پیشنهاد دادن آنچه مخاطب از آن استقبال خواهد کرد، برعهده سامانههای توصیهگر است. این سامانهها که امروز، ما کاربر بسیاری از آنها هستیم، سعی میکنند از روی علاقهمندیهای ما و دیگران تصمیماتی بگیرند. در واقع این سیستمها با مد نظر قرار دادن الگوریتمها و الگوهایی سعی در مدل کردن رفتار محیط دارند به ترتیبی که بتوانند پیشنهاداتی بدهند که مورد استقبال محیط قرار بگیرد.
۱. مقدمه
با توجه به رشد روزافزون شبکهها از جمله شبکه اینترنت که کاربران در میان کارهای روزمره خود پیوسته در شرایطی قرار میگیرند که باید روی موارد مختلفی تصمیمگیری کنند و عمل انتخاب کردن در میان هزاران انتخاب ممکن است کار مشکلی باشد و در بسیاری از مواقع کاربران مررد میشود. بنابراین چقدر بهتر است اگر ما بتوانیم گزینههایی به کاربران بدهیم تا هم از آنها استقبال بشود و همچنین به طور موازی بتوانیم منفعت خود تحت این فرایند افزایش دهیم. برای مثال یک فروشگاه اینترنتی ساده را درنظر بگیرید که محصولاتی را برای فروش ارائه میدهد. اگر ما بتوانیم محصولاتی را که مورد توجه کاربر است، ارائه دهید میتوان به اهداف گفته شده در بالا رسید.
این سیستمها میتواند به صورت شخصیسازیشده کار کنند، یعنی هر کاربر سلیقه و اطلاعات شخصی خاص خود را دارد و توصیهها بر این اساس داده میشود در صورتی که نمونههایی را میتوان یافت که صرفا پر بازدیدترین صفحات یا پرفروشترین کالاها رو بدون توجه به سلیقه افراد پیشنهاد میدهند. عملا در روش دوم مدلسازی اتفاق نمیافتد و صرفا اطلاعات قبلی تحت آمار خاصی برگشت داده میشود و تمرکز ما نیز رو روش اول خواهد بود چرا که روش اول با توجه به این که قادر است پیشنهاداتی با دقت بسیار بالاتری بر مبنای علاقهمندیها و شباهتهای خاصی بدهد. در حال حاضر مطالعات بسیاری روی روش دوم انجام شده که در بخش بعد به آنها خواهیم پرداخت. [1]
مدلسازی در سیستمهای توصیهگر میتوانند اطلاعات مورد نیاز خود را که همان دیتاستها هستند را به شیوههای مختلفی جمع آوری کنند. آنهای میتوانند در لایههای زیرین یک سیستم نصب شوند و به صورت ضمنی اطلاعات کابران از حمله رفتار آنها را جمعآوری کنند.
در حالت کلی این سیستمها به چند دسته مختلف تقسیم میشوند که مهمترین آنها عبارتند از:
روش مبنتی از اشتراک1
روش مبتنی بر محتوا2
اما روش های دیگری نیز مانند روشهای مبتنی بر دانش3 و ترکیبی4 برای مدل کردن و پیش بینی استفاده میشود که در جلوتر به طور مختصر راجع به آنها میپردازیم.
