##**تولید گفتگو به کمک یادگیری تقویتی عمیق** ---------- **به نام خدا** #مقدمه یکی از موضوعات مهمی که در سالهای اخیر در حوزه پردازش زبانهای طبیعی[^**N**atural **L**anguage **P**rocessing (NLP)] مورد توجه قرار گرفته، سیستمهای تولید گفتگو[^Dialogue System] است. سیستمهای تولید گفتگو یا عاملهای مکالمه کننده[^**C**onversational **A**gents (CA)] مانند دستیارهای شخصی [^Personal Assistants] و رباتهای سخنگو [^Chatbots] در جامعه امروز بسیار فراگیر شده است[1]. که می توان در این حوزه به دستیار های شخصی بر روی تلفن های همراه [^همچون Siri در Apple و Cortana در Microsoft]یا ربات های آنلاین در شبکههای اجتماعی همچون تلگرام اشاره کرد. با این حال پاسخ های تولید شده توسط این عامل ها، جملات کوتاه و قابل پیش بینی هستند. دراین مقاله با استفاده از یادگیری تقویتی عمیق به تولید مدلی برای رباتهای سخنگو می پردازیم،که بتواند مشکلات ذکرشده، را رفع کرده و به تولید پاسخهای هماهنگ، منسجم و سرگرم کننده بیانجامد. این مدل، گفتگو بین دو عامل مجازی را با استفاده از سیستم پاداش و تنبیه جهت دستیابی به اهداف بلند مدت در گفتگو[^ منظور از اهداف بلند مدت سرگرم کردن کاربر، ادامه پیدا کردن مکالمه با دیالوگ های جدید، برخورد کمتر با جملات گنگ،جلوگیری از حلقه بی نهایت و غیره می باشد.]، پیاده سازی میکند[2]. این کار را می توان جز یکی از اولین قدم ها در حوزه تولید مکالمه در جهت دستیابی به اهداف بلند مدت دانست. #کارهای مرتبط تلاش های انجام شده برای ساخت سیستمهای گفتگو، را می توان به دو گروه اصلی تقسیم کرد: گروه اول در تلاش بودند،قوانینی برای نگاشت پیامهای ورودی به پاسخها، به وسیلهی مجموعه بزرگی از دادههای آموزش[^training data]، بیایند و از این طریق پاسخ مناسب هر ورودی را به دست بیاورند.(این گروه مسائل تولید گفتار را جز مسائل source-to-target transduction به حساب میآورند.) ریتر[^Ritter] و همکارانش مشکل تولید پاسخ را به عنوان یک مسئله ترجمه ماشینی [^Machine Translation]دسته بندی کردند[3]. در ادامه سوردونی [^Sordoni] سیستم ریتر را بهبود بخشید. او به جای استفاده از سیستم مکالمه بر پایه ترجمه ماشینی کلمه به کلمه[^a phrasal SMT-based(**S**tatistical **M**achine **T**ranslation) conversation system]، از شبکههای عصبی بهره برد. پیشرفت شبکههای عصبی و همچنین مدل [^LSTM sequence-to-sequence(SEQ2SEQ) model]SEQ2SEQ، منجر به تلاشهای زیادی در جهت ساخت سیستمهای مکالمه [^conversation system] شد[4]. گروه دوم بر روی ساخت سیستمهای گفتگو وظیفهگرا، برای حل مسائل