به نام خدا
اسیرا 1 یکی از انواع آزمونهای شناخت انسان از رایانه (کپچا2) است که از کاربر می خواهد از مجموعه ی 12 عکس سگ و گربه فقط تصاویر گربهها را انتخاب کند. انجام این تست برای انسان بسیار ساده است [1]. بهطوری که 99/6% از انسانها در کمتر 30 ثانیه به آن پاسخ میدهند. ولی شواهد نشان می دهند که تشخیص گربه و سگ به صورت خودکار از یکدیگر کار دشواری است [2].

در این تست اگر اشارهگر موس روی هریک از تصاویر نگه داشته شود تصویر حیوان به صورت بزرگ تر نمایش داده شده و جملهی"Adopt me" در زیر آن تصویر ظاهر می شود که در صورت کلیک بر آن کاربر را به صفحهی آن حیوان در سایت 3Petfinder.com ارجاع میدهد. لازم به ذکر است که این تست برای مجموعهی داده4ای خود از آرشیو این سایت استفاده میکند[2].
۱. مقدمه
درچند سال اخیر در صفحات وب برای جلوگیری از نفوذ هکرها و روباتها به رایانه از کپچا استفاده میشود که برای حل آن به یک کاربر (انسان) نیاز است. بهدلیل اینکه آزمونها باید برای انسان ها ساده و برای رایانه دشوار باشد، تمام آنها بر پایهی اطلاعاتی طراحی میشوند که برای کاربرها قابل تشخیص و برای عاملهوشمند 5 غیر قایل تشخیص باشد. از نظر نوع این اطلاعات کپچاها را میتوان به 2 دسته تقسیم کرد :
در دستهی اول این اطلاعات صرفا اعداد و حروف تصادفی هستند.
در دسته دوم این اطلاعات تصاویر هستند.
دسته دوم علاوه بر تصادفی بودن به پایگاه داده6ی بزرگی از تصاویر دستهبندی شده 7 نیاز دارد. اما دسته اول را می توان با چند خط کد پیادهسازی کرد. و این در حالی است که امکان موفقیت رایانهها در این نوع تست بیشتر از نوع دوم است. در میان دلایل متعدد برتری دسته ی دوم میتوان به این دلیل اشاره کرد که مجهز کردن ماشین به بینایی 8 بسیار دشوارتر از مجهز کردن آن برای تشخیص متن 9است. اما فراهم آوردن پایگاه دادهی مورد نیاز دسته دوم نیز کار دشواریست[2].

اسیرا در دسته دوم از انواع کپچاها قرار میگیرد و پایگاه داده ای خود را از سایت Petfinder.com تامین می کند. Petfinder10 دارای پایگاه دادهای شامل بیش از 3 میلیون تصویر از سگ و گربه است که روزانه 10000 تصویر را به پروژهی اسیرا اختصاص میدهد. همچنین لازم به ذکر است که اسیرا توسط شرکت مایکروسافت ابداع شده است[4]. انگیزهی انجام این پروژه شناخت تصاویر سگ و گربه از یکدیگر به کمک الگوریتم های هوش مصنوعی به منظور عبور از اسیرا می باشد.
۲. شرح مسئله
در این مسئله وظیفه ی ما یافتن الگوریتمی با بالاترین میزان دقت در تشخیص تصاویر سگ و گربه برای دسته بندی آنهاست. ورودی این مسئله مجموعه دادهای جهت آموزش11 از تصاویر سگ و گربه و خروجی آن میزان دقت در طبقه بندی تصاویر در مجموعه دادهای مورد آزمایش 12 است[5]. مجموعه داده ای که توسط سایت Kaggle.com در اختیار ما قرار داده شده است قسمتی از پایگاه داده اسیرا است که توسط مایکروسافت ارائه شده است. مجموعه دادهای جهت آموزش آن شامل 25000 تصویر که 12500 تصویر آن سگ و 12500 تصویر دیگر آن گربه است. و همچنین مجموعه دادهای مورد آزمایش آن نیز شامل 12500 تصویر است. سایز متوسط تصاویر ارائه شده در حدود 500*350 پیکسل است.

با توجه به آنچه که در شکل 3 مشاهده می کنید در کار یادگیری، ورودی، مجموعه داده مخصوص آموزش است و خروجی که به کمک یکی از الگوریتم هایی که در
قسمت بعدی ذکر می شود به دست میآید، مدل طبقه بندی شده است و در قسمت عملکرد کار (شکل 4) از این مدل طبقه بندی شده استفاده کرده و مجموعه داده مخصوص آزمایش را مورد بررسی قرار می دهد.

