عنوان
تشخیص بیماری قلبی
۱. مقدمه
شاید بتوان تشخیص بیماریها با استفاده از الگوریتمهای هوش مصنوعی را مفیدترین و صلحآمیزترین کاربرد هوش مصنوعی تاکنون دانست. هوش مصنوعی کامپیوترها، میتواند حتی قبل از پزشکان، به تشخیص تعدادی از بیماریها کمک کند اما تشخیص و تایید نهایی از جانب خود پزشک است. تشخیص برخی از بیماریها ساده است و هر پزشکی میتواند با یک معاینه و شرح حال مختصر از عهده آن برآید. اما برای تشخیص تعداد دیگری از بیماریها، تیزهوشی پزشک، یک استنتاج قوی ذهنی و آزمایشات دقیق لازم است. تعدادی از بیماریها هم طوری هستند که به سبب ماهیت زیرپوستی و تدریجی خود، غالبا خیلی دیر تشخیص داده میشوند. از فعالیتهای در این موضوع میتوان سرویسFace2Gene1 و ابزارهایی برای تشخیص بیماریهایی نظیر اوتیسم2 و آلزایمر یا زوال عقل3 را نام برد.[1]
در این بین بیماریهای قلبی – عروقی (CAD) رتبه نخست علت مرگ و میر در جهان را به خود اختصاص داده و بیشتر مردم دنیا هر ساله بیشتر از هر علت دیگری جان خود را به علت بیماریهای قلبی و عروقی از دست میدهند، طبق برآورد صورت گرفته ۱۷.۵ میلیون نفر در جهان در سال ۲۰۱۲ بعلت بیماریهای قلبی عروقی فوت نمودهاند که ۳۱ درصد از کل موارد مرگ و میرها را شامل میشود، از این مرگها حدود ۷.۴ میلیون به بیماری عروق کرونر قلب و ۶.۷ میلیون ناشی از سکته های قلبی و مغزی بوده است. [2]
ما در این پروژه میخواهیم با زدن الگوریتمهای داده کاوی و یادگیری ماشین بر روی دادههای دانشگاه ایرواین به تشخیص بیماری قلبی بپردازیم.
دادهکاوی4 به مفهوم استخراج اطلاعات نهان یا الگوها و روابط مشخص در حجم زیادی از دادهها در یک یا چند بانک اطلاعاتی بزرگ است. داده کاوی پیشرفت قابل ملاحظهای را در نوع ابزارهای تحلیل موجود نشان میدهد اما محدودیتهایی نیز دارد. یکی از این محدودیتها این است که با وجود اینکه به آشکارسازی الگوها و روابط کمک میکند اما اطلاعاتی را دربارهٔ ارزش یا میزان اهمیت آنها به دست نمیدهد. دومین محدودیت آن این است که با وجود توانایی شناسایی روابط بین رفتارها یا متغیرها لزوماً قادر به کشف روابط علت و معلولی نیست. موفقیت داده کاوی در گرو بهرهگیری از کارشناسان فنی و تحلیل گران کار آزمودهای است که از توانایی کافی برای طبقهبندی تحلیلها و تغییر آنها برخوردار هستند. تواناییهای فنی در داده کاوی از اهمیت ویژهای برخوردار اند اما عوامل دیگری نیز مانند چگونگی پیادهسازی و نظارت ممکن است نتیجه کار را تحت تأثیر قرار دهند پس در این آزمایش هوشمندی کد علاوه بر الگوریتمهای به کار بردهشده از اهمیت خوبی برخوردار است.[3]
ده الگوریتم برتر دادهکاوی بیان شده در یک مقاله[10] سی4.55, خوشهبندی کی-میانگین6, ماشین بردار پشتیبانی7, الگوریتم آپریوری8, الگوریتم امید ریاضی–بیشینه کردن9, پیجرنک10, آدابوست11, الگوریتم کینیرست12, الگوریتم کلاسهبندی نایوبیزین13 و الگوریتم کارت14 اند. کلاسهبندی یا دسته بندیها به دو منظور استفاده میشوند: مدلهای توصیفی و مدلهای پیشبینی کننده.
به طور کلی در مقالهای[11] به بررسی خلاصه کارها و الگوریتمهای استفاده شده دادهکاوی در زمینه پزشکی پرداخته است.
اکنون به بررسی تعدادی از کارهایی که تا کنون در این موضوع انجام شدهاند میپردازیم.
