
۱. مقدمه
تشخیص حالت چهره از مهمترین چالش های پردازش تصویر محسوب می گردد و امروزه این موضوع کاربردهای فراوانی پیدا کرده است . از نمونه این کاربرد های ارتباط انسان با کامپیوتر است که با استفاده از روشهای تشخیص حالت میتوان یک ارتباط به اصطلاح قلبی میان انسان و کامپیوتر ایجاد کرد .به عنوان مثال ربات هایی ساخت که با خوشحالی شما خوشحال و با ناراحتی شما ناراحت شوند . از جمله کاربردهای دیگر این بحث در طراحی انیمیشن و فیلم های کارتونی است به این صورت که اگر یک شخصیت کارتونی حرکات صورت خود را برای نمایش یک حالت از چهره ی یک انسان الهام بگیرد نمایش حالت مورد نظر بسیار حقیقی تر بوده و طراحی نیز ساده تر میگردد .
تشخیص حالات مختلف از روی ویژگی های صورت به خصوص ویژگی های مربوط به چشم ُ دهان و ابرو ها انجام میگیرد و با استفاده از قوانینی که جهت تمییز حالات مختلف از یکدیگر تعریف میشود میتوان حالت چهره را با دقت خوبی مشخص کرد .
۲. کار های مرتبط
شش حالت اصلی چهر ه که اغلب برای تشخیص در نظر گرفته میشوند عبارتند از : خوشحالی ْ ناراحتی ْ خشم ْ تعجب ْ ترس و تنفر .
جهت تشخیص حالت میبایست ابتدا با انجام یک سری پیش پردازش ها ناحیه مورد پردازش را روی صورت مشخص نمود یعنی مربعی که در آن دقیقا صورت قرار داشته باشد و باقی قسمت های تصویر حذف شوند . در مرحله بعد میبایست یک سری ویژگی از تصویر صورت استخراج شود . سپس هر حالت چهره به وسیله ی یک دسته بند دسته بندی شود .
داده ها که شامل تصویر ها از حالات مختلف میباشد را به دو قسمت آموزش و آزمایش تقسیم مینماییم و با قسمت آموزش دسته بندی ها را یاد گرفته با قسمت آزمایش تست برنامه را انجام میدهیم .

در شکل زیر 21 نقطه به عنوان نقاط مشخصه در نظر گرفته شده اند .

