#1.مقدمه
کپچا[^1] در تعریفی ساده سامانهٔ امنیتی و روند ارزیابی است، که بااستفاده از ازمون تورینگ برای جلوگیری از برخی حملههای خرابکارانهٔ رباتهای اینترنتی [^2]بهکار میرود. این روند میتواند مشخص کند که مراجعه کننده به یک وبگاه و یا سایر خدمات آنلاین انسان است یا کامپیوتر.
لازم به ذکر است که کپچا را گاهی «معکوس تست تورینگ» می نامند، چون تست تورینگ توسط انسان برگزار میشود و هدفش تشخیص ماشین است، اما کپچا توسط ماشین برگزار میشود و هدفش تشخیص انسان است.
1.1.**تاریخچه کپچا**
کپچا در سال ۲۰۰۰ و در دانشگاه Carneige Mellon توسط Luis von Ahn و همکارانش ساخته شد و برای اولین بار در سایت Yahoo مورد استفاده قرار گرفت[1].
یکی از شکل های معمول کپچا به صورت تصویر است. در این نوع کپچا معمولا حروف و اعدادی انگلیسی به شکلی کنار هم قرار میگیرند و کاربر باید این حروف و اعداد را تشخیص دهد. معمولا مسئولین این سایتها فکر میکنند که رباتها یا برنامههای کامپیوتری نمیتوانند پاسخ این سؤالات را بدهند.

<div style="direction:rtl">1.2.**کاربرد کپچا**</div>
کپچا کاربردهای زیادی در جهت افزایش امنیت دارد که در ادامه به مهمترین آنها اشاره خواهیم کرد:
<div style="direction:rtl">1.2.1.**جلوگیری از نظرات اسپم در سایت و وبلاگ**</div>
اکثر صاحبان وبلاگ یا سایت ها با نرم افزارهای اتوماتیک آنلاین که اقدام به انتشار نظرات اسپم میکنند آشنایی دارند که معمولا به هدف افزایش رنک و بهبود سئو سایت اسپمر بکار میرود. با استفاده از کپچا تنها انسان ها قادر به انتشار نظر در بخش وبلاگ سایت شما خواهند بود و به این ترتیب نیاز به عضویت در سایت یا وبلاگ شما برای جلوگیری از نظرات اسپم نیست.
1.2.2.**نقش کپچا در بخش عضویت سایت**
سایت های زیادی در دنیا خدمات رایگان ارائه میدهند که نیازمند عضویت و ساخت اکانت از طرف افراد هستند. مهمترین آنها سیستم های ایمیل یاهو و گوگل هستند. تا چند سال پیش و قبل از بکارگیری کپچا بزرگترین مشکل آنها ساخت تعداد زیادی اکانت توسط روبات های اینترنتی بود که میتوانستند در چند دقیقه صدها ایمیل بسازند. استفاده از سیستم کپچا این امکان را فراهم کرد که تنها انسان ها قادر به تکمیل فرم و ثبت نام نهایی باشند و امروزه به یک ضرورت در سیستم های رایگان تبدیل شده است.
<div style="direction:rtl">1.2.3. .**کپچا برای نظرسنجی آنلاین**</div>
در نوامبر ۱۹۹۹ یک نظر سنجی آنلاین در سایت Slashdot.org برای تعیین بهترین دانشگاه در زمینه علوم کامپیوتر و برنامه نویسی برگزار شد. با توجه به نبودن سیستمی مشابه کپچا در آن زمان با تشخیص و ثبت IP نظردهندگان از تکراری بودن افراد جلوگیری میکردند. با این وجود این سیستم قدرت کپچا را نداشته و دانشجویان دانشگاه Carneige Mellon برنامه ای برای ثبت نظر اتوماتیک ساخته و اجرا کردند، روز بعد این دانشگاه با اختلاف زیادی در رتبه اول ایستاد. بلافاصله دانشجویان دانشگاه MIT نیز برنامه مشابهی را راه اندازی کردند و این نظرسنجی در نهایت به جنگ روبات های اینترنتی تبدیل شد. در پایان رای گیری دانشگاه MIT با ۲۱۱۵۶ رای رتبه نخست را بدست آورد و Carneige Mellon با ۲۱۰۳۲ رای در رتبه دوم ایستاد، در حالیکه سایر دانشگاه ها هرکدام کمتر
از ۱۰۰۰ رای داشتند. امروزه برگزاری نظرسنجی عمومی در اینترنت بدون استفاده از کپچا کاری بیهوده و اشتباه است.
<div style="direction:rtl">1.2.4. **جلوگیری از هک پسورد**</div>
در گذشته و قبل از همه گیر شدن سیستم کپچا، یکی از روش های رایج برای هک کردن اکانت کاربران و دسترسی به اطلاعات ، آزمون و خطای کلمات عبور مختلف بوده است. در این روش هزاران کلمه از روی فرهنگ لغات برای یک نام کاربری مشخص امتحان میشد. امروزه با چند تلاش اشتباه در سیستم های ایمیل مانند یاهو یک کپچا به کاربر نشان داده میشود تا از این روش هک بخوبی جلوگیری شود.
<div style="direction:rtl">1.3. **هدف**</div>
بدین منظور کپچا آزمونهایی را تولید میکند که:
1. انسان بتواند در طول چند ثانیه به آن پاسخ دهد و دراین زمینه به مشکل برنخورد.
2. کامپیوترهای فعلی ، نباید توانایی پاسخ به چنین سوالاتی را داشته باشند.
در بسیاری از سایت ها و وبلاگ ها بکارگیری کپچا تاثیر بالایی بر کاهش نظرات اسپم و جلوگیری از هک دارد ولی در نقطه مقابل استفاده نادرست از کپچا و عدم رعایت اصول آن میتواند موجب کاهش ارتباط کاربران با سایت شما گردد. گاهی اوقات در صفحات اینترنتی با سوالات و تصاویری مواجه میشویم که تشخیص آنها حتی برای انسان بسیار دشوار و وقتگیر خواهد بود. در این شرایط کاربران صبر زیادی از خود نشان نداده و سایت شما را ترک میکنند
بدین منظور در این پروژه سعی بر این است با نوشتن افزونه برای مرورگر برخی از انواع کپچا را (بشکنیم).
#2.چکیده
در پروژه شکستن کپچادر ابتدا با استفاده از کتابخانه اپنسیوی و شبکههای عصبی چند روش متداول در پردازش تصویر را مختصرا توضیح داده و
در گزارشی دو روش شبکه های عصبی [^4]و تشخیص بردار فضایی در تصویر [^5] برای شکستن کپچا راجداگانه با زبان برنامه نویسی پایتون پیاده سازی کرده و با نوشتن افزونه ای برای مرورگر نتایج را از نظرزمان بندی و دقت بررسی میکنیم [2, 3, 7].
در این پروژه از [سامانه آموزش دانشگاه شریف](http://edu.sharif.edu) استفاده می کنیم .که صرفاشامل اعداد با رنگ های مختلف است و در اینده با گسترش پایگاه داده سعی در شکستن کپچا های مختلف را داریم .