۱.۱. روش مبنتی بر اشتراک
در این روش سعی داریم تا با استفاده از استخراج اطلاعات از رفتارها و عقاید کاربران در گذشته بتوانیم تشخیص دهیم که احتمالا این کاربر در حال حاضر علاقهمند به چه کالا یا آیتمی است تا با پیشنهاد دادن آن به کاربر ،نیازهای او رو برطرف سازیم. یکی از مهمترین مزایای این روش کارایی بالای آن است(البته باید توجه داشت که کارایی5ابعاد مختلفی دارد مثلا میتوانیم به بعد سرعت اشاره کنیم اما جنبههای دیگری مثل دقت وجود دارند که باید مورد بررسی قرار داده شوند.) و همین مورد باعث شده تا این روش به عنوان یکی از روشهای رایج در صنعت باشد. یک سیستم توصیهگر ساده عموما از یک ماتریس شباهت ساختهشده است. ردیفهای این ماتریس میتوانند کاربران و ستونهای آن آیتمها باشند. با بررسی این ماتریس میتوانیم شباهتهای کاربران را با هم بیابیم و پس از یافتن کاربران شبیه، مشغول پیشنهاد آیتمهای مورد علاقه کاربر پیدا شده را به کاربر جدید شویم. در ساده ترین حالت جدول فوق را در نظر بگیرید :
| User | Item1 | Item2 | Item3 | Item4 | Item5 |
|---|---|---|---|---|---|
| Alice | 5 | 3 | 4 | 4 | ? |
| User1 | 3 | 1 | 2 | 3 | 3 |
| User2 | 4 | 3 | 4 | 3 | 5 |
| User3 | 3 | 3 | 1 | 5 | 4 |
| User4 | 1 | 5 | 5 | 2 | 1 |
در این جدول میخواهیم علاقه مندی آلیس را به آیتم شماره پنج بیابیم. با توجه به اطلاعات جدول ابتدا باید نزدیک ترین کاربر را به آلیس پیدا کنیم و میزان نمره او را برای آلیس در نظر بگیریم. برای پیدا کردن کاربر مشابه نیز راههای مختلفی وجود دارد که یکی از آنها روش کوسین است. هر کاربر رو همراه با علاقهمندیهایش یک بردار میبینیم و میزان اختلاف بردارها را به صورت ریاضی محاسبه میکنیم و در انتها می توانیم کاربران مشابه را بیابیم[1].
اما یکی از روشهای ساده به نام روش پیرسن 6 که دارای پیادهسازی بسیار راحتی است را برای آشنایی با بحث و بررسی روال کامل پشنهاد کردن یک کالا توسط سیستم پیشنهادگر دنبال میکنیم. در این بخش در نظر داریم تا میزان علاقه آلیس، که در جدول بالا آمده را به کالا پنجم بیابیم.
همان طور که گفته شد اولین قدم یافتن نزدیک ترین کاربر به آلیس است، برای این کار ما می خواهیم از فرمول مذکور استفاده کنیم. در فرمول زیر
میزان شباهت دو کاربر با توجه به میانگینها رای آنان بدست میآید، اما علت تفریق رای از میانگین این است که چون این امکان وجود دارد که هر کاربر با سلیقه خاص خود رای بدهد(منظور این که مثلا یک کاربر بهترین رایش ۳ است و بدترین آن ۲ پس اگر او به کسی ۵ داد مشخص میشود که رای او فوقالعاده است و اگر به کسی ۱ بدهد مشخص میشود که واقعا از آن خوشش نیامده ولی اما شرایطی را در نظر بگیرید که یک کاربر عموما به همه ۵ بدهد، این نشان میدهد که او به خودی خود نمرههای بالایی رو در نظر میگیرد و احتمالا ۵ برای کاربر فعلی برابر با ۳ برای یک کاربر سخت پسند است.)

پس از بدست آوردن شباهت حال وقت این است که برای آلیس پیشبینی کنیم که چقدر به کالای ۵ علاقهمند است.

و در نهایت با استفاده از فرمول زیر می توانیم میزان علاقه کاربران را بیابیم. اما روشهای هم ارز زیادی برای فرمول پیرسن وجود دارند که هر کدام خاصیت خود را دارند و در موارد خاص خود مورد استفاده قرار خواهند گرفت که عبارتند از:
Cosine Similarity
Spearman’s Rank Correlation Coefficient
Mean Squared Difference
اما روشهای بحث شده کاملا مبتی بر شباهت بین کاربران بود. همانطور که قبلا گفته شد روشهایی وجود دارند که با توجه به شباهت کالاها کار میکنند که در اینجا از توضیح و تشریح نمونه برای این مورد صرفه نظر میشود. یکی از مشکلاتی که میتوان برای این روش ذکر کرد این است که چه اتفاقی میافتد اگر ما هیچ اطلاعات قبلی را از کاربر نداشته باشیم ؟ که این شرایط را Cold Start(این موضوع را در جلوتر بررسی خواهیم کرد) میگوییم.[2].
