در این پروژه باید سامانهای را توسعه دهید که با یادگیری ویژگیهای اسکن مغزی بیماران مبتلا به اسکیزوفرنی، قادر باشد تا این بیماری را از روی ویژگیهای استخراج شده از تصویر اسکن مغزی، تشخیص دهد.
مجموعه داده و نحوه ارزیابی پروژه خود را میتوانید از این مسابقه دریافت کنید.
۱. مقدمه
اسکیزوفرنی یک اختلال روحی است که در حدود یک نفر در هر صد نفر به آن مبتلا می شوند. این بیماری دربین مردها و زنان به یک اندازه شایع است و در جوامع شهری و بین گروه های اقلیت بیشتر مشاهده شده است. قبل از سن 15 سالگی بسیار نادر است اما در هر سنی پس از آن رخ می دهد و بیشتر در سنین 15 تا 35 سالگی مشاهده شده است.
ازجمله نشانه های این بیماری، افکار پریشان، اختلالات فکری، رفتارهای عجیب و غریب، پارانویا (هذیان گویی شدید)، توهم بزرگی و عظمت و توهم از نوع شنوایی می باشد [1] .
ازآنجا که در این بیماری، تشخیص به موقع، میزان بهبودی و زنده ماندن بیماران را بهبود می بخشد، بنابراین پردازش تصویر به عنوان یک ابزار تصمیم گیرنده می تواند پزشکان را در تشخیص اولیه کمک کند. تصاویر پزشکی وضعیت بدن را به صورت دو بعدی و حتی سه بعدی(به وسیله کامپیوتر) نشان می دهند، از این رو پردازش تصویر و کاربرد آن در تشخیص بیماری ها از جمله اسکیزوفرنی اهمیت فراوانی دارد.
پردازش تصویر روشی برای تبدیل یک تصویر به صورت دیجیتال و انجام برخی از عملیات ها بر روی آن، به منظور دریافت یک تصویر بهبود یافته و یا برای استخراج برخی از اطلاعات مفید از آن است. معنای دقیق تر آن عبارت است از هر نوع پردازش سیگنال که ورودی یک تصویر است و خروجی پردازشگر تصویر می تواند یک تصویر یا یک مجموعه از نشانهای ویژه یا متغیرهای مربوط به تصویر باشد. اغلب تکنیک های پردازش تصویر شامل برخورد با تصویر به عنوان یک سیگنال دو بعدی و به کار بستن تکنیک های استاندارد پردازش سیگنال روی آن ها می باشد [2] .
یکی از سیستم های تصویربرداری ام آر آی می باشد، اما تصاویر حاصل به صورت خام قابل استفاده نیستند، لذا پردازش های وسیع و گسترده ای روی آن ها صورت می گیرد که شامل پردازش تصاویر و استخراج اطلاعات موثر در تشخیص و یافتن مواضع مورد توجه، بازسازی تصاویر در کامپیوتر به صورت سه بعدی و درون یابی اطلاعات جهت تولید برش های لازم از ارگان تحت تصویربرداری، حذف نویز، اختصاص رنگ و ارتقاء کیفیت تصویر می باشد.
اهداف پردازش تصویر :
• بهبود اطلاعات تصویر برای استفاده انسان
• پردازش داده های تصویر برای ادراک ماشین

مرحله ی پیش پردازش : پس از تصویربرداری (به دست آوردن ماتریس تصویر) که توسط حسگر مناسب و مبدل آنالوگ به دیجیتال انجام می شود ، پیش پردازش انجام می شود. هدف اصلی بهبود تصویر است به عنوان مثال حذف نویز از داده های تصویری در این مرحله انجام می شود.
مرحله ی بخش بندی : خروجی مرحلة بخش بندی، مرز یک ناحیه و یا تمام نقاط درون یک ناحیه است.
• نمایش مرزی زمانی مفید است که مشخصات خارجی شکل (مانند گوشه ها یا خمیدگی ها ) مهم باشد.
• نمایش ناحیه ای وقتی مفید است که خواص درونی بخش های تصویر( مانند بافت شکل ) مورد توجه باشد.
مرحله ی توصیف : در این مرحله که انتخاب ویژگی هم نامیده می شود ، روشی برای برجسته کردن ویژگی های مورد نظر اجرا می شود. مثلا در تشخیص بیماری اسکیزو فرنی ویژگی هایی در تصویر MRI که باعث تمایز بیمار از شخص سالم می شود.