#3.کارهای مرتبط
در قسمت کارهای مرتبط در ابتدا پروژه هایی مشابه کپچا با کاربردهای مختلف معرفی میشود و در قسمت دوم به معرفی چند روش برای پیاده سازی میپردازیم.
<div style="direction:rtl"> 3.1.** پروژه های مرتبط با کپچا **</div>
<div style="direction:rtl">3.1.1. **ReCAPTCHA**</div>
دانشگاه کارنگی ملون که تحقیقات زیادی در زمینه کپچا دارد، میخواست واژه کپچا را به نام خود به ثبت برساند که این اقدام مورد پذیرش واقع نشد، به همین دلیل
آنها از واژه یِ ریکپچا برای اقدامات خود استفاده نمودند.
یک سرویس رایگان است که بیشتر در زمینه کتاب ها و روزنامه های دیجیتال مورد استفاده قرار میگیرد. reCAPTCHA فرایند کاری خود را با ارسال تصاویری غیر قابل تشخیص توسط رایانه و برای شناسایی انسان انجام می دهد. جالب است بدانید که این کامپوننت از تصاویری که توسط
سیستم های OCR ، غیر قابل شناسایی تشخیص داده شده است بعنوان تصاویر کپچا استفاده می نماید.

<div style="direction:rtl">3.1.2. **کپچای صوتی[^3]**</div>
کپچای تصویری فقط برای افراد با بینایی کامل کاربرد دارد و افراد کم بینا یا نابینا قادر به پاسخگویی به ازمون تورینگ نیستند.
یکی از انواع جایگزین کپچاهای تصویری، مدل صوتی آن است. این مدل ، شامل صدای یکسری از حروف یا اعداد است. البته این حروف یا اعداد خیلی ساده بیان میشود و شما تنها نیاز دارید آنها را کپی کنید. البته مشکل اینجاست که ممکن است برنامه علاوه بر پخش خود صداها یکسری از صداهای پشت صحنه را هم برای شما ایجاد کند. هدف از این کار، ممانعت از تکمیل این تستها توسط برنامههای خودکار مانند اپلیکیشنهای تشخیص صدای رایانه است[4] .
کپچاهای صوتی نیز چندان ضد ضربه نیستند. در بهار سال 2008، گزارشهایی منتشر شدند که نشان می دادند هکرها شیوه ای را برای سیستم کپچاصوتی، شما باید یک کتابخانه از اصوات را ایجاد کنید که هر کاراکتر در بانک اطلاعاتی کپچا را مجدداً بیان می کنند. توجه داشته باشید که بر حسب میزان تحریف، ممکن است اصوات متعددی برای یک کاراکتر واحد وجود داشته باشد
شروع این برنامه با خواندن فایل های صوتی شروع میشود و سپس جمع آوری 1000 کپچا از انواع مختلف و استفاده از انها برای آموزش و تست.
اولین قدم برای شکستن این نوع کپتچا استفاده از چندین تکنولوژی machine learning برای اجرای ASR میباشد[5].
در این زمینه تکنیک های زیادی وجود دارد، 3روش که در این قسمت استفاده میشود:
1. MFCC [^7]
<div style="direction:rtl">1.MFCC [^7]</div>
<div style="direction:rtl">2. PLP [^8]
</div>
<div style="direction:rtl">3. RAS TA-PLP [^9]
</div>
پس از طبقه بندی هر صدا، Spammer از نرم افزارهای مختلف تشخیص گفتار برای تفسیر CAPTCHAصوتی استفاده می کند.
موفقیت در این زمینه به دو بخش تقسیم میشود:
1. تقسیم بندی[^10]:
در ابتدا باید audio را به بخش هایی تقسیم کنیم و پس از ان باید انها را بر اساس سروصدا و یا کلمه طبقه بندی کنیم.(کلمات در این قسمت شامل حرف یا عدد است.
2. شناخت[^11]:
برای recognize کردن حروف و اعداد نیز از الگوریتم های adaBoost, support vector machine, K-nearest neighbor استفاده میشود.
<div style="direction:rtl">3.1.3. **Are you A Human**</div>
سرویس جالبی است که کاربر برای تکمیل فرم باید یک بازی تعاملی را انجام دهد. این بازی با کلیک کردن و کشیدن اشیا انجام میشود و مطمئنا از تشخیص حروف کپتچا جالب تر خواهد بود.

