یکی از کاربردهای مهم پردازش گفتار، یافتن کلمات کلیدی در گفتار است. به عنوان مثال یک پایگاه داده از صداهای ضبط شده را در نظر بگیرید. فرض کنید بخواهیم در این گفتارها به دنبال مجموعه ای از واژه های کلیدی بگردیم. در این صورت باید از الگوریتم های واژهیابی گفتار استفاده کنید. یکی از مقال هایی که این الگوریتم می تواند در آن جا مورد استفاده قرار گیرد، گفتارهای ضبط شده در یک کلاس درس است. مثلا فرض کنید که _گفتارهای درس مدارهای الکتریکی_ضبط شده باشد و ما می خواهیم بدانیم در کدامیک از قسمت های این مجموعه در مورد کلمه کلیدی _دیود_ صحبت شده است.
# مقدمه
امروزه پردازش گفتار تقریبا در همه ی جنبه های زندگی ما نفوذ کرده. از گوشی و ساعت های هوشمند گرفته تا مباحث نظامی و امنیتی، همه جا نشانه ای از حضور تکنولوژی پردازش گفتار دیده می شود. [1]
اما این مباحث دهه هاست که در حوزه ی دانشگاهی مورد بررسی هستند، پس چرا در سال های اخیر اسم آن اینقدر بر سر زبان ها افتاده است؟ دلیل آن این است که اخیرا شاخه ی جدید از هوش مصنوعی به نام یادگیری عمیق توانسته است پردازش گفتار را به اندازه ای دقیق کند که خارج از محیط های کنترل شده هم بتوان از آن استفاده کرد.
استاد دانشگاه استنفورد و بنیان گذار سایت کورسرا، Andrew Ng پیش بینی کرده است که تا زمانی که دقت پردازش گفتار از 95 درصد به 99 درصد می رسد، اصلی ترین راه برای ارتباط برقرار کردن با کامپیوتر می شود. این فاصله ی 4 درصدی ، در واقع تفاوت میان "به طور آزاردهنده ای غیرقابل اعتماد" و "بسیار مفید" است که به لطف هوش مصنوعی و خصوصا یادگیری عمیق، آنقدری طول نمی کشد که بشر به این دقت می رسد.
درین بخش ما انحصارا به استخراج و جستجوی کلمات کلیدی در گفتار می پردازیم. گفته می شود آژانش امنیت ملی آمریکا مکالمات افراد بسیار زیادی را شنود کرده و به کار رفتن عبارات خاصی در متن مکالمه را بررسی می کند! [2] از کاربرد های امنیتی این موضوع که بگذریم این حوزه در جنبه های دیگر نیز کاربرد های فراوانی دارد.
# شرح مسئله و کارهای مرتبط
**هدف مسئله:** هدف ما همانطور که در بخش چکیده گفته شده است، پیدا کردن روشی برای استخراج و جستجوی کلمات به کار رفته در یک فایل صوتی می باشد. برای این منظور ما از هوش مصنوعی و شاخه های متنوع آن کمک خواهیم گرفت.