مرحله تشخیص و تفسیر : طی این مرحله با استفاده از اطلاعات توصیف گر ها ، یک برچسب به هر شی نسبت داده می شود.
مطالعات بر روی MRI : در مغز بیماران مبتلا به اسکیزوفرنی، تغییرات ساختمانی خاصی نظیر افزایش حجم مایع مغزی- نخاعی و بطن های جانبی و کاهش حجم لوبهای تمپورال، تالاموسها، هیپوکامپها و اونکوسها دیده میشود و MRI روش مناسبی برای نشان دادن این تغییرات میباشد. MRI همچنین نشان می دهد که حجم ماده خاکستری و سفید افراد مبتلا نسبت به گروه سالم کاهش یافتـه است. ما از این تفاوت هایی که در MRI افراد سالم و اسکیزوفرنی وجود دارد، برای تشخیص بیماری استفاده خواهیم کرد.

۲. کارهای مرتبط
مجموعه داده : داده ها از دو مجموعه اطلاعات جمع آوری شده توسط روش های مختلف تصویربرداری تشکیل شده است :
Functional Network Connectivity [4] و Source-Based Morphometry[5]
مجموعه FNC از اسکن FMRI(تصویرسازی تشدید مغناطیسی کارکردی) ، به دست آمده و هماهنگی بین مناطق مختلف مفز را توصیف می کند. SBM از اسکن MRI مشتق شده و غلظت ماده خاکستری را در مناطق مخنلف مغز نشان می دهد. می توانید مجموعه داده را از این آدرس دریافت کنید.
تشخیص الگو شاخهای از مبحث یادگیری ماشینی است. میتوان گفت تشخیص الگو، دریافت دادههای خام و تصمیم گیری بر اساس دستهبندی دادهها است. روشهای تشخیص الگو، الگوهای مورد نظر را از یک مجموعه دادهها با استفاده از دانش قبلی در مورد الگوها یا اطلاعات آماری دادهها، جداسازی میکند. الگوهایی که با این روش دستهبندی میشوند، گروههایی از اندازهگیریها یا مشاهدات هستند که نقاط معینی را در یک فضای چند بعدی تشکیل میدهند. این ویژگی اختلاف عمده تشخیص الگو با تطبیق الگو است، که در آنجا الگوها با استفاده از موارد کاملا دقیق و معین و بر اساس یک الگوی مشخص، تشخیص داده میشوند. مسئله دسته بندی 1یکی از مسائل اصلی مطرح شده در یادگیری ماشین است و بسیاری از مسائل را می توان به صورت یک مسئله دسته بندی مطرح کرده و حل کرد. از طرفی در یادگیری ماشین نیز روش های مختلفی برای حل مسئله دسته بندی صورت گرفته است. در ادامه نمونه هایی از الگوریتم هایی که برای دسته بندی جهت تشخیص بیماری اسکیزوفرنی استفاده شده اند، معرفی می شوند.
روش Gaussian Process
یک نمونه [6] از روش هایی که برای دسته بندی انجام شده ، بر مبنای الگوی یادگیری ماشین های بیزی به نام دسته بندی فرایند گوسی می باشد. یادگیری بیزوی این امکان را فراهم می آورد که اطلاعات اولیه طراح در مورد داده ها را مدل سازی کنیم و به صورت یکپارچه با اطلاعات حاصل از داده های نمونه گیری شده ، ادغام کنیم. همچنین این مدل سازی، یکی از اصلی ترین مشکلات در مدل سازی داده ها ، برای رگرسیون یا کلاس بندی، یعنی بیش برازش 2را تا حد زیادی حل می کند. ساختار استنتاجی که می توان به وسیله ی الگوریتم های بیزوی به وسیله ی ایده ی بیزی بودن به مسائل اضافه کرد، بسیار انعطاف پذیر و مشابه روند طبیعی استدلال در انسان هاست. در واقع داشتن پیش فرض هایی در رابطه با یک حقیقت (توزیع پیشین )3 و استنتاج به وسیله ی تابعی که امکان پذیربودن رخدادی را به شرط داشتن (رخداد) پارامترهای پیش فرض(تابع یا توزیع درست نمایی ) 4برای بدست آوردن امکان پذیر بودن رخداد مورد نظر (تابع) اساس کار استدلال و آموزش بیزوی بوده، که بسیار مشابه روند استدلالی در انسان است. مدل GP بر اساس فرض داشتن یک فرایند گوسی روی داده های ورودی است[7] .