برای فهم بهتر نحوه یافتن کاربرهای شبیه و همینطور پیشنهاد کردن صحیح، به شکل زیر توجه کنید:

۱.۲. روش مبنتی بر محتوا
یکی دیگر از روشهای توصیه این است که ما طبق محتوای محصولات و موارد مورد علاقه کاربر بتواینم موارد مشابه آن را بیابیم و به او پیشنهاد دهیم. ساده ترین استفاده از این سیستم در موتورهای جستوجو است، فرض کنید ما تعداد زیادی صفحه داریم که باید آنها را خیلی سریع برای کاربران بر طبق متنی که جستوجو میکنند نمایش دهیم بنابراین ما باید تمام صفحات اینترنت در ایندکس 7 تا قادر باشیم در کمترین زمان خروجی را برگردانیم. اما چگونه میتوان شباهت بین صفحات اینترنت را یافت؟ پاسخ این که روشهای بسیاری برای شباهت متن مخصوصا در زبان انگلیسی وجود دارد که یکی از رایجترین آن روش TF-IDF است[2] اما از ذکر چگونگی روش صرفه نظر میشود چرا هدف بخش پروژه صرفا آشنایی با چهارچوب اصلی موضوع است نه جزئیات دقیق. ذکر این نکته ضروری است که ارتباط بسیار عمیقی بین سیستمهای توصیهگر و همینطور سیستمها ذخیره و بازیابی اطلاعات وجود دارند زیرا جستوجو و استخراج اطلاعات به صورت Automative و آن هم به صورت معنی دار عاملیست تا این دو زمینه به همدیگر نزدیک شوند. شایان ذکر است که مشکل Cold Start هم که یکی از مشکلات روش قبلی بود که با روش مبتنی بر محتوا تا حدود زیادی قابل حل است. همچنین در این روش ما قادرین تا از الگوریتمهای مختلف کلاسبندی8 استفاده کنیم.
۱.۲.۱. روش term frequency-inverse document frequency)tf-idf)
در این روش، Tf-idf در واقع یک آمار عددی است که نشان می دهد هر کلمه موجود در یک سند ، در میان مجموعه ای از اسناد چه قدر اهمیت دارد . این مقدار معمولا به عنوان فاکتور وزنی در بازیابی اطلاعات به کار می رود. مقدار tf در ساده ترین حالت نشان دهنده ی فرکانس خام یک کلمه(t) در یک سند(d) است (تعداد دفعات رخداد کلمه در سند).
۱.۳. آموزش سیستم
در مجموع میتوان گفت که روشهای بسیاری برای مدل کردن سیستم وجود دارند اما باید این نکته رو مد نظر قرار داد که همه آنها در یکی از دو دسته کلی قرار میگیرند. لازم به ذکر است که ما برای غنی کردن سیستم خود به لحظ اطلاعات میتوانیم به دو صورت کلی عمل کنیم.
در حقیقت این که شما چه چیزی را پشنهاد کنید خیلی موردی مهمی نیست بلکه این که مدل شما چگونه عمل میکند مورد مهمتری خواهد بود اما نمیتوان از یاد برد که نوع کالاها و محیط همواره بر روی عاملهای هوش تاثیر خاص خود را میگذارند.
روش صریح به این معنی که از کابران خواسته شود که نظر خود را راجع به محصولات مختلف در سیستم قرار دهند تا ما بتوانیم آنها را استخراج کنیم و از آنها بهره بجوییم.
روش ضمنی به این معنی که با مانیتور کردن کاربران در یک سیستم(با تمرکز کردن بر روی رفتار آنها) سعی در تشخیص علایق کاربران داریم.
۲. کارهای مرتبط
تا به این جا سعی شد تا مسئله به درستی شرح داده شود و اصول کلی حل مسئله آشنا شدهایم اما در این قسمت تلاش شده تا کارهایی که در مقالههای مختلف در این زمینه انجام شده و اینجانب آنها مطالعه کردهام را شرح و توضیح دهیم اما با توجه به این که با توجه علاقه، اینجانب سعی کردم در حوزه توصیه بازیهای رایانهای جست و جو و فعالیت کنم اما نکتهای که مهم است این است که موضوعی که میخواهیم پیشنهاد کنیم شاید خیلی مهم نباشد بلکه نحوه مدل کردن سیستم موضوع مورد اهمیت است چرا شما به راحتی میتوانید مدل خود را روی موضوعات مختلفی استفاده کنید.