<div style="direction:rtl">3.1.4 .**کپچا به زبان فارسی[^6] **</div>
کپچافا اساسا مبتنی بر روش ارائه شده در کپچا میباشد، لیکن متناسب با محیط کاربر فارسی زبان طراحی شده و از همین روی است که آنرا کپچافا یا همان کپچای فارسی نام نهاده ایم. کپچا ها شامل لغات یا عبارات لاتین میباشند در حالیکه کپچافا ها از لغات و عبارات فارسی استفاده میکنند.
چرا کپچافا ؟
به دو دلیل عمده، بر این باوریم که استفاده از کپچافا برای شما سودمند است. اول، تکنولوژی بازشناسی خودکار متون برای زبان لاتین بسیار پیشرفته است به صورتی که هم اکنون رباتهای اینترنتی ای وجود دارند که بر اساس الگوریتمهای پردازش تصویر و شناسایی الگو میتوانند بسیاری از کپچاها را تشخیص دهند. نمونههایی از عملکرد این رباتها را میتوان روزانه در بخش نظرات سایتهای پر مخاطب و قدرتمندی همچون یاهو نیز مشاهده کرد. این در حالیست که علاوه بر ساختار زبان و لغات فارسی که امکان ایجاد کپچافا های پیچیده تری را نسبت به زبان لاتین ایجاد میکند، تکنولوژی بازشناسی خودکار متون نیز در بستر زبان فارسی بسیار ضعیف و نوپا می باشد. دوم، این سرویس کاملا رایگان بوده و شما میتوانید بدون اینکه هیچ هزینه ای پرداخت نمایید سایت، وبلاگ و یا پورتال خود را ایمن سازید.
تیم کپچافا معتقد است که با توجه به ساختار زبان فارسی، حروف برای اینکه یک لغت را تشکیل دهند باید به همدیگر چسبیده باشند و این پتانسیل منجر به تاثیر گذاری تغییر شکل حروف به روی حروف همسایه میشود. ویژگی که اجازه میدهد تا با ایجاد میزان اندک کجی ها، کپچافا همچنان در مقابل OCRها از امنیتی بسیار بالایی برخوردار باشد. توجه به این نکته میتواند ارزشمند باشد که در زبان لاتین حروف از همدیگر جدا نوشته میشوند و این واقعیت بستری است که در آن با استفاده از الگوریتمهای جدا سازی اشیا در تصویر میتوان به راحتی حروف را از هم جدا کرده و سپس به وسیله الگوریتمهایی مانند محاسبه حداقل تغییر بر اساس شکل اشیا آنها را تشخیص داد. همانطور که اشاره شد، از آنجایی کهدر زبان فارسی حروف به یکدیگر متصل هستند، تشخیص مرز میان آنها توسط ابزارهای OCR، مخصوصا در حالتی که تغییر شکل رخ داده باشد کار بسیار بسیار دشواری است.در واقع خواندن کپچافا برای کاربران ایرانی ساده و برای ابزارهای ضدامنیتی بسیار مشکل است. ، در حال حاضر این محصول میتواند به وب سایتهایی که با زبان پی اچ پی، هاست شدهاند خدمت بدهد.

<div style="direction:rtl">3.1.5. **NUCaptcha**</div>
نسل بعدی کد امنیتی به طور خاصی طراحی شده است که کپتچا به طورمتحرک است و احتمال خطای کامپیوترها بیشترشده است و از طرفی امنیت تصویر بیشترشده است.Nucaptcha با استفاده از شاخص های اندازه گیری برای شناسایی فعالیت های مشکوک ساخته شده است، این نوع کپتچا یا خیلی اسان هستند که با استفاده از ocr قابل حل میباشند یا به شدت سخت بوده و حتی انسان ها هم قادر به حل ان نمیباشند. این نوع کپتچا برای موارد با امنیت بالا طراحی شده است.
<div style="direction:rtl">3.2. **روش های موجود**</div>
شکستن کپچا از چندمرحله اساسی تشکیل شده است که برای هر مرحله روش های مختلفی وجود دارد
:
3.2.1. مرحله اول:
در این مرحله عکس ابتدا باید به عنوان ورودی داده شود.در زبان پایتون بهترین کار پارس کردن صفحه وب با استفاده از urlib2 .
******************
مرحله دوم :
در این مرحله باید در عکس کپچای دریافتی
تمام نویزها ، خطوط اضافی باید برداشته شوند
برای انجام این عملیات که به smoothing معروف است یک فیلتر به تصویر اعمال میکنیم
رایج ترین نوع فیلتر ،خطی می باشد، که در آن مقدار پیکسل خروجی را (به عنوان مثال(g(I,j)) به عنوان مجموع وزنی از مقدار پیکسل ورودی (به عنوان مثال تابع $$(f (i+ k، j+l)$$) تعیین می شود:

