به نام خدا
ایجاد واژهنامه از روی پیکره دوزبانه یکی از گامهای اصلی برای رسیدن به یک سامانه مترجم ماشینی است. ترجمه ماشینی یعنی تبدیل خودکار متن زبان مبدا به متن معادل آن در زبان مقصد. عمده روشهای ترجمه ماشینی بر مبنای مدلهای آماری و یادگیری ماشین بنا شده است که از یک پیکره دوزبانه، مجموعهی عظیمی از متن که به هر دو زبان مبدا و مقصد وجود داشته و در سطح جمله همتراز شدهاند، برای یادگیری معادلها به صورت آماری استفاده میکنند.
پیکره دوزبانه غالبا در سطح جمله همتراز میشود. حال مسئله اصلی این خواهد بود که چطور میشود این جملهها را در سطح کلمه همتراز نموده و واژهنامهای به صورت خودکار از کلمات معادل، از روی پیکره دو زبانه استخراج نمود.
۱. مقدمه
با گسترش روزافزون حجم دادهها و اطلاعات و همچنین گسترش تعاملات بینالمللی، برقراری ارتباط تبدیل به یکی از مهمترین چالشهای بشر امروز شده است. یکی از مشکلات عمدهای که در این زمینه وجود دارد عدم امکان برقراری ارتباط توسط دادگانی به زبان دیگر است. ترجمه ماشینی یکی از راههایی است که برای حل این مشکل ارائه شده و به خاطر اهمیت آن، در سالیان اخیر توجه بسیار زیادی به آن شده است. رویکردهای متفاوتی در پیادهسازی این ایده وجود دارد که رویکرد مبتنی بر قانون از برجستهترین آنها بوده و در سالهای اخیر رویکرد جدید مبتنی بر آمار مطرح شده است. رویکرد آماری ترجمه ماشینی را، مبتنی بر پیکره1 نیز مینامند. چراکه سیستم طراحیشده، تمام اطلاعات موردنیاز خود را، از یک پیکره موازی دوزبانه2 که مجموعه بسیار بزرگی از جملات هم ترجمه است، استخراج مینماید. مبنای عملکرد یک مترجم آماری، نظریه تصمیم آماری است. تئوری تصمیم آماری روش شناختهشدهای برای ساخت یک سیستم تصمیمگیری مرکب، از چندین منبع اطلاعاتی موجود، با هدف حداقل سازی خطای تصمیمگیری میباشد. پارامترهای چنین سیستمی با استفاده از مجموعه بزرگی از دادگان آموزشی (پیکره موازی دوزبانه) تخمین زده میشود. به کمک این روش امکان ترجمه متون تخصصی در زمینههای مختلف با بررسی مقالات موجود در آن زمینه و ترجمه آنها میسر میشود.
یکی از مراحل ترجمهی ماشینی ساخت واژهنامه با استفاده از همتراز کردن لغات در جملات همترجمه است که در ادامه به آن خواهیم پرداخت.
۲. مدلهای همترازی
۲.۱. همترازی لغات3
مسئله همترازی لغات بدین صورت تعریف میشود که جمله e = e_{1}^{I} در زبان مبدأ و ترجمه آن در زبان مقصد f = f_{1}^{J} داده شده، هدف یافتن تناظر بین لغات e و f است. ارتباط بین دو لغت توسط جفت (i,j) مشخص میشود که مکان آنها را در f و e مشخص میکند و 1\leqq i\leqq I \text{ , } 1 \leqq j \leqq J .