۲.۱. سامانه توصیهگر بازی
اولین مطلبی که مورد بررسی قرار گرفت سیستم توصیهگری بود که در دانشگاه هاروارد برای بازیهای رایانه ای ساخته شده بود[4]. دیتاستهای این سیستم از مجموعه سایتهای مختلفی جمعآوری شده است که به بازیهای رایانه بر اساس نظرهای مردم رای و ربته میدهند.
در این سیستم دو نوع بررسی انجام شده است:
مدل Naive Bayes
مدل Random Forest
در حقیقت سیستم برای یادگیری و تولید مدل از دو روش بالا استفاده شده است. البته با رشد تکنولوژی و به تبع آن بازیهای رایانهای خروجی این پروژه که به عنوان پروژه پایانی یکی از دانشجویان دانشگاه هاروارد انجام شده است، تقریبا ارزش خاصی ندارد. با توجه به این که چنین پروژههایی بیشتر باید بار پیادهسازی داشته باشند تا تئوری به همین دلیل روی داکیومنت کردن پروژه خیلی تلاشی نشده است. برای دنبال کردن کار ایشان میتوان اطلاعات بهروز و معتبر را از دیتاستهای Steam(یک سیستم آنلاین تخصصی مخصوص بازی است که توسط شرکت بازی سازی Valve ساخته شده است) جمعآوری کنیم. همچنین این شرکت Apiهایی طراحی کرده است تا برنامه نویسان بتوانند از آنها استفاده کنند و از دیتاهای آنان بهره ببرند. اما اگر به کد استفاده شده در سیستم مورد نظر نگاه کنیم خواهیم دید که برنامه نویس از روش MapReduce برای پردازش اطلاعات استفاده کرده است. با عنایت بر این که ما قطعا در آینده باید آزمایشاتی انجام دهیم، پس آشنایی با بحثهای پیادهسازی و ایده گرفتن از آنها میتواند برای ما مفید باشد.
۲.۱.۱. روش Map Reduce
در این روش [7] یکی از روش های مفید و تاثیر گذار در حوزه پردازش اطلاعات بسیار بزرگ است، ایده اصلی به این صورت است که ما بیایم اطلاعات را به بخشهای مختلفی 9 تقسیم کنیم. بعد از آن شروع به پردازش این قسمتها به صورت توزیع شده بین پردازهها، نخها یا سیستمهای متصل به هم تحت شبکه انجام دهیم. با توجه به این که اطلاعات بزرگ اولیه به قسمتهای کوچکتری تقسیم شده است بنابراین پردازش آنها برای واحدهای پردازشی ما آسانتر است یا حداقل با سیستم ضعیفتری هم این امکان برای ما فراهم است که پردازشها را انجام دهیم. بعد از این که واحدهای پردازشی(Map) اطلاعات را پردازش کردند باید نتیجه را به صورت که دوتایی (key, value) تولید کنند تا سیستمهای دیگری به نام Reduce که هر کدام وظیفه گرفتن اطلاعات با یک کلید خاص را دارند، اطلاعات را جمع آوری و معنیدار کنند. همینطور با توجه به نیاز بیش از پیش پردازش مجموعه دادههای حجیم، شرکتهای بزرگ مختلفی مانند آمازون این امکان را برای ما فراهم کردهاند تا برنامههای MapReduce خود را روی خوشه10 های آنان اجرا کنیم که اتفاقا پروژه انجام شده در بالا از سرویسهای شرکت آمازون برای تولید ماتریس شباهت ۱.۶گیگابایتی خود استفاده کرده است . برای درک بهتر این روش به یک مثال میپردازیم:
۲.۱.۲. کاربرد
امروزه از این روش در حوزه بازیابی اطلاعات11 استفاده میشود و اولین مثال آنها شمردن تعداد وقوع هر کلمه در یک متن بسیار بزرگ است. سیستم به این صورت عمل میکند که ابتدا متن رو به قسمتهایی تقسیم میکند و هر سیستم شروع به پردازش قسمت مربوط به خود میکند به این صورت که با مشاهده هر لغت یک دوتایی (Word,1) تولید میکند و بر میگرداند و بعد از آن سیستمهای Reduce با گرفتن کلید مخصوص خود مثلا (Word, 1) میزان دوتایی ذخیره شد در خود (Word , 5) به با مقدار جدید جمع و ذخیره میکند (Word, 6) و به همین ترتیب تعدادهای صحیح برای کلیدهای مختلف که کلمات ما هستند بدست میآید به شکل زیر توجه کنید:
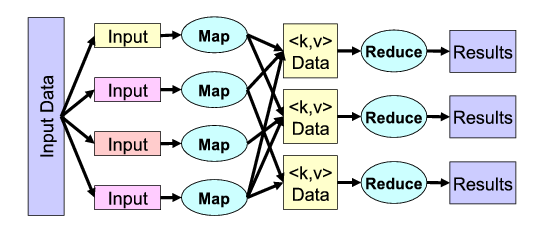
به شبه کد مقابل دقت شود:
function (String name, String document):
// name: document name
// document: document contents
for each word w in document:
emit (w, 1)
function(String word, Iterator partialCounts):
// word: a word
// partialCounts: a list of aggregated partial counts
sum = 0
for each pc in partialCounts:
sum += pc
emit (word, sum)
۲.۲. مجموعه خانواده الگوریتمهای Slope One
این مجموعه الگوریتمها بر مبنای الگوریتمهای مبنتی بر اشتراک کار می کنند که به بررسی آن میپردازیم[7]. در این روش تمرکز بر روی شباهت آیتمهای امتیاز داده شده با هم است تا شباهت کاربرها با یکدیگر و ذکر این نکته ضروری است که اگر دادههای ما به صورت باینری باشند نمیتوانیم از این روش استفاده کنیم( برای مثال این که موضوع مورد بررسی ما خریدن یا نخریدن یک کالا باشد، پس برای هر کالا دو حالت وجود دارد خریدن(۱) و نخریدن(۰)) و میتوانیم به عنوان روش جایگزین از همان روش کوسین برای پیدا کردن آیتمهای مشابه بهره ببریم. این روش هنگامی سودمند است که ما دادههایی را داشته باشیم که کاربران به آنها نمره داده باشند(مثلا عددی بین ۱ تا ۵ به کالاها بدهیم، کاری که ما در فروشگاه کافهبازار برای نرمافزارها و بازیهای مختلف با عنوان نظر دادن انجام میدهیم). در واقع این روش سعی میکند کالاهایی را که یک کاربر دوست ندارید را از مواردی که دوست دارد به خوبی تفکیک کند.
۲.۲.۱. مزایای روش
پیاده سازی ساده.
کارایی بالا در هنگام جست و جو.
دقت بالا.
به روش رسانی در لحظه به این ترتیب که تغییر نظر برای کابران میتواند همه نتایج را در لحظه تغییر دهد.
انتظار حداقلی برای کاربران تازه وارد به این معنی که با این روش تا حدی مشکل Cold Start بهبود یافته است.
مناسب برای جست و جوهای آنلاین و پویا که آن را برای سیستمهای دنیای واقعی مناسب میکند.
۲.۲.۲. نحوه عملکرد
همانطور که در تعریف و توضیح سیستمهای مبتنی بر شباهت تاکید شد، ما در حالت کلی یک ماتریس شباهت داریم که ردیفهای آنهای کاربران و ستونهای آن محصولات هستند که در درایههای ماتریس میزان رای هر کاربر به کالای مخصوص داده میشود. فرض کنید دو آیتم i , j داریم که کاربر A به ترتیب امتیازات ۱ و ۱.۵ را به هر کدام داده در صورتی که کاربر B به آیتم i امتیاز ۲ را داده است. حال میخواهیم ببینیم که این کاربر به آیتم j چند میدهد.
کاری که در ذات این شیوه انجام میشود این است که ابتدا اختلاف امتیاز دو آیتم را برای کاربر A محاسبه میکنیم و سپس بعد از آن آن اختلاف را به امتیاز کاربر B اضافه میکنیم که در اینجا داریم :
| j | i | User |
|---|---|---|
| 1.5 | 1 | A |
| ? | 2 | B |
البته این مثال سادهترین روش را نشان میدهد و صرفا جهت آشنایی با موضوع است.
در این مقاله روشهای مختلفی مورد بررسی قرار گرفته است که اینجانب صرفا در این جا ذکر نام میکنم و از توضیح و تفصیل بیشتر هر مرحله چشمپوشی میکنم. امید است که توضیح دقیق فرمولها و نکات هر کدام در بخش آزمایشها انجام شود.