۳. کارهای مرتبط
در ادامه به توضیح روش هایی که می توان برای حل این مسئله از آنها بهره برد میپردازیم:
3.1. SIFT13
"تبدیل مستقل از مقیاس ویژگی" یک الگوریتم در بینایی ماشین است؛ که برای استخراج ویژگیهای مشخص از تصاویر، استفاده در الگوریتم کارهایی چون تطبیق نماهای مختلف یک جسم یا صحنه و شناسایی اجسام به کار میرود. در این الگوریتم ابتدا تصویر اصلی به طور پیشرونده با فیلترهای گاوسی با سیگما در بازه ۱ تا ۲ محو میشود که حاصلش یک سری تصاویر محو شده گاوسی است (به این کار فیلتر کردن آبشاری می گویند) سپس، این تصویرها از همسایگان بلافصل خود(از دید سیگما) کم میشوند تا یک سری جدید از تصاویر پدید آیند[6].
گامهای اصلی در محاسبه ویژگیهای تصویر عبارتاند از:
آشکارسازی اکسترممهای فضای مقیاس هر پیکسل در تصاویر با هشت همسایهاش و نه پیکسل(پیکسل متناظر و هشت همسایهاش) از هر یک از تصاویر دیگر سری مقایسه میشود.
محلیسازی کلیدنقطهها - کلیدنقطهها از اکسترممهای فضای مقیاس گزیده میشوند.
گرایش گماری - برای هر کلیدنقطه در یک پنجره ۱۶x۱۶، نمودار فراوانی گرایش گرادیانها به کمک درونیابی دوسویه محاسبه میشوند.
توصیفگر کلیدنقطه - نمایش در یک بردار ۱۲۸ عنصری.

3.2. bag of words(BoW)
در بینایی کامپیوتر مدل BoW در صورتی که در آن با ویژگیهای تصاویر مانند کلمات برخورد گردد میتواند برای دستهبندی تصاویر مورد استفاده قرار گیرد. در این مدل یک لغتنامه به وسیله خوشهبندی 14ویژگیهای استخراج شده 15 مجموعه دادههای آموزشی تشکیل می دهد. و همچنین هر خوشه16 یک کلمه از این فرهنگ لغت تصویری محسوب می شود. و تصاویر با بردار های فراوانی که در آن هر بعد نشان دهنده نسبت ویژگی های متعلق به یک خوشه است[5].

۳.۳. یادگیری عمیق 17
یادگیری عمیق یک زیر شاخه از یادگیری ماشینی است که اساس آن بر یادگیری نمایش دانش و ویژگیها در لایههای مدل است [7]. یک نمونه ( برای مثال : تصویر یک گربه) می تواند به صورت های مختلف نظیر یک بردار ریاضی پر شده از مقدار به ازای هر پیکسل و در دید کلی تر به شکل یک مجموعه از زیرشکل های کوچک تر (نظیر اعضای صورت گربه) مدل سازی شود. برخی از این روش های مدل سازی باعث ساده شدن فرایند یادگیری ماشین (برای مثال : تشخیص تصویر گربه) می شود. در واقع به زبان سادهتر، هدف یادگیری عمیق، استخراج خود ویژگیها به صورت هوشمند طی یک مرحله یادگیری است. انگیزه ی اولیه این حوزه از طریقه بررسی ساختار عصبی در مغز انسان الهام گرفته شده است که در آن یاخته های عصبی با ارسال پیام به یکدیگر ادراک را امکان پذیر می کنند.
در بخش بعد پیاده سازی این الگوریتم ها می پردازیم.
۴. آزمایشها
۴.۱. مجموعه دادهها
همان طوری که در قسمت شرح مسئله توضیح دادهشد، مجموعه دادهای که مسابقهی Kaggle در اختیار ما قرار داده است به شرح زیر است :
مجموعهی دادهای جهت آموزش : شامل 25000 تصویر سگ و گربه که تصاویر دارای برچسب می باشند.
مجموعهی دادهای جهت آزمایش : شامل 12500 تصویر است (واضح است که این تصاویر فاقد برچسب میباشند.)
تمام تصاویر این دو مجموعه دارای فرمت jpg بوده و سایز متوسط تصاویر ارائه شده در حدود 500*350 پیکسل است. میتوان آنها را از اینجا به دست آورد. اما در اینجا به علت موجودنبودن برچسب18 مجموعهی دادهای جهت آزمایش به منظور تشخیص درصد خطای الگوریتم، از بخشی از مجموعهی دادهای جهت آموزش (که دارای برچسب هستند) استفادهمیکنیم.

