۱. 1.مقدمه
تشخیص احساسات یا Sentiment analysis شاخه ای از علوم کامپیوتر و پردازش زبان (NLP) است که سعی دارد ماشین و هوش مصنوعی را با احساس و عواطف انسانی آشنا سازد و تشخیص آنها از هم را میسر سازد .
تلفن همراهی را تصور کنید که بر اساس مکالمات شما با افراد تشخیص میدهد که امروز روز دشواری داشته اید و به طور خودکار تماس کسانی که سابقه ی بیشترین دعوا ی لفظی را دارند را بلاک میکند تا شما در آرامش باشید .
شبکه ی اجتماعی را تصور کنید که لحن و احساس شما را از آپدیت روزانه ی که پست کردید تشخیص میدهد و شما را با افرادی با حس مشابه در تماس قرار میدهد تا با هم بر سر مشکل مشترکتان (مثلا حقوق کم ) درد و دل کنید ! همچنین اگر شبکه ی اجتماعی دارای جامعه ی بزرگی باشد اطلاعات جمع آوری شده ی آن برای امور آماری - روان شناسی بی نظیر خواهند بود . مثلا روانشناسان میتوانند شروع یک اپیدمی افسردگی در یک منطقه ی خاص را تشخیص دهند . از آنجا که میزان جرم وقتی که مردم یک منطقه مشکلات روحی دارند بیشتر است پلیس نیز میتواند نیرو های خود را بر این اساس در جا های مختلف تقسیم کند .
تشخیص احساس در زمان حال بیشترین کاربرد را در سایت های عرضه انواع کالا ( مجازی یا حقیقی ) دارد . بسیار مهم است که مدیر سایت و شرکت عرضه کننده ی محصول بدانند کدام نقد و بررسی ها از یک محصول مثبت هستند و کدام منفی و اینکه شدت منفی یا مثبت بودن چقدر است . کاربر از محصول کمی ناراضی است یا شدیدا ؟ شرکت های بزرگی همچون Amazon و Google و Ebay از SA برای بررسی نظرات کاربران استفاده میکنند . این شاخه از SA را Opinion mining میگویند .
تشخیص احساس ماشین های فعلی را یک نسل به جلو رانده و باور عمومی بر بی احساس بودن ماشین ها را کمرنگ تر میسازد . در پی آن باعث آسان تر شدن بسیاری از جهات زندگی انسان نیز خواهد شد .
۲. 1.1شرح مساله
در این پروژه قصد داریم به کمک SA برنامه ای بنویسیم که حالت روحی نویسنده ی یک حساب سایت Twitter را بررسی و تشخیص دهد . برای ساده تر شدن مساله کمیت "حالت روحی" را یک کمیت بولین در نظر میگیریم به این شکل که شخص میتواند خوشحال - ناراحت - خنثی باشد .
در صورت امکان سعی خواهد شد که حالت های پیچیده تر روحی مثل استرس و آرام بودن (Contentsity and stress ) را نیز شناسایی کنیم .
در انتها اطلاعات را بر روی نموداری بر حسب زمان/احساس نمایش میدهیم که نشان دهنده ی حالت روحی فرد در گذر زمان خواهد بود .
هدف ما در این مساله رسیدن به دقت بالای 70 درصد است . دلیل آن اینست که طبق گزارش ها و تحقیقات متعدد دقت انسان در تشخیص حالت احساسی با در دست داشتن تنها متن ، در حدود 70 درصد است [20] .
۳. 2.1چالش ها
در پیاده سازی SA برای یک نوشتار همیشه چالش های زیادی را پیش روی داریم :
کاربر به طور مستقیم احساس خود را بروز نمیدهد و ممکن است به شیوه های متعدد ( افعال یا صفات منفی ) نظر خود را بروز دهد . جملات پیاپی ممکن است معنی هم را تکمیل کنند .
امروز حالم به هیچ وجه خوب نبود
یا
اگر فکر میکنید حالم خوبه در اشتباهیدکاربر ممکن است از کنایه - طعنه - شوخی استفاده کند . هر کدام از این موارد در ساختار جمله مفهومی کاملا متفاوت با مفهوم واقعی دارند .
امروز همونقدر خوشحال بودم که یه بره تو سلاخ خونه خوشحاله !
این کامپیوتر کاربردش در حد یه پاره آجر هم نیستکاربران معمولا از ساختار های جمله ای پیچیده ای استفاده میکنند که به دلیل رسمی نبودن الزاما در چهارچوب کلی ساختار زبان قرار نمیگیرند .
بنا به دلایل فوق بررسی تنها لغت به لغت (Lexical) میتواند باعث ایجاد نتایج غلط شود .
هیچ کدام از این چالش ها تا به کنون در ضمینه ی NLP به کلی حل نشده اند .
۴. 2. کار های مرتبط
در ضمینه ی Sentiment analysis که ازین به بعد آن را به اختصار SA می نامیم تا به کنون روش های مختلفی پیشنهاد شده . درادامه به بررسی تعدادی از کارهای انجام شده میپردازیم . هر روش به مقاله مربوط ارجا داده شده است .
ٍشکلک ها ! [1]
ساده ترین روش تشخیص حالت یک نویسنده مشاهده ی شکلک ها یا Emoticons ای هست که او در متن به کار برده . با این شکلک های بسیار ساده میتوان مفاهیم احساسی پیچیده ای را انتقال داد .
مثلا :
حالم خوب است :))
مفهوم بسیار ساده ای دارد . در حالی که :
حالم خوب است :(
مفهوم پیچیده تری را منتقل میکند . همانطور که میبینید شکلک ها میتوانند در SA بسیار موثر باشند . با این وجود بسیاری از پروژه های فعلی شکلک ها را به دلایل متعدد نادید میگیرند :
استفاده نادرست کاربر : همه از شکلک ها برای بیان احساسات خود استفاده نمیکنند . بعضی ممکن است حتی به عادت هم که شده در پایان متن شکلک مثبت به کار ببرند .
کاربرد بسیار کم شکلک ها : در متن های جدی شکلک ها کاربر بسیار کمی دارند . به خصوص کاربرانی که دارای هیجان زیادی هستند یا بسیار عصبانی اند ممکن است اصلا از شکلک ها استفاده نکنند . در واقع یک پژوهش نشان داده که میزان استفاده از شکلک ها در محیط های رسمی کمتر از 10% است [1].
با این حال استفاده از شکلک ها در کنار متد های دیگر SA میتوانند در نتیجه گیری بسیار کمک کننده باشد .