۲. کارهای مرتبط
در مقالهای [4] مراحل این تحقیق را پیدا کردن دادههای آموزشی, اعمال الگوریتمها بر روی آن, بهدستآوردن مدل و در نهایت ارزیابی مدل یافتشده معرفی کردهاست. سپس با اعمال سه الگوریتم درخت تصمیم15 جی4816, درخت لجیستیک17 و جنگل تصادفی18 و مقایسه آنها مشاهده شد که الگوریتم جی48 حساسیت و دقت بالاتری نسبت به بقیه دارد که در کل با اعمال هرس کم کننده خطا19 بهتر از دو درخت دیگر جواب میدهد. در آخر با جی48 به 56.76 درصد دقت رسیده است.
از کارهای مهم برای دادهکاوی انتخاب ویژگیهای مناسب برای تحلیل است به خصوص زمانی که بخواهیم کلاس بندی انجام بدهیم. مقالهای[5] در این موضوع به بررسی نتایج با دو روش انتخاب ویژگیها بر اساس قوانین کامپیوتری20 یا CFS و انتخاب بر اساس معیارهای پزشکی21 یا MFS پرداختهاست. معیار گرفتن هر کدام از این روشها به تنهایی ممکن است باعث رسیدن به نتایج اشتباه بشود پس اعمال هر دو روش ضروری است. این مقاله هم مانند بقیه موارد تنها 14 مورد نامبردهشده در قسمت قبل را استفاده کرده است. دادههای ما یک برای بخش افراد سالم و چهار بخش برای افراد ناسالم دارد که در این مقاله پیشنهاد شدهاست که چهار گروه ناسالم را یک گروه در نظر بگیریم. سپس نتایج بهدستآمده روی متغیرهایی که با دو معیار بالا انتخاب شدهاند در دو حالت همهی متغیرها و تنها متغیرهای پیوسته را مقایسه کرده که دقت, حساسیت و کاملیت در حالت تنها متغیرهای پیوسته بهتر و بیشتر بودهاند. این موضوع را میتوان اینگونه توجیح کرد که متغیرهای گسسته مثل جنسیت از ابتدا یکسان بودهاند اما متغیر سن با گذر زمان تغییر میکند و امکان تغییر احتمال ابتلا به بیماریهای قلبی را افزایش میدهد. در این مقاله و اکثر مقالات دیگر کلاسه بندی اسویام را روش خوبی برای دستهبندی نامبردهاند که در این مقاله از راه بهینهسازی متوالی کمینه22
برای اسویام استفاده کردهاست.
متغیرهای انتخابی این مقاله در جدول زیر قابل مشاهدهاند:
از دیگر روشهای نام برده شده انتخاب ویژگیها در این مقاله میتوان به موارد زیر اشاره کرد:
روش حذفی عقبگردی23 [6]
روش انتخاب ویژگی پوشش کننده با استفاده از چیاسکوئر24[7]
استفاده همزمان از چیاسکوئر و گین رشیو25 برای انتخاب ویژگیهای مناسب[8]
روش کرنل اف-اسکور26[9]
در مقالهای دیگر [12] ویژگیها به سه دستهی مفید, تکراری و غیر مفید تقسیمبندی شدهاند . در این مقاله از روشهای پیسیای27 و چیاسکوئر تست برای انتخاب ویژگیها استفادهشدهاست. روش پیسیای در تشخیص چهره, تشخیص الگو, مقایسه تصاویر و دادهکاوی کاربرد دارد. مراحل این روش به شرح زیراند:
فراهم سازی ماتریس ورودیها
کم کردن میانگین در همهی ابعاد
بهدستآوردن ماتریس کواریانس از نتیجهی مرحلهی قبل
بهدست آوردن مقدارویژه و بردار ویژه
ساختن وکتوری از ویژگیها
استخراج پایگاهدادهی جدید
T \big(v\big) = \lambda v
تست چیاسکوئر تستی برای تشخیص ویژگیهای مرتبط و مفید است. فرمول چیاسکوئر در زیر قابل مشاهده است.
