وقتی برای یک محصول هزاران نظر توسط استفاده کنندهها قرار داده میشود، با چالش تحلیل این نظرات مواجهیم و اینکه بلاخره مخاطب چقدر از محصول ما راضی است. این مشکل وقتی شدیدتر میشود که مخاطب بیحوصله، نظرش را در چندین حرف *توییت* میکند و حالا ما باید بفهمیم که منظور مخاطب از این واژههای اختصاری و شکلکهای خندان یا عصبانی چیست. بگذریم از مواقعی که برای خود انسان هم فهمیدن لحن نظر، چندان آسان نیست، مثل این یکی:
> There's a thin line between likably old-fashioned and fuddy-duddy, and The Count of Monte Cristo ... never quite settles on either side.
ما در این پروژه میخواهیم که نظراتی را که پیرامون فیلمهای مختلف داده شده است را در پنج دسته لحنی: «منفی، نسبتا منفی، خنثی، نسبتا مثبت و مثبت» دستهبندی نماییم.
# مقدمه
شناسایی لحن که به آن نظرکاوی هم گفته می شود روشی است که در آن نظر، لحن، برآورد، گرایش و احساس مردم نسبت به موجودیت هایی مثل: محصولات ، خدمات، وقایع مورد مطالعه قرار می گیرد.
**کاربردهای شناسایی لحن نظرات:**
نظرات به دلیل تاثیر کلیدی که بر روی رفتار انسان میگذارد محور اصلی بیشتر فعالیت های بشر می باشد. هنگامی که ما میخواهیم یک تصمیمی بگیریم نیاز داریم که نظرهای دیگران را هم بدانیم. در دنیای واقعی شرکت ها و سازمان ها همواره به دنبال این هستند که نظرات مردم یا مشتریان را درباره ی محصولات و یا خدمات خود بدانند. مشتریان هم به دنبال این هستند که قبل از خرید یک محصول نظرات کاربرانی که قبلا از آن محصول استفاده کرده اند را بدانند و بر اساس آن اقدام به خرید یا عدم خرید آن محصول کنند. بدست آوردن نظرات مردم و مشتریان خود یک تجارت عظیم برای بازاریابی، روابط اجتماعی و حتی رقابت های انتخاباتی می باشد. در گذشته این اطلاعات از طریق برگه های نظرسنجی و یا آزمایش بر روی یک گروه خاص بدست می آمد ولی امروزه با گسترش روزافزون رسانه های اجتماعی (مثل بلاگ ها،توییتر و فیسبوک) افراد و سازمان ها از محتوای این رسانه ها برای تصمیم گیری استفاده می کنند و افراد دیگر لازم نیست که به نظر دوستان و آشنایان درباره یک محصول اکتفا کنند زیرا نظر و بحث های فراوانی درباره ی آن محصول در محیط وب وجود دارد. البته به خاطر فراوانی و تنوع سایت ها پیدا کردن و پایش سایت های مفید و چکیده گرفتن از اطلاعات موجود در آنها هنوز کاری دشوار و پیچیده می باشد، زیرا هر سایت به طور معمول دارای حجم زیادی از نظرات می باشد که برای انسان عادی استخراج و خلاصه سازی نظرات موجود سخت می باشد. در اینجاست که نیاز به یک سیستم شناسایی لحن نظرات احساس می شود. در سال های اخیر سیستم های تشخیص لحن نظرات در تقریبا تمام محدوده های ممکن از پیش بینی فروش محصولات و خدمات مشتریان گرفته تا پیش بینی وقایع اجتماعی و نتیجه انتخابات سیاسی پخش شده اند.
**تعاریف پایه:**
تعریف موجودیت e: یک موجودیت می تواند یک محصول، سرویس، موضوع، فرد، سازمان یا حتی یک واقعه باشد. و با دوتایی ( T , W ) نشان داده می شود که در آن T سلسه مراتبی از اجزا و زیر اجزای موجودیت و w مجموعه مشخصه های موجودیت e را نشان می دهند. همچنین هر یک از اجزا و زیر اجزا هم دارای یک مجموعه مشخصه می باشند. به طور مثال برای موجودیت دوربین مجموعه مشخصه W شامل: سایز ، وزن و کیفیت تصویر است و مجموعه اجزا T شامل لنز و باتری می باشد. برای راحتی کار از واژه ی جنبه (aspect) به جای دوتایی مجموعه اجزا و مشخصه های موجودیت استفاده می شود.