در مرحله پیش پردازش تصویر های چهره نرمال سازی می شوند و اگر نیاز بود ،برای افزایش کارائی تشخیص سیستم بهبود می یابند .برخی یا تمام مراحل پیش – پردازش زیر ممکن است در یک سیستم تشخیص چهره پیاده سازی شوند :
.1نرمال سازی اندازه ی تصویر .این کار معمولا انجام می شود تا اندازه ی تصویر گرفته شده به یک اندازه تصویر پیش فرض مانند 128*128تغییر کند ،این اندازه ی تصویر همان اندازه ی تصویری است که سیستم تشخیص چهره با آن کار می کند.
برای حذف اثر فاصلۀ دوربین نسبت بهشخص ،کمیتی بنام BASEکه در واقع فاصلۀ بین انتهای داخلی چشم ها می باشد ،در نظر گرفته شده و تمام مقادیر
اندازه گیری شده نسبت به این کمیت نرمالیزه می شوند.
برای اینکه مختصات AUها در تصـاویر مختلـف نسـبت بـه یک مرجع ثابتی اندازه گیری شوند ، نقطه مرجع تقریبا نوک بینی میتواند فرض شود به عنوان مبدا مقایسه ی مختصات AU ها در تصاویر مختلف در نظر گرفته میشود .
مختصات مبدا برابر خواهد بود با :
.2یکسان سازی هیستوگرام .این معمولا بر روی تصاویر خیلی تاریک یا خیلی روشن برای بهبود کیفیت تصویر و بهبود کارآئی تشخیص چهره انجام می شود که گستره ی contrastتصویر را اصلاح می کند که به عنوان نتیجه ،برخی ویژگیهای مهم چهره آشکارتر می شوند.
.3فیلترینگ میانه .برای تصاویر دارای نویز ،به خصوص تصاویری که از طریق دوربین عکاسی و یا frame grabberگرفته شده است ،فیلترینگ
میانه می تواند تصویر را بدون از دست رفتن اطلاعات تمیز کند. .
4.فیلترینگ بالا گذر .استخراج کننده های ویژگی ای که مبتنی بر روی کلیات چهره هستند ،ممکن است از تصویری که لبه یابی روی آن صورت گرفته است نتیجه ی بهتری بدهند .فیلترینگ بالا گذر بر روی جزئیاتی مانند لبه ها تاکید دارند که در نتیجه کارآئی تشخیص لبه را افزایش می دهد.
حذف اثر دورانی نیز از جمله پیش پردازش ها جهت تشخیص چهره و سپس حالت آن میباشد.θ نیز زاویه BASE نسبت به افق است که جهت حذف دوران صورت در نظر گرفته میشود .
بدین ترتیب مختصات جدید هر یک از AUها نسبت به مبدا بدست آمده به صورت زیر محاسبه میگردد:
پس از انجام پیش – پردازش ( اگر لازم بود )تصویر چهره ی نرمال شده به منظور پیدا کردن ویژگیهای کلیدی ای که قرار است برای دسته بندی از آنها استفاده شود ،به ماژول استخراج ویژگی فرستاده می شود .به عبارت دیگر در مرحله feature extraction میبایست ویژگی های تصویر را با استفاده از کتابخانه های موجود استخراج نمود . اینکار درواقع خطا های ابعادی تصویر ورودی را کاهش میدهد و ویژگی هایی قابل پردازش از تصویر ارائه میکند .
روشهای مختلف استخراج ویژگی بنا به فلسفهٔ پشت سرشان ممکن است یک یا چند کار زیر را انجام دهند:
حذف نویز دادهها
جداسازی اجزای مستقل دادهها
فروکاهی ابعاد برای تولید بازنمایی مختصرتر
افزایش بعد برای تولید بازنمایی جداییپذیریتر
الگوریتم استخراج ویژگی مورد نظر برای پیاده سازی این مسئله الگوریتم SIFT میباشد .
الگوریتم SIFT یا (Scale-invariant feature transform) یا تبدیل مستقل از مقیاس ویژگی ، یک الگوریتم در بینایی ماشین است که برای استخراج ویژگیهای مشخص از تصاویر، برای استفاده در الگوریتمهای کارهایی چون تطبیق نماهای مختلف یک جسم یا صحنه(برای نمونه در دید دوچشمی) و شناسایی اجسام به کار میرود. ویژگیهای بدست آمده نسبت به مقیاس تصویر و چرخش ناوردا و نسبت به تغییر دیدگاه و تغییرات نورپردازی تا اندازهای وابسته نیست.
گامهای اصلی در محاسبه ویژگیهای تصویر عبارتاند از:
آشکارسازی اکسترممهای فضای مقیاس - هر پیکسل در تصاویر با هشت همسایهاش(پیکسل متناظر و هشت همسایهاش) مقایسه میشود.
محلیسازی کلیدنقطهها - کلیدنقطهها از اکسترممهای فضای مقیاس گزیده میشوند.
گرایش گماری - برای هر کلیدنقطه در یک پنجره ۱۶x۱۶، نمودار فراوانی گرایش گرادیانها به کمک درونیابی دوسویه محاسبه میشوند.
توصیفگر کلیدنقطه - نمایش در یک بردار ۱۲۸ عنصری.
در ماژول دسته بندی ،با کمک یک دسته بند الگو ،ویژگیهای استخراج شده از تصویر چهره با آنهایی که در کتابخانه ی چهره ( یا پایگاه داده ی
چهره ) ذخیره شده اند مقایسه می شود .پس از انجام این مقایسه ،تصویر چهره بر اساس حالت آن دسته بندی می شود.
الگوریتم دسته بندی مورد استفاده الگوریتم svm است . ماشین بردار پشتیبانی (Support vector machines - SVMs) یکی از روشهای یادگیری بانظارت است که از آن برای طبقهبندی و رگرسیون استفاده میکنند .
ماشین بردار پشتیبان خطی:
ما مجوعه داده های آزمایش D شامل n عضو(نقطه)را در اختیار داریم که به صورت زیر تعریف می شود:

