# مقدمه + بسم الله الرحمن الرحیم با توجه به گسترش متون و مستندات الکترونیکی فارسی ، استفاده از روشی کارآمد جهت [بازیابی اطلاعات](http://fa.wikipedia.org/wiki/%D8%A8%D8%A7%D8%B2%DB%8C%D8%A7%D8%A8%DB%8C_%D8%A7%D8%B7%D9%84%D8%A7%D8%B9%D8%A7%D8%AA) ضروریست. برای بازیابی اطلاعات ، پی بردن به مفهوم اصلی متن ،رده بندی متون و یافتن کلمات مناسب برای جست و جو و مقالات ؛ استخراج کلمات کلیدی بهترین روش است. کلمات کلیدی مجموعه ای از لغات مهم در یک مستند هستند که توصیفی از محتوای مستند را فراهم می آورند و برای اهداف مختلفی قابل استفاده هستند. *یکی از عملیات های مهم در فرآیند های [خوشه بندی](http://fa.wikipedia.org/wiki/%D8%AE%D9%88%D8%B4%D9%87%E2%80%8C%D8%A8%D9%86%D8%AF%DB%8C) ، طبقه بندی و استخراج اطلاعات ، استخراج کلمات کلیدی از متن است. *با یافتن کلمات کلیدی می توان راحت تر و در زمانی کوتاه تر به مفهوم یک متن یا مقاله پی برد *همچنین برای بازگرداندن مستندات بهتر و نتایج دقیق تر از موتورهای جست و جو از کلمات کلیدی استفاده می شود. در مجموع کلمات کلیدی ابزار مفیدی برای جست و جوی حجم زیادی از مستندات در زمان کوتاه هستند. لازمه استخراج کلمات کلیدی از متن دقت زیاد است ؛ با عنایت به این مطلب و با توجه به اینکه این فرآیند بسیار دشوار و زمان بر است ، نیاز به یک فرآیند خودکار برای استخراج کلمات کلیدی احساس می شود. لذا در این پروژه تصمیم برآن است که روشی برای استخراج خودکار کلمات کلیدی از متن بیان و پیاده سازی شود. # کارهای مرتبط+فرآیند کلی استخراج کلمات کلیدی به شرح زیر است: ابتدا کلمات اضافی حذف شده و سایر کلمات ریشه یابی و برچسب گذاری میشوند. سپس تعدادی ازکلمات به عنوان کاندید مشخص می شوند که به هر کلمه کاندید وزنی اختصاص داده میشود. در مرحله آخر کلمات کلیدی دارای بیشترین وزن انتخاب می شوند. متداول ترین روش برای انتخاب کلمات کلیدی n-grams است.روش های استخراج کلمات کلیدی : روش TF-IDF روش یادگیری ماشینی ترکیب روش های تحلیل آماری و زبانشناختی روش پیشنهادی این پروژه روش TF-IDF است: در این روش میزان تکرار یک کلمه در یک مستند را در مقابل تعداد تکرا آن در مجموعه کلیه مستندات در نظر می گیریم. # آزمایشها # کارهای آینده # مراجع بهروز مینایی بیدگلی ، مجتبی وحیدی اصل ، سمیه عربی نرئی ؛ "استخراج کلمات کلیدی جهت طبقه بندی متون فارسی" زهره کریمی ، مهرنوش شمس فرد ؛ "سیستم خلاصه سازی خودکار متون فارسی" ، دوازدهمین کنفرانس بین المللی انجمن کامپیوتر ایران ، 1385 امیرشهاب شهابی ، محمدرضا کنگاوری ؛ "چکیده سازی چندنوشتاری زبان فارسی" Dalianis, H.; “SweSum–A text Summar izer f or Swedish, Technica l r eport” , TRITANA-P0015, IPLab-174, NADA, KTH, 2000. Frantzi, K.; Ananiadou, S.; Mima, H.;”A utoma tic Recognition of Multi-wor d Ter ms: the C-va lue/NC-value Method ”, International Journal on Digital Libraries, 3(2):115-130, 2000به طور کلی 3 روش متداول برای استخراج کلمات کلیدی