در دامنههای خاص تمرکز کردند. که بیشتر این تلاشها شامل فرآیند تصمیمگیری مارکف [^**M**arkov **D**ecision **P**rocesses (MDPs)]میشود. #تعریف مسئله همانطوری که در بخش قبل ذکر شد مدل seq2seq یکی از مدل های مورد استفاده در سیستمهای تولید پاسخ است که می تواند احتمال تولید پاسخ مناسب را بیشینه کند. اما با وجود موفقیت مدل seq2seq، استفاده از آن، سبب رخداد دو مشکل میگردد. - مشکل اول : این مدل با تابع [^the **M**aximum-**L**ikelihood **E**stimation (MLE) objective function: در علم آمار برآورد درستنمایی بیشینه روشی است برای برآورد کردن پارامترهای یک مدل آماری. وقتی بر مجموعهای از دادهها عملیات انجام میشود یک مدل آماری به دست میآید آنگاه درستنمایی بیشینه میتواند تخمینی از پارامترهای مدل ارائه دهد.(در بخشهای بعدی به توضیح بیشتر آن میپردازیم)]MLE آموزش دیده است. دراین مدل احتمال پاسخ به کاربر با جملاتی مانند "I don’t know" زیاد است. اما هدف رباتهای سخنگو، سرگرم کردن کاربر است و تولید این دست از پاسخها موجب از دست دادن مخاطب میگردد. پس به پاسخهایی نیاز داریم که علاوه بر دارا بودن اطلاعات، توجه مخاطب را نیز جلب کند. - مشکل دوم : به ستون سمت راست جدول زیر توجه کنید :  یکی دیگر از مشکلات معمول در استفاده از این مدل ایجاد حلقه بینهایت برای سیستم است که سیستم توانایی شکستن این حلقه را ندارد. در قسمت بالا سمت راست جدول، سیستم در سومین دیالوگ وارد حلقه بینهایت میشود. با توجه به مشکلات بالا به مدلی نیاز داریم که به هدف [^ارتباط مفید با کاربر] رباتهای سخنگو به وسیله پاداش تعریف شده [^توسط توسعه دهنده] دست یابد و همچنین بتواند با در نظر گرفتن اثر بلند مدت[^long-term influence] یک پاسخ بر روی مکالمه جاری، از وقوع حالتهایی مانند ایجاد حلقه بینهایت بپرهیزد. # مروری بر ادبیات و مقدمات لازم ##شبکه های [^**L**ong **S**hort-**T**erm **M**emory(حافظه طولانی کوتاه-مدت)]LSTM شبکههای LSTM، نوع خاصی از شبکههای عصبی بازگشتی هستند که توانائی یادگیری وابستگیهای بلندمدت را دارند. این شبکهها برای اولین بار توسط سپ هوخرایتر[^Sepp Hochreiter] و یورگن اشمیدهوبر [^Jürgen Schmidhuber] در سال ۱۹۹۷ معرفی شدند[5]. و در سال 2000 میلادی توسط ژرس و اشمیدهوبر بهبود یافتند[6]. در حقیقت هدف از طراحی شبکههای LSTM، حل کردن مشکل وابستگی بلندمدت[^long-term dependency] بوده است. به یاد سپاری اطلاعات برای بازههای زمانی بلند مدت، رفتار پیشفرض شبکههای LSTM بوده و ساختار آنها به صورتی است که اطلاعات خیلی دور را به خوبی بخاطر میسپارند که این ویژگی در