۱. مقدمه
بسم الله الرحمن الرحیم
با توجه به گسترش متون و مستندات الکترونیکی فارسی ، استفاده از روشی کارآمد جهت بازیابی اطلاعات ضروریست.
برای بازیابی اطلاعات ، پی بردن به مفهوم اصلی متن ،رده بندی متون و یافتن کلمات مناسب برای جست و جو و مقالات ؛ استخراج کلمات کلیدی بهترین روش است.
کلمات کلیدی مجموعه ای از لغات مهم در یک مستند هستند که توصیفی از محتوای مستند را فراهم می آورند و برای اهداف مختلفی قابل استفاده هستند.
*یکی از عملیات های مهم در فرآیند های
خوشه بندی ، طبقه بندی و استخراج اطلاعات ، استخراج کلمات کلیدی از متن است.
*با یافتن کلمات کلیدی می توان راحت تر و در زمانی کوتاه تر به مفهوم یک متن یا مقاله پی برد
*همچنین برای بازگرداندن مستندات بهتر و نتایج دقیق تر از موتورهای جست و جو از کلمات کلیدی استفاده می شود.
در مجموع کلمات کلیدی ابزار مفیدی برای جست و جوی حجم زیادی از مستندات در زمان کوتاه هستند.
لازمه استخراج کلمات کلیدی از متن دقت زیاد است ؛ با عنایت به این مطلب و با توجه به اینکه این فرآیند بسیار دشوار و زمان بر است ، نیاز به یک فرآیند خودکار برای استخراج کلمات کلیدی احساس می شود.
لذا در این پروژه تصمیم برآن است که روشی برای استخراج خودکار کلمات کلیدی از متن بیان و پیاده سازی شود.
۲. کارهای مرتبط
فرآیند کلی استخراج کلمات کلیدی به شرح زیر است:
ابتدا کلمات اضافی حذف شده و سایر کلمات ریشه یابی و برچسب گذاری میشوند.
سپس تعدادی ازکلمات به عنوان کاندید مشخص می شوند که به هر کلمه کاندید وزنی اختصاص داده میشود.
در مرحله آخر کلمات کلیدی دارای بیشترین وزن انتخاب می شوند.
متداول ترین روش برای انتخاب کلمات کلیدی n-grams است.
به طور کلی 3 روش متداول برای استخراج کلمات کلیدی وجود دارد :
روش TF-IDF : در این روش میزان تکرار یک کلمه در یک مستند را در مقابل تعداد تکرا آن در مجموعه کلیه مستندات در نظر می گیریم.
روش یادگیری ماشینی: در این روش با مجموعه ای از اسناد آموزشی و کلمات کلیدی مشخص برای آنها ، فرآیند استخراج کلمات کلیدی به عنوان یک مساله طبقه بندی مدل سازی می شود. کلمات بر اساس مشخصه هایشان ، به "کلمات کلیدی" و "کلمات غیرکلیدی" طبقه بندی می شوند. احتمالات طبقه بندی به صورت آماری از مجوعه آموزشی یادگرفته می شوند. این روش ها دارای انعطاف پذیری زیادی هستند. به عنوان نمونه یکی از این روش ها روش به کار رفته در [6] است که یک مدل یادگیری Naive Bayes را می سازد ؛ یا روش به کار رفته در [7] که از الگوریتم طبقه بندی C 5.0 استفاده می کند.
ترکیب روش های تحلیل آماری و زبان شناختی: علت ترکیب این دو روش این است که اطلاعات آماری بدون پالایش زبان شناختی نتایج مفیدی را در اختیار قرار نمی دهند. بدون اطلاعات زبان شناختی ، کلمات نامطلوبی مانند "از" ، "او" و غیره نیز به علت تکرار زیاد استخراج خواهند شد.از جلمه روش های به کار رفته در این دسته ، روش [5] است.
روش پیشنهادی این پروژه روش TF-IDF است که با الگوگیری نسبی از روش آخر ابتدا به حذف کلمات نامطلوبی از قبیل ضمایر ، حروف ربط و غیره می پردازد سپس با استفاده از یک روش آماری و بر مبنای تعدد تکرار کلمات به رده بندی آنها پرداخته و در نهایت کلمات کلیدی متن را استخراج می نماید.
۳. شرح روش پیشنهادی
در روش TF-IDF وزن دهی کلمات تابعی از توزیع کلمات مختلف در مستندات است.
برای پیاده سازی این روش ابتدا یک مجموعه اسناد (برای مثال مجموعه اسناد همشهری) را در نظر می گیریم. به ازای تمام کلماتی که در پیکره وجود دارد ، بررسی می کنیم که هر کلمه در چه تعداد از سندها تکرار شده است و آن را ذخیره می کنیم .