این رابطه میتواند توسط گراف بدون جهت A با I+J رأس یا ماتریس B با I×J خانه نمایش داده شود که [3]
دو شکل زیر این دو روش را برای جمله انگلیسی and the program has been implemented و جمله فرانسوی معادل le programme a ´et´e mis en application نشان میدهد.[7]


پارامترهای ماشین ترجمه آماری با بررسی پیکرههای تراز شده در سطح لغت برآورد میشوند و بالعکس، همترازی خودکار لغات، بهترین همترازی را با استفاده از مدل ماشین ترجمه آماری انتخاب میکند.فرایند چرخشی حاصل از این دو تفکر، نمونهای از الگوریتم امید ریاضی-بیشینه کرد 4 را نتیجه میدهد.[6]
۲.۲. مدلهای همترازی چند به یک[9]
جهت کم کردن پیچیدگی محاسباتی برای مدلها این محدودیت را قایل میشویم که هر کلمه هدف تنها با یک کلمه مبدأ بتواند متناظر شود. در نتیجه ما میتوانیم تناظر بین دو جمله را با دنباله a = a_{1}^{J} نشان دهیم و a_j = i را مکان لغتی در جمله مبدأ که با آن متناظر است تعریف کنیم.
دنباله a_{i}^{j} متغیر پنهانیاست که در پیکره موازی مشخص نشده اما برای ساخت مدلهای درست فرایند ترجمه لازم است محاسبه شود. احتمال تولید f = f_{1}^{J} از e = e_{1}^{I} با همترازی a = a_{1}^{J} این را با (P(a_{1}^{J},f_{1}^{J}|e_{1}^{J} مدل میکنیم. بعضی مواقع یک کلمه در جملهٔ مقصد ترجمهٔ هیچ کلمهای در جملهٔ مبدأ نیست، با در نظر گرفتن توکن خالی 5چنین امکانی را به مدل اضافه میکنیم.
هم ترازی که احتمال توأم جمله هدف را از جمله مبدأ ماکسیمم کند، همترازی ویتربی6 نام دارد و اینگونه محاسبه میشود:

در ادامه به معرفی چند مدل همترازی میپردازیم.
۲.۳. مدلهای همترازی آیبیام7
مدلهای آیبیام از ۱ تا ۵ به ترتیب افزایش پیچیدگی و تعداد پارامترها نامگذاری شدهاند.
۲.۳.۱. مدل 1[6]
در مدل ۱ فرضیات زیر در نظر گرفته میشود:
طول جملهٔ مقصد (J) غیر مستقل از I است.
برای هر کلمهٔ هدف، همه ترازها هم احتمال هستند و به مکان کلمه در جمله بستگی ندارد در واقع توزیع احتمالی مدل همترازسازی، یکنواخت در نظر گرفته میشود.
(P(a_{j}|f_{1}^{j-1},a_{1}^{j-1},J,e_{1}^{I}) = 1/(I+1) (3هنگام محاسبه همترازی، کلمه هدف تتها به کلمه مبدأی که با آن متناظر است، وابسته است.
(P(f_{j}|a_{1}^{j},f_{1}^{j-1},J,e_{1}^{I}) = T(f_{j}|e_{a_j}) (4
(T(f_{j}|e_{a_j} احتمال ترجمه کلمه به کلمه از است.
۲.۳.۲. مدل 2[5]
در مدل دو ما فرض میکنیم که مکان تراز a_{j} برای کلمه f_{j} بهj و طولهای جملات،I و J بستگی دارد. در نتیجهٔ چنین فرضی ماتریس همترازی به ماتریس قطری میل میکند.