ساختار آنها نهفته است. همه شبکههای عصبی بازگشتی به شکل دنبالهای (زنجیرهای) تکرار شونده، از ماژولهای (واحدهای) شبکههای عصبی هستند. در شبکههای عصبی بازگشتی استاندارد، این ماژولهای تکرار شونده ساختار سادهای دارند، در حالی که در شبکههای LSTM ماژول تکرار شونده به جای داشتن تنها یک لایه شبکه عصبی، ۴لایه دارند که طبق ساختار ویژهای با یکدیگر در تعامل و ارتباط هستند[8،7]. 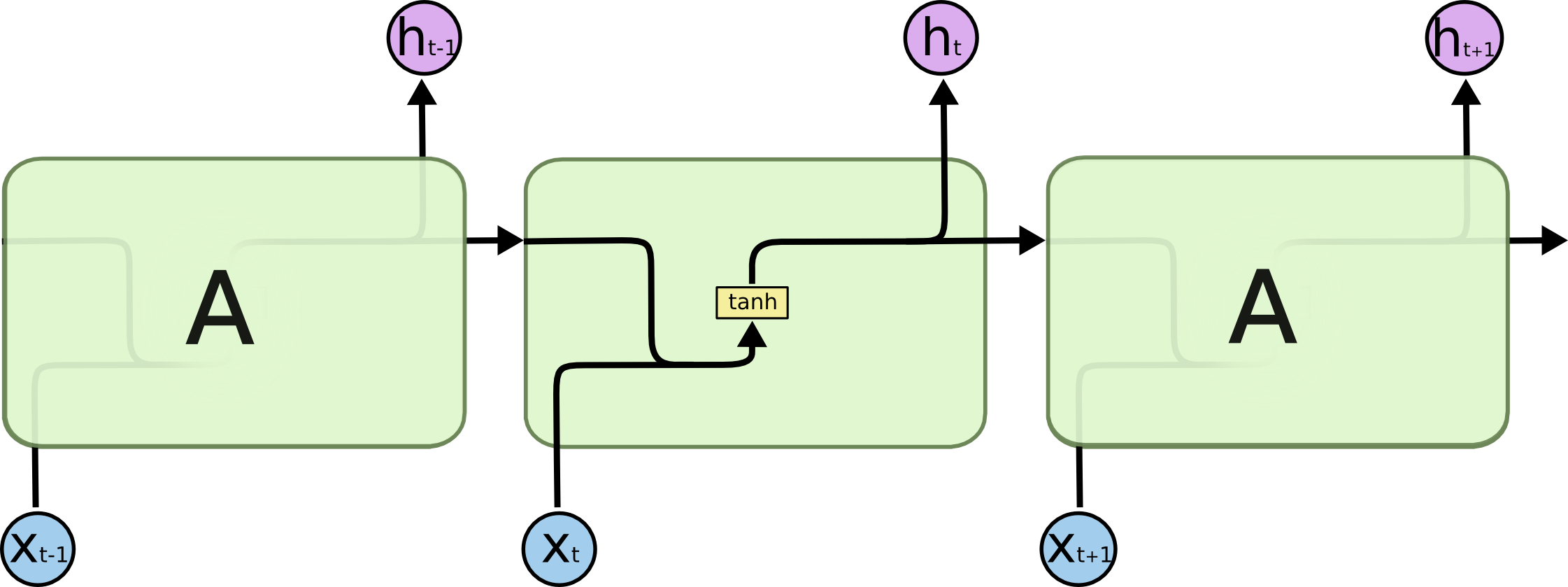 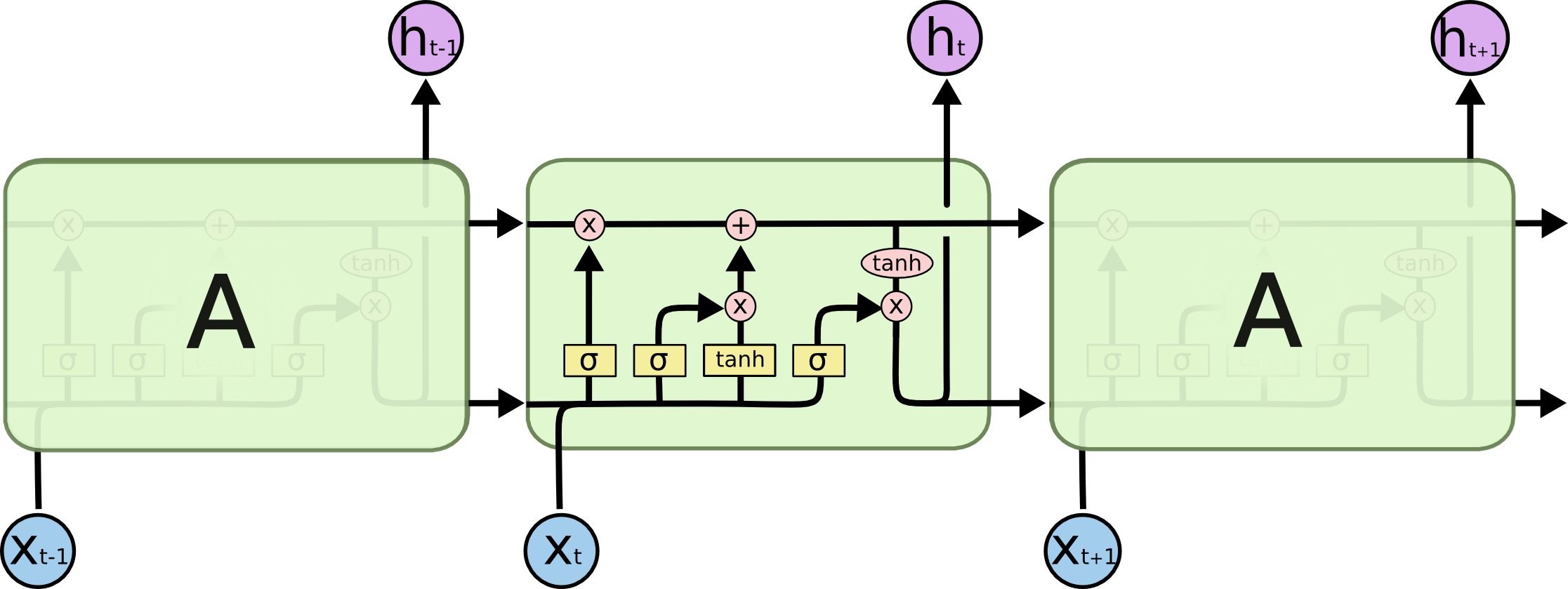 ##مدل رمزنگار-رمزگشا (توالی به توالی ) شبکه [^ Encoder-Decoder( sequence-to-sequence) LSTM]LSTM مدل رمزنگار-رمزگشا LSTM یک شبکه عصبی بازگشتی برای مسائلی است که یک دنباله را به دنباله دیگر نگاشت میکند. (یک دنباله به عنوان ورودی دریافت می کند و خروجی، دنباله دیگری است.) به همین دلیل به آن مدل seq2seq نیز گفته میشود. در مسائل seq2seq دنباله ورودی و خروجی میتوانند دارای طول های متفاوتی باشند به همین دلیل این مسائل از اهمیت زیادی برخوردار بوده و چالش برانگیزاند[9]. مدل seq2seq، در مسائلی چون ترجمه ماشینی، خلاصهکردن متن [^ Text summarization]و تشخیص گفتار[^ speech recognition] کاربرد دارد. به طور مثال در ترجمه ماشینی سنتی، جمله ها به چند قسمت تقسیم میشوند و هر قسمت به صورت جداگانه ترجمه میشود که منجر به اختلال در خروجی ترجمه میگردد. این در حالی است که انسان ها برای ترجمه یک جمله ابتدا معنای آن را متوجه میشوند سپس جمله را ترجمه میکنند. مدل seq2seq در ترجمه ماشینی از روش انسان گونهی ترجمه پیروی میکند.[10] این معماری از ترکیب دو مدل تشکیل شده است. ابتدا دنباله ورودی رمزگذاری شده و به برداری از اعداد با طول ثابت تبدیل میشود که به آن، بردار فکر[^ thought vector] گفته میشود. سپس برای رمزگشایی، بردار به دنبالهی خروجی تبدیل میشود.[10،9]  # مدل یادگیری تقویتی در این بخش به توضیح بخش های مختلف مدل مورد استفاده می پردازیم. سیستم یادگیری شامل دو عامل است. (عامل اول را p و عامل دوم q مینامیم.) عامل ها به نوبت می توانند با دیگری صحبت کنند. یک گفتگو به صورت دنبالهای از جملهها است که به وسیله هر دو عامل تولید شده و به صورت زیر نمایش داده میشود.  ## عمل عمل [^action] **a** یک صحبت یا دیالوگ است که قرار است توسط یکی از عاملها تولید شود. فضای حالت اعمال، بی نهایت است زیرا دنبالههای تولید شده طول دلخواهی دارند. ## حالت حالت [^state] به صورت دوتایی شامل** [p,q]** است که دیالوگ قبلی تولید شده توسط هر کدام از عاملها را نشان میدهد. تاریخچه گفتگو بین 2 عامل در یک بردار ذخیره میشود. ##پاداش هر پاداش از 3 بخش تشکیل میشود که در زیر به توضیح آنها میپردازیم. ###سهولت در پاسخگویی[^Ease of answering] پاسخ به دیالوگی که توسط ماشین تولید میشود باید آسان باشد.