سپس یک سند به عنوان ورودی دریافت می شود. هدف یافتن کلمات کلیدیِ سند دریافت شده است.
برای این منظور ابتدا بررسی می کنیم که هر یک از کلمات سند ورودی ، چند بار در همان سند استفاده شده است.
سپس به ازای تمام کلمات سند ورودی بررسی می کنیم که هر کلمه در چه تعداد از اسناد پیکره اصلی (برای مثال همشهری) وجود دارد.
بعد از طی کردن این مراحل به حساب کردن وزن کلمات می پردازیم :
تعیین وزن کلمات با استفاده از دو معیار term frequency و inverse document frequency انجام می شود که به شرح زیر محاسبه خواهند شد :
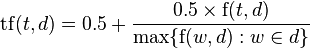
که در آن :
و
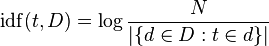
که در آن N تعداد کل اسناد موجود در پیکره است و

بیانگر تعداد اسنادی است که کلمه t در آنها وجود دارد.
در نهایت وزن هر کلمه به صورت زیر محاسبه خواهد می شود :

تنها نکته ای که باقی می ماند مواجه شدن با کلمه ایست که در مجموعه اسناد وجود نداشته باشد. در این صورت مخرج idf صفر شده و با مشکل مواجه خواهیم شد.
در چنین حالتی به صورت قراردادی مخرج idf را یک در نظر می گیریم.
پس از آنکه وزن تمامی کلمات سند ورودی محاسبه شد ، کلماتی که دارای بیشترین وزن هستند ، به عنوان کلمات کلیدی معرفی می شوند.
۴. ارزیابی سیستم
با توجه به اینکه زبان فارسی منبعی شامل متون و کلمات کلیدی آنها ندارد ، برای ارزیابی این سیستم باید تعدادی متن را در نظر گرفت ، کلمات کلیدی آنها را یک بار به صورت دستی و با استفاده از عقل و هوش انسان و یک بار با استفاده از سیستم مزبور استخراج نمود . سپس با مقایسه نتیجه دو روش سیستم ارزیابی شده و کارایی آن محاسبه می شود.
۵. آزمایشها
حال به مرحله ای رسیده ایم که پیاده سازی اولیه روش انجام شده است.
کد و نمونه ای از فایل های مربوطه را می توانید در لینک مقابل ببینید: استخراج کلمات کلیدی
در پیاده سازی جهت بهبود نتایج و نزدیک شدن به جواب صحیح مسئله می توان پس از حذف استاپ ورود ها و علائم از هضم جهت ریشه یابی کلمات استفاده کرد.
با استفاده از هضم می توان به ریشه کلمات فارسی دسترسی داشت و از مصادر افعال استفاده کرد .همچنین برای tokenize کردن نیز می توان از آن استفاده نمود. هضم کمک می کند تا به یک متن تمیز و مرتب دسترسی داشته باشیم و کار با کلمات را برای ما آسان می کند.
اما بنده پس از آزمایش متوجه شدم که در این روش نتایج بدون استفاده از هضم مطلوب تر هستند چرا که برای مثال در استفاده از هضم "قربان" به "قرب" تبدیل شده و به طور کلی مفهومش عوض می شود.
در این مرحله تمام آنچه در شرح روش پیشنهادی بیان شده بود ، با زبان برنامه نویسی پایتون پیاده سازی شده است.
مسلما مهم ترین قدم پس از پیاده سازی اولیه ، آزمودن راه حل ارائه شده می باشد.
برای ارزیابی "استخراج کلمات کلیدی" از متن دو روش پیشنهاد می شود :
ارزیابی مبتنی بر کارشناس انسانی(ارزیابی کیفی) :
در اﯾﻦ روش، ﮐﻠﻤـﺎت ﮐﻠﯿـﺪی اﺳـﺘﺨﺮاج ﺷـﺪه ﺗﻮﺳـﻂ ﺳﯿﺴـﺘﻢ، ﺑـﻪ ﯾـﮏ ﮐﺎرﺷـﻨﺎس ﻣﻮﺿـﻮع ﺳـﻨﺪ، داده ﻣــﯽﺷــﻮد و ﮐﺎرﺷــﻨﺎس ﺑــﺎ ﺗﻮﺟــﻪ ﺑــﻪ ﻣﺤﺘﻮای ﺳــﻨﺪ، ﺧــﻮب ﯾــﺎ ﺑــﺪ ﺑــﻮدن ﻧﺘﺎﯾﺞ را ﻣﺸــﺨﺺ ﻣﯽﮐﻨﺪ. در اﮐﺜﺮ ﻣﻮاﻗﻊ اﯾﻦ ﮐﺎرﺷﻨﺎس، ﻫﻤﺎن ﻧﻮﯾﺴﻨﺪه ﻣﺘﻦ ﻣﯽﺑﺎﺷﺪ.