وجود دارد : + روش TF-IDF : در این روش میزان تکرار یک کلمه در یک مستند را در مقابل تعداد تکرا آن در مجموعه کلیه مستندات در نظر می گیریم. + روش یادگیری ماشینی: در این روش با مجموعه ای از اسناد آموزشی و کلمات کلیدی مشخص برای آنها ، فرآیند استخراج کلمات کلیدی به عنوان یک مساله طبقه بندی مدل سازی می شود. کلمات بر اساس مشخصه هایشان ، به *"کلمات کلیدی"* و *"کلمات غیرکلیدی"* طبقه بندی می شوند. احتمالات طبقه بندی به صورت آماری از مجوعه آموزشی یادگرفته می شوند. این روش ها دارای انعطاف پذیری زیادی هستند. به عنوان نمونه یکی از این روش ها روش به کار رفته در [6] است که یک مدل یادگیری Naive Bayes را می سازد ؛ یا روش به کار رفته در [7] که از الگوریتم طبقه بندی C 5.0 استفاده می کند. + ترکیب روش های تحلیل آماری و زبان شناختی: علت ترکیب این دو روش این است که اطلاعات آماری بدون پالایش زبان شناختی نتایج مفیدی را در اختیار قرار نمی دهند. بدون اطلاعات زبان شناختی ، کلمات نامطلوبی مانند "از" ، "او" و غیره نیز به علت تکرار زیاد استخراج خواهند شد.از جلمه روش های به کار رفته در این دسته ، روش [5] است. روش پیشنهادی این پروژه روش TF-IDF است که با الگوگیری نسبی از روش آخر ابتدا به حذف کلمات نامطلوبی از قبیل ضمایر ، حروف ربط و غیره می پردازد سپس با استفاده از یک روش آماری و بر مبنای تعدد تکرار کلمات به رده بندی آنها پرداخته و در نهایت کلمات کلیدی متن را استخراج می نماید. #شرح روش پیشنهادی در روش TF-IDF وزن دهی کلمات تابعی از توزیع کلمات مختلف در مستندات است. برای پیاده سازی این روش ابتدا یک مجموعه اسناد (برای مثال مجموعه اسناد همشهری) را در نظر می گیریم. به ازای تمام کلماتی که در پیکره وجود دارد ، بررسی می کنیم که هر کلمه در چه تعداد از سندها تکرار شده است و آن را ذخیره می کنیم . سپس یک سند به عنوان ورودی دریافت می شود. هدف یافتن کلمات کلیدیِ سند دریافت شده است. برای این منظور ابتدا بررسی می کنیم که هر یک از کلمات سند ورودی ، چند بار در همان سند استفاده شده است. سپس به ازای تمام کلمات سند ورودی بررسی می کنیم که هر کلمه در چه تعداد از اسناد پیکره اصلی (برای مثال همشهری) وجود دارد. بعد از طی کردن این مراحل به حساب کردن وزن کلمات می پردازیم : تعیین وزن کلمات با استفاده از دو معیار term frequency و inverse document frequency انجام می شود که به شرح زیر محاسبه خواهند شد : 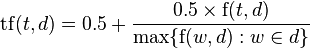 که در آن : $$ f(t,d) $$ تعداد تکرار کلمه t در سند d (سند هدف) است و $$ max{f(w,d)} $$تعداد پر تکرارترین کلمه در سند d می باشد و 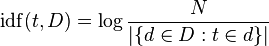 که در آن N تعداد کل اسناد موجود در پیکره است و  بیانگر تعداد اسنادی است که کلمه t در آنها وجود دارد. در نهایت وزن هر کلمه به صورت زیر محاسبه خواهد می شود :  تنها نکته ای که باقی می ماند مواجه شدن با کلمه ایست که در مجموعه اسناد وجود نداشته باشد. در این صورت مخرج idf صفر شده و با مشکل مواجه