**شرح مسئله و راهکار هاکاروف ، Dinamic Time Wrapping ، شبکه های عصبی ، یادگیری عمیق و ... [3]
# آزمایشها
# کارهای آینده
# مراجع
[1] : https://medium.com/@ageitgey/machine-learning-is-fun-part-6-how-to-do-speech-recognition-with-deep-learning-28293c162f7a
[2] : https://www.theguardian.com/technology/2015/feb/20/mobile-phones-hacked-can-nsa-gchq-listen-to-our-phone-calls
[3] : Anusuya, M. A., and Shriniwas K. Katti. "Speech recognition by machine, a review." arXiv preprint arXiv:1001.2267 (2010
# پیوندهای مفید
+ [کتابخانه پردازش گفتار](http://kaldi.sourceforge.net/)رکوف ، Dynamic Time Warping ، شبکه های عصبی ، یادگیری عمیق و متد های دیگر که به شرح مهم ترین و پرکاربرد ترین آنها می پردازیم[1]
##مدل مخفی مارکوف:
مدل مخفی مارکوف یک سری متناهی از حالتهاست، که با یک توزیع احتمال پیوسته است. در یک حالت خاص، توسط توزیع احتمال پیوسته یک خروجی یا مشاهده می تواند بدست اید. حالات از خارج مخفی هستند از این رو مدل مخفی مارکوف نامیده شده است. مدل مخفی مارکوف، یک مدل آماری است که در آن پارامترهای مخفی را از پارامترهای مشاهده شده مشخص می نماید.پارامترهای بیرون کشیده شده برای آنالیزهای بعدی می توانند استفاده شوند.به عنوان مثال برای دستور العمل های بازشناسی الگو. در مدل مارکوف معمولی،وضعیت به طور مستقیم توسط مشاهده گر قابل مشاهده است.بنابراین حالت انتقال احتمالات تنها پارامترها هستند.در مدل مخفی مارکوف ، وضعیت به طور مستقیم قابل مشاهده نیست، اما متغییرهای تحت تاثیر با وضعیت قابل مشاهده هستند.هر حالت یک توزیع احتمالات دارد برای خروجی ممکن که گرفته شود.بنابراین ترتیب گرفته های ایجاد شده توسط HMM اطلاعاتی در رابطه با حالت توالی میدهد.
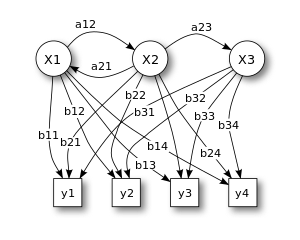
**پارامترهای اصلی مدل مارکوف**
+ مجموعه حالتهایی که ممکن است اتفاق بیفتد.
+ مجموعه تصمیماتی که میتوان در حالتهای مختلف گرفت.
+ مجموعه نتایجی که ممکن است متعاقب هر تصمیمگیری بدست آید.
+ منافع و ارزش افزوده این تصمیمگیری در مقایسه با تصمیمات ممکن دیگر
با گرفتن مناسبترین تصمیم, بهترین راه حل برای مسئله مطرح شده را تشخیص داده, و به بهترین حالت بعدی ممکن رسید. این راه حل, بصورت یک تابع ارزش
نشان داده می شود که در هر حالت (موجود), بهترین حالت بعدی (مطلوب) توسط آن تعیین میشود.
**مرتبه مدل مارکوف**
+ مدل مارکوف مرتبه صفر
مدل مارکوف از مرتبه صفر مانند یک توزیع احتمال چند جمله ای می باشد. چگونگی تخمین پارامترهای مدل مارکوف مرتبه صفر و همچنین پیچیدگی مدل مشخص و قابل حل است و در کتابهای آمار و احتمالات وجود دارد.
+ مدل مارکوف مرتبه اول
احتمال یک وضعیت به احتمال وضعیت قبلی آن (از نظر زمانی) بستگی دارد, به بیان دیگر احتمال وضعیتهای ممکن, مستقل نیستند.
+ مدل مارکوف مرتبه M
مرتبه یک مدل مارکوف برابر است با طول حافظه ای که مقادیر احتمال ممکن برای حالت بعدی به کمک آن محاسبه می شود. برای مثال، حالت بعدی در یک مدل مارکوف از درجه ۲ (مدل مارکوف مرتبه دوم) به دو حالت قبلی آن بستگی دارد.
**استفاده از مدل مخفی مارکوف در پردازش گفتار**
در طول چندین سال گذشته این روش به عنوان موفقترین روش در شناسایی گفتار مورد استفاده قرار گرفته است. دلیل اصلی این مساله این است که مدل مخفی مارکوف قادر است به شکل بسیار خوبی خصوصیات سیگنال گفتار را در قالب ریاضی قابل فهم تعریف کند.