تعریف نظر: یک نظر شامل پنج تایی (e , a , s ,h , t) می باشد که در آن e نام موجودیت، a جنبه های موجودیت s، e لحن نظر بر روی جنبه ی a از موجودیت e h نظر دهنده و t زمانی است که نظردهنده h نظر خود را در مورد موجودیت e بیان میکند. هنگامی که نظر تنها در مورد یک موجودیت است برای a مقدار GENERAL قرار داده می شود.
**هدف و وظایف کلیدی شناسایی لحن نظرات:**
هدف پیدا کردن پنج تایی (e , a , s ,h , t) در یک سند d داده شده می باشد. که برای رسیدن به این هدف سیستم شناسایی لحن نظرات 6 وظیفه اصلی زیر را انجام می دهد:
وظیفه اول: استخراج موجودیت ها و دسته بندی آنها. استخراج موجودیت ها مشابه پیدا کردن موجودیت های نامدار در استخراج اطلاعات می باشد. در زبان طبیعی مردم برای یک موجودیت اسامی مختلفی بیان می کنند به طور مثال واژه ی Motorola به سه صورت نوشته می شود: Mot ، Moto ، Motorola بنابراین ما به راهکاری نیاز داریم که تشخیص دهید همه ی این اسامی به یک موجودیت اشاره میکند.
وظیفه دوم: استخراج جنبه ها و دسته بندی آنها. که چون در این پروژه تنها در مورد یک موجودیت نظر داده می شود این مقدار برابر GENERAL می شود. اینگونه مسائل در سطح سند (Document Level) طبقه بندی می شوند.
وظیفه سوم: استخراج نظر دهنده ها و دسته بندی آنها.
وظیفه چهارم: استخراج زمان نظر و تبدیل آن به فرمت استاندارد.
وظیفه پنجم: تعیین لحن نظر در مورد جنبه ی a.
وظیفه ششم: تولید تمام پنج تایی های (e , a , s ,h , t) موجود در سند d بر اساس نتیجه ی بخش های بالا.
به طور مثال در سند داده شده زیر:
Posted by: big John Date: Sept. 15, 2011
I bought a Samsung camera and my friends brought a canon camera yesterday.in the past week, we both used the cameras a lot. The photos from my Samy are not that great, and the battery life is short too. My friend was very happy with his camera and loves its picture quality. I want a camera that can take good photos. I am going to return it tomorrow.
پنج تایی های زیر استخراج می شوند:
(Samsung, picture_quality, negative, big John, Sept-15-2011)
(Samsung, battery_life, negative, big John, Sept-15-2011)
(Canon, GENERAL, positive, big John’s_friend, Sept-15-2011)
(Canon, picture_quality, positive, big John’s_friend, Sept-15-2011)
بر اساس مقداری که که می توان برای لحن در نظر گرفت دو نوع فرموله سازی وجود دارد.:
اگر لحن فقط مقادیر گسسته و قطعی بگیرد مانند: مثبت یا منفی، نسبتا مثبت،نسبتا منفی و خنثی در این صورت تبدیل به یک مسئله ی رده بندی (Classification Problem) می شود.
اگر لحن مقادیر عددی و یا امتیاز در یک بازه ی خاص را اختیار کند مانند 5-1 در این صورت تبدیل به یک مسئله ی رگرسیون (Regression Problem) می شود.
بیشتر تکنیک های موجود برای دسته بندی در سطح سند از یادگیری با ناظر استفاده می کنند. البته تعدادی روش بی ناظر هم وجود دارد. که در قسمت کارهای مرتبط بیشتر توضیح داده خواهد شد.
# کارهای مرتبط
( مرجع شماره 9 ) یک الگوریتم ساده یادگیری بی ناظر برای دسته بندی نظرات ارائه می کند که این دسته بندی بر اساس میانگین جهتگیری لحن عبارات داخل نظر است که شامل قید و صفت می باشد. یک عبارت دارای جهتگیری مثبت است هنگامی که آن دارای وابستگی های مثبت باشد و دارای جهتگیری منفی است هنگامی که آن عبارت دارای وابستگی های منفی باشد. در این مقاله جهتگیری لحن یک عبارت به وسیله ی اطلاعات متقابل بین عبارت داده شده و کلمه ی "عالی" منهای اطلاعات متقابل بین عبارت داده شده و کلمه ی "ضعیف" محاسبه می شود. یک نظر مثبت در نظر گرفته می شود اگر میانگین جهتگیری لحن عبارت هایش مثبت باشد.