جایی که مقدار y برابر ۱ یا -۱ و هر xi یک بردار حقیقی p-بعدی است. هدف پیدا کردن ابرصفحه جداکننده با بیشترین فاصله از نقاط حاشیه ای است که نقاط با y_i=1 را از نقاط باy_i=-1 جدا کند. هر ابر صفحه می تواند به صورت مجموعه ای از نقاط x که شرط زیر را ارضا می کند نوشت:w.x - b=0
جایی که . علامت ضرب است. w بردار نرمال است، که به ابرصفحه عمود است. ما می خواهیم w و b را طوری انتخاب کنیم که بیشترین فاصله بین ابر صفحه های موازی که داده ها را از هم جدامی کنند، ایجاد شود. این ابرصفحه ها با استفاده از رابطه زیر توصیف می شوند.


اگر داده های آموزشی جدایی پذیر خطی باشند، ما می توانیم دو ابر صفحه در حاشیه نقاط به طوری که هیچ نقطه مشترکی نداشته باشند، در نظر بگیریم و سپس سعی کنیم، فاصله آنها را، ماکسیمم کنیم . با توجه به شکل زیر ، جهت ماکسیمم کردن فاصله میبایست نُرمِ w را مینیمم کنیم .

برای اینکه از ورود نقاط به حاشیه جلو گیری کنیم، شرایط زیر را اضافه می کنیم:
به ازای هر i یکی از شرایط زیر میبایست برقرار باشد :


که شرط اول برای xi های کلاس اول ، و شرط دوم برای xi های کلاس دوم میباشد .
و ترکیب این دو شرط را میتوان به صورت کلی اینگونه بیان کرد :

بنابراین مسئله ی بهینه سازی شامل مینیمم کردن w با شرط بالا خواهد بود .
فرم اولیه :
حل مسئله بهینه سازی بالا به دلیل وابستگی به نرم w سخت میباشد اما ما میتوانیم مسئله را به فرم زیر تغییر دهیم:
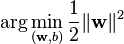
و البته با وجود شرط گفته شده .
این مسئله یک مسئله بهینه سازی برنامه ریزی غیر خطی (QP)محسوب میشود .
می توان عبارت قبل را با استفاده از ضرایب نا منفی لاگرانژ به صورت زیر نوشت که در آن آلفا ها ضرایب لاگرانژ هستند .

اما فرمول فوق اشتباه است . فرض کنید ما بتوانیم خانواده ای از ابرصفحات که نقاط را تقسیم می کنند پیدا کنیم . پس همه yi ها در شرط صادقند بنابراین میتوان مینینمم را باسوق دادن تمام آلفا ها به سمت بینهایت پیدا کرد . این شرط را میتوان به فرم زیر نمایش داد :

حالا می توان این مسئله را به کمک برنامه ریزی غیرخطی استاندارد حل کرد. جواب می تواند به صورت ترکیب خطی از بردارهای آموزشی بیان شود :

تنها چندآلفا بزرگتر از صفر خواهد بود.xi متناظر، دقیقاً همان بردار پشتیبان خواهد بود و شرط را ارضا خواهد کرد. از این می توان نتیجه گرفت که بردارهای پشتیبان شرط زیر را نیز ارضا میکنند که از آن مقدار b قابل محاسبه است :

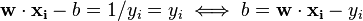
و در نهایت اگر از تمام بردار های پشتیبان میانگین گرفته شود الگوریتم مقاوم تر خواهد بود .