Model based scheme
Memory based scheme
Baseline Schemes
The PEARSON Reference Scheme
The SLOPE ONE Scheme
The WEIGHTED SLOPE ONE Scheme
The BI-POLAR SLOPE ONE Scheme
۲.۳. سامانه توصیهگر بازی اولیه[9]
در این مقاله به این گونه بحث شده بود که ابتدا ما نیاز به یک سیستم قوی و مجزا به توصیه بازیهای رایانه ای داریم و این ادعا هم بر مبنای یک سری داده و ارقام است، البته بنده به هم اعتقاد دارم که برای پیشنهاد کردن بازیهای رایانهای علاوه بر داده و ارقام باید مدلی طراحی شود که بتوانیم از روی آن حالات روحی و روانی کاربران را نیز تشخیص دهیم و پیشبینی کنیم چرا که اولین نقطه که بازیهای رایانه بر روی آن تاثیر میگذارند روح و روان بازیکنان است بنابراین در زمان انتخاب بازی نیز یکی از عوامل تاثیرگذار همان روحیه بازیکن یا خریدار است. روش این مقاله بر پایه روشی است که در مراجع آن اشاره شده است (تحلیل اولیه[10] 12). روش به این صورت است که در ابتدا از روش معرفی شده برای جمع آوری اطلاعات پایه استفاده میکند و سپس برای پیشنهاد کردن دو مدل را معرفی کرده است:
Archetypal Top-L Recommender Systems
Neighborhood Oriented Models
که هر روش ویژگیهای خاص خود را دارد اما ما در اینجا صرفا نتیجه نهایی رو نشان میدهیم. در صورتی که به پیادهسازی این روش بپردازیم قطعا جزئیات بیشتری را خواهیم آورد.

۳. آزمایشها
همانطور که در بخشهای قبل تصمیم گرفتیم روی یکی از الگوریتمهای ذکر شده با دقت بیشتری کار کنیم، در این بخش سعی شده تا الگوریتمهای Slope One را مورد بررسی قرار دهیم. برای این منظور ابتدا باید یک مجموعه داده مناسب را پیدا کنیم که بتوانیم با آنها الگوریتمها را مورد ارزیابی قرار دهیم.
نویسندگان مقاله از دوسری داده مجزا برای ارزیابی الگوریتم خود استفاده کردهاند اما متاسفانه در حال حاضر تنها یکی از آنها موجود بود و ما نیز پس از پیاده سازی الگوریتم از مجموعه دادههای موجود استفاده کردیم.
الگوریتمی که دقیقا پیاده سازی شده است، الگوریتم SLOPE ONE است. نحوه پیاده سازی آن را میتوانید در اینجا پیدا کنید.
۳.۱. معرفی دیتاست
این دیتاست متشکل از ۱۰۰۰۰۰ رای است که توسط ۹۴۳ کاربر به ۱۶۸۲ محصول داده شده است. قابل ذکر است که هر کدام از کاربران نیز حداقل به ۲۰ فیلم رای دادهاند. ابتدا باید دادههای دیتاست را به صورتی آماده سازی کنیم که چگونگی این عملیات در نمونه مستندات موجود در دیتاست وجود دارد. داده به ۵ مجموعه تقسیم میشوند که هر قسمت به دو بخش( یک بخش ۲۰ درصدی دادهها که دادههای تست ما هستند و مابقی آنها به عنوان دادههای آموزشی خواهند بود ) تقسیم میشود. باید توجه داشت که هر کدام از این پنج بخش با هم هیچی اشتراکی ندارند. در این تقسیم بندی تعداد رایها هم در دادههای آموزشی و هم در دادههای تست مشخص نیست و هر عددی میتواند باشد.
۳.۲. معرفی الگوریتم
همانطور که از قسمتهای گذشته مشخص است ما برای آزمایش دیتاست از الگوریتم Slope One استفاده کردهایم که فرمول تئوری آن به صورت زیر است. همچنین لازم به ذکر است که فرمول زیر سادهترین نوع از این خانواده است.
در فرمول بالا u آرایهای است که کاربر به تمام آیتمهای مورد نظر خود رای داده است، و مقداری که در فرمول وجود دارد میانگین این آرایه است و همینطور متغییر card نشان دهنده تعداد رایهای کاربر است و مجموعه S هم کل مجموعه رایهای کاربران به itemهای مورد نظر است. مقدار پیشبینی بر اساس میانگین رای کاربر و انحراف رای کل کاربران از میانگین رایشان به آن item خاص به دست میآید.