نمونه ای از شکلک ها - دسته بندی بر اساس خوب - بد - خنثی بودن آنها
روش لغوی ساده یا Basic lexicon analysis
در این روش با استفاده از یک دیکشنری که که تمام لغات مربوط به دامنه ی کاری ما در آن طبق مثبت منفی بودن امتیاز داده شده اند متن را آنالیز میکنیم . این روش بسیار ساده بوده و در متن لغاتی مثل "خوب" "عالی" "بد" "زشت" و غیره را که همه بار منفی دارند را در نظر گرفته و امتیاز آنها را جمع میکند . نتیجه ی نهایی امتیاز جمله بدست آمده است که اگر مثبت باشد جمله مثبت و اگر منفی باشد جمله را منفی در نظر میگیرد . این روش با وجود سادگی به دلیل پیچیدگی ساختار زبانی به ندرت مورد استفاده قرار میگیرد . زیرا یک جمله میتواند دارای شماری زیادی از کلمات منفی باشد ولی معنی مثبتی داشته باشد . ( چالش منفی سازی جملات ) *این کتاب به طرز مسخره و احمقانه ای زیباست* مشاهده میشود که تکرار کلمات "مسخره" و "احمقانه" دو برابر کلمه ی "زیبا" میباشند ولی با این حال جمله معنایی بسیار مثبت دارد . مشکل دیگر عدم توانایی شناختن استعارات و کنایات است . این مشکل را تا حدودی میتوان با داشتن یک دیکشنری جدا گانه برای استعارات متداول و روش های تشخیص تشابه مثل NGram تا حدی حل کرد . ولی در این حالت هم بررسی لغتی به تنهایی کافی نیست و باید از روش های دیگری مثل Grammar tree استفاده برد . همچنین بسیاری از جملات که بار مثبت یا منفی دارند ممکن است به هیچ وجه از کلمات احساسی استفاده نکنند :
صفر تا صد این ماشین 2 ثانیه است !
متد های پیشرفته تر به سه نوع تقسیم میشوند :
متد های مبنی بر Machine Learining و استفاده از classifier ها مانند Naive bayes - SVM و Maximum entropy
متد های Lexical/NLPکه در آن ها به کلمات در یک مقیاس از -11 تا +11 ارزشی معادل با مثبت/منفی بودن کلمه داده شده و متن با استفاده از nlp آنالیز میشود .
متد های ترکیبی.
در زیر تعدادی از روش های مورد استفاده را میبینید . برخی از آنها را در ادامه شرح خواهیم داد .