برای این نوع ارزیابی تعدادی سند در نظر گرفته شد و کلمات کلیدی استخراج شده(مجموعه ای شامل 5 کلمه) به کارشناس ارائه شد و از کارشناس خواسته شد تا یکی از گزینه های "سطح پایین" ، "قابل قبول" و یا "سطح بالا" را انتخاب نماید!
برای نمونه دو سندِ کوتاه که به این روش ارزیابی شده اند ، نشان داده می شود :
توجه شود سند هایی که به عنوان نمونه به نمایش گذاشته می شوند ، صرفا جهت روشن شدن ماجرا و ارائه نتایج می باشند ؛ به همین دلیل بسیار کوتاه انتخاب شده اند تا مطالعه گزارش از حوصله خواننده خارج نشود.
سند اول قسمت هایی از سخنرانی "سید حسن نصر الله " است :
لبیک یا حسین
لبیک یا حسین
لبیک یا حسین
این سخنان زیبا را می توان این طور ترجمه کرد که :
ما این جا ایستاده ایم و ندای خود را به گوش آمریکایی ها می رسانیم.
هر چند که آمریکایی ها نمی فهمند که معنی لبیک یا حسین چیست ، لبیک یا حسین را بسیار از ما شنیده اند.
لبیک یا حسین یعنی تو در معرکه جنگ هستی، هر چند که تنهایی و مردم تو را رها کرده باشند و تو را متهم و خوار شمرند.
لبیک یا حسین یعنی تو و اموالت و زن و فرزندانت در این معرکه باشند.
لبیک یا حسین یعنی مادری فرزندش را به میدان دفاع می فرستد و آن گاه که فرزندش شهید شد و سر بریده اش به مادر داده شد، مادر سر را به خانه برده و خاک و خون آن را پاک کرده و به سر بگوید: «از تو راضی هستم. پروردگار، چهرهات را روشن بدارد، همان طور که نزد فاطمهی زهرا (سلام الله علیها) مرا روز قیامت رو سپید
کردی.»
لبیک یا حسین یعنی مادری، همسری یا خواهری می آید تا پسر، همسر یا برادر خود را لباس رزم بپوشاند و به میدان رزم روانه کند.
لبیک یا حسین یعنی زینب ( علیها سلام ) به برادرش حسین ( علیه السلام ) جواز آرزو و شهادت را ببخشد.
لبیک یا حسین یعنی این.
و به این کلام خاتمه می دهیم تا همه بشنوند:
هر کجای دنیا که به ما نیاز باشد، ما حاضریم.
و ما تنها کفن پوش نخواهیم بود. بلکه ما همراه کفن، اسلحه حمل خواهیم کرد.
و در نهایت می گوییم: لبیک یا حسین
و این است معنای هر یا حسین ما
کلمات کلیدی بازگردانده شده توسط سیستم : {حسین ، لبیک ، تو ، یعنی ، آمریکا }
به نظر کارشناس نتایج "قابل قبول" بوده است .
سند دیگری که به عنوان نمونه نشان داده میشود :
قلم های سرخ ، دفاتر سپید
به مناسب 20 فروردین ، سالروز شهادت سید مرتضی آوینی
به چشمانش که نگاه کردم،
تبلور ایمان را یافتم
سر بر خاک که مینهاد،
هقهق اشک بود و نالههای بیقرار
درست از همانجا حضور خدا را حس میکردی
لحظه لحظه رسیدن به قرب الهی را
خاکی و متواضع با لباس ساده بسیج
دست در دست دلاوران از حماسه سازان گفت،
زمان گذشت و زمانه عوض شد. اما سید هنوز با دهان روزه و دعای زیر لب از سفرهای سبز آسمانی شاهدان جان بر کف، بر دفاتر سپید با قلمهای سرخ مینوشت... 1
رضا برجی ( از دوستان شهید آوینی )نقل می کند که یکی از رفقای سید به ایشان گفت : «حاج مرتضی! دیگر باب شهادت هم بسته شد. ». آوینی در جواب گفت: « نه برادر، شهادت لباس تکسایزی است که باید تن آدم به اندازه آن در آید، هر وقت به سایز این لباس تک سایز درآمدی، پرواز میکنی، مطمئن باش! »
و آوینی آن قدر با قلم سرخش بر دفاتر سپید نقشِ عشق زد که لباس تک سایزِ شهادت به تنش شد و در میان رمل های فکه پر کشید و آسمانی شد.