متغیر oتکرار رویت شده و Eتکرار مورد انتظار است
x_{r} ^{2} = \frac{ \sum_.^. ( O_{i} - E_{i} )^{2} }{ E_{i}}
در این مقاله روش شبکههای عصبی همراه با الگوریتمهای انتخاب ویژگی بالا امتحان شدهاست. شبکههای عصبی به سه قسمت ورودی, قسمت نهان و خروجی تقسیم میشوند. کار اصلی شبکههای عصبی پیشبینی است. از فواید شبکههای عصبی نامبردهشده در این مقاله موارد زیر را میتوان مطرح کرد:دقت بالا
مستقل از پراکندگی داده
سازگاری با نویز
نگهداری آسان
قابل پیاده سازی در سختافزارهای موازی
مورد دیگر بررسی شده در این مقاله الگوریتم جست و جوی ژنتیک28است. از این الگوریتم به منظور پیدا کردن زیرمجموعهای از ویژگیها با دقت بالا استفادهشده.

در نهایت الگوریتم پیشنهادی ارائه شدهی این مقاله ابتدا الگوریتمهای کم کردن ویژگی و بعد از آن پیادهسازی الگوریتم شبکههای عصبی روی ویژگیهای بهدستآمده است که در مقایسه با روشهای جی48, ناییوبیزین و پارت (PART) دقت بالاتری داشتهاست.
برای بخشی از روشهای دیگر استفاده شده به طور خلاصه میتوان موارد زیر را نامبرد:
استفاده از سه الگوریتم ناییوبیزین, کینیرست و دیال (Decision List algorithm) در [13]
سیستم IHDPS با استفاده از درخت تصمیم, ناییوبیزین و شبکههای عصبی در [14]
الگوریتم بر پایهی گراف در [15]
یادگیری قانون وابستگی29 به همراه الگوریتم ژنتیک در [16]
کلاسه بندی وابسته وزندار 30 در [17]
۳. آزمایشها
در این بخش ابتدا به بررسی دادههای پایگاهدادهی خود میپردازیم.
۳.۱. بررسی دادهها
اولین و از مهمترین مراحل این آزمایش بعد از شناخت مسئله را میتوان شناخت پایگاه دادهی خود دانست. یکی از عوامل تاثیر گذار در نتیجه کیفیت دادههاست که بر میزان دقت و کامل بودن آن دلالت دارد. [3] پایگاهداده دانشگاه ایرواین دارای 76 متغیر برای 303 بیمار است که در تمام کارهای تا به حال انجام شده روی آن فقط 14 متغیر آن مورد استفاده قرارگرفتهاند.این متغیرها عبارتاند از:
سن
جنسیت (0 برای خانمها و 1 برای آقایان)
نوع درد قفسه سینه
فشار خون در حال استراحت (Trestbps)
میران کلسترول
قندخون ناشتا (0 برای کمتر از 120 و 1 برای بیشتر از 120 )
نتایج الکتروکاردیوگرافی (Restecg سه مقدارnorm برای نرمال,abn برای غیر نرمال و hyp هاپرتروپی بطن چپ )
بیشینه میزان ضربان قلب (Thalach)
آنژین ناشی از ورزش داشته است یا خیر؟ (Exang)
استی ورزش مرتبط با استراحت
شیب قسمت استی (صعودی, نزولی و بدون شیب)
تعداد رگهای رنگی در فلوروسکوپی (ca بین 0 تا 3)
وضعیت قلب در تست تالیم
وضعیت (0 برای سالم 1 تا 4 برای نا سالم)
برای بخش آزمایش ما از این 14 متغیر استفاده کردهایم
۳.۲. ابزار
ابزار مورد استفادهی ما برای این آزمایش یکی از بستههای زبان برنامهنویسی پایتون به نام سایکیت [18] است.
۳.۳. تئوری روشهای استفاده شده
در این بخش سعی بر این شده که روشهای گوناگون مورد بررسی قراربگیرند و آزمایش شود که کدامیک از این روشها بهترین مدلسازی را ارائه میدهند.
۳.۳.۱. شبکههای عصبی
یکی از روشهای یادگیری تحت نظارت (supervised learning) شبکه عصبی MLP با یادگیری یک تابع به شکل زیر با گرفتن ویژگیهای ورودی خروجی یا خروجیهای مربوطه را پیشبینی میکند.
که m و o به ترتیب تعداد بعدهای ورودی و خروجی اند.
شبکههای عصبی میتوانند یک تابع تخمین غیر خطی برای کلاسهبندی یا رگراسیون بیاموزد. تفاوت آن با رگراسیون در این است که بین لایهی ورودی و لایهی خروجی یک یا تعداد زیادی لایه وجود داشتهباشد که به آن لایهها لایههای مخفی میگویند.