نموداری از روش های مورد استفاده در SA

تفاوت بین دو روش
۵. 1.2 روش [7]NLP
برای توضیح بیشتر بد نیست با چند دیکشنری آشنا شویم :
ـ Wordnet یک دیکشنری lexical است که برای پژوهش های مربوط به پردازش زبان ساخته شده . این دیکشنری با تاکید بر روی کلمات هم معنا تمام کلمات انگلیسی را در خوشه بندی کرده(به این خوشه ها synset گفته میشود ) و هر کدام از این خوشه ها با خوشه های دیگر میتوانند رابطه ای مثل تضاد یا تناسب داشته باشند . شکل زیر یک تصویر سازی از ساختار Wordnet است :
ـSentiWordnet یک نسخه ی ویرایش شده از ورد نت است که به تمام لغات دو مقدار مثبت بودن و منفی بودن (Positive - Negative) را نیز نسبت داده که این متغیر ها دو عدد بین 0 و 1 هستند .
بدیهی است که در صورت عدم استفاده از یادگیری ماشین میتوان از دیکشنری فوق برای بررسی لغات از لحاظ احساسی استفاده نمود .
همچنین کاربرد دیگر این دیکشنری ها WSD یا Word Sense Disambiguation میباشد به این مفهوم که معنای هر کلمه را در متن (Context) دریابیم ( با توجه به اینکه کلمات بستگی به متن میتوانند چند معنای متفاوت داشته باشند .)
الگوریتم های WSD خارج از موضوع این پژوهش بوده و بیشتر ازین به آنها اشاره ای نمیشود . با این وجود میتوان از WSD در مرحله ی Preprocessing از الگوریتم های SA برای نتیجه ی دقیق تر استفاده نمود . مشکل عمده ی WSD اینست که در Context های مختصر مثل Twitter دقت کافی را دارا نمیباشد .
روش NLP را میتوان تکامل یافته ی روش لغوی ساده ( basic lexicon analysis یا Keyword analysis ) دانست . این روش چهار مرحله کلی دارد :
شناسایی بخش مهم متن برای SA
تشخیص ساختار جمله و تشکیل grammar tree
امتیاز دهی به کلمات مهم تشخیص داده شده در متن (features)
امتیاز دهی نهایی به متن
شکل زیر سیر روش NLP را به طور مختصر نشان میدهد :

روش NLP
چالش ها در این روش با تعریف یک مجموعه قواعد خاص حل میشوند . مثلا برای تشخیص صفات منفی در افعال منفی ساختار جمله بررسی شده ، مثبت و منفی بودن فعل و صفت که در مرحله ی دوم بدست آمد بررسی میشود .
برای تشخیص کنایه از وجود کلمات با معنای متضاد (مثبت و منفی در SentiWordnet) در یک جمله استفاده میشود . هر چند به طور کلی روش NLP در برخورد با کنایه و استعاره ها و واژه های کوچه بازاری و عامیانه ضعف زیادی از خود نشان میدهد .
در نهایت با محاسبه ی امتیاز همه feature ها برای متن دو امتیاز کلی مثبت و منفی محاسبه میشود . این کار به دو روش صورت میگیرد :
جمع امتیاز های مثبت و منفی feature ها