سالروز جاودانگیش مبارک باد!
1: کتاب همسفر خورشید
راوی: دالایی
کلمات کلیدی بازگرداند شده توسط سیستم :{سپید ، دفاتر ، شهادت ، آوینی ، سید }
به نظر کارشناس نتایج "سطح بالا" می باشد.
برای ارزیابی در این قسمت حدود ده سند به روش بیان شده ، مورد آزمایش قرار گرفتند . میانگین نتایج ارزیابی "قابل قبول" بوده است.
ارزیابی مبتنی بر برچسب های ارائه شده(ارزیابی کمی):
برای آزمودن این روش از سندهایی استفاده می شود که قبلا برچسب گذاری شده اند و به عبارتی قبلا یک کارشناس سند، کلمات کلیدی سند مذکور را استخراج نموده و در اختیار قرار داده است.
با توجه به اینکه همواره ارائه اعداد و ارقام کار را برای مقایسه راحت تر و البته دقیق تر می کند ، برای ارزیابی این روش نیز فرمولی ارائه می شود که به شرح زیر مورد استفاده قرار می گیرد :
فرض کنید سند "a" در اختیار است و کارشناس سند مجموعه کلمات "A" را به عنوان کلمات کلیدی مشخص نموده است.
در سیستم پیاده سازی شده سند "a" به عنوان ورودی گرفته شده و مجموعه "B" بازگردانده می شود که شامل n کلمه برتر به عنوان کلمات کلیدی است. (مقدار n توسط برنامه نویس قابل تغییر است)
یک معیار سنجش برای میزان دقیق بودن سیستم به صورت زیر ارائه می شود:
روشن است که هرچه R بزرگ تر باشد ، نشان دهنده دقتِ بیشتر و نتیجه مناسب تر است.
برای روشن شدن نحوه استفاده از این روش نیز دو مثال بیان میشود :
متن زیر قبلا با کلمات {عید ، قربان ، ابراهیم ، کربلا ، حسین} برچسب گذاری شده بوده است.
بسم رب الحسین
عید قربان
واژه ایست که از کودکی آن را بسیار شنیده ایم ، سال هاست که آن را جشن می گیریم و آن را عید می نامیم.
اما می خواهم تفسیر تازه ای از قربان بگویم :
می خواهم بگویم که قربان آغاز نمایشی طولانی است ، نمایشی که نمی توان در آن جز زیبایی دید ...!
آغازی است برای به نمایش گذاشتن عبودیت واقعی ، برای به تصویر کشیدن بندگی مخلصانه و شاید برای اینکه به همه بفهماند که هیچ کس را جز حسین سعادت ثار الله شدن نیست ... !
ابراهیم سرفراز و اسماعیل سیاوشانه از این آزمایش سخت بیرون آمدند وحاصلش شد :
« وَ إِذِ ابْتَلىَ إِبْرَاهِیمَ رَبُّهُ بِکلَمَاتٍ فَأَتَمَّهُنَّ قَالَ إِنىّ جَاعِلُکَ لِلنَّاسِ إِمَامًا قَالَ وَ مِن ذُرِّیَّتىِ قَالَ لَا یَنَالُ عَهْدِى الظَّالِمِینَ . بقره/124. »
و از این روست که خداوند او را امامت داد و در میان فرزندان ابراهیم ، اسماعیل را که از همه رو سپید تر بود برگزید تا نبوت آخرالزمان ، یگانه ثار الله جهان و امام آخرین قیام ( که رقم زننده عهد خداست ) را از ذریه او قرار دهد.
این تازه شروع نمایش بود و پرده اول ...
و تو خوب می دانی که فدای خدا شدن عهد خدا بود با ذریه ابراهیم که باید می رسید به ذبیح الله الاعظم... به حسین.
و زیبا ترین صحنه نمایش زمانی شکل گرفت که خانمی با قد خمیده و مو های سپید در کنار جسم بی سر برادر زمزمه می کرد "رب تقبل منا لک هذا القربان"
آری ! قربان عید انتظار حسین است و می رود تا غدیر که هدیه خدا به آل ابراهیم برسد و امامت از نسل اسماعیل برسد به علی .
و خدا یگانه کوثر پیامبرش را مهد امامت قرار دهد و فرزند علی و زهرا (سلام الله علیها) بی آنکه از خدا وحی ای برسد ، خود و تمام هستی اش را به قربانگاه ببرد...
و غدیر می رود و می رود تا برسد به عاشورا... می رود تا آن ذبحی که ابراهیم و مکه تاب دادنش را نداشتند به حسین و کربلا بسپارد...