در یک سیستم پردازش گفتار مبتنی بر مدل مخفی مارکوف قبل از آموزش ، یک مرحله استخراج ویژگی انجام می گردد.
## الگوریتم Dynamic Time Warping
در زمینه بررسی سری های زمانی، DTW یک الگوریتم برای یافتن مشابهت میان دو سری زمانی است که ممکن است در سرعت متفاوت باشند. برای مثال مشابهت در راه رفتن می تواند توسط DTW شناسایی شود حتی اگر فردی از فرد دیگر سریعتر حرکت کند یا حتی حرکتش شتاب دار باشد.

یکی از مهم ترین حوزه های کاربرد DTW حوزه ی پردازش گفتار است.همانطوری که بخش طرح مسئله اشاره شد، سرعت ادای کلمات هر بار ممکن است متفاوت باشد. با استفاده از الگوریتم DTW می توان مشابهت بین کلماتی که یکسان هستند اما با سرعت های مختلف ادا شده اند را شناسایی کرد.
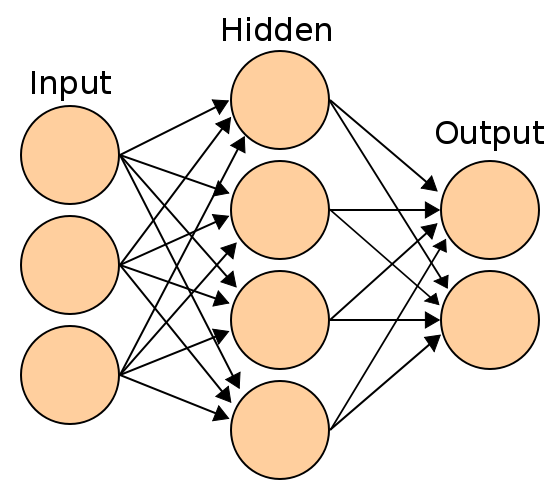
##شبکه های عصبی
شبکه های عصبی مصنوعی سیستم ها و روش های محاسباتی نوین برای یادگیری ماشینی، نمایش دانش و در انتها اعمال دانش به دست آمده در جهت پیش بینی پاسخ های خروجی از سامانه های پیچیده هستند.ایده اصلی این گونه شبکه ها تا حدودی الهام گرفته از شیوه کارکرد سیستم عصبی زیستی برای پردازش داده ها و اطلاعات به منظور یادگیری و ایجاد دانش قرار دارد.
این سیستم از شمار زیادی عناصر پردازشی فوق العاده بهم پیوسته با نام نورون تشکیل شده که برای حل یک مسئله با هم هماهنگ عمل می کنند و توسط سیناپس ها (ارتباطاتت الکترومغناطیسی) اطلاعات را منتقل می کنند. در این شبکه ها اگر یک سلول اسیب ببیند بقیه سلول ها می توانند نبود آنرا جبران کرده؛ و نیز در بازسازی آن سهیم باشند. این شبکه ها قادر به یادگیری اند. مقلا با اعمال سوزش به سلول های عصبی لامسه، سلول ها یاد میگیرند که به طرف جسم داغ نروند و با این الگوریتم سیستم می آموزد که خطای خود را اصلاح کند.
# آزمایشها
# کارهای آینده
# مراجع
[1] : Anusuya, M. A., and Shriniwas K. Katti. "Speech recognition by machine, a review." arXiv preprint arXiv:1001.2267 (2010
# پیوندهای مفید
+ [کتابخانه پردازش گفتار](http://kaldi.sourceforge.net/)
: https://medium.com/@ageitgey/machine-learning-is-fun-part-6-how-to-do-speech-recognition-with-deep-learning-28293c162f7a
: https://www.theguardian.com/technology/2015/feb/20/mobile-phones-hacked-can-nsa-gchq-listen-to-our-phone-calls
https://en.wikipedia.org/wiki/Hidden_Markov_model
https://en.wikipedia.org/wiki/Dynamic_time_warping