روش اول میانگین امتیاز های مثبت و منفی feature ها

روش دوم
مهم ترین ضعف این روش وابستگی به دیکشنری های لکسیکال مانند Wordnet می باشد . این دیکشنری ها برای زبان انگلیسی تهیه شده اند برای سایر زبان ها من جمله فارسی کاملا بلا استفاده اند . برای رفع این مشکل باید به طور دستی یک دیکشنری مختصر مربوط به دامنه ی کاری ما ایجاد شود که بسیار وقت گیر خواهد بود .
با این وجود روش NLP از لحاظ سرعت و قدرت پردازش بسیار سریعتر از سایر روش ها عمل میکند . هرچند میزان خطای بالای آن و همچنین الزام نوشتن قواعد بسیار برای زبان باعث شده این روش به ندرت مورد استفاده قرار بگیرد . امروزه از روش های Machine learning به دلیل سادگی و همچنین عدم نیاز به دسترسی به ساختار جمله بیشتر استفاده میشود [7].
۶. 2.2 روش های مبتنی بر Machine Learning
این روش ها بر خلاف روش NLP نیاز به در نظر گرفتن ساختار گرامری جمله ندارند . در عوض باید به طور مناسبی با یک Learning set تربیت (Train) شوند .
"مناسب" از این لحاظ که اگر dataset ما دارای موضوعی خاص مثلا بررسی نقد های یک هتل باشد learning set نیز به تبعه باید از همین نوع باشد .
استفاده از learning set نامناسب باعث افت شدیدی در دقت کلاس بندی شده و این اهمیت learning set مناسب را نشان میدهد .
این روش ها اولین بار توسط Pang و lee با بررسی چند مدل classifier مورد پژوهش قرار گرفتند [13] . آنها روش های SVM - Naive bayes - MAX Entropy را مورد بررسی قرار دادند و بین آنها SVM را دارای بالاترین و Naive bayes را دارای پایین ترین دقت ارزیابی کردند[3] .

روش بیز ساده [6] Naive bayes classifier
روش بیز ساده یک روش قدرتمند دسته بنده (classification) مبتنی بر احتمالات میباشد . در این روش فرض میکنیم تعدادی کلاس (دسته بندی) داریم . احتمال وجود داده ی جدید در هر کدام یک ازین دسته بندی ها را بدست می آوریم . هر کلاسی که احتمال بیشتری را نتیجه داد داده ی خود را به آن کلاس اختصاص میدهیم [5] .
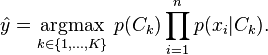
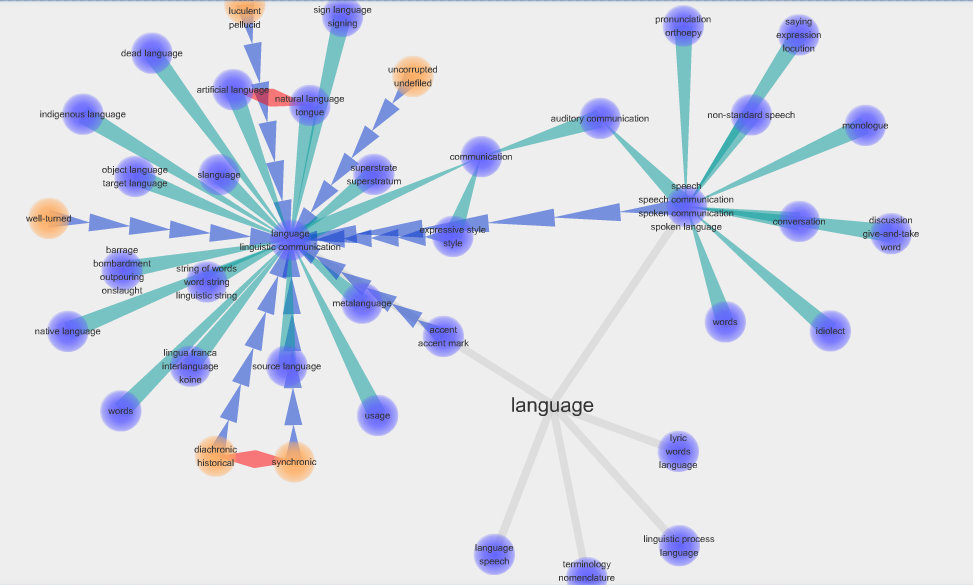
فرمول بالا فرمول اصلی classifier است . Px به معنای احتمال x است . همچنین داریم :

ـ x در اینجا به معنی دیتای جدید و یک متغیر برداریست و C کلاسی است که دیتا میتواند در آن قرار بگیرد یا نگیرد .

فرمول فوق را میتوان به زبان ساده اینطور شرح داد که احتمال قرار گرفتن یک feature در یک کلاس برابر تعداد feature های مشابه یا یکسان است که قبلا در آن کلاس قرار داشته اند . (کلاس = دسته بندی ) . ولی از آنجا که متن ما شامل برداری از چندین feature ها هست برای بدست آوردن احتمال وجود متن در کلاس مذکور داریم (طبق قانون زنجیره ای ) :

و چون احتمال رخ دادن feature ها در متن مستقل از هم میباشند داریم :
پس میتوان گفت احتمال قرار گرفتن متن X در کلاس C برابر است با :