و چه صحنه ای با شکوه تر از کربلا؟
و حسین در قربان غسل شهادت می کند و می رود تا به جهانیان نشان دهد که بگذارید حاجی ها با پول خود قربانی دهند و من می روم تا از تمام جان و پاره های دلم قربانی دهم...
و حسین در کربلا تمام هستی اش را قربانی کرد، به خدا پیوست و ثار الله شد تا دیگر شکی نماند که "انّ الحسین مصباح الهدی و سفینة النجاة"
اما این قربان کجا و آن قربان کجا؟!
ابراهیم از خدا خواست فرزندی به او عطا کند
حسین از خدا خواست قربانی او را قبول کند
مکه هاجر به دنبال جرعه ای آب می گشت
و کربلا رباب پی آب بی تاب بود
مکه زیر پای اسماعیل آب جاری شد
و در کربلا از گلوی علی اصغر خون...
مکه ابراهیم خواست اسماعیلش را قربانی کند اما نشد!
کربلا حسین علی اکبرش ، اصغرش ، عباسش را ، قاسمش را ، همه و همه را قربانی کرد
مکه ابراهیم به شیطان سنگ زد تا او را فریب ندهد
کربلا شیطان جرئت مقابله با حسین را نداشت!
مکه ابراهیم و اسماعیل کعبه را بازسازی کردند
کربلا حسین و آلش تمامی قلب ها را بازسازی کردند ...
و بازسازی قلب ها به عاشورا و کربلا ختم نشد مگر نه اینکه "کل ارض کربلا و کل یوم عاشورا"؟
هر روز و هر روز می شود به یاد حسین سدی از اشک ساخت در مقابل شیطان ...
به خصوص این روز ها که از عرفه می شود عطر نسیم محرم را حس کرد ...
پس بنشینیم به انتظار
از قربان تا قربان
بنشینیم به نظاره
از مکه تا کربلا
از اسماعیل تا حسین
و کاش به زودی بنشینیم به نظاره
از حسین تا مهدی
از قیام تا قیام
کلمات کلیدی به دست آمده از سیستم ، مجوعه مقابل می باشد : {قربان ، ابراهیم ، خدا ، حسین ، الله ، رود ، اسماعیل ، عید ، کربلا}
اشتراک دو مجموعه : {عید ، قربان ، ابراهیم ، کربلا ، حسین}
با توجه به فرمول ارائه شده ، دقت سیستم در مورد این سند 100 % است.
مثال دیگر :
متن زیر قبلا با کلمات {فیزیک ، بور ، ارتفاع ، آسمانخراش ، فشارسنج} برچسب گذاری شده است.
سؤال امتحان نهایی فیزیک دانشگاه کپنهاگ
چگونه می توان با یک فشارسنج ارتفاع یک آسمانخراش را محاسبه کرد ؟
پاسخ یک دانشجو:
" یک نخ بلند به گردن فشارسنج می بندیم و آن را از سقف ساختمان به سمت زمین می فرستیم.
طول نخ به اضافه طول فشارسنج برابر ارتفاع آسمانخراش خواهد بود.
این پاسخ ابتکاری چنان استاد را خشمگین کرد که دانشجو را رد کرد.
دانشجو با پافشاری بر اینکه پاسخش درست است ؛ به نتیجه امتحان اعتراض کرد.
دانشگاه یک داور مستقل را برای تصمیم درباره این موضوع تعیین کرد . داور دانشجو را خواست و به او شش دقیقه وقت داد تا راه حل مسئله را به طور شفاهی بیان کند تا معلوم شود که با اصول اولیه فیزیک آشنایی دارد.
دانشجو پنج دقیقه غرق تفکر ساکت نشست . داور به او یادآوری کرد که وقتش درحال اتمام است . دانشجو پاسخ داد که چندین پاسخ مناسب دارد اما تردیددارد کدام را بگوید.
وقتی به او اخطار کردند عجله کند چنین پاسخ داد:
اول اینکه می توان فشارسنج را برد روی سقف آسمانخراش ، آن را از لبه ساختمان پایین انداخت و مدت زمان رسیدن آن به زمین را اندازه گرفت.ارتفاع ساختمان
مساوی
یا اگر هوا آفتابی باشد می توان فشارسنج را عمودی بر زمین گذاشت و طول سایهاش را اندازه گرفت. بعد طول سایه آسمانخراش را اندازه گرفت و سپس
با یک تناسب ساده ارتفاع آسمانخراش را به دست آورد .