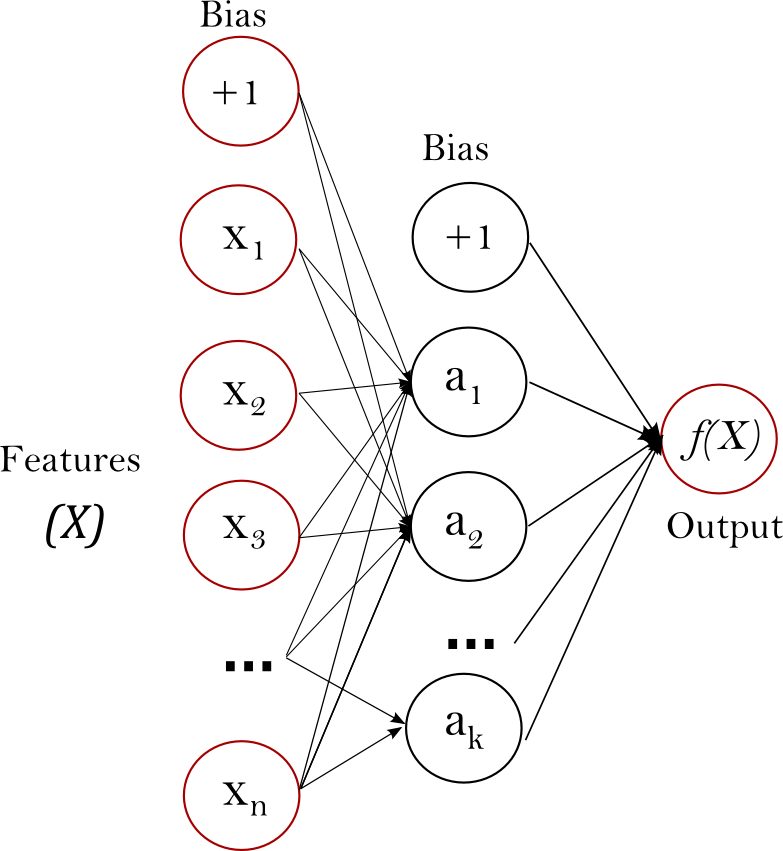
شبکههای عصبی یک مجموعه از ویژگیها ملقب به نورونها را به عنوان ورودی میدهد هر نورون با یک جمع وزندار مقدار ورودی از لایه قبل را تبدیل میکند. لایهی خروجی, خروجی اخرین لایهی نهان را گرفته و به خروجی تبدیل میکند که این خروجی ئیشبینی شبکه عصبی از ورودیهاست.
ویژگیهای مثبت شبکهعصبی:
توانایی آموختن مدلهای غیر خطی
توانیی آموختن مدلها در زمان حقیقی (real time) با استفاده از partial_fit
ویژگیهای منفی شبکهعصبی:وزنهای متفاوت ورودی باعث تغییر در دقت خروجی پیشبینیشده میشود (به دلیل بیشینههای محلی)
باید مقدارهایی برایش از ابتدا مشخص باشند مثل تعداد نورونها و لایههای پنهان
به scale ویژگیها حساس است
۳.۳.۲. ماشین بردار پشتیبانی
ماشین بردار پشتیبانی (SVM) یکی از روشهای یادگیری بانظارت است که از آن برای طبقهبندی و رگرسیون استفاده میکنند. این روش روشی جدید و با کارایی خوب است. مبنای کاری دستهبندی کنندهی SVM دستهبندی خطی دادهها است. در تقسیم خطی دادهها سعی میکنیم خطی را انتخاب کنیم که حاشیه اطمینان بیشتری داشته باشد. قبل از تقسیمِ خطی برای اینکه ماشین بتواند دادههای با پیچیدگی بالا را دستهبندی کند دادهها را به وسیلهٔ تابعِ phi به فضای با ابعاد خیلی بالاتر میبریم. برای اینکه بتوانیم مسئله ابعاد خیلی بالا را با استفاده از این روشها حل کنیم از قضیه دوگانی لاگرانژ برای تبدیلِ مسئلهٔ مینیممسازی مورد نظر به فرم دوگانی آن که در آن به جای تابع پیچیدهٔ phi که ما را به فضایی با ابعاد بالا میبرد، تابعِ سادهتری به نامِ تابع هسته که ضرب برداری تابع phi است ظاهر میشود استفاده میکنیم. از توابع هسته مختلفی از جمله هستههای نمایی، چندجملهای و سیگموید میتوان استفاده نمود.[19]
ویژگیهای مثبت :
بهینه برای فضاهای با ابعاد زیاد
بهینه برای تعداد ابعاد بزرگتر از تعداد نمونهها
بهینه از نظر مصرف حافظه
قابلیت استفاده از تابع هستههای متنوع از قبل تعریف شده و تابع هستههای دلخواه کاربر
همانند شبکههای عصبی در بیشینههای محلی به مشکل برنمیخورد
ویژگیهای منفی:
قابلیت محاسبه مستقیم تخمین احتمال را ندارد
نیاز به تابع هسته خوب دارد
در این آزمایش ما از linear SVC, RBF SVC , sigmoid SVC و SVR استفاده کردیم که linear SVC, RBF SVC , sigmoid SVC در بخش کلاسهبندی و SVR در بخش رگرسیون هستند.

