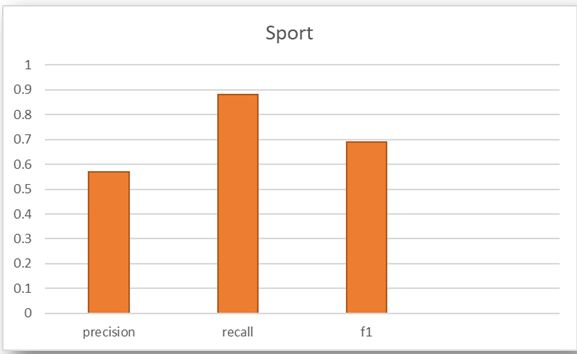
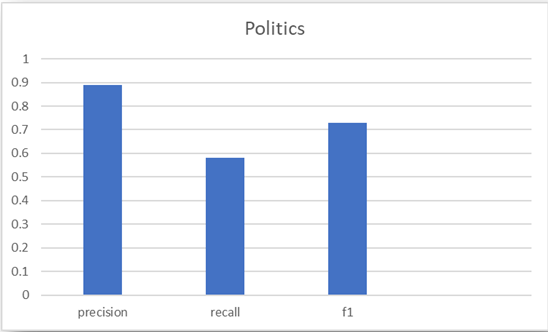
۳.۲. روش MLP:
در این روش یک شبکه عصبی چند لایه با تعدادی لایه مخفی برای حل مسئله در نظر گرفتیم.
دیتاست مورد استفاده در این روش اخبار رویترز و موجود در ماژول keras است.
در این روش نیز مشابه روش قبل داده را به دو دسته دادههای مرحله یادگیری و مرحله آزمودن تقسیم کردیم. فاز یادگیری را با دادههای یادگیری انجام داده و با دادههای آزمودن عملکرد مدل را بررسی کردیم.
لایه ورودی
در این لایه متن داده بعد از پردازش اولیه بصورت رقم در ماتریسی قرار داده میشود و این ارقام به لایه ورودی شبکه داده میشوند. وزن هر اتصال طی مرحله یادگیری مشخص میشود تا در نهایت خروجی را مشخص کند.
لایه مخفی
تعداد لایههای مخفی شبکه معمولا میانگینی از لایههای ورودی و خروجی شبکه است. با آزمایش روی تعداد لایههای مختلف بهترین نتیجه برای 256 بدست آمد.
لازم به ذکر است که تعداد لایههای بیشتر گرچه دقت بالاتری ممکن است بدهند ولی باعث overfitting میشود.
لایه خروجی
به تعداد دستههای نهایی node دارد که مشخص میکند ورودی به کدام دسته تعلق دارد.
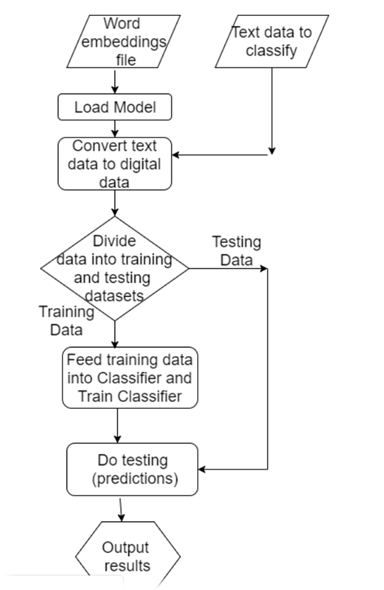
بطور خلاصه فلوچارت این روش را میتوان به شکل زیر نشان داد.
نکته: همانطور که در فلوچارت زیر مشخص است، در این روش بر خلاف روش قبل نیاز به مرحلهی تبدیل متن با فرمت ascii به رقم باینری داریم تا این ارقام در وزنهای شبکه ضرب شوند و خروجی را مشخص کنند.
ارزیابی نتایج
برای ارزیابی روش استفاده شده accuracy را همانند معیارهای گفته شده در روش قبل محاسبه کردیم و در این الگوریتم مدل با دقتی حدود 0.8 دادههای تست را پیشبینی کرد.
۴. آزمایشها
ابزارها
برای تحلیل دادههای نوشتاری و کلاسهبندی آنها در زبان پایتون ماژولهایی وجود دارد که در ذیل اشارهی مختصری به آنها شده است. در پیادهسازی انجام شده از ماژول NLTK استفاده شده است. اما برای پیادهسازیهای مختلف دیگر که بعضا میتوانند دقیقتر هم عملکنند میتوان از ماژولهای دیگر مانند ماژول Scikit-Learn استفاده کرد.