(مرجع شماره 7) این مقاله یک روش برای پیداکردن لحن نظرات با استفاده از SVM برای کنار هم قرار دادن اطلاعات مربوط به منابع مختلف معرفی میکند.
[^Semantic ] که به آن نظرکاوی[^Opinion mining] هم گفته می شود روشی است که در آن نظر، لحن، برآورد، گرایش و احساس مردم نسبت به موجودیت هایی مثل: محصولات ، خدمات، وقایع مورد مطالعه قرار می گیرد.
**کاربردهای شناسایی لحن نظرات:**
نظرات به دلیل تاثیر کلیدی که بر روی رفتار انسان می گذارد محور اصلی بیشتر فعالیت های بشر می باشد. هنگامی که ما میخواهیم یک تصمیمی بگیریم نیاز داریم که نظرهای دیگران را هم بدانیم. در دنیای واقعی شرکت ها و سازمان ها همواره به دنبال این هستند که نظرات مردم یا مشتریان را درباره ی محصولات و یا خدمات خود بدانند. مشتریان هم به دنبال این هستند که قبل از خرید یک محصول نظرات کاربرانی که قبلا از آن محصول استفاده کرده اند را بدانند و بر اساس آن اقدام به خرید یا عدم خرید آن محصول کنند. بدست آوردن نظرات مردم و مشتریان خود یک تجارت عظیم برای بازاریابی، روابط اجتماعی و حتی رقابت های انتخاباتی می باشد. در گذشته این اطلاعات از طریق برگه های نظرسنجی و یا آزمایش بر روی یک گروه خاص بدست می آمد ولی امروزه با گسترش روزافزون رسانه های اجتماعی (مثل بلاگ ها،توییتر و فیسبوک) افراد و سازمان ها از محتوای این رسانه ها برای تصمیم گیری استفاده می کنند و افراد دیگر لازم نیست که به نظر دوستان و آشنایان درباره یک محصول اکتفا کنند زیرا نظر و بحث های فراوانی درباره ی آن محصول در محیط وب وجود دارد. البته به خاطر فراوانی و تنوع سایت ها پیدا کردن و پایش سایت های مفید و چکیده گرفتن از اطلاعات موجود در آنها هنوز کاری دشوار و پیچیده می باشد، زیرا هر سایت به طور معمول دارای حجم زیادی از نظرات می باشد که برای انسان عادی استخراج و خلاصه سازی نظرات موجود سخت می باشد. در اینجاست که نیاز به یک سیستم شناسایی لحن نظرات احساس می شود. در سال های اخیر سیستم های تشخیص لحن نظرات در تقریبا تمام محدوده های ممکن از پیش بینی فروش محصولات و خدمات مشتریان گرفته تا پیش بینی وقایع اجتماعی و نتیجه انتخابات سیاسی پخش شده اند.
**تعاریف پایه:**
تعریف موجودیت[^Entity] e: یک موجودیت می تواند یک محصول، سرویس، موضوع، فرد، سازمان یا حتی یک واقعه باشد. و با دوتایی ( T , W ) نشان داده می شود که در آن T سلسه مراتبی از اجزا و زیر اجزای موجودیت و w مجموعه مشخصه های موجودیت e را نشان می دهند. همچنین هر یک از اجزا و زیر اجزا هم دارای یک مجموعه مشخصه می باشند. به طور مثال برای موجودیت دوربین مجموعه مشخصه W شامل: سایز ، وزن و کیفیت تصویر است و مجموعه اجزا T شامل لنز و باتری می باشد. برای راحتی کار از واژه ی جنبه (aspect) به جای دوتایی مجموعه اجزا و مشخصه های موجودیت استفاده می شود.
تعریف نظر: یک نظر شامل پنج تایی (e , a , s ,h , t) می باشد که در آن e نام موجودیت، a جنبه های موجودیت s، e لحن نظر بر روی جنبه ی a از موجودیت e h نظر دهنده و t زمانی است که نظردهنده h نظر خود را در مورد موجودیت e بیان میکند. هنگامی که نظر تنها در مورد یک موجودیت است برای a مقدار GENERAL قرار داده می شود.