و

توجه کنید که چون Px=Z است و Px در تمام مقایسه های ما ثابت است ( ما میخواهیم یک متن واحد X را با چند کلاس مقایسه کنیم ) مقدار آن را میتوان یک عدد ثابت فرض کرد و در نظر نگرفت . به این ترتیب احتمال اینکه X در هر C باشد را بدست می آوریم و در نهایت هر C که احتمال بالاتری داشت X را به همان دسته تخصیص میدهیم .
قسمت Training این الگوریتم در تخصیص feature های مناسب به هر کلاس پیش از عمل دسته بندی است . که همان Learning set نام دارد[8][5] .
روش[3] SVM
روش SVM یا ماشین برداری پشتیبان یک روش یادگیری ماشین خطی و نظارت شده (supervised) است . این روش در پژوهش انجام گرفته توسط Pang پر دقت ترین روش بین یه classifier از نوع بیز ساده - SVM - Max Enthropy بود که دقت آن 74% تخمین زده شد .
در این روش برای کلاس بندی اطلاعات از یک خط استفاده میشود . با ورود اطلاعات جدید بنا بر اطلاعات قبلی (Learning set) یک خط جدید تولید میشود که داده ی جدید را در دسته ی مربوط به آن قرار دهد . به این خط که در هر مرحله تولید میشود Hyperplane میگویند . شکل زیر نمایشگر یک Hyperplane در فضای دو بعدی است .

توجه کنید که در Machine Learning هر feature را یک بعد میدانیم و در نتیجه به کار بردن واژه ی خط که دو بعدی است برای این منظور اشتباه است .
هایپر پلین را میتوان یک خط n بعدی دانست که تصور آن دشوار است . برای همین از فضای دو بعدی برای توضیح SVM استفاده میشود .
در هر مرحله با یافتن هایپر پلین بهینه که خطی است که بیشترین فضای خالی از دو طرف را داشته باشد (Optimal gap)و داده ها را به درستی تقسیم بنده کند عمل تقسیم بندی انجام میشود .
ممکن است که عمل تقسیم بندی با رسم هایپر پلین به تنهایی امکان پذیر نباشد . مثلا در شکل زیر که داده ها به هم نزدیک میباشند (distance آنها از هم کم است) :

در این موارد SVM با استفاده از یک سری توابع ریاضی که به آنها کرنل (kernel) میگویند داده ها را به فضای جدیدی میبرد که بتوان از هایپر پلین برای جدا سازی آنها استفاده نمود . به این عمل نگاشت (mapping) میگویند [11][13][15].

جزییات ریاضی این روش و ساختار کرنل پیچیده بوده و از ذکر آن خود داری میشود . برای اطلاعات بیشتر به[14] مراجعه شود .
۷. 3.2 روش های Unsupervised
روش [2] Turney
در سال 2002 turney روشی را برای بررسی SA بدون نیاز به نظارت ارائه داد . این روش به اختصار شرح داده میشود .
در این روش ابتدا متن توسط یک (POS (Part Of Speach تگر تگ میشود . به این معنا که ساختار جمله - فعل صفت و غیره مشخص میشود . از متن جملاتی که دارای صفت (adjective یا adverb ) هستند را جدا کرده و بقیه را نادید میگیرد . از آنجا که طی پژوهش های قبلی مشاهده شده که صفت ها را میتوان feature های خوبی در SA دانست . ولی صفت به تنهایی کافی نیست زیرا بعضی صفات بسته به متن میتوانند معنی مثبت یا منفی داشته باشند .به همین دلیل علاوه به صفت context را هم یک feature در نظر میگیریم .
در مرحله ی بعد سری کلمات 2 تایی پیاپی که از جدول زیر پیروی کنند استخراج میشوند . در غیر این صورت کلمات نادید گرفته میشوند . برای اطلاعات بیشتر در مورد این جدول به [2] مراجعه کنید .

JJ = صفت
NN = اسم
RB = adverb
VB = فعل
در مرحله ی بعدی میزان مثبت/منفی بودن هر یک ازین سری کلمات دوتایی توسط الگوریتم PMI-IR محاسبه میشود .
(این قسمت بعدا تکمیل میشود)
۸. 3.آزمایش ها
1.3 آزمایش اولیه
در این آزمایش از کورپوس سایت اسنتفورد برای ایجاد Learning Set استفاده شده است [18] . این کورپوس شامل 1 میلیون و 600 هزار توئیت است که به طور دستی طبقه بندی شده اند . از این بین به دلیل محدودیت های سخت افزاری تعداد 11 هزار توئیت به صورت شبه تصادفی انتخاب شدند . به این صورت که نزدیک به 5500 عدد توئیت مثبت و 5500 عدد توئیت منفی به طور تصادفی از بین همه ی توئیت ها انتخاب شدند .
در ادامه Pipeline برنامه به اختصار شرح داده شده است .
1.1.3 مرحله اول - پیش پردازش
ابتدا تمام توئییت ها را یک پردازش کلی میکنیم تا ویژگی های غیر مهم آنها حذف شوند . در توئیت میتوان افراد را با پیشوند "@" فراخوانی کرد . این فراخوانی ها هیچ بار عاطفی ندارند برای همین کلیه ی آنها را به عبارت قاعده دار زیر میتوان پیدا و حذف کرد :