اما اگر بخواهیم خیلی علمی باشیم ، می توان یک تکه نخ کوتاه به فشارسنج بست و آن را مثل یک پاندول به نوسان درآورد ، نخست در سطح زمین وسپس روی
سقف آسمانخراش . ارتفاع را از اختلاف نیروی جاذبه می توان محاسبه کرد :
یا اگر آسمانخراش پله اضطراری داشته باشد، میتوان ارتفاع ساختمان را با بارومتر اندازه زد و بعد آنها را با هم جمع کرد.
البته اگر خیلی گیر و اصولگرا باشید می توان از فشارسنج برای اندازهگیریی فشار هوا در سقف و روی زمین استفاده کرد و اختلاف آن برحسب
میلیبار را به فوت تبدیل کرد تا ارتفاع ساختمان بدست آید.
ولی چون همیشه ما را تشویق میکنند که استقلال ذهنی را تمرین کنیم و از روشهای علمی استفاده کنیم، بدون شک بهترین روش آنست که در اتاق سرایدار
را بزنیم و به او بگوییم: اگر ارتفاع این ساختمان را به من بگویی یک فشارسنج نو و زیبا به تو می دهم...!!
این دانشجو کسی نبود جز نیلز بور، تنها دانمارکی که موفق شد جایزه نوبل در رشته فیزیک را دریافت کند ...
کلمات کلیدی به دست آمده از سیستم مجموعه زیر می باشد :
{کرد ، فشارسنج ، پاسخ ، دانشجو ، ارتفاع ، آسمانخراش ، توان ، طول ، نخ ، داور}
اشتراک دو مجموعه : {ارتفاع ، آسمانخراش ، فشارسنج} می باشد
با توجه به فرمول ارائه شده ، دقت سیستم در مورد این سند 60% است.
برای ارزیابی در این قسمت حدود ده سند به روش بیان شده ، مورد آزمایش قرار گرفتند . میانگین نتایج ارزیابی حدود " R = 67% " بوده است.
در مجموع به نظر می رسد برای اسنادی که حالت تحلیلی ، خبری و غیر کنایی دارند ، این روش با دقت بسیار بالایی ، کلمات کلیدی را استخراج می نماید.
۶. بهبود نتایج
در قسمت های قبلی نحوه کار روش tf_idf برای استخراج کلمات کلیدی از متن بیان شد. پس از پیاده سازی و ارزیابی این روش ، نوبت به ارتقای نتایج می رسد.
برای بهبود نتایج چند راهکار وجود دارد:
مثلا می توان مراحل پیش پردازشی را به آن افزود تا سطح نتایج بالاتر رود.
یا می توان با اهمیت دادن بیشتر به کلماتی که در عنوان یک مطلب ذکر می شوند ، کلمات کلیدی بازگردانده شده را به آنچه که واقعا نمایانگر موضوع سند است ، نزدیک تر کرد.
راهکار دیگری که می تواند به بهبود نتایج کمک کند اهمیت دادن به نحوه توزیع کلمات است . برای مثال اینکه یک کلمه فقط در ابتدای سند به تعداد دفعات زیاد تکرار شده باشد ، نشان دهنده اهمیت آن نخواهد بود و طبیعتا کلمه ای مطلوب تر است که علاوه بر تکرار زیاد ، توزیع متناسب و متوازن تری در متن داشته باشد.
راهکار دیگر پردازش معنایی کلمات است که البته به نسبت روش موجود حافظه بیشتری اشغال کرده و زمان بر است . منظور از پردازش معنایی این است که در ذخیره نمودن کلمات و سپس امتیازدهی به آنها کلمات هم معنی را یک مفهوم در نظر گرفت و به کل آن مفهوم نمره داد . برای مثال می توان کلمات "بخش" و "قسمت" را ذکر کرد که هر دو در زبان فارسی رایج هستند . در این روش هر دو کلمه با یک مفهوم (مثلا بخش) در نظر گرفته میشوند.
برای پیاده سازی این روش لازم است تمام کلمات هم معنی و مصطلح را به صورت جداگانه ذخیره نمود و سپس از آن استفاده کرد.
پیاده سازی این روش زمان بر است و حافظه زیادی مصرف می کند و از آن مهم تر نیاز به اطلاعات گسترده و به روز در مورد زبان فارسی دارد اما برای بهبود نتایج راهکار مناسبی است.
راهکار دیگری که پیشنهاد می شود بررسی و رفع مشکلیست که به دلیل خطاهای محتمل نگارشی و املایی ممکن است رخ دهد و البته رایج هستند . مثلا تهران و طهران ؛ هم چنین قضاییه و قضائیه
از دیگر راهکارهایی که مناسب به نظر می رسد ، می توان به افزودن عبارات کلیدی به روش tf_idf و در نظر گرفتن key phrase اشاره کرد.