تابع هستههای مختلف به صورت زیرند:
linear :
polynomial:
rbf:
sigmoid:
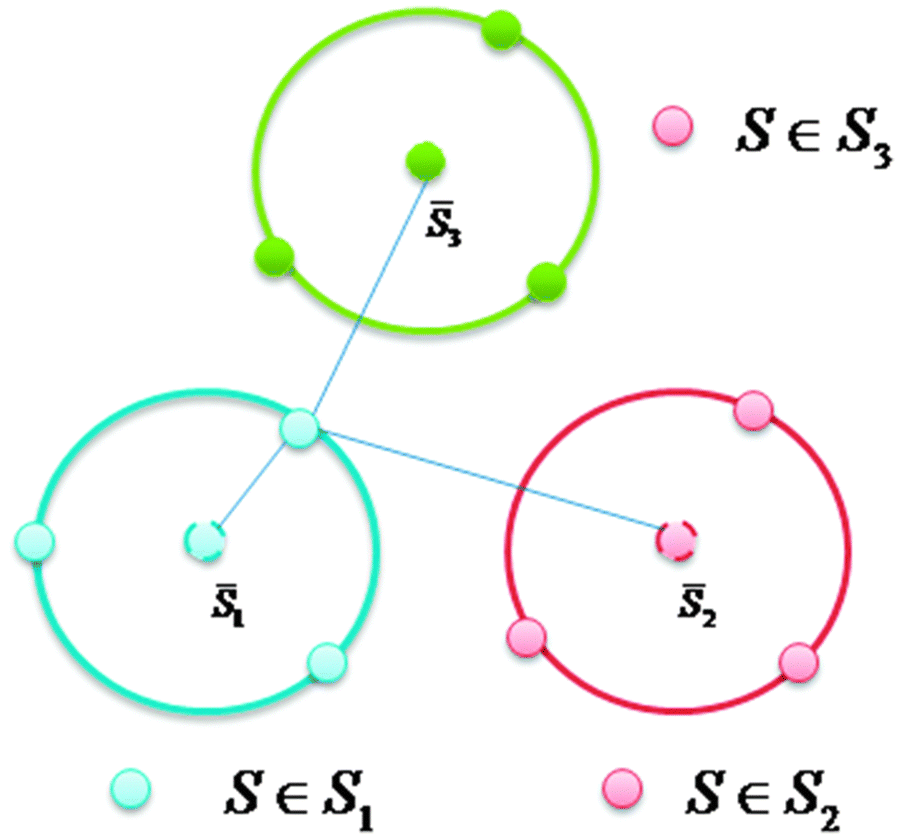
۳.۳.۳. نزدیکترین طبقه بندی ثقل
نزدیکترین طبقه بندی ثقل (Nearest Centroid Classifier) هر کلاس را با مرکز ثقل (میانه) اعضای آن کلاس بیان میکند.
ویژگیهای مثبت:
نیاز به انتخاب موردی ندارد
بهروز رسانی برچسب (از مراحل الگوریتم KMeans) را سادهتر میکند
ویژگیهای منفی:
کلاسهای غیر محدب
۳.۳.۴. دستهبندیکننده بیز ساده
دستهبندیکننده بیز ساده گروهی از دستهبندیکنندههای ساده بر پایه احتمالات و یکی از روشهای یادگیری بانظارت است. بهطور ساده روش بیز روشی برای دستهبندی پدیدهها، بر پایه احتمال وقوع یا عدم وقوع یک پدیدهاست.