آدرس ها و لینک های اینترنتی نیز هیچ ارزش احساسی ندارند پس آنها را نیز با عبارت زیر پیدا و حذف میکنیم :

بر خلاف این دو ، در هر توئیت کلماتی با پیشوند # وجود دارند که هش تگ نامیده میشوند . این کلمات از لحاظ مفهومی بسار مهم بوده و میتوانند نکات کلیدی توئیت قلمداد شوند . برای همین با عبارت زیر این کلمات را پیدا کرده و سپس # ابتدای آنها را حذف میکنیم تا مانند سایر کلمات عادی در جمله قرار گیرند و بعدا مورد استفاده قرار گیرند .

در ادامه تمامی کلمات به Lowercase تبدیل شده و فاصله های اضافی (Whitespace) از متن حذف میشوند .
2.1.3 مرحله ی دوم - استخراج Feature ها از متن
همانطور که گفته شد Feature ها در متن کلماتی هستند که برای ما ارزشمند هستند و معنایی عاطفی را حمل میکنند . برای بدست آورن تقریبی لیست این کلمات . کلماتی را که به طور قطع Feature نیستند را حذف میکنیم . برای شروع از یک Stopword list استفاده میکنیم [19] . این لیست شامل کلمات کوتاه انگلیسی است که هیچ بار عاطفی را در بر ندارند . تمامی کلماتی که در این لیست وجود دارند را نادید میگیریم .
مرحله ی بعدی ساده سازی کلمات طولانی است . توئیت ها متن هایی غیر رسمی هستند و کاربر برای بیان راحت تر احساسات خود ممکن است به شیوه های غیر متعارف نوشتاری روی آورد . برای مثال برای تاکید بر خوشحالی از کلمه ای مانند : "سلاااااااااممممممم" یا "سلللللللللللللللللااااااممممممممم" و غیره استفاده کند . این طولانی سازی لغات در حالت عادی باعث میشود که برای مثال دو کلمه ای که بالا ذکر شد دو Feature جدا در نظر گرفته شوند در حالی که واضحا هر دو یک معنی و بار عاطفی را دارند . در نتیجه به سادگی و با عبارات قاعده مند کلیه ی کلماتی که بیشتر از 2 حرف تکراری پیاپی در آنها باشند را کوتاه میکنیم به این شکل که تمامی حروف تکراری را هرچقدر هم که زیاد باشند به 2 عدد کاهش میدهیم . به این ترتیب کلمات "سلاااااااام" و سلاااااااااااااااام" هر دو به کلمه ی "سلاام" تبدیل میشوند که امر بسیار مفیدی در کاهش شمار Feature هاس ماست .
3.1.3 مرحله ی سوم - ایجاد Learning set
در این مرحله تمام توئیت های موجود در کورپوس آماده را بررسی میکنیم و تمامی Feature ها موجود در تمامی این توئیت ها را جمع آوری میکنیم . مجموعه ی بدست آمده مجموعه کل Feature هاس ماست . در مرحله ی بعدی بردار feature های توئیت ها را تشکیل میدهیم . این بردار شامل N فیلد است که N تعداد کل Feature های ماست . هر فیلد نماینده ی یک Feature است . در صورتی که آن Feature در توئیت موجود بود فیلد را 1 ( یا True) و در غیر اینصورت 0 (یا False) در نظر میگیریم . این مجموعه بردار ها مستقیما در Train کردن Classifier ما مورد استفاده قرار خواهند گرفت .
شکل زیر نمایش یک Feature vector برای تنها یک توئیت است . Feature ها موجود در توئیت در شکل علامت گذاری شده اند :