ماژول NumPy: یک ابزار پایهای برای محاسبات ریاضیاتی در زبان پایتون. در اکثر ابزارهای دیگر از این ماژول ارثبری شده است.
ماژول Natural Language Toolkit: یا همان NLTK که معروفترین و قدرتمندترین ابزار موجود برای پردازش متن است. این ماژول درون خود از ماژول NumPy ارثبری میکند. (در اینجا برای کلاسهبندی و کارهای پیش پردازش مورد استفاده قرار میگیرد.)
ماژول keras: یک ماژول معروف و قدرتمند برای پیادهسازی شبکههای عصبی است. برای پیادهسازی روش MLP از این ماژول استفاده شده است.
ماژول word cloud: این ماژول تصویری از کلمات پرتکرار یک متن را در اختیار ما میگذارد که با تحلیل این تصاویر میتوان به موضوع متن پی برد. به عنوان مثال در تصاویر زیر تکرار واژههایی نظیر game و team نشان دهنده ماهیت ورزشی خبر و کلماتی مانند government و people حاکی از ماهیت سیاسی خبر هستند.

تصویر 8: word cloud مربوط به اخبار سیاسی

تصویر 9:word cloud مربوط به اخبار ورزشی بهبود نتایج و افزایش دقت ردهبند:
برای بهبود نتایج میتوان در مرحله پیش پردازش قوی تر عمل کرد. بعنوان مثال مراحلی مانند حذف کلمات پرتکرار و بیهوده مثل فعلهایی مانند (said, go, come, ...) و یا اصلاح املای کلمات با غلط املایی میتوانند دقت مدل را بهبود دهند.
۵. تحلیل و تفسیر نتایج
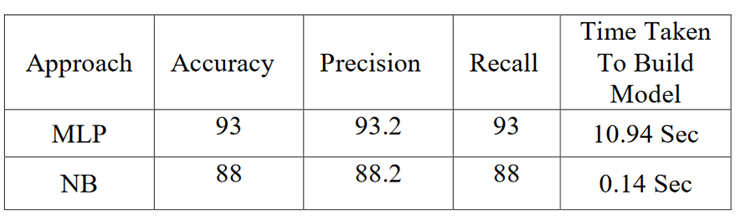
همانطور که در قسمتهای قبل نتایج را مشاهده کردید، با مقایسه نتایج حاصل از ارزیابی دو روش پیادهسازی شده، به این نتیجه دست یافتیم که MLP همواره با دقت بیشتری نسبت به Naïve Bayes کلاس بندی را پیشبینی میکند. تفاوت دیگر در مدت زمان یادگیری این دو روش است. Naïve Bayes بسیار سریع تر از روش MLP مرحله یادگیری و کلاس بندی را انجام میدهد.
جدول زیر حاصل مقایسه معیارهای ارزیابی در زمینهی دقت و سرعت روشها رسم شده است. [3]
۶. کارهای آینده
ما میتوانیم برای گسترش و تعمیم الگوریتم تعداد کلاس هایمان را بیشتر کنیم در واقع موضوعات را گسترش دهیم و علاوه بر اخبار سیاسی و ورزشی موضوعاتی مانند تکنولوژی ، پزشکی ، اقتصادی و .. را به آن اضافه کنیم. همچنین همانطور که گفته شد از فیلترهای spell check و یا حذف کلمات بی معنی در مرحلهی پاکسازی متن استفاده کنیم. با این روش دقت و سرعت برنامه را افزایش خواهیم داد.
فایلهای پیاده سازی
برای دسترسی به فایلهای پیادهسازی پروژه به گیت هاب مراجعه کنید.
۷. منابع و ارجاعات
[1] Y. Yang and X. Liu, "A Re-examination of Text Categorization Methods", Proceedings of the 22nd annual international ACM SIGIR conference on research and development in information retrieval, pp. 42-49, .1999
[2]S.A. Wood and T.D. Gedeon, "A Hybrid Neural Network for Automated Classification" Proceedings of the 6th Australasian Document Computing Symposium, .2001
A Comparative Study between Naïve Bayes and Neural Network (MLP) Classifier for Spam Email Detection[3]