نویسنده این متن کیست؟ پروژه تشخیص خودکار نویسنده به دنبال روشهایی میگردد که به این پرسش پاسخ دهد.
در واقع این پروژه باید با استفاده از مجموعه کوچکی (کمتر از ۱۰ سند متنی) از یک نویسنده، به ازای هر سند متنی که نویسنده آن مجهول است، به این پرسش پاسخ دهد که آیا نویسنده سند مجهول نیز با سندهای قبل یکسان است یا خیر.
۱. مقدمه
تشخیص نویسنده ی متن در بسیاری از حوزه هایی که شامل بازیابی اطلاعات و زبان شناسی هستند یک مسئله مهم به شمار می رود، همچنین در زمینه های کاربردی مانند، تعقیب قانونی یک متن و روزنامه نگاری که پیدا کردن نویسنده ی یک متن ممکن است جان انسانی را نجات دهد (مانند یادداشتی برای باج خواهی)، از اهمیت به سزایی برخوردار است.
چارچوب کلی تمام راه حل های پیشنهادی برای حل این مسئله استفاده از طبقه بندی متن (Text Classification) است. به این ترتیب که با استفاده از تعداد محدودی سند از نویسنده های مشخص، نویسنده ی یک سند مجهول را می یابیم. مسئله ی مهم بعدی حصول اطمینان از این است که آیا سند جدید متعلق به یکی از نویسنده های شناخته شده می باشد یا خیر؟
در زندگی واقعی، زبان شناسان حرفه ای پزشکی قانونی خود برای تشخیص نویسنده ی مجهول اغدام می کنند. به منظور پر کردن شکاف میان زبان شناسی و علوم کامپوتر نیاز به بکارگیری و تلفیق تجربیات هر دو زمینه ی علمی وجود دارد.
۲. کارهای مرتبط
به عنوان یک راه حل برای این مسئله قصد داریم میزان شباهت متن های شناخته شده را با متن ناشناس بیابیم.
جهت مقایسه اسناد ابتدا باید کلمات موجود در هر سند متنی را طبقه بندی کنیم. برای این کار یک تحلیلگر لغوی ابتدا تمام لغات را از هم جدا کرده و حروف آن را به صورت کوچک درمی آورد تا بتوان راحت تر آنها را با یکدیگر مورد مقایسه قرار داد سپس stopword ها را که شامل لغاتی با تکرار زیاد و بدون معنای خاص هستند را حذف می کند. پس از این مرحله عمل بن یابی، یعنی یافتن بن افعال انجام می گیرد. با استفاده از تمام لغات باقی مانده ارزش یا وزن هر لغت در سند متنی مورد نظر مشخص می شود.
حال با استفاده از وزن لغات در سند متنی ناشناس و وزن لغات اسناد متنی معلوم می توان میزان شباهت اسناد را تعیین نمود و تشخیص داد که آیا یک نویسنده آنها را نگاشته یا خیر؟
در اینجا هدف اختصاص یک عدد در بازه صفر و یک، به سند متنی ناشناس است که میزان شباهت آن را با متن های شناخته شده تعیین می کند. به طوری که عدد صفر نشان دهنده این است که شباهتی بین اسناد وجود ندارد و عدد یک به معنای بیشترین شباهت بین متن ناشناس و متون شناخته شده است.
به منظور محاسبه شباهت این اسناد از فرمول زیر کمک می گیریم:
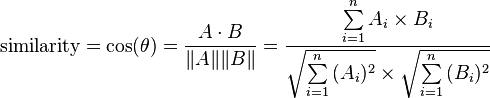
متغیر های A و B نشان دهنده تعداد تکرار یک لغت در هر یک از سندهای متنی هستند.
۳. آزمایشها
۴. کارهای آینده
۵. مراجع
Efstathios Stamatatos. A Survey of Modern Authorship Attribution Methods. of the American Society for Information Science and Technology, Volume 60, Issue 3, pages 538-556, March 2009.
# پیوندهای مفید