(h(k,lضرایب فیلتر را مشخص میکند و KERNEL نامیده میشود.
انواع فیلتر:
1. Homogeneous filter
2. Gaussian Filter
3. Median filter
4. Bilateral Filter
******************
مرحله سوم :
وعکس باید به باینری تبدیل شود
برای تکه تکه کردن عکس به حروف یا اعداد در این مرحله روش
انواع Thresholding:
1. Threshold Binary
2. Threshold Binary, Inverted
3. Threshold to Zero
4. Threshold to Zero, Inverted
5. Global Thresholding
6. Adaptive Gaussian Thresholding
7. Adaptive Mean Thresholding
با ازمایش این 7 روش، بهترین راه برای کپچا استفاده از TRUNC ,TOZERO و Adaptive Gaussian Thresholding میباشد.


مرحله چهارم:
در این مرحله از سمت چپ شروع به پردازش میکندو به اصطلاح عکس را تکه تکه[^10] میکند.
در این مرحله میتوان ازopencv یا cvblubاستفاده کرد
با توجه به اینکه در کپچا نویز زیادی وجود دارد ودر هنگام تکه تکه کردن عکس مشکلاتی نظیر شامل نصف شدن یک حرف یا نمایش دوحرف در کنار هم میباشد
از opencv که دارای دقت بیشتری است استفاده میکنیم.
مرحله پنجم:
در این مرحله عکس پردازش شده و قطعه قطعه شده مرحله قبل
به بردار تبدیل شده و شبکه عصبی این بردار را با تصاویر دوره ی اموزشی تطابق داده
و از طریق الگوریتم های تقریب و درون یابی مشخص میشود که به کدام تصویر از مجموعه تصاویر زمان اموزش شبیه تر است
برای recognition روش های مختلف وجود دارد :
1. ABBYY OCR
2. Gocr
3. Ocrad
4. Tesseract OCR
در این قسمت با توجه به جدول زیر بهترین روش استفاده از tesseract میباشد(مقاله )

مرحله train :
در این مرحله ابتدا عکس هایی که برای آموزش سیستم هستند ، پردازش شده و به شبکه عصبی داده میشوند
با استفاده از الگوریتم های مختلف داده ها اموزش داده می شوند.
1. svm[^12]:
در الگوریتم SVM از (Histogram of Oriented Gradients (HOG به عنوان بردار مشخصات استفاده می شود.
2. Knn[^13]:
الگوریتمknn ما مستقیما از پیکسل ها به عنوان بردار مشخصات استفاده می شود.
در این مرحله اگر پایگاه داده کامل باشد، خطا کاهش میابد.
#4.روش پیشنهادی3.2.2.مرحله دوم :
در این مرحله باید عکس کپچای دریافتی از تمام نویزها و خطوط اضافی خالی شود. برای انجام این عملیات که به smoothing معروف است یک فیلتر به تصویر اعمال میکنیم.
رایج ترین نوع فیلتر ،خطی می باشد، که در آن مقدار پیکسل خروجی را (به عنوان مثال(g(I,j)) به عنوان مجموع وزنی برای مقدار پیکسل ورودی (به عنوان مثال تابع (f (i+ k، j+l)) تعیین می شود:

<div style="direction:rtl">(h(k,lضرایب فیلتر را مشخص میکند و KERNEL نامیده میشود.</div>
انواع فیلتر:
<div style="direction:rtl">1.Homogeneous filter</div>
<div style="direction:rtl">2.Gaussian Filter</div>
<div style="direction:rtl">3.Median filter</div>
<div style="direction:rtl">4.Bilateral Filter</div>
******************
3.2.3.مرحله سوم :
در این مرحله عکس باید به عکس باینری تبدیل شود. این مرحله با استفاده از thresholding انجام میشود.
انواع Thresholding:
<div style="direction:rtl">1.Threshold Binary</div>
<div style="direction:rtl">2.Threshold Binary, Inverted</div>
<div style="direction:rtl">3.Threshold to Zero</div>
<div style="direction:rtl">4.Threshold to Zero, Inverted</div>
<div style="direction:rtl">5.Global Thresholding</div>
<div style="direction:rtl">6.Adaptive Gaussian Thresholdin</div>
<div style="direction:rtl">7.Adaptive Mean Thresholding</div>
<br/>
با ازمایش این 7 روش، بهترین راه برای کپچا استفاده از TRUNC ,TOZERO و Adaptive Gaussian Thresholding میباشد.


******************
3.2.4.مرحله چهارم:
در این مرحله از سمت چپ شروع به پردازش میکندو به اصطلاح عکس را تکه تکه میکند.
در این مرحله میتوان ازopencv یا cvblubاستفاده کرد ولی با توجه به اینکه در کپچا نویز زیادی وجود دارد ودر هنگام تکه تکه کردن عکس با مشکلاتی نظیر نصف شدن یک حرف و یا نمایش دوحرف در کنار هم مواجه میشویم، بهتراست از از opencv که دارای دقت بیشتری است استفاده کنیم.
******************
3.2.5.مرحله پنجم:
در این مرحله عکس پردازش شده و قطعه قطعه شده مرحله قبل به بردار تبدیل شده و شبکه عصبی این بردار را با تصاویر دوره ی اموزشی تطابق میدهد
و از طریق الگوریتم های تقریب و درون یابی مشخص میشود که به کدام تصویر از مجموعه تصاویر زمان اموزش شبیه تر است
<br/>
برای recognition روش های مختلف وجود دارد :
<div style="direction:rtl">1.ABBYY OCR</div>
<div style="direction:rtl">2.GOCR</div>
<div style="direction:rtl">3.Ocrad</div>
<div style="direction:rtl">4.Tesseract OCR</div>
در این قسمت با توجه به جدول زیر بهترین روش استفاده از tesseract میباشد[11].