(P(a_{j}|f_{1}^{j-1},a_{1}^{j-1},J,e_{1}^{I}) = a(a_{j},J,I) (5
۲.۳.۳. مدلهای مبتنی بر باروری8[7]
مدل 1 و 2 بر اساس انتخاب کار میکردند، یعنی به هر لغت هدف یک لغت مبدأ را اختصاص میدادند، اما در همترازی دستی میبینیم که لغات مختلف تمایلات مختلفی برای تراز شدن با تعداد متفاوتی عدد را دارند و همین ویژگی باعث شده تا نحوه عملکرد مدلهای باقی مانده از این دو مدل متفاوت شود.متغیر رندوم\phi_{e}را برابر با تعداد لغاتی که e در یک همترازی به آنها متصل است تعریف میکنیم و آنرا حاصلخیزی e مینامیم. در مدلهای مبتنی بر حاصلخیزی ابتدا حاصلخیزی تمام لغات مبدأ را مشخص میکنیم،سپس تصمیم میگیریم که هر لغت کدام کلمات هدف =t_{1,i},…,t_{I,\phi_{i}}t_{i} را تولید میکند. این دنباله کلمات یک تبلت9 و مجموعه تبلتها، تابلو10 نامید میشود. سپس مکان هر کلمه در تابلو در جمله مقصد را مشخص میکنیم(\pi_{I,k}). بنابرین داریم:
P(\pi_{0}^{I},t_{0}^{I}|e_{0}^{I}) = P(\phi_{0}^{I}|e_{1}^{I})P(t_{0}^{I}|\phi_{0}^{I},e_{1}^{I})P(\pi_{0}^{I}|t_{0}^{I},e_{1}^{I}) (6)
اگر <t,$\pi$> را مجموعه جفتهایی تعریف کنیم که f و a یکسانی را نتیجه میدهند خواهیم داشت:
P(f,a|e) = \Sigma_{(t,\pi)\Subset {(f,a)}} P(t,\pi|e) (7)
۲.۳.۴. مدل 3
مدل 3 یک مدل مبتنی بر باروری است که فرضیات زیر در آن در نظر گرفته شده:
احتمال حاصلخیزی یک لغت فقط به همان لغات بستگی دارد و نه به همسایگانش و حاصلخیزی آنها
ترجمه فقط به جفت کلمه مبدا و مقصد بستگی دارد و نه کلمات مبدا یا مقصد قبلی
مرتبسازی فقط به مکان کلمه هدف و طول دو جمله ربط دارد.
۲.۳.۵. مدل 4[8]
مدل 3 کلمات یک تبلت را غیر مستقل از هم تراز میکرد.در مدل 4 مکان اولین کلمه یک تبلت مشخص میشود و مکان سایر کلمات تبلت به مکان کلمه اول وابسته است.
P(\pi_{i,1} = j|\pi_{1}^{i-1},t_{0}^{I},\phi_{0}^{I},e_{0}^{I}) = d_{1}(j-c_{i-1}|A(e_{i-1}),B(f_{j})) (8)
c_{i} سقف میانگین مکانهای تبلت i در جمله مقصد است.A و B توابعی هستند که کلمات را بر اساس تاثیری که روی ترتیب ترجمه دارند، طبقهبندی میکنند.
۲.۳.۶. مدل 5
در مدل ۳ و ۴ هوریستیکی وجود ندارد که از تخصیص مکانی ک قبلا استفاده شده، جلوگیری کند یعنی ممکن است به ازای جفت i,k، نابرابر t(I,k) برابر داشته باشیم. مدل ۵ این ناقص را رفع کرده اما به پیچیدگی مدل افزوده.
۲.۴. مدل پنهان مارکوف11[4]
در ترازبندی صورت گرفته توسط انسان، تراز یک کلمه به شدت به تراز کلمه قبلی خود وابسته است، بنابرین به مدلی جهت در نظر گرفتن این وابستگی نیاز داریم. اگر تصور کنیم که تراز a_{j} تنها به تراز قبلیاش وابسته است(فرض مارکوف)، میتوانیم مدل پنهان مارکوف را با مرتبط کردن حالت i با کلمه e_{j} تعریف کنیم. همچنین تصور میکنیم f_{j} تنها به لغت متناظر خود، e_{a_j} وابسته است و از حالت i با احتمال (t(f_{j}|e_{i} انتشار مییابد.
۲.۵. کارهای مشابه[12]
۲.۶. دادگان[11]
پیکره میزان مجموعهای است حاوی بیش از ۱ میلیون جمله از متون انگلیسی (اغلب در حوزه ادبیات کلاسیک) و ترجمه این جملات به فارسی که توسط دبیرخانه شورای عالی اطلاعرسانی تهیه شدهاست.
۳. آزمایشها
پروژههایی در این زمینه که با روشهای مدلسازی مختلف پیادهسازی شدهاند، موجوداند که برخی از آنها مرتبط با این تکلیف درس یادگیری ماشین میباشند، من در این فاز به پبادهسازی مدل آیبیام 1 پرداختم و در آن از یکی از همین پروژهها استفاده کردهام.