فرمول بیز با استفاده از فرض استقلال ساده :
در این آزمایش ما از بیز سادهی گاسین استفاده کردیم که فرمول آن به صورت زیر است:
مقدار سیگما و میو توسط شباهت بیشنه (maximum likelihood) تخمین زدهمیشوند.
ویژگیهای مثبت:
از نظر محاسباتی سریع
پیادهسازی آسان
با ابعاد بالا خوب کار میکند
ویژگیهای منفی:
فرضیاتی دارد که اگر نقض شوند بد عمل میکند[20]
۳.۳.۵. درخت تصمیم و رگراسیون درخت تصمیم
درخت تصمیم از روشهای یادگیری بانظارت است که برای کلاسهبندی و رگرسیون استفاده میشود. هدف آن تشخیص کلاس متغیر هدف با استفاده از یکسری قوانین استخراج شده از دادههاست. این قوانین به صورت اگر شرط آنگاه و در غیر اینصورت آنگاه هستند.
ویژگیهای مثبت:
ترجمه آسان
آمادهسازی کمی برای دادهها لازم دارد
قادر به کار با دادههای عددی و غیر عددی است
میتواند مسائلی با چند خروجی را حل کند
قابل آزمودن است
ویژگیهای منفی:
ممکناست درختهای پیچیدهای خروجی دهند
سربار دارد
میتوانند ناپایا باشند
۳.۴. نتایج آزمایش
تمام روشهای توضیح دادهشده در بخش قبل را روی 14 ویژگی منتخب با استفاده از سایکیت پایتون پیادهسازی کردیم کدها از گیتهاب قابل مشاهدهاند.
نتایج را در دو حالت که در اولی بیمار بودن یا سالم بودن به صورت دودویی (بولین) و در دومی 0 به معنای سالم و 1تا4 بیمار در نظر گرفتهشدهاست.
| روش: | score | recal | precission |
|---|---|---|---|
| شبکه عصبی | 0.97 | 0.5 | 0.48 |
| SVR | 0.93 | 0.48 | 0.48 |
| linearSVC | 0.84 | 0.43 | 0.48 |
| rbfSVC | 0.94 | 0.48 | 0.48 |
| sigmoidSVC | 0.03 | 0.5 | 0.01 |
| nearest centroid | 0.96 | 0.5 | 0.48 |
| gaussian naive bayes | 0.89 | 0.46 | 0.48 |
| Decision Tree | 0.69 | 0.68 | 0.52 |
| D-Tree Regression | 0.64 | 0.65 | 0.52 |
جدول بالا و نمودار زیر برای حالت بولین در نظر گرفتهشدهی بیماری قلبی است.

سپس برای حالت دوم نتایج را از روی نمودار زیر میبینیم

همانطور که قابل مشاهده است در حالت اول شبکههای عصبی و در حالت دوم بیز ساده گاسین بهتر عمل کردهاست.
۴. کارهای آینده
برای کارهای آینده میتوان الگوریتمهای مربوط به گرفتن قسمت آموزشی و تستی همانند تن فولد (ten fold) و الگوریتمهای انتخاب ویژگی را نیز امتحان کرد. زیرا برای مثال تمام آزمایشهای انجام شده تا کنون از این 14 ویژگی استفاده مردهاند اگر بقیهی ویژگیها هم بررسی شود بهتر است.
۵. مراجع
[1] blog.shafadoc.ir/tag
[2] parsine.com
[3] en.wikipedia.org/wiki/Datamining
[4]Heart Disease Prediction Using Machinelearning and Data Mining TechniqueJaymin Patel, Prof.TejalUpadhyay, Dr. Samir Patel
[5]A Knowledge driven Approach for Efficient Analysis of Heart Disease Dataset G. N. Beena BethelAssociate Professor,CSE Department,GRIET, Hyderabad T. V. Rajinikanth, PhDProfessor,CSE Department,SNIST, Hyderabad. S. Viswanadha Raju, PhDProfessor,CSE Department,JNTUH, Jagityal, Karimnagar.