[^این جنبه از تولید کلام به تابع forward-looking مربوط می شود که در بخش بعد به توضیح آن می پردازیم.]حال میخواهیم این مقدار را اندازه بگیریم: جهت محاسبه میزان سهولت پاسخگویی، به جای محاسبه تمام حالتهایی که میتوانند جواب مناسبی داشته باشند، منفی احتمال جملاتی که باعث ایجاد گمراهی برای ماشین میشوند[^dull responses]مانند - I don’t know what you are talking about. - I have no idea. را محاسبه میکنیم. مجموعه ای از این جملات (S)را در نظر گرفته و به کمک این مجموعه و احتمالات مدل seq2seq به محاسبه پاداش (r1) میپردازیم.  ### جریان اطلاعات[^Information Flow] میخواهیم از تولید پاسخهای تکراری توسط هر عامل جلوگیری کنیم. به همین منظور میزان شباهت معنایی بین نوبتهای متوالی یک عامل را محاسبه کرده و پاداش r2، برابر منفی لگاریتم cos شباهت بین این دو عامل است.  ### هماهنگی معنایی[^Semantic Coherence] همچینین میخواهیم از حالت هایی که پاسخ ها دارای امتیاز (پاداش) بالا هستند اما از نظر معنایی هماهنگی با مکالمه بین 2 عامل ندارند پرهیز کنیم. به همین دلیل میزان اشتراک اطلاعات بین عمل انتخاب شده و دیالوگهای قبلی بیان شده در متن را بررسی میکنیم .  پاداش نهایی عملی مانند a مجموع وزندار پاداشهای معرفی شده در بخشهای قبل است. 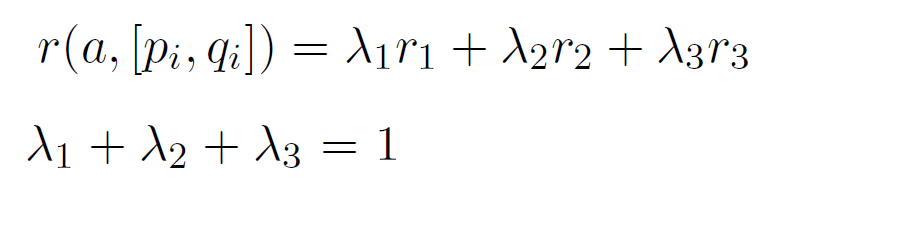 که در آن مجموع ضرایب پاداش ها 1 است. و در این مدل این ضرایب را با مقادیر زیر مقدار دهی می کنیم. 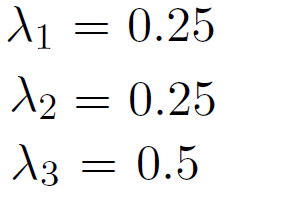 #معرفی مجموعه داده جهت پیاده سازی این کار از مجموعه داده[^Dataset] ترجمه ماشینی WMT10 کنفرانس ACL [^**A**ssociation for** C**omputational **L**inguistics]2010 دانشگاه اوپسالا سوئد [^Uppsala University, Sweden] استفاده میشود. در این مجموعه حدود 22 میلیون [^به طور دقیق 225220376] جمله به زبان انگلیسی در حوزهها و مفاهیم مختلف در ارتباط با تکنولوژی،جامعه و غیره وجود دارد. همچنین مجموعه دادههایی به زبانهای دیگر نیز در آن موجود و قابل استفاده است. مجموعه داده مورد استفاده را از [لینک](http://www.statmt.org/wmt10/training-giga-fren.tar) زیر دریافت کنید. [11] در مقاله اصلی از بخشی ازمجموعه داده سایت [Opensubtitle](http://www.opensubtitles.org/) استفاده شده است که شامل 10 میلیون پیام میباشد. که جهت اطمینان از ساده بودن مجموعه داده ورودی در پاسخگویی، 0.8 میلیون دنباله از آن استخراج شده که کمترین احتمال تولید جملاتی مانند: - i don’t know what you are taking about. به عنوان پاسخ در آن وجود داشته باشد.