۴.۲. پیاده سازی
در این قسمت مدل BoW را برای پیاده سازی پروژه و الگوریتم SIFT را جهت استخراج ویژگیهای تصاویر انتخاب کردهایم.( در قسمت کارهای مرتبط به توضیح آنها پرداختهایم.)
مراحل ابتدایی جهت این کار عبارتند از :
خواندن تمام تصاویر از مجموعه دادهای جهت آموزش و برچسبهای آنها.
استخراج ویژگیهای هر تصویر به کمک روش bag of words.
یادگیری از طریق بردارهای تصاویر.
ارائهی تصاویر از مجموعهی دادهای جهت آزمایش به الگوریتم برای پیش بینی دسته تصاویر.
از الگوریتم SIFT جهت استخراج نقاط کلیدی19 و توصیف نقاط کلیدی20 هر تصویر بهرهمیبریم.در این مرحله الگوریتم آرایهای از توصیفات را برمیگرداند. بعد از استخراج نقاط کلیدی و توصیفات آنها باید فرادادهها را از هر فایل تصویر بهدستآورد. فرادادهها21 شامل نام فایلها،مسیر22 و کلاس یا دسته 23تصاویر می باشند.
مراحل پیادهسازیشده در کد را می توان به کمک تصویر زیر بهتر درکنمود.
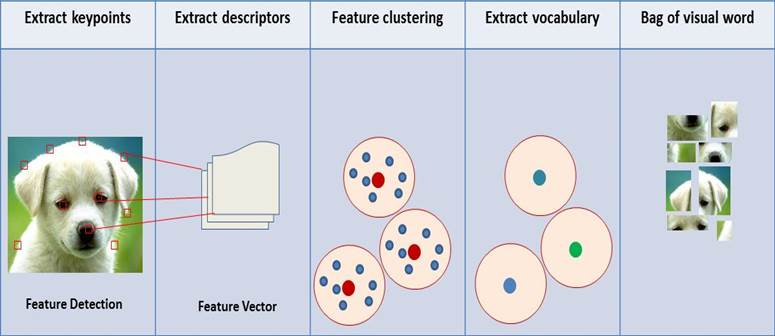
همانطوری که در شکل مشاهدهمیکنید بعد از بهدستآوردن آرایهی ویژگیها، به خوشهبندی ویژگیها و استخراج واژهنامهای از ویژگیها24 میپردازیم. سپس استخراجکنندهی ویژگی 25 میتواند از واژهنامهی بهدستآمده برای پردازش تصاویر استفادهکند.
این الگوریتم صرفا از یک مدل آموزشیافته جهت پیشبینی نوع تصویر استفادهمیکند.
برای یادگیری مشخصات استخراجشده، از ماشین SVM 26 استفادهمیکنیم.
۴.۳. ابزارهای مورد استفاده
برای پیادهسازی مدل BoW، الگوریتم SIFT و همچنین ماشین SVM از زبان برنامهنویسی پایتون27،کتابخانهی scikit-learn 28 و کتابخانه openCV 29 استفاده میکنیم. روش نصب این کتابخانههادر اینجا ذکرشدهاست.
کد کامل پروژه را میتوان از گیت هاب دریافتکرد.
۴.۴. نتایج
نتایج زیر به کمک یک مجموعهی دادهای جهت آموزش شامل 100 تصویر و دو مجموعهی دادهای جهت آزمایش شامل 100 تصویر گربه و 100 تصویر سگ بهدستآمدهاست.
| تعداد تصاویر درست | تعداد تصاویر غلط | میزان دقت | |
|---|---|---|---|
| حالت ۱(مجموعهی دادهای جهت آزمایش شامل ۱۰۰ تصویر گربه) | 66 | 34 | 66% |
| حالت ۲(مجموعهی دادهای جهت آموزش شامل ۱۰۰ تصویر سگ) | 69 | 31 | 69% |
جدول 1 - نتایج اولیه
در زیر بعضی از نمونههای درست و نادرست را نمایشمیدهیم.
۴.۴.۱. نمونههای درست