لینک پروژه در گیت
همانگونه که گفته شد در مدل آیبیام 1، در ابتدا همهی احتمالها یکسان در نظر گرفته شده و از توزیع نرمال محاسبه میشود. حال اگر بررسی پیکره به جای یکبار، چندین بار صورت گیرد و هر بار از احتمالات حاصل از مرحله قبل استفاده شود، نتیجه دقیقتر خواهد بود. حلقه داخل کد و متغیر loop_count به همین منظور استفاده شدهاند. مسلما هر چقدر تعداد دفعات این تکرار بیشتر شود، نتیجه دقیقتر میشود. نتیجه برای دو فایل متن موجود در پروژه گیتهاب در زیر آمده است:


در برنامه اصلی از ساختمان داده دیکشنری استفاده شده بود که برای پیکرهای به بزرگی پیکره میزان کارآمد نبود و به خطای حافظه منجر میشد. برای حل این مشکل به جای دیکشنری از جدول استفاده کردهام، با اینکار مشکل حافظه حل شد اما سرعت برنامه به دلیل بزرگی پیکره رضایتبخش نیست.
در مرحله بعد اعداد و علایم نگارشی را با اجرا فایل clear.py حذف کردهام تا در لغتنامه ظاهر نشوند.
در ادامه به ترتیب قسمتی از نتیجه اجرای برنامه روی 1000 خط ابتدای پیکره و انتخاب لغات با احتمال بیش از 0.25 و اجرای برنامه روی 50000 خط ابتدای پیکره و انتخاب لغات با احتمال بیش از0.5 آوردهشدهاند. طبیعتا هرقدر جملات بیشتری بررسی شوند و نیز هرقدر لغتنامه سختگیرانهتر ساخته شود(به عبارتی تنها لغات با احتمال همترازی بالا انتخاب شوند)، دقت بیشتر خواهد بود.
از آنجا که نتایج صحیح همترازی به صورت آماده وجود ندارد و باید دستی حساب شود، فقط دقت همین دو حالت محاسبه شده است.

| تعداد کل کلمات | تعداد کلمات صحیح | دقت |
|---|---|---|
| 34 | 3 | 0.0882 |

| تعداد کل کلمات | تعداد کلمات صحیح | دقت |
|---|---|---|
| 57 | 43 | 0.7543 |
لازم به ذکر است جهت رعایت حقوق کپی رایت پیکره میزان در گیت قرار داده نشده است.
۴. بهبود نتایج
همانطور که در فاز اول توضیح داده شد، در مدل آیبیام1 برای هر کلمه هدف، همهی ترازها هماحتمال هستند و به مکان کلمه در جمله بستگی ندارد و این ضعف در آیبیام2 برطرف شدهاست. در این فاز به پبادهسازی مدل آیبیام2 و همچنین بهبود سرعت در آیبیام1 پرداخته شدهاست.
ایجاد ایندکس روی جداول پایگاه داده و انجام پرسوجوهای انتخاب12 با استفاده از ایندکس باعث افزایش سرعت این نوع پرسوجوها و در پرسوجوهای درج13 و بهروزرسانی14 باعث کاهش سرعت میشود.[13][14] برای افزایش سرعت برنامه از این تکنیک در پرسوجوهای انتخاب، استفاده شدهاست.
در آیبیام2 نسبت به آیبیام1 تفاوت درصد تخصیصهای صحیح و ناصحیح بیشتر و نتایج دقیقتر میشود زیرا در عمل، در ترجمه، مکان کلمه هدف و مقصد در زوج جملات نزدیک به هماند و در آیبیام2 نیز احتمال همترازی در نزدیکی قطر بیشتر است. نمونهای از این تفاوت برای جملات دو فایل متنی واقع در گیتهاب در ادامه نمایش داده شدهاست.