3.2.6. مرحله train :
در این مرحله ابتدا عکس هایی که برای آموزش سیستم تهیه شده اند را پردازش کرده و به شبکه عصبی میدهیم و سپس با استفاده از الگوریتم های مختلف داده ها ، آموزش داده می شوند.
<div style="direction:rtl">1.svm[^12]: </div>
در الگوریتم SVM از (Histogram of Oriented Gradients (HOG به عنوان بردار مشخصات استفاده می شود.
<div style="direction:rtl">2.Knn[^13]:</div>
الگوریتمknn مستقیما از پیکسل ها به عنوان بردار مشخصات استفاده می شود.در این مرحله اگر پایگاه داده کامل باشد، خطا کاهش میابد.
#4.روش پیشنهادی:
<div style="direction:rtl">4.1.**روش پیشنهادی1:**</div>
در این قسمت به شرح روش پیشنهادی بر روی عکس زیر میپردازیم:

چگونگی شناسایی متن در تصاویر :
روش های زیادی برای شناسایی وجود دارد که عبارتند از: استفاده از فیلترهای تصویری، فیلترهای تشخیص لبه ، تشخیص الگو، استخراج رنگ و غیره.
چون کپچا دارای حروف کج است پس از هیستگرام رنگ های این عکس استفاده میکنیم
الگوریتم که از ان استفاده میکینم به الگوریتم multivalued image decomposition معروف است
اساسا به معنای این است که ما در ابتدا یک هیستوگرام از رنگ هارا در تصویر میسازیم و بر اساس انها گروه بندی میکنیم .
در این مثال پس زمینه ( سفید ) ،خطوط سر و صدا ( خاکستری ) ، متن ( قرمز).است
در ابتدا بعد از بازکردن عکس ان را بهGIF تبدیل کرده (زیرا این فرمت با 255 رنگ مراحل کار را اسانتر میکند)
در زیر هیستوگرام (histogram) رنگ های عکس را چاپ میشود:

این تصویر نشان دهنده تعداد پیکسل هر یک از 255 رنگ در تصویر است . شما می توانید ببینید که رنگ سفید بیشترین تعداد پیکسل را دارد و رنگ قرمز که نشان دهنده متن تصویر است در حدود 200 است
میتوانیم لیستی از 10 رنگ متداول در تصویر ایجاد کنیم، که ستون اول شماره رنگ است و ستون دوم تعداد پیکسل در تصویر رنگ است.

مطابق انتظار سفید بیشترین رنگ است. و بعد خاکستری و پس از آن قرمز است.
سپس اقدام به ایجاد تصویر باینری(تنها 2 رنگ ) میکنیم که رنگ متن به عنوان سیاه و هر چیز دیگری به عنوان رنگ سفید ایجاد میشود.که نتایجی مانند نمونه به دست می اوریم.
| ورودی | خروجی |
|:-----------------------------------------------|:-----------------------------------------------------:|
|  |  |
تا این مرحله با موفقیت متن را از پس زمینه ها جدا کردیم
هدف در مرحله بعدی شناسایی اطلاعات متنی در تصویر است
با الگوریتم زیر شما مجموعه ای از حروفی دارید که با مقایسه مرزهای هر یک از مجموعه ها، در مقایسه با مجموعه های دیگر برخی از حروف که در کنار یکدیگر هستند را شناسایی میکنید. ولی چون کپچاها دارای حروف کج و مورب هستند،استفاده از هیستگرام رنگ ها ایده بهتری میباشد.
در این مرحله از الگوریتمی که به الگوریتم multivalued image decomposition معروف است، استفاده میکنیم.
اساس کار این الگوریتم به این صورت است که در ابتدا هیستوگرامی از رنگ ها، در تصویر میسازیم و سپس بر اساس آنها گروه بندی میکنیم. در این مثال به 3 گروه، پس زمینه ( سفید ) ،خطوط سر و صدا ( خاکستری ) ، متن ( قرمز) تقسیم میشود.
پس از آن عکس را بازکرده وبه GIF تبدیل میکنیم. (زیرا این فرمت با 255 رنگ مراحل کار را اسانتر میکند) و بعد هیستوگرام (histogram) رنگ های عکس چاپ میشود:

این تصویر نشان دهنده تعداد پیکسل هر یک از 255 رنگ در تصویر است. شما می توانید ببینید که رنگ سفید بیشترین تعداد پیکسل را دارد و رنگ قرمز که نشان دهنده متن تصویر است، تقریبا در حدود 200 است.
میتوانیم لیستی از 10 رنگ متداول در تصویر ایجاد کنیم، که ستون اول شماره رنگ است و ستون دوم تعداد پیکسل در تصویر رنگ است.