۳.۳. روش ارزیابی آزمایشات
پس از پیاده سازی الگوریتم فوق ما به منظور ارزیابی، از روش Mean absolute error استفاده کردیم که به صورت زیر است:
در رابطه بالا f ها پیشبینیهای ما و yها مقادیر صحیح هستند.
ارزیابی به این ترتیب است که مقادیر مختلف راْیها را ابتدا به سیستم میدهیم به جز مواردی خاصی که برای تست سیستم میخواهیم از آنها استفاده کنیم. همان طور که میدانیم الگوریتم عامل ما در این سیستم بر مبنای شباهت item ها در دادهها کار می کند و هیچ گونه اطلاعاتی به ازای کاربران نگهداری نمیشود، بنابراین ما برای ارزیابی، موارد موجود در دادههای تست را برای هر کاربر جمع آوری و مرتب میکنیم و آن به سیستم میدهیم تا مقادیر پیشبینی شده را به ازای همه itemها به ما بدهد.
اگر به ازای مقادیر پیشبینی شده مقدار صحیحی در مجموعه دادهها داشتیم( به این معنی که کاربر قبلا به آیتم رای داده بود ) ما قادر خواهیم بود تا میزان خطا را حساب کنیم و در غیر این صورت از آن پیشبینی صرفه نظر میکنیم و مقدار بعدی را مورد بررسی قرار میدهیم.
۳.۴. نتایج
نتایج این آزمایش به ازای هر قسمت از مجموعه داده به شرح زیر است :
| سری ۱ | سری ۲ | سری ۳ | سری ۴ | سری ۵ |
|---|---|---|---|---|
| ۰.۰۲۳۶۴۸۲۰۴۹۷۸۱ | ۰.۰۰۷۳۵۳۳۹۹۴۰۲۱۴ | ۰.۰۲۲۲۳۸۶۵۵۹۸۳۲ | ۰.۰۱۸۸۹۹۵۹۵۷۵۵۲ | ۰.۰۲۲۲۳۸۶۵۵۹۸۳۲ |
میانگین کلی آزمایشات برابر با۰.۰۱۱۲۶۴۰۸۵۸۸۸۱ است که اگر این رقم را بر ۵ تقسیم کنیم تا بتوانیم حجم اختلاف را نسبت به کل بازه ببینیم به عددی نزدیک به ۰.۲۲ درصد خطا خواهیم رسید.
۴. بهبود الگوریتم
الگوریتم تست شده در بخش قبلی تنها از شباهتهای آیتمها با یکدیگر استفاده میکرد و به اطلاعات راجع به کاربر توجه خاصی نمیکرد. با عنایت به همین مطلب میتوان سیستمی طراحی کرد که هم از اطلاعات شخصیسازی شده کاربران و هم از اطلاعات استخراج شده از شباهت آیتمها با یکدیگر استفاده کند.[11]
۴.۱. معرفی الگوریتم slope one اصلاح شده
در این الگوریتم به علاوه اطالاعات قبلی از پارامترهای خاصی برای کاربران استفاده شده است:
Item Usefulness
از این داده به عنوان یک معیار برای وزن دادن به هر کالا استفاده میشود که این داده کاملا به ازای هر کاربر شخصیسازی شده استper user trustiness
با توجه به این که در این الگوریتم در نظرات کاربران رو نظران دیگر کاربران نیز استفاده شده است بنابراین کاربرانی که بر روی نظرات دیگر کاربران نظر داده اند قطعا بیشتر مورد توجه هستند و ما میتوانیم به آنها بیشتر اتکا کنیم
۴.۱.۱. روش Per User Trustiness
در این روش تلاش میکنیم تا مشخص کنیم هر کاربر به کدام یک از کاربران دیگر اعتماد دارد و این مقدار در مقام عمل توسط متغیری به نام web of trust محاسبه میشود، به شکل رو به رو توجه کنید:

برای مثال در شکل بالا کاربر A به کاربران B و C اعتماد دارد و این دو کاربر نیز به کاربر D اعتماد دارند. اگر معادله اولیه الگوریتم را به خاطر بیاورید :
در این معادله اثری از اعتماد کاربران وجود ندارد ولی ما میتوانیم میزان اختلاف رای دیگر کاربران از میانگین را در میزان اعتماد به همین کاربر ضرب کنیم. با این کار اگر به کاربری اعتماد زیادی داریم و او از میانگین فاصله زیادی دارد بنابراین ما نیز با احتمالا خوبی از میانگین فاصله داریم و اگر خیر شرایط میتواند بر عکس شود. اما مهمترین نکته این است که دیگر همه کاربران برای ما مساوی نیستند و بسته به اعتماد ما به آنها توجه ما به آنها نیز تحت تاثیر قرار میگیرد.