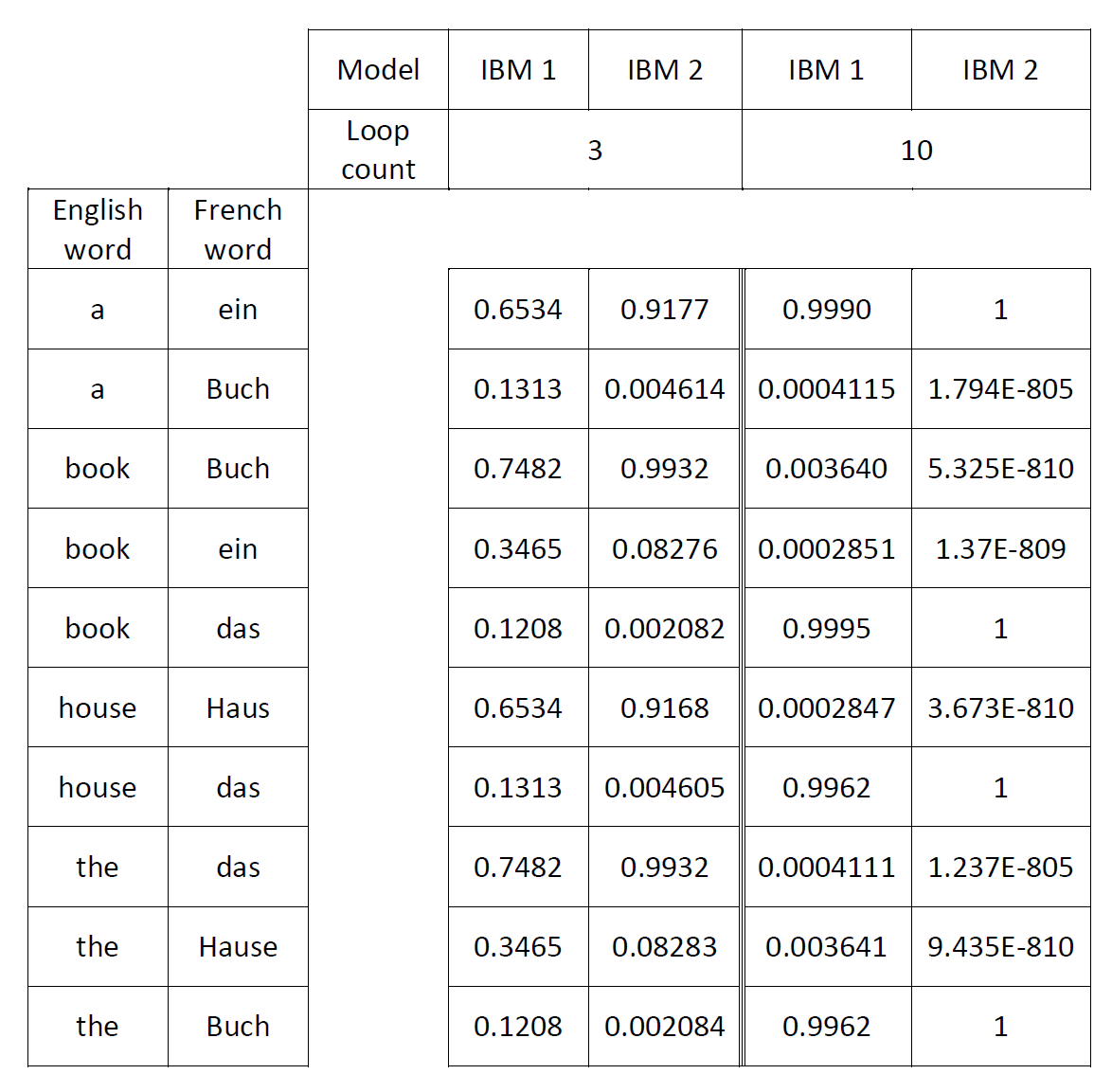
نتیجه اجرای آیبیام2 روی 1000 خط اول پیکره میزان با مقدار loop_count =1 و انتخاب همترازیهایی با احتمال بیش از 0.25 در این لینک و با loop_count =3 و انتخاب لغات با احتمال بیش از 0.8 در این لینک قرار داده شده است. دقت این دو آزمایش در ادامه محاسبه شدهاست. توجه کنید همین آزمایش برای آیبیام1 در فاز قبل، دقت 0.0882 را نتیجه داده بود.