مطابق انتظار سفید بیشترین رنگ است. و بعد خاکستری و پس از آن قرمز است. سپس اقدام به ایجاد تصویر باینری(تنها 2 رنگ ) میکنیم، که رنگ متن به عنوان سیاه و هر چیز دیگری به رنگ سفیدتبدیل میشود.
نتایج زیر حاصل میشود:
| ورودی | خروجی |
|:-----------------------------------------------|:-----------------------------------------------------:|
|  |  |
تا این مرحله با موفقیت متن را از پس زمینه ها جدا کردیم، هدف در مرحله بعدی شناسایی اطلاعات متنی در تصویر است.
با الگوریتم زیر شما مجموعه ای از حروف داریدکه با مقایسه مرزهای هر یک از مجموعه ها، در مقایسه با مجموعه های دیگر حروفی که در کنار یکدیگر هستند را شناسایی میکند و بعد با برش افقی از تصویر مشخص میشود که هر تصویر از کجا شروع میشود و تا کجا ادامه دارد، در نهایت با تبدیل آنها به تصاویر جداگانه، ما مجموعه از حروف و اعداد برای شناخت داریم .
for each binary image:
for each pixel in the binary image:
if the pixel is on:
if any pixel we have seen before is next to it:
add to the same set
else:
add to a new set
همچنین با برش افقی از تصویر ما می توانیم مشخص کنیم که هر تصویر از کجا شروع میشود و تا کجا ادامه دارد و پس از استخراج آنها به تصاویر جداگانه، ما مجموعه از حروف و اعداد برای شناخت داریم .
خروجی این مثال در این مرحله :
[(6, 14), (15, 25), (27, 35), (37, 46), (48, 56), (57, 67)]
این خروجی نشان دهنده نقطه اغازی و پایانی هر حرف یا عدد میباشد.
این روش از چند نظر انتخاب بهتری نسبت به روش های دیگر است:
1. نیاز به اموزش گسترده ندارند .
2. نمیتوانندovertrained شوند.
3. شما میتوانید اطلاعات نادرست را اضافه یا حذف کنید و نتایج ان را مشاهده کنید.
4. به راحتی قابل درک هستند.
5. نتایج به صورت درجه بندی ارائه میدهند پس میزان شباهت مشخص میشود..
6. وقتی توانایی تشخیص بعضی از کاراکتر ها را ندارد، به اسانی خودتان میتوانید ان را اضافه کرده حتی اگر قبلا شبیه ان را ندیده باشد
سپس بردار فضایی برای تشخیص تصاویر را میسازیم[10].
در این کد دو ورودی از جنس دیکشنری پایتون میگیرد که با شماره 0 و 1 ارتباط انها را مشخص میکند، 0 به معنی عدم ارتباط و 1 به معنی یکسان بودن انهاست.
#5.آزمایشها
خوشبختانه بسیاری از کپچا ضعیف هستند و با تمیز کردن ، حذف خطوط درهم و برهم و به کمک OCR های ساده حل شده اند
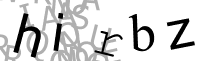
با گذشتن از مرحله اول
اکنون نتایج حاصل را برای استخراج متن به OCR داده میشود
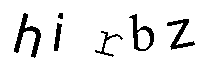
در اینجا از 3 ابزار OCR برای مقایسه استفاده شده :
Tesseract :hirbz
Gocr:_i_bz
Ocrad:hi_bL
چند نمونه دیگر:
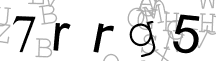
Tesseract :7rrq5
Gocr :7rr95
Ocrad :7rrgs
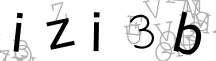
Tesseract :izi3b
Gocr :izi3b
Ocrad :iLi3b
در این ازمایش گرفتن نتیجه 100% ملاک نیست زیرا مردم واقعی هم گاهی اشتباه میکنند
در این ازمایش ، Tesseract فقط g با q اشتباه کرد و Gocr به جای g ,عدد 9 را چاپ کرده بود که قابل درک بود
ولی Ocrad هیچ جواب درستی نداده است
6. وقتی توانایی تشخیص بعضی از کاراکتر ها را ندارد، به آسانی خودتان میتوانید آن را اضافه کرده حتی اگر قبلا شبیه آن را ندیده باشد.
در مرحله آخر بردار فضایی برای تشخیص تصاویر را میسازیم. در این کد دو ورودی از جنس دیکشنری پایتون میگیرد که با شماره 0 و 1 ارتباط انها را مشخص میکند، 0 به معنی عدم ارتباط و 1 به معنی یکسان بودن انهاست[10].
<div style="direction:rtl">4.2.**روش پیشنهادی2:** </div>
در روش دوم از توابع OPENCVاستفاده میکنیم، نحوه عملکرد این روش در مراحل زیر توضیح داده میشود:
این توابع توانایی تشخیص عکس با فرمت GIF را ندارند پس اگر از عکس با این فرمت استفاده شود باید با استفاده از خود توابع OpenCV یا به صورت دستی تبدیل فرمت کنیم.
در مرحله بعد با استفاده از gray , blur , thresh به باینری کردن عکسها، حذف نویزها و از بین بردن لکه های زاید میپردازیم.
>>> img = cv2.imread(image)
>>> out = np.zeros(img.shape, np.uint8)
>>> gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
>>> blur = cv2.GaussianBlur(gray,(5,5),0 )
>>> ret,thresh = cv2.threshold(blur,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
بعد از حذف نویز و استفاده از این توابع نوبت به تکه تکه کردن عکس ها میرسد، با بررسی و آزمایش عکس ها مختلف حدود طول و عرض مربع هایی شامل هر عکس معلوم میشود.
در این مرحله دو گزینه برای خط کشیدن بین حروف مطرح میشود.
<div style="direction:rtl">1. Straight Bounding Rectangle</div>
این روش با خطوط صاف بین حروف مشخص میشود.
>>> x,y,w,h = cv2.boundingRect(cnt)
>>> cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
<div style="direction:rtl">2. Rotated Rectangle</div>
دراین روش محدوده مستطیل با حداقل سطح کشیده میشود و برای حالتی که کمی چرخش در حروف باشد مناسب می باشد.
>>> rect = cv2.minAreaRect(cnt)
>>> box = cv2.boxPoints(rect)
>>> box = np.int0(box)
>>> cv2.drawContours(img,[box],0,(0,0,255),2)
در مرحله بعد با تبدیل عکس ها به بردار شروع میشود، بعد از آن باید با استفاده از شبکه عصبی، تصویرکپچا را با تصاویری که آموزش داده شده اند مقایسه کرده و با الگوریتم های درونیابی، تقریب و تصمیم مشخص کند که به کدام نزدیک تر است.
برای آموزش شبکه عصبی بهترین راه ها استفاده از K-NN و SVM است که در این روش پیشنهادی از K-NN استفاده میکنیم، زیرا همان طور که گفته شده، در این روش مستقیما از پیکسل ها به عنوان بردار مشخصات استفاده می شود.
پس از آموزش شبکه عصبی دو فایل samples , responses ایجاد میشوند که اولی مشخص کننده بردارهای جواب متناظر با داده است و دومی نمایش دهنده بردارهای داده های جمع اوری شده می باشد.
>>> model = cv2.KNearest()
>>> model.train(samples,responses)
همانند روش پیشنهادی قبل وابستگی حروف کپچا را با داده های اموزش دیده مقایسه میکنیم .
#5.آزمایشها
خوشبختانه بسیاری از کپچا ضعیف هستند و با تمیز کردن ، حذف خطوط درهم و برهم و به کمک OCR های ساده حل شده اند.