فرم دوگان:
حال با استفاده از این تعریف و جانشینی زیر:


می توان نشان داد که دوگان SVM به مسئله بهینه سازی زیر ساده می شود:
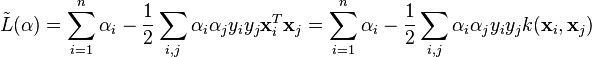
که در آن مقدار آلفا به ازای تمام i ها مثبت بوده و برای مینیمم بودن b خواهیم داشت :

در اینجا هسته به صورت زیر تعریف خواهد شد :

و w نیز با کمک ترم های آلفا به صورت زیر محاسبه خواهد شد:

برای تشخیص حالت نیز از آنجایی که چندین حالت چهره وجود دارد یعنی بیش از دو کلاس جهت دسته بندی داده ها موجود است بنابراین میبایست از ماشین بردار پشتیبان چند کلاسی استفاده نمود .
ماشین بردار پشتیبان چند کلاسی:
SVM اساساً یک جداکننده دودویی است. در بخش قبلی پایه های تئوری ماشین های بردار پشتیبان برای دسته بندی دو کلاس تشریح شد. یک تشخیص الگوی چند کلاسی می تواند به وسیله ی ترکیب ماشین های بردار پشیبان دو کلاسی حاصل شود. به طور معمول دو دید برای این هدف وجود دارد. یکی از آنها استراتژی "یک در مقابل همه " برای دسته بندی هر جفت کلاس و کلاس های باقیمانده است. دیگر استراتژی "یک در مقابل یک" برای دسته بندی هر جفت است. در شرایطی که دسته بندی اول به دسته بندی مبهم منجر می شود.برای مسائل چند کلاسی٬رهیافت کلی کاهش مسئله ی چند کلاسی به چندین مسئله دودویی است. هریک از مسائل با یک جداکننده دودویی حل می شود. سپس خروجی جداکننده های دودویی SVM با هم ترکیب شده و به این ترتیب مسئله چند کلاس حل می شود.
در نهایت در مرحله ی یادگیری از طریق الگوریتم svm راه تشخیص حالت از روی ویژگی های تصاویری که حالت آنها نیز معین است یادگرفته میشود و سپس در مرحله آزمایش برای هر داده ورودی از طریق روش یاد گرفته شده حالت چهره تشخیص داده میشود .
۳. مراجع
خانمحمدی، سهراب، علی آقاگلزاده، و میرهادی سیدعربی، 1381، تشخیص حالتهای چهره براساس نقاط مشخصه صورت با استفاده از شبکه عصبی RBF و منطق فازی، دومین کنفرانس ماشین بینایی و پردازش تصویر، تهران، دانشگاه خواجه نصیرالدین طوسی
M. Rosenblum , Y. Yacoob and L. Davis ,"Human Expression Recognition from Motion using a Radial Basis Function Network Architecture," IEEE Trans. on Neural Networks ,vol.7,No.5,september 1996.
Claude C. Chibelushi, Fabrice Bourel Facial Expression Recognition :A Brief Tutorial Overview
Facial Expression Recognition : Neeta Sarode et. al. / (IJCSE) International Journal on Computer Science and Engineering Vol. 02, No. 05, 2010, 1552-1557
A Frontal Face Detection Algorithm Using Fuzzy Classifier Ramazan Tasaltin and Osman Taylan
Kernel projection algorithm for large-scale SVM problems Jiaqi Wang, Qing Tao, Jue Wang
Face recognition by support vector machines Published in:Automatic Face and Gesture Recognition, 2000. Proceedings. Fourth IEEE International Conference on
3D facial expression recognition using SIFT descriptors of automatically detected keypoints
Facial expression recognition based on discriminative scale invariant feature transform H Soyel, H Demirel - Electronics letters, 2010 - IET