[6]Zhao, H., Guo, S., Chen, J., Shi, Q., Wang, J., Zheng,C., et al. (2010). Characteristic pattern study of coronaryheart disease with blood stasis syndrome based ondecision tree. In 4th international conference onbioinformatics and biomedical engineering (iCBBE)(pp. 1–3). Chengdu, China: IEEE
[7]Abraham, R., Simha, J. B., & Iyengar, S. (2007).Medical datamining with a new algorithm for featureselection and Naı¨ve Bayesian classifier. In 10thinternational conference on information technology,(ICIT), 2007 Orissa IEEE computer society (pp. 44–49).
[8]Sethi, P., & Jain, M. (2010). A comparative featureselection approach for the prediction of healthcarecoverage. Information Systems, Technology andManagement, 392–403.
[9]Polat, K., & Guenes, S. (2009). A new feature selectionmethod on classification of medical datasets: Kernel Fscore feature selection. Expert Systems withApplications, 36, 10367–10373
[10]Top 10 algorithms in data mining Xindong Wu · Vipin Kumar · J. Ross Quinlan · Joydeep Ghosh · Qiang Yang · Hiroshi Motoda · Geoffrey J. McLachlan · Angus Ng · Bing Liu · Philip S. Yu · Zhi-Hua Zhou · Michael Steinbach · David J. Hand · Dan Steinberg
[11]A Survey of Data Mining Techniques on Medical Data for Finding Locally Frequent Diseases Mohammed Abdul Khaleel*Sateesh Kumar Pradham G.N. Dash Research Scholar P.G.Department of Computer Science P.G.Department of Physics Sambalpur University, India Utkal University, India Sambalpur University, India
[12]Classification of Heart Disease using Artificial Neural Networkand Feature Subset Selection M. Akhil Jabbar, B.L Deekshatulu & Priti Chandra
[13]Asha Rajkumar, G.Sophia Reena, Diagnosis Of Heart Disease Using Datamining Algorithm, Global Journal of Computer Science andTechnology 38 Vol. 10 Issue 10 Ver. 1.0 September 2010.
[14]Sellappan Palaniappan Rafiah Awang, Intelligent Heart Disease Prediction System Using Data Mining Techniques, IJCSNSInternational Journal of Computer Science and Network Security, VOL.8 No.8, August 2008
[15]MA. Jabbar, B.L Deekshatulu, Priti Chandra, “Graphbased approach for heart disease prediction”, LNEEpp 361-369 Springer Verlag 2012
[16]MA.Jabbar, B.L Deekshatulu, Priti Chandra, “Anevolutionary algorithm for heart disease prediction”,CCIS pp 378-389springer Verlag(2012)
[17]Intelligent and Effective Heart Disease Prediction System using Weighted Associative Classifiers Jyoti Soni, Uzma Ansari, Dipesh SharmaComputer ScienceRaipur Institute of Technology, RaipurC.G., IndiaSunita SoniComputer ApplicationsBhilai Institute of technology, BhilaiC.G., India
[18]http://scikit-learn.org/stable/
[19]https://fa.wikipedia.org/wiki/%D9%85%D8%A7%D8%B4%DB%8C%D9%86%D8%A8%D8%B1%D8%AF%D8%A7%D8%B1_%D9%BE%D8%B4%D8%AA%DB%8C%D8%A8%D8%A7%D9%86%DB%8C
[20]https://github.com/ctufts/Cheat_Sheets/wiki/Classification-Model-Pros-and-Cons
۶. پیوندهای مفید
میتواند نیمی از هشت هزار بیماری ژنتیکی را با تحلیل الگوهای چهره و مقایسه با عکسهای بیماران در پایگاه اطلاعاتی خود تشخیص بدهد
Autism( RightEye GeoPref Autism آزمایشی به نام )
Alzaymer (Winterlight ابزار شرکت )
Data mining
C4.5
k-means clustering
Support vector machine
Apriori algorithm
EM algorithm
Page rank
AdaBoost
k-nearest neighbors algorithm
Naive Bayes classifier
CART:Classification and Regression Trees
Decision tree
J48
Logistic Model Tree
Random Forest
ReducedErrorPruning
Computerized Feature Selection
Medical Feature Selection
Sequential minimal optimization
backward elimination
Wrapper based feature selection using Chi-square
Gain ratio
Kernel F-score
PCA
Genetic Search
association rule mining
Weighted Associative Classifier(WAC)