آزمایش اول: loop_count =1 , probability >= 0.25
| تعداد کل کلمات | تعداد کلمات صحیح | دقت |
|---|---|---|
| 126 | 34 | 0.269 |
آزمایش دوم: loop_count =3 , probability >= 0.8
| تعداد کل کلمات | تعداد کلمات صحیح | دقت |
|---|---|---|
| 239 | 138 | 0.577 |
۵. کارهای آینده
پیکره میزان یک ترجمه از یک متن داستانی است، با بررسی مقالات تخصصی در زمینههای مختلف می توان لغات تخصصی و یا معانی تخصصی لغات را استخراج کرد و در پایگاه داده به نحوی این اطلاعات را ذخیره کرد(میتوان یک جدول برای هر یک از علوم بررسیشده تهیه کرد و یا ستونی به جدول اصلی اضافه کرد که به ازای هر سطر نشان دهندهی فیلدهایی است که در آنها این معنی از این کلمه استخراج میشود). انجام این کار دو حسن دارد:
استفاده در لغت نامه: در حال حاضر نرم افزازهای غیر رایگانی با این ویژگی مانند دیکشنری نارسیس وجود دارند. نارسیس 19 زمینه تخصصی مانند کامپیوتر، اقتصاد، حقوق و تجارت را پوشش میدهد.[15] هدف میتواند تولید نسخه رایگان لغت نامهای به قدرت نارسیس باشد.
استفاده در ترجمه خودکار: به کمک طبقهبندی15 مقالات و به دست آوردن فیلد متن مبدا میتوان از معانی تخصصی لغات در این فیلد و احتمالشان استفاده کرد.
۶. مراجع
[1] Tiedemann, Jorg. "Bitext alignment." Synthesis Lectures on Human Language Technologies 4.2 (2011): 1-165.
[2] Och, F.J. and Tillmann, C. and Ney, H. and others 1999, Improved alignment models for statistical machine translation, Proc. of the Joint SIGDAT Conf. on Empirical Methods in Natural Language Processing and Very Large Corpora
[3]P. F. Brown et al. 1993. The Mathematics of Statistical Machine Translation: Parameter Estimation. Computational Linguistics, 19(2):263–311.
[4]S. Vogel, H. Ney and C. Tillmann. 1996. HMM-based Word Alignment in StatisticalTranslation. In COLING ’96: The 16th International Conference on Computational Linguistics, pp. 836-841, Copenhagen, Denmark.
[5]Yarin Gal, Phil Blunsom (12 June 2013). "A Systematic Bayesian Treatment of the IBM Alignment Models" (PDF). University of Cambridge. Retrieved 26 October 2015.
[6]KNIGHT, Kevin. A statistical MT tutorial workbook. Manuscript prepared for the 1999 JHU Summer Workshop, 1999.
[7]Brunning, James Jonathan Jesse. Alignment Models and Algorithms for Statistical Machine Translation. Diss. University of Cambridge, 2010.
[8]Zamin, Norshuhani, et al. "A lazy man’s way to part-of-speech tagging." Knowledge Management and Acquisition for Intelligent Systems. Springer Berlin Heidelberg, 2012. 106-117.
[9]Collins, Michael. "Statistical machine translation: IBM models 1 and 2." Columbia: Columbia University (2011).
[10]Liu, Yang, Qun Liu, and Shouxun Lin. "Discriminative word alignment by linear modeling." Computational Linguistics 36.3 (2010): 303-339.
[11]http://www.dadegan.ir/catalog/mizan
[12]https://en.wikipedia.org/wiki/Bitext_word_alignment
[13]http://www.tutorialspoint.com/sqlite/sqlite_indexes.htm
[14]https://www.sqlite.org/queryplanner.html
[15]http://www.narcissoft.com/onlinedic.asp
corpus_based
bilingual parallel corups
word alignment
expectation-maximization algorithm (EM)
null token
viterbi alignment
IBM
fertility-based model
tablet
tableau
select queries
insert
update
classification