**هدف و وظایف کلیدی شناسایی لحن نظرات:**
هدف پیدا کردن پنج تایی (e , a , s ,h , t) در یک سند d داده شده می باشد. ولی از آنجا که ما در این پروژه قصد داریم در مورد تشخیص لحن نظرات درباره ی فیلم صحبت کنیم در نتیجه می توان زیرمسئلههای تشخیص نظردهنده، تشخیص موجودیت، تشخیص جنبه و زمان را برای سادهسازی حذف نموده و تنها لحن کلی یک نظر را بررسی نمود.
برای ادامه بحث بهتر است روش های زیر را برای استخراج ویژگی های متن تعریف کرد:
[14] روش n-gram : یک روشی است برای پیدا کردن کلمه ی n ام از روی n-1 کلمه ی قبلی.
روش POS یا Position Of Speech :در این روش به یک از کلمات جمله یک تگ[^Tag] اختصاص داده می شود که نشان دهنده ی موقعیت کلمه در جمله است. این تگ ها می توانتد به صورت خیلی رسمی باشد مانند N, V, Adj, Adv, Prep. و یا به روش های دیگر مانند finer-grained که دارای 36 تگ PRP, PRP$, VBG, VBD, JJR, JJS … می باشند عمل کرد
بیشتر تکنیک های موجود برای دسته بندی در سطح سند از یادگیری با ناظر استفاده می کنند. البته تعدادی روش بی ناظر هم وجود دارد. که در قسمت کارهای مرتبط بیشتر توضیح داده خواهد شد.
# کارهای مرتبط
[9] یک الگوریتم بی ناظر ساده را برای کلاس بندی نظرات ارائه کرده و نظرات را به دو دسته ی پیشنهادی[^Recommended ] و غیر پیشنهادی[^not Recommended] تقسیم میکند. این الگوریتم با روش PMI-IR برای پیش بینی جهت گیری لحن[^Semantic Orientation] عبارات داخل نظر با استفاده از اندازه گیری میزان شباهت دو کلمه یا عبارت به کار گرفته می شود. این الگوریتم 3 مرحله دارد:
مرحله ی اول: استخراج عبارات دارای قید و صفت. اگرچه یک صفتِ تنها میتواند نشان دهنده ی خوبی یا بدی باشد ولی ممکن است برای تعیین جهت گیری[^ Orientation] لحن کافی نباشد. به طور مثال عبارت غیر قابل پیش بینی [^Unpredictable] برای فرمان اتومبیل یک جهت گیری منفی ولی برای یک فیلم یک جهت گیری مثبت دارد. بنابراین الگوریتم دو کلمه ی متوالی را استخراج میکند که یکی از کلمات قید و یا صفت بوده و دیگری زمینه را فراهم میکند. برای استخراج این دو تایی ها از روش برچسب گذاری POS استفاده می شود. به این صورت که دو کلمه ی متوالی در صورتی از نظر استخراج می شوند که برچسب آن ها مطابق با یکی از الگوهای موجود در جدول زیر باشند.
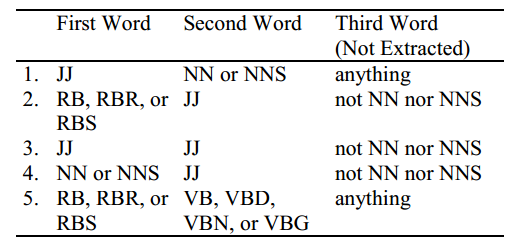
شکل 1.الگوهای برچسب گذاری برای استخراج عبارات دو کلمه ای از نظرات
در شکل زیر فرمت این الگوها نشان داده شده است.

مرحله ی دوم: تخمین جهتگیری عبارات استخراج شده در مرحله ی اول. در این مرحله از الگوریتم PMI-IR استفاده می شود. PMI بین دو کلمه ی word1 و word2 به صورت زیر تعریف می شود:
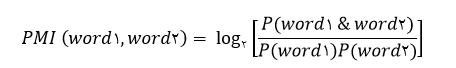
که در این فرمول (P(word1 & word2 احتمال وقوع همزمان کلمه ی word1 با word2 را نشان میدهد. کسر داخل فرمول وابستگی آماری میان دو کلمه را نشان میدهد. جهت گیری هر عبارت به صورت زیر محاسبه میشود:
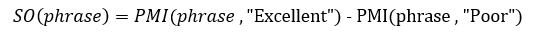
مرحله ی سوم: محاسبه ی میانگین جهت گیری لحن عبارات در نظر داده شده و کلاس بندی آن نظر با عنوان پیشنهادی و یا غیر پیشنهادی.