خواهیم شد. در چنین حالتی به صورت قراردادی مخرج idf را یک در نظر می گیریم. پس از آنکه وزن تمامی کلمات سند ورودی محاسبه شد ، کلماتی که دارای بیشترین وزن هستند ، به عنوان کلمات کلیدی معرفی می شوند. # ارزیابی سیستم با توجه به اینکه زبان فارسی منبعی شامل متون و کلمات کلیدی آنها ندارد ، برای ارزیابی این سیستم باید تعدادی متن را در نظر گرفت ، کلمات کلیدی آنها را یک بار به صورت دستی و با استفاده از عقل و هوش انسان و یک بار با استفاده از سیستم مزبور استخراج نمود . سپس با مقایسه نتیجه دو روش سیستم ارزیابی شده و کارایی آن محاسبه می شود. # آزمایشها # کارهای آینده # مراجع [1] بهروز مینایی بیدگلی ، مجتبی وحیدی اصل ، سمیه عربی نرئی ؛ "استخراج کلمات کلیدی جهت طبقه بندی متون فارسی" [2] زهره کریمی ، مهرنوش شمس فرد ؛ "سیستم خلاصه سازی خودکار متون فارسی" ، دوازدهمین کنفرانس بین المللی انجمن کامپیوتر ایران ، 1385 [3] امیرشهاب شهابی ، محمدرضا کنگاوری ؛ "چکیده سازی چندنوشتاری زبان فارسی" [4] Dalianis, H.; “SweSum–A text Summar izer f or Swedish, Technica l r eport” , TRITANA-P0015, IPLab-174, NADA, KTH, 2000. [5] Frantzi, K.; Ananiadou, S.; Mima, H.;”A utoma tic Recognition of Multi-wor d Ter ms: the C-va lue/NC-value Method ”, International Journal on Digital Libraries, 3(2):115-130, 2000 [6] Witten, I.; Paynter, G.; Frank, E.; Gutwin, C.; Nevill-Manning, C.; ” KEA : Practica l A utoma tic Key phra se Extra ction” , In Proceedings of A CMDL' 99, pages254-255,1999 [7] Zhang, Y.; Zincir-Heywood, N. and Milios, E.; ” Wor ld Wide Web Site Summariza tion ”, Web Intelligence and Agent Systems: An International Journal, 2(1):39-53, 2004. #پیوندهای مفید [روش جدید وزن دهی](http://ceit.aut.ac.ir/islab/projects/arshad/maleki/Papers/CSICC2007/MMaleki-CSICC2007.pdf) [ﻣﻘﺪﻣﻪای ﺑﺮ ذﺧﯿﺮه و ﺑﺎزﯾﺎﺑﯽ اﻃﻼﻋﺎت ﻣﺘﻮن زﺑﺎن ﻓﺎرﺳﯽ ](http://www.arooz.net/attachments/059_20-IR.pdf) [پردازش زبان فارسی در پایتون](http://www.sobhe.ir/hazm/) [پیکره فارسی همشهری](http://ece.ut.ac.ir/dbrg/hamshahri/fadownload.html) [برنامه نوشته شده در گیت !](https://gist.github.com/sheikholeslami/11293353) [ﺗﺤﻠﯿﻞ ﺳﯿﺴﺘﻢ ﯾﺎﻓﺘﻦ ﺧﻮدﮐﺎر ﮐﻠﻤﺎت ﮐﻠﯿﺪی ﻣﺘﻮن زﺑﺎن ﻓﺎرﺳﯽ ](http://www.docdroid.net/file/view/bihv/059-27-keyword.pdf) [Survey of Keyword Extraction Techniques](http://www.docdroid.net/bii3/lott.pdf.html) [Exploration and Improvement in Keyword Extraction for News Based on TFIDF ](http://www.docdroid.net/file/view/bihs/3f818df5-d8Survey of Keyword Extraction Techniques ee-4da3-b58e-26b9c6cedd0a.pdf) [Unsupervised Approaches for Automatic Keyword Extraction Using Meeting Transcripts](http://www.docdroid.net/file/view/bii5/naacl-2009.pdf) [تی اف آیدی اف در ویکی پدیا](http://en.wikipedia.org/wiki/Tf%E2%80%93idf)