با گذشتن از مرحله اول :

اکنون نتایج حاصل را برای استخراج متن به OCR داده میشود
در اینجا از 3 ابزار OCR برای مقایسه استفاده شده :
Tesseract :hirbz
Gocr:_i_bz
Ocrad:hi_bL
چند نمونه دیگر:

Tesseract :7rrq5
Gocr :7rr95
Ocrad :7rrgs

Tesseract :izi3b
Gocr :izi3b
Ocrad :iLi3b
در این ازمایش گرفتن نتیجه 100% ملاک نیست زیرا مردم واقعی هم گاهی اشتباه میکنند.
در این ازمایش ، Tesseract فقط g با q اشتباه کرد و Gocr به جای g ,عدد 9 را چاپ کرده بود که قابل درک بود.
ولی Ocrad هیچ جواب درستی نداده است.
******************
دراین فاز پروژه بر روی عکس های مختلف ازمایشاتی انجام داده که نتایج ان در زیر اماده است.این نتایج بر اساس جدا کردن عکس ها بر اساس هیستگرام انها میباشد.
برای عکس هایی با فرمت زیر قابلیت تشخیص 100% را دارد.
هجده](http://amirajorloo.com/static/Mahla/18.png)
******************
پایگاه داده اصلی شامل 56 عکس با فرمت و رنگ مشابه عکس بوده اند که نتایج زیر حاصل شده است.

Correct Guesses - 20.0
Wrong Guesses - 56.0
Percentage Correct - 35.7142857142
Percentage Wrong - 64.2857142857
در این ازمایش ها بیشتر خطا ها از 0 و o ناشی میشود و البته حروف h , k , c, p نیز به دلیل کمبود داده برای اموزش در بعضی موارد دچار خطا میشوند.که در فاز بعدی با افزایش corpus این مشکلات حل خواهند شد.
******************

قابلیت تشخیص این عکس و عکس های مشابه با این میزان سختی را ندارد و گاهی فقط بعضی از حروف را تشخیص میدهد.
*******************
عکس زیر کپچای دانشگاه شریف بوده است که به دلیل مرتب بودن و نداشتن خطوط زاید با تابع ocr ذکر شده نیز قابل حل میباشد.