۴.۴.۲. نمونههای نادرست


۴.۵. بهبود نتایج
اگر مجموعهی دادهای جهت آموزش را افزایشدهیم، میزان دقت الگوریتم افزایشمییابد. در آزمایشهای بالا عامل را به کمک ۱۰۰ تصویر آموزشدادهایم، حال این مقدار را به ۱۰۰۰ تصویر میرسانیم و نتایج را با حالت قبلی مقایسه میکنیم.
| تعداد کل تصاویر مجموعهی دادهای جهت آزمایش | تعداد تصاویر درست | میزان دقت | |
|---|---|---|---|
| حالت ۱(مجموعهی دادهای جهت آموزش شامل ۱۰۰ تصویر) | 150 | 82 | 54/6% |
| حالت ۲(مجموعهی دادهای جهت آموزش شامل ۱۰۰۰ تصویر) | 150 | 116 | 66% |
جدول 2 - مجموعهی دادهای جهت آزمایش فقط شامل تصاویر گربه میباشد.
به علت محدود بدون حجم حافظه، میتوانیم عامل را به کمک چند مجموعه تصویر به صورت متوالی آموزشدهیم که همانطور که مشاهدهمیشود به افزایش میزان دقت تشخیص میانجامد.
| تعداد تصاویر درست | میزان دقت | |
|---|---|---|
| عامل آموزشیافته با یک مجموعه داده | 82 | 54/6% |
| عامل آموزشیافته با دو مجموعه داده | 94 | 62/6% |
| عامل آموزشیافته با سه مجموعه داده | 103 | 68/6% |
| عامل آموزشیافته با چهار مجموعه داده | 117 | 78% |
جدول 3 - مجموعهی دادهای جهت آزمایش شامل 150 عکس گربه و هر مجموعهی دادهای جهت آموزش شامل 100 عکس میباشد.
| تعداد تصاویر درست | میزان دقت | |
|---|---|---|
| عامل آموزشیافته با یک مجموعه داده | 331 | 66/2% |
| عامل آموزشیافته با دو مجموعه داده | 364 | 72% |
جدول 4 - مجموعهی دادهای جهت آزمایش شامل 500 عکس گربه و هر مجموعهی دادهای جهت آموزش شامل 1000 عکس میباشد.
۵. کارهای آینده
یکی از راهکارهای مناسب برای ادامه این پروژه استفاده از روش یادگیری عمیق می باشد[10]. در این روش به علت مدلسازی شکل مورد نظر به زیر شکلهای کوچکتر که باعث سادهترشدن فرآیند یادگیری ماشین میشود و همچنین نداشتن مشکل حافظه ذکرشده برای این روش، دقت بالاتری را برای تشخیص تصاویر سگ و گربه از یکدیگر بهدستمیدهد. و همچنین از مشکلات پیادهسازی این روش میتوان به نیاز آن به سخت افزار خاص اشارهکرد. که در آینده میتوان این روش را نیز پیادهسازی نمود.
۶. مراجع
[1] Philippe Golle, Machine Learning Attacks Against the Asirra CAPTCHA
[2] Jeremy Elson, John R. Douceur, Jon Howell, Jared Saul, Asirra: A CAPTCHA that Exploits Interest-Aligned Manual Image Categorization
[3] Asirra AntiSpam
[4] Microsoft Research - Asirra Project
[5] Bang Liu, Yan Liu, Kai Zhou, Image Classification for Dogs and Cats
[6] David G. Lowe, Distinctive Image Features from Scale-Invariant Keypoints
[7] Yoshua Bengio,Deep Learning of Representations: Looking Forward
[8] Dogs vs. Cats competition dataset from Kaggle
[9] Amrith Kumar, Machine Learning-Image Detection.Cats Vs Dogs
[10] Deep Learning Wins Dogs vs Cats competition on Kaggle
پیوندهای مفید
Asirra (Animal Species Image Recognition for Restricting Access)
CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart)
بزرگترین سایت برای یافتن خانه برای حیوانات بیخانمان
dataset
agent
database
classified
machine vision
text recognition
برای مطالعه بیشتر:https://www.petfinder.com/birthday-petfinder-story/
training dataset
test dataset
SIFT( تبدیل ویژگی مقیاسنابسته)
clustering
extracted
cluster
deep learning
label
Keypoints
نمایش یک بردار عددی از ویژگیهای تصاویر : Keypoint descriptors
metadata
path
category
در اینجا منظور واژگان بصریست.
feature extractor
( ماشین بردار پشتیبانی)Support vector machines
python :یک زبان برنامه نویسی همه منظوره،سطح بالا،شیءگرا و مفسر است
یک کتابخانهی یادگیری ماشین منبع باز برای زبان برنامه نویسی پایتون .
یک کتابخانهی بینایی ماشین منبع باز جهت دستکاری تصاویر.