[15] گاهی محدودیت های موجود برای ترکیب های عطفی مشکلاتی برای تعیین جهت گیری لحن این ترکیبات ایجاد میکند. به طور مثال جمله ی:
The tax proposal was simplistic and well-received by the public.
نادرست است به خاطر اینکه صفت “simplistic” دارای جهت گیری منفی و صفت “well-received” دارای جهت گیری مثبت می باشد و ما از کلمه ی “and” زمانی استفاده می کنیم که هر دو صفت دارای یک جهت گیری باشند. در این مقاله برای حل این مشکل از یک الگوریتم یادگیری با ناظر 4 مرحله ای زیر استفاده میکند:
مرحله ی اول: همه ی ترکیب های عطفی از نظر داده شده استخراج می شوند.
مرحله ی دوم: از یک الگوریتم یادگیری با ناظر استفاده میکند برای اینکه مشخص کند ترکیب عطفی داده شده دارای جهت گیری یکسانی است و یا دارای جهت گیری های مخالف هم هستند. خروجی این مرحله یک گراف است که نودها صفات و رابطه ی بین نودها نشان دهنده ی یکسانی یا مخالف بودن جهت گیری لحن بین آن هاست.
مرحله ی سوم:یک الگوریتم خوشه بندی [^clustering Algorithm] ساختار گراف را برای تولید دو زیرمجموعه صفات پردازش می کند.
مرحله ی چهارم: از آنجا که می دانیم به طور کلی صفات مثبت از صفات منفی بیشتر استفاده می شوند، خوشه ی با میانگین تکرار بیشتر را به عنوان جهت گیری لحن مثبت کلاس بندی می کنیم.
[6] این مقاله گفتگوهای آنلاین درباره فیلم ها را دنبال میکند. و با استناد به اینکه معمولا مردم تمایل دارند برای بیان لحن خود از یک سری عبارات مشخص استفاده کنند، کلاس پیام ها را با گشتن به دنبال مجموعه عبارات مشخصی که نشان دهنده ی لحن نویسنده ی آن، در رابطه با فیلم است مشخص میکند. این مجموعه عبارات می تواند شامل عبارات زیر باشند:
“great acting”, “wonderful visuals”, “terrible score”, “uneven editing”
که این عبارات باید به صورت دستی در یک لغت نامه خاص وارد شوند، و لحن معادل هر عبارت را هم باید به صورت دستی وارد کرد. این لغت نامه برای هر زمینه متفاوت می باشد و برای زمینه های جدید یک لغت نامه دیگر لازم است.
[1] در این مقاله برای کلاس بندی نظرات از سه الگوریتم یادگیری Naïve Bayes ، Maximum Entropy و SVM استفاده می شود. برای پیاده سازی این الگوریتم ها بر روی سند داده شده باید از یک چارچوب استاندارد پیروی کنیم: فرض می کنیم {f1 , f2 , … , fm} شامل m ویژگی از پیش تعیین شده ای باشند که میتوانند در یک سند ظاهر شوند. و (ni(d تعداد دفعاتی باشد که ویژگی fi در سند d رخ می دهد. در این صورت سند d را میتوان به صورت بردار زیر نمایش داد:
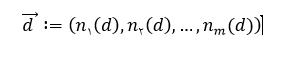
روش اول: Naïve Bayes :
در این روش برای تعیین کلاس سند داده شده d از فرمول زیر استفاده می شود:
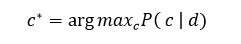
که( P( c | d به صورت زیر بدست می آید:
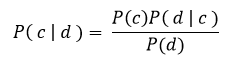
در این فرمول (P(d نقشی در تعیین کلاس *c ندارد. و برای تعیین (P( d | c می توان با فرض اینکه ویژگی ها مستقل از هم هستند به رابطه ی زیر رسید:
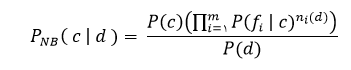
اگر چه شرط مستقل بودن ویژگی ها در دنیای واقعی برقرار نمی باشد ولی این روش هنوز به طرز شگفت آوری خوب عمل میکند.