4.1.3 مرحله چهارم - تربیت Classifier
در این مرحله مستقیما با استفاده از Feature vector هایی که بدست آوردیم میتوانیم Classifier مورد نظر خود را تربیت کنیم . در این آزمایش ابتدایی به دلیل سادگی بیشتر از Classifier بیز ساده استفاده شده است . در صورت عدم کارایی در آزمایش های بعدی از SVM استفاده خواهیم نمود .
در این مرحله پس از Train کردن Classifier میتوان مستقیما ورودی های امتحانی خود (Test data set) را به Classifier داد تا دقت آنرا بسنجیم .
در این آزمایش از Classifier مربوط به کتابخانه NLTK استفاده شد . در طول آزمایش آشکال شد که این Classifier ایرادات بسیار زیادی دارد . برای مثال :
زمان بسیار طولانی برای تربیت کردن . حدود 30 دقیقه فقط برای 11 هزار عدد توئیت .
امکان ذخیره سازی classifier با اینکه وجود دارد ولی بدرستی کار نمیکند و باعث تغییرات جدی در نتیجه میشود .
فقط یک بار قابل تربیت شدن است .
بدلیل محدودیت های مذکور تصمیم بر این شد که در آزمایش های نهایی حتما از classifier دیگری استفاده شود .
5.1.3 مرحله پنجم - اندازه گیری دقت و نتیجه گیری و کار های آینده
در بررسی انجام شده بوسیله ی Test data set موجود . به میانگین دقت (percision) در 68% دست یافتیم . این عدد به عدد مطلوب ما یعنی 70% بسیار نزدیک است . این عدد بیان گر دقت ماشین است و نمایانگر اینست که تعداد خطای ما نسبتا قابل قبول بوده . test دیتا را میتوانید در لینک پایین بیابید .

در ادامه به میزان Recall به مقدار 73% دست یافتیم .

با این دو عدد میتوان مقیاس F را به صورت زیر حساب کرد :