و یکی دیگر از راهکارها پیاده سازی کامل روشی دیگر است که در مقالات نتیجه بهتری گرفته باشد . برای مثال روش یادگیری ماشینی و ...
روشی که برای پیاده سازی در این قسمت انتخاب شده است ، افزودن عبارات به روش tf_idf و کار با key phrase می باشد.
همان طور که در مباحث درس"ذخیره و بازیابی اطلاعات" نیز بیان شده است ، برای دستیابی به عبارات کلیدی می توانیم تمام ngram ها را نیز ذخیره کرده و برای دستیابی به نتایج از آنها استفاده کنیم .
عبارات می تواند شامل هر تعدا کلمه ای که مورد نظر برنامه نویس است باشد برای مثال 2gram ، 3gram و ...
آنچه در این فاز از پروژه پیاده سازی شده است ، افزودن bigram (یا همان 2gram) ها به روش tf_idf می باشد. که البته با توجه به الگوریتم و روش پیاده سازی ، افزودن سایر ngram ها به برنامه کار بسیار ساده ای می باشد .
برای استخراج key phrase ها به همان صورت که در توضیح روش tf_idf گفته شده است ، عمل خواهد شد با این تفاوت که این بار به جای ذخیره و استفاده از کلمات ، تمام جفت کلماتی که کنار هم قرار دارند نیز ذخیره و استفاده می شوند.
برای مثال از عبارت "درس سه واحدی هوش مصنوعی" علاوه بر کلمات "درس" ، "سه" ، "واحدی" ، "هوش " و "مصنوعی " چهار عبارت "درس سه" ، "سه واحدی" و "واحدی هوش " و "هوش مصنوعی " نیز در نظر گرفته می شوند.
و طبق همان روش توضیح داده شده در "شرح روش پیشنهادی" برای bigram ها عمل خواهیم نمود .
کد مورد نظر را می توانید در لینک زیر ببینید :
پس از پیاده سازی این روش به ارزیابی آن می پردازیم.
مجددا برای ارزیابی از دو روش کیفی و کمی (که قبلا توضیح داده ایم) استفاده می شود.
همان اسنادی که در قسمت آزمایش ها مورد بررسی قرار گرفته بودند ، این بار نیز به عنوان ورودی استفاده شده اند و مضاف بر آنها ده سند دیگر نیز به منظور بالا بردن دقت کار برای ارزیابی مورد استفاده قرار گرفتند.
نتایج حاصل از این پیاده سازی را ارزیابی نمودیم.
نتیجه ارزیابی کیفی : " قابل قبول نزدیک به سطح بالا "
و نتیجه ارزیابی کمی : تقریبا " 75.55 % = R " می باشد ؛ نسبت به فاز قبل ( که R= 67% بود ) بهبود یافته و " 8.55% " ارتقا یافته است.
برای روشن شدن موضوع، نتیجه دو روش کلمه کلیدی و عبارت کلیدی را برای یک سند به نمایش می گذاریم .
یکی از اسنادی که در فاز قبل برای ارزیابی مورد استفاده قرار گرفت ، اندازه گیری ارتفاع آسمانخراش با فشارسنج توسط بور بود.
سندی که انتخاب شده بود برای نوشتن آسمان خراش از درج نیم فاصله بین آسمان و خراش استفاده کرده بود :( آسمانخراش به جای آسمان خراش)
در نظر بگیرید اگر نویسنده متن به این موضوع دقت نکرده باشد در این صورت هر یک از کلمات آسمان و خراش به طور جداگانه امتیازدهی خواهند شد و نتیجه به شرح زیر خواهد بود :
کلمات کلیدی تعیین شده توسط کارشناس :
{فیزیک ، بور ، ارتفاع ، آسمانخراش ، فشارسنج}
نتیجه روش پیاده سازی شده در فاز قبل : {کرد ، یک ،خراش ،فشارسنج ، پاسخ ، دانشجو ، آسمان }
---> R = 20%
نتیجه روش پیاده سازی شده در این فاز : {خراش ، فشارسنج ، پاسخ ، دانشجو ، آسمان ، ارتفاع ، آسمان خراش }
---> R= 60%
همان طور که مشاهده میشود ، نتیجه روش دوم به طور چشم گیری بهتر است .
۷. نقطه ضعف سامانه:
برای نمونه نگاهی به نتایج بازگردانده شده توسط سامانه برای سند فوق بیندازیم :
لازم به ذکر است علی رغم اینکه کلمات کلیدی استخراج شده تقریبا بیان گر موضوع سند می باشند اما دقت محاسبه شده ، دقت بالایی محسوب نمی شود.