۴.۱.۲. روش Item Usefulness
در این روش سعی شده تا بین کالاهایی که توسط کاربران بیشتری مورد قضاوت قرار گرفته اند و کالاهایی که کمتر مورد توجه قرار گرفتهاند تفاوت قائل شویم.
برای محاسبه این نیز باید محاسبات دیگر نیز انجام دهیم که این خود مستلزم ماتریس دیگری که تعداد آیتمهایی که توسط کابران مختلف co-rate شده اند را نگه داریم قطعا در این روش ما performance را حال در ابعاد مختلف مانند: سرعت جست و جو ، حافظه استفاده شده برای نگهداری اطلاعات از دست خواهیم داد.
از معرفی فرمول مربوط به این بخش صرفه نظر شده است چرا که برای بررسی آن باید تعدادی دیگری فرمول معرفی میشد.
۴.۱.۳. نتایج روش
در نهایت با ادغام این رو روش ما میتوانیم نتایج بهتری از روش اصلی بدست آوریم اما ذکر این نکته مهم است که پاسخهای دقیق تری که بدست آوردیم به قیمت میزان خوبی کارایی تمام شد. محققان این روش آزمایشات خود رو روی سه دیتاست تست کردهاند که اولین آن همان دیتاستی است برای تست در بخشهای قبلی این مقاله مورد استفاده قرار گرفته است.
۵. کارهای آینده
روشهای مختلفی برای بهبود الگوریتم پایه Slope One به کار گرفته شده است. برای مثال میتوان به استفاده از المان زمان برای رای کاربران اشاره کرد. هر چقدر کاربران به اختلاف کمتری نسبت به حال به کالاها رای داده باشند پس احتمالا رای او برای ما ارزش بیشتر خواهد داشت و همین طور اگر رای ثبت شده توسط متعلق به زمانهای دور تری نسبت به بقیه کاربران باشد بنابراین میتوانیم بگوییم که این کاربر برای ما جالب توجه نخواهد بود.
۶. مراجع
[1] Jannach, Zanker, Felfernig, Friedrich(2011). "Recommender systems : An Introduction". Cambridge University Press
[2] A.Rajaraman, J.D.Ullman(2010, 2011). "Mining of Massive Datasets". Stanform Publication
[3] Terveen, Loren; Hill, Will (2001). "Beyond Recommender Systems: Helping People Help Each Other". Addison-Wesley. p. 6. Retrieved 16 January 2012
[4] http://www.felixgonda.com/cs109/
[5] https://en.wikipedia.org/wiki/Naive_Bayes_classifier
[6] Jeffrey Dean and Sanjay Ghemawat, MapReduce: Simplified Data Processing on Large Clusters (http://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf), OSDI'04: Sixth Symposium on Operating System Design and Implementation,San Francisco, CA, December, 2004.
[7] Daniel Lemire, Anna Maclachlan, Slope One Predictors for Online Rating-Based Collaborative Filtering (http://arxiv.org/abs/cs/0702144), In SIAM Data Mining (SDM'05), Newport Beach, California, April 21–23, 2005.
[8] https://en.wikipedia.org/wiki/Collaborative_filtering
[9] R Sifa, C Bauckhage, A Drachen - Proc. KDML-LWA, 2014 - ceur-ws.org
[10] Cutler, A., Breiman, L.: Archetypal Analysis. Technometrics 36(4), 338–347 (1994)
[11] Weighted Slope One Predictors Revisited, Available_Url: http://www2013.org/companion/p967.pdf
پیوندهای مفید
Collaborative-Filtering
Content-Based
Knowledged-Based
Hybrid Recommendation
Performance
Pearson’s correlation coefficient
Index
Classification Algorithms
Shard
Cluster
Information Retrieval
Archetypal Analysis