[12] #مراجع [1] Iulian V. Serban, Chinnadhurai Sankar, Mathieu Germain, Saizheng Zhang, Zhouhan Lin, Sandeep Subramanian, Taesup Kim, Michael Pieper, Sarath Chandar, Nan Rosemary Ke, Sai Rajeshwar, Alexandre de Brebisson, Jose M. R. Sotelo, Dendi Suhubdy, Vincent Michalski, Alexandre Nguyen, Joelle Pineau1 and Yoshua Bengio , "A Deep Reinforcement Learning Chatbot",pages 1. arXiv preprint arXiv:1709.02349. [2] Jiwei Li1, Will Monroe1, Alan Ritter, Michel Galley, Jianfeng Gao2 and Dan Jurafsky , "Deep Reinforcement Learning for Dialogue Generation" .arXiv preprint arXiv:1606.01541. [3] Alan Ritter, Colin Cherry, and William B Dolan. 2011. Data-driven response generation in social media. In Proceedings of the conference on empirical methods in natural language processing, pages 583–593. Association for Computational Linguistics. [4] Iulian V Serban, Alessandro Sordoni, Yoshua Bengio, Aaron Courville, and Joelle Pineau. 2015a. Building end-to-end dialogue systems using generative hierarchical neural network models. arXiv preprint arXiv:1507.04808. [5] Sepp Hochreiter, Jürgen Schmidhuber. "Long Short-Term Memory",1997. [6] Felix A. Gers , Jürgen Schmidhuber. "Recurrent Nets that Time and Count", IDSIA, 2000. [7] Understanding LSTM Networks, [Online], Available: http://colah.github.io/posts/2015-08-Understanding-LSTMs/#fn1 [Accessed Nov 2017]. [8] LSTM یادگیری شبکه های , [Online], Available: http://mehrdadsalimi.blog.ir/1396/02/25/Understanding-LSTM-Networks [Accessed Nov 2017]. [9] Encoder-Decoder Long Short-Term Memory Networks, [Online], Available: https://machinelearningmastery.com/encoder-decoder-long-short-term-memory-networks/ [Accessed Nov 2017]. [10] tensorflow neural machine translation tutorial, [Online], Available: https://github.com/tensorflow/nmt [Accessed Nov 2017]. [11] ACL 2010 Joint Fifth Workshop on Statistical Machine Translation and Metrics MATR Uppsala, Sweden, [Online], Available : http://www.statmt.org/wmt10/ [Accessed Nov 2017]. [12] OpenSubtitle corpus, [Online] , Available : http://opus.nlpl.eu/OpenSubtitles.php [Accessed Nov 2017].