علت این موضوع قرار داشتن کلمات "فیزیک" و "بور" در برچسب های از پیش مشخص شده است .
فیزیک و بور برای این سند کلمات بسیار مهمی محسوب میشوند اما با توجه به اینکه روش tf_idf بر پایه تکرار کلمات کار می کند ، بازگردانده نشدن این کلمات توسط سامانه امری کاملا بدیهی است.
نکته جالب توجه این است که
اگر در تمام سند به جای کلمه دانشجو (که به بور اشاره دارد ) از خود کلمه "بور " استفاده می شد ، حتما "بور " در کلمات بازگردانده شده ، توسط سامانه قرار می گرفت و دقت بالاتر می رفت.
این موضوع نشان دهنده ضعف سامانه در مقابله با مفاهیم ، اشارات و کنایه هاست. همان طور که در فاز قبل نیز مطرح شد ، این روش برای اسنادی که حالت تحلیلی ، خبری و غیر کنایی دارند بسیار مناسب است .
۸. عملکرد نادرست و ضعیف
علی رغم اینکه در نظر گرفتن bigram ها برای بالا بردن دقت سامانه روش بسیار مناسبی محسوب می شود ، اما اگر به تنهایی مورد استفاده قرار بگیرند (از بررسی کلمات صرف نظر کرده و فقط جفت کلمات را بررسی کنیم ) نتایج به طور چشم گیری افت خواهد کرد چرا که تعداد اسنادی که کلمات کلیدی آنها فقط شامل عبارات دو کلمه ای باشد ، بسیار کم است .
به همین دلیل بهترین روش ترکیبی از term ها و bigram هاست که در این فاز پیاده شده است .
۹. کارهای آینده
تمام روش هایی که در قسمت بهبود نتایج بیان شد ، برای ارتقای پروژه روش های مناسبی هستند . اگر فرصتی برای بهبود بخشیدن نتایج وجود داشته باشد ، به نظر "پردازش معنایی " و "بررسی نحوه توزیع کلمات" راهکار های مناسبی می باشند و پیاده سازیشان می تواند به بالا بردن سطح نتایج و نزدیک شدنشان به آنچه واقعا مطلوب ماست ، کمک کند.
۱۰. مراجع
[1] بهروز مینایی بیدگلی ، مجتبی وحیدی اصل ، سمیه عربی نرئی ؛ "استخراج کلمات کلیدی جهت طبقه بندی متون فارسی"
[2] زهره کریمی ، مهرنوش شمس فرد ؛ "سیستم خلاصه سازی خودکار متون فارسی" ، دوازدهمین کنفرانس بین المللی انجمن کامپیوتر ایران ، 1385
[3] امیرشهاب شهابی ، محمدرضا کنگاوری ؛ "چکیده سازی چندنوشتاری زبان فارسی"
[4] Dalianis, H.; “SweSum–A text Summar izer f or Swedish, Technica l r eport” , TRITANA-P0015, IPLab-174, NADA,
KTH, 2000.
[5] Frantzi, K.; Ananiadou, S.; Mima, H.;”A utoma tic Recognition of Multi-wor d Ter ms: the C-va lue/NC-value Method ”, International Journal on Digital Libraries, 3(2):115-130, 2000
[6] Witten, I.; Paynter, G.; Frank, E.; Gutwin, C.; Nevill-Manning, C.; ” KEA : Practica l A utoma tic Key phra se
Extra ction” , In Proceedings of A CMDL' 99, pages254-255,1999
[7] Zhang, Y.; Zincir-Heywood, N. and Milios, E.; ” Wor ld Wide Web Site Summariza tion ”, Web Intelligence and Agent
Systems: An International Journal, 2(1):39-53, 2004.
۱۱. پیوندهای مفید
ﻣﻘﺪﻣﻪای ﺑﺮ ذﺧﯿﺮه و ﺑﺎزﯾﺎﺑﯽ اﻃﻼﻋﺎت ﻣﺘﻮن زﺑﺎن ﻓﺎرﺳﯽ
ﺗﺤﻠﯿﻞ ﺳﯿﺴﺘﻢ ﯾﺎﻓﺘﻦ ﺧﻮدﮐﺎر ﮐﻠﻤﺎت ﮐﻠﯿﺪی ﻣﺘﻮن زﺑﺎن ﻓﺎرﺳﯽ
Survey of Keyword Extraction Techniques
Exploration and Improvement in Keyword Extraction for News Based on TFIDF
Unsupervised Approaches for Automatic Keyword Extraction Using
Meeting Transcripts