#6.کد پروژه
+ [کد](https://github.com/mahlarht/breaking-captcha)
#7.اینده کپچا
[The Future of CAPTCHA ](http://mollom.com/blog/the-future-of-captchas)
#8.کارهای اینده
مرحله اول در شکستن کپچا به طور معمول بسیار اسان بوده و به طور خودکار انجام میشود
ولی در مرحله جداکردن حروف هنوزم انسان بهتر است زیرا اگر درهمریختگی های پس زمینه متشکل ازاشکال متشابه باحروف باشند، این اشکال وحروف توسط این درهم و برهمی متصل شده یا گاهی به اشتباه در هر تصویر 2 حرف تقسیم بندی می شود.
از این رو برای بهبود عملکرد باید بر این بخش تمرکز کربیست و یک](http://amirajorloo.com/static/Mahla/21.jpg )
#6.کد پروژه
+ [کد روش پیشنهادی اول](https://github.com/mahlarht/breaking-captcha)
+ [کد روش پیشنهادی دوم](https://github.com/mahlarht/final_breaking_captcha)
#7.آینده کپچا
<div style="direction:rtl">[The Future of CAPTCHA ](http://mollom.com/blog/the-future-of-captchas)</div>
#8.کارهای آینده
برای اینکه این کد برای اکثریت کپچاها استفاده شود، بهتر از روش دوم استفاده کنیم. زیرا در این روش با پایگاه داده کمتر و سریع تر از روش قبل به جواب می رسیم.
مرحله اول در شکستن کپچا به طور معمول بسیار اسان بوده و به طور خودکار انجام میشود
ولی در مرحله جداکردن حروف هنوزم انسان بهتر است زیرا اگر درهمریختگی های پس زمینه متشکل ازاشکال متشابه باحروف باشند، این اشکال وحروف به هم متصل شده یا گاهی به اشتباه در هر تصویر 2 حرف تقسیم بندی می شود.
از این رو برای بهبود عملکرد باید بر این بخش تمرکز کرد.
همچنین اگر در قسمت train از روش های جدیدتر و کدهای بهینه تر استفاده شود، اشتباهاتی نظیر تشابه حروف رخ نمیدهد.
در قسمت تکه تکه کردن گاهی برای بعضی حروفی مثل B و 8 باید دقت بیشتری شود در این صورت درصد عملکرد تا حد زیادی افزایش میابد.
#8.مراجع
1. Engber, Daniel (January 17, 2014). "Who Made That Captcha?". nytimes.com. NYT. Retrieved 17 January 2014
2. Basic Vector Space Search Engine Theory. LA 2600 – January 2, 2004 - presented by Vidiot.
3. Scott A. Clayton. Breaking the Cryptographp, January 2010.
4. Jeffrey P. Bigham and Anna C. Cavende .Department of Computer Science and Engineering DUB Group University of Washington.
5. Jennifer Tam, Jiri Simsa, David Huggins-Daines, Luis von Ahn, and Manuel Blum. Improving Audio CAPTCHAs , Computer Science Department, Carnegie Mellon University
5000 Forbes Avenue, Pittsburgh, PA 15213.
6. Jennifer Tam, Sean Hyde, Jiri Simsa, Luis Von Ahn. Computer Science Department ,Carnegie Mellon 5000 Forbes Ave, Pittsburgh 15217 University.
7. Jeff Yan, Ahmad Salah El Ahmad, Breaking Visual CAPTCHAs with Naïve Pattern Recognition Algorithms, School of Computing Science, Newcastle University, UK.
8. N. Suguna and Dr. K. Thanushkod, An Improved k-Nearest Neighbor Classification Using
Genetic Algorithm.
9. Albert Parra Pozo,SPANISH-ENGLISH TEXT RECOGNITION, TRANSLATION AND
INTERPRETATION OF MENUS AND DOCUMENTS.
10. C. Cortes and V. Vapnik. Support-vector networks.Machine
learning.
#9.پیوندهای مفید
+ [Nucaptcha](http://www.nucaptcha.com/)
+ [Vicarious](http://vimeo.com/77431982)
+ [video ](https://developers.google.com/recaptcha/)
11. Parra Pozo, Albert , Purdue University, May 2010. Spanish-English text recognition,
translation and interpretation of menus and documents. Major Professor: Edward
J. Delp
#9.پیوندهای مفید
<li style="direction:rtl">[Nucaptcha](http://www.nucaptcha.com/)</li>
<li style="direction:rtl">[Vicarious](http://vimeo.com/77431982)</li>
<li style="direction:rtl">[ Captcha video](https://developers.google.com/recaptcha)</li>
<li style="direction:rtl">[k-NN](http://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm)</li>
<li style="direction:rtl">[SVM](http://en.wikipedia.org/wiki/Support_vector_machine)</li>
<li style="direction:rtl">[Contour Features](http://docs.opencv.org/trunk/doc/py_tutorials/py_imgproc/py_contours/py_contour_features/py_contour_features.html)</li>
+ [کتابخانه اپنسیوی](http://opencv.org)
+ [اپنسیوی در پایتون](http://docs.opencv.org/trunk/doc/py_tutorials/py_tutorials.html)
+ [بینایی کامپیوتری در جاوا اسکریپت](http://inspirit.github.io/jsfeat/)
+ [شبکههای عصبی در جاوا اسکریپت](https://github.com/harthur/brain)
+ [شبکههای عصبی کانلوشنال در جاوا اسکریپت](https://github.com/karpathy/convnetjs)
+ [یک منبع خوب](http://stackoverflow.com/questions/9413216/simple-digit-recognition-ocr-in-opencv-python)
+ [پیادهسازی svm در جاوا اسکریپت](https://github.com/karpathy/svmjs)
+ [k-NN](http://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm)
+ [پایگاه داده نمونه](http://www.cs.cmu.edu/~guestrin/Class/10701/projects.html#image)
+ [آشنایی با سرویس ایرانی کپچافا](http://www.captchafa.net/)
+ [نمونه کد کپچافا](https://github.com/mhehm/captchafa)
[^1]: Completely Automated Public Turing test to tell Computers and Humans Apart
[^2]: Internet Bot
[^3]: Audio captcha
[^4]: Neural Network
[^5]: Vector Space Image Recognition
[^6]: captchafa
[^7]: mel-frequency cepstral coefficients
[^8]: perceptual linear prediction
[^9]: relative spectral transform-PLP
[^10]: Segmentation
[^11]: recognition
[^12]: Support Vector Machine
[^13]: K-Nearest Neighbour