مقیاس F برای این ماشین در حدود 70.5% بدست می آید .
دیتا ست مربوط به تست شامل 498 توئیت طبقه بندی شده به صورت دستی است که به همراه سایر فایل ها قابل مشاهده است .
این اعداد با این که امید بخش جلوه میکنند ولی هنوز الگوریتم ما دارای یک مشکل بسیار جدی است و آنهم عدم توانیی درک منفی ساز هاست :
امروز حال خیلی خوبی ندارم " توسط ماشین به دلیل وجود کلمات خیلی و خوب جمله ی مثبتی در نظر گرفته میشود .
تا به کنون تمام Feature های خود را Unigram در نظر گرفتیم . در آزمایش بعدی امتحان میکنیم که آیا استفاده از BIGram ها در رفع این مشکل تاثیری خواهد داشت یا خیر .
همچنین سعی خواهد شد که از Classifier سریع تری استفاده شود .
2.3 فایل ها
تمامی فایل ها را در اینجا میتوانید بیابید .
توجه ! برای اجرای کد نیازمند پایتون نسخه ی 3.2 به بالا یا PyPy نسخه 2.3 به بالا به همراه کتابخانه NLTK نسخه 3 به بالا میباشید .
لیست فایل ها
learning.csv شامل 11 هزار توئیت برای تربیت ماشین است
sentibot.py فایل اصلی برنامه است
stopwords.txt شامل تمام کلمه های استاپ ورد است که بار عاطفی ندارند
testdata.manual.2009.06.14.csv شامل 498 توئیت است که برای تست نتیجه ی ماشین مورد استفاده قرار گرفته است
3.3 پیاده سازی SVM
همانطور که ذکر شد کتابخانه ی NLTK سرعت بسیار پایینی داشت . در این مرحله از کتاب خانه ی LibSVM استفاده شده و کد بالا بر اساس SVM پیاده سازی میشود . پارامتر های SVM در پایین ذکر شده اند :
param = svm_parameter()
param.C = 10
param.kernel_type = LINEAR
همانطور که مشاهده میشود از SVM خطی استفده شده . لازم ب ذکر است که بقیه ی مراحل کار عینا مانند روش قبل بوده و تنها کلاس Classifier تغییر یافته به همین دلیل از ذکر مجدد آنها خود داری مشود و تنها به ذکر نتایج جدید بسنده میکنیم .
زمان تربیت SVM با توجه به انکه کتابخانه ی Libsvm بر اساس زبان C است به حدود 10دقیقه رسیده که از زمان 30-40 دقیقه ای NLTK بسیار بهتربه نظر می رسد .
برای تست برنامه از همان TestData بخش قبل استفاده شد . میزان دقت و recall به شرح زیر به دست آمد :
دقت (Precison) بدست آمده برابر با 67%
و Recall بدست آمده برابر 77%
همانطور که مشاهده میشود میزان دقت تفاوت چندانی با بخش قبل نکرد . این امر به دلی گسترده گی بسیار زیاد Learning set و دقت بالا ی آن است . به نظر میرسد جملاتی که از لحاظ احساسی چندان پیچیده یا مبهم نیستند توسط هر دو روش تقریبا قابل شناسایی هستند .
فایل های پروژه را مجددا در اینجا می توانید مشاهده کنید . یادآور میشد که اطلاعات تست و یادگیری دقیقا مشابه قسمت قبل می باشند . همچنین مراحل پیش پردازش توییت ها و پیدا کردن Feature ها تغییری نکرده اند.
لازم به ذکر است برای اجرای این فایل نیازمند به کتابخانه ی LibSVM - بایندینگ این کتابخانه برای زبان پایتون - و همچنین پایتون نسخه ی 2.6 میباشید .این کد روی نسخه های دیگر تست نشده است .
۹. 4. کارهای آینده
مهمترین هدف برای آینده پیاده سازی یکی از روش های فوق برای زبان فارسی است . قسمت برنامه نویسی این کار انجام شده و آن را میتوانید در لینک گیت مشاهده کنید . بخش اصلی این کار تهیه ی دیتا-ست به زبان فارسی است که باید به صورت دستی و به کمک یک Crawler انجام شود .
با وجود نوشتن بخش آنالیز احساسی ، هنوز برنامه کامل نشده و به توییتر متصل نمیگردد . برای این منظور از API توییتر استفاده خواهد شد .
اضافه کردن قابلیت رسم نمودار بر اساس اطلاعات . برای این منظور از کتابخانه ی Chart.js استفاده میشود .
در حال حاضر حالت احساسی تنها از جنبه ی خوشحالی و ناراحت بودن بررسی میشود . با در دست داشتن Learning Set های مناسب میتوان جنبه های دیگر مثل عصبانیت و آرامش و غیره را نیز بررسی نمود .
۱۰. مراجع
J. Park, V. Barash, C. Fink, and M. Cha. Emoticon style: Interpreting differences in emoticons across cultures. In International AAAI Conference on Weblogs and Social Media (ICWSM), 2013.
Peter Turney (2002). "Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews".
Bo Pang; Lillian Lee and Shivakumar Vaithyanathan (2002)."Thumbs up? Sentiment Classification using Machine Learning Techniques"
wordnet.princeton.edu . WordNet
Minsky, M. (1961). Steps toward Artificial Intelligence .
Extracting Opinion Propositions and Opinion Holders using Syntactic and Lexical Cues Steven Bethard , Hong Yu , Ashley Thornton, Vasileios Hatzivassiloglou and Dan Jurafsky
Lexicon-Based Methods for Sentiment Analysis Maite Taboada Simon Fraser University Julian Brooke University of Toronto Milan Tofiloski Simon Fraser University Kimberly Voll University of British Columbia Manfred Stede University of Potsdam
http://nlp.stanford.edu/IR-book/html/htmledition/naive-bayes-text-classification-1.html
http://www.sciencedirect.com/science/article/pii/S2090447914000550
Real-Time Twitter Sentiment Classification Using Unsupervised Latha.K1 , A.Sujitha2
COLT-92 by Boser, Guyon & Vapnik
Combining Lexicon-based and Learning-based Methods for Twitter Sentiment Analysis Lei Zhang, Riddhiman Ghosh, Mohamed Dekhil, Meichun Hsu, Bing Liu
Sentiment Analysis - A multimodal approach by Lucas Carstens
www.kernel-machines.org (توابع کرنل)
Classification by Support Vector Machines Florian Markowetz Max-Planck
Comparing and Combining Sentiment Analysis Methods Pollyanna Gonçalves Belo Horizonte, Matheus Araújo
A Tutorial on Support Vector Machines for Pattern Recognition CHRISTOPHER J.C. BURGES
http://help.sentiment140.com/for-students (دیتا ست ها و تست دیتا ها)
https://github.com/ravikiranj/twitter-sentiment-analyzer/blob/master/data/feature_list/stopwords.txt
20.http://www.theguardian.com/news/datablog/2013/jun/10/social-media-analytics-sentiment-analysis