روش دوم Maximum Entropy:
در این روش برای تخمین ( P( c | d از روش زیر استفاده می کند:
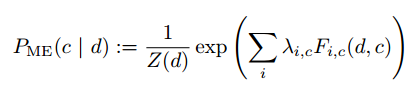
که در آن (Z(d یک تابع نرمال و λ یک پارامتر وزن دار است طوری که λ نشان دهنده ی این است که ویژگی fi به کلاس c اشاره میکند و (Fi,c( d , c هم به صورت زیر تعریف می شود:
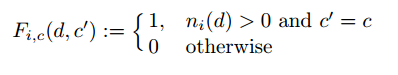
این روش هیچ فرضی مبنی بر مستقل بودن ویژگی ها نمی کند و به همین دلیل برای مواقعی که نمی توان چنین فرضی نمود از روش naïve Bayes بهتر عمل می کند.
روش سوم SVM :
ایده اصلی پشت پروسه ی آموزش، پیدا کردن یک هایپرپلن[^Hyperplane] است که با بردار w ⃗ نشان میدهند که این هایپرپلن نه تنها بردار های d یک کلاس را از کلاس های دیگر جدا میکند بلکه بزرگترین هایپرپلن ممکن را پیدا می کند. برای این کار فرض می کنیم {c(j )∈ {1 ,-1 کلاس درست سند di باشد. پاسخ میتواند به صورت زیر باشد:
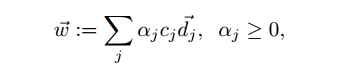
# آزمایشها
# کارهای آینده
# مراجع
[1] Pang, Bo, Lillian Lee, and Shivakumar Vaithyanathan. "Thumbs up? Sentiment Classification using Machine Learning Techniques."
[2] Liu, Bing, and Lei Zhang. "A survey of opinion mining and sentiment analysis." Mining Text Data. Springer US, 2012. 415-463.
[3] Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank, Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Chris Manning, Andrew Ng and Chris Potts. Conference on Empirical Methods in Natural Language Processing (EMNLP 2013).
[4] Bespalov, Dmitriy, Bing Bai, Yanjun Qi, and Ali Shokoufandeh. Sentiment classification based on supervised latent n-gram analysis. In Proceeding of the acmconference on information and knowledge management (ciKm-2011). 2011
[5] Li, Shoushan, Sophia Yat Mei Lee, Ying Chen, Chu-Ren Huang, and Guodong Zhou. Sentiment classification and polarity shifting. In Proceedings of the 23rd international conference on computational Linguistics (coLing -2010). 2010
[6] Polanyi, Livia and Annie Zaenen. contextual valence shifters. In Proceedings of the aaaiSpring Symposium on exploring attitude and affect in text. 2004.Tong, R.M. 2001. An operational system for detecting and tracking opinions in on-line discussions. W or king Notes of the A CM SIGIR 2001 Workshop on Operational Text Classification (pp. 1-6).New York, NY: ACM
[7] Mullen, Tony and Nigel Collier. Sentiment analysis using support vector machines with diverse information sources. In Proceedings of emnLP-2004. 2004
[8] Paltoglou, Georgios and Mike Thelwall. astudy of information retrieval weighting schemes for sentiment analysis. In Proceedings of the 48th annual meeting of the association for computational Linguistics (acL-2010). 2010
[9] Turney, Peter D. thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews. In Proceedings of annual meeting of the association for computational Linguistics (acL-2002). 2002
[10] Mejova, Yelena and Padmini Srinivasan. exploring Feature Definition and Selection for Sentiment classifiers. In Proceedings of the Fifth international aaai conference on Weblogs and Social media (icWSm-2011). 2011
[11] Gamon, Michael, Anthony Aue, Simon Corston-Oliver, and Eric Ringger. Pulse: mining customer opinions from free text. advances in intelligent Data analysis Vi, 2005: pp. 121–132
[12] Abbasi, Ahmed, Hsinchun Chen, and Arab Salem. Sentiment analysis in multiple languages: Feature selection for opinion classification in web forums. acm transactions on information Systems
[13] Dasgupta, Sajib and Vincent Ng. mine the easy, classify the hard: a semi-supervised approach to automatic sentiment classification. In Proceedings of the 47th annual meeting of the acL and the 4th iJcnLP of the aFnLP (acL-2009). 2009 (toiS), 2008. 26(3)