داده های آموزشی : {( D = {(Xi , Yi داده های تست : {( D={(Xi , Yi
بر اساس عملیات ریاضی که در فرآیند گوسی انجام می دهد، به داده های خروجی برچسبی را نسبت می دهد ، در این نمونه مقاله به بیماران اسکیزوفرنی عدد -1 و به افراد سالم 1 نسبت می دهد.
روش Support Vector Machines
روش های طبقه بندی خطی، سعی دارند که با ساختن یک ابرسطح ( که عبارت است از یک معادله خطی )، دادهها را از هم تفکیک کنند. روش طبقه بندی ماشین بردار پشتیبان که یکی از روش های طبقه بندی خطی است، بهترین ابرسطحی را پیدا میکند که با حداکثر فاصله5، دادههای مربوط به دو طبقه را از هم تفکیک کند [8].
مجوعه داده های آزمایش D شامل n عضو(نقطه)را در اختیار داریم که به صورت زیر تعریف می شود:
جایی که مقدار Y برابر ۱ یا 1- و هر یک بردار حقیقی P – بعدی است. هدف پیدا کردن ابرصفحه جداکننده با بیشترین فاصله از نقاط حاشیه ای است که نقاط باYi = 1 را از نقاط با Yi = -1 جدا کند. هر ابر صفحه می تواند به صورت مجموعه ای از نقاط که شرط مقبل را ارضا می کند نوشت: 0 = w . x - b جایی که . علامت ضرب است، w بردار نرمال است، که به ابرصفحه عمود است. ما می خواهیم w و b را طوری انتخاب کنیم که بیشترین فاصله بین ابر صفحه های موازی که داده ها را از هم جدامی کنند، ایجاد شود. این ابرصفحه ها با استفاده از این رابطه توصیف می شوند. w . x – b = 1 و w . x – b = -1
اگر داده های آموزشی جدایی پذیر خطی باشند، ما می توانیم دو ابر صفحه در حاشیه نقاط به طوری که هیچ نقطه مشترکی نداشته باشند، در نظر بگیریم و سپس سعی کنیم، فاصله آنها را، ماکسیمم کنیم. با استفاده از هندسه، فاصله این دو صفحه ( 2 تقسیم بر ||W|| ) است. بنابر این ما باید ||W|| را مینیمم کنیم. برای اینکه از ورود نقاط به حاشیه جلو گیری کنیم، شرایط زیر را اضافه می کنیم: برای هر i
برای کلاس اول : 1 =< w . xi - b
برای کلاس دوم : w . xi - b => -1
روش Random Forest
[9] فرض می شود (X = (X1, X2, ... , Xp مجومعه ای است از P متغیر پیش بین بالقوه ، Xj= (X1 j ,X2 j ,...,Xnj ) T و همچنین فرض می شود Y صفت تحت بررسی است (در اینجا ابتلا یا عدم ابتلا به بیماری اسکیزوفرنی) و در آن n تعداد افراد در نمونه است. همچنین b شماره درخت و B تعداد کل درختان است. مقدار اولیه b را برابر یک قرار می دهیم. در گام k-ام ، \Theta k نمونه مستقل و با توزیع یکسان از مجموعه داده ها انتخاب می گردد، این مجموعه با نام مجموعه یادگیری یا آموزشی خوانده می شود. همچنین x نیز نمونه تصادفی از مجموعه متغیر های پیش بین مورد مطالعه انتخاب می گردد. تابع پیش بین h با استفاده از x و تتایk ساخته می شود. گام ها B مرتبه تکرار شده تا به تعداد B درخت برسیم. فرض می شود :
اگر P > Q باشد ، رندم فارست پیش بینی می نماید که x به به کلاس فرضا 1 (بیماران اسکیزوفرنی) تعلق دارد و برعکس، اگر P < Q باشد، پیش بینی می نماید که به کلاس فرضا 0 (افراد سالم) تعلق دارد.
روش درخت تصمیم
درخت تصمیم یکی از روش های ناپارامتری رده بندی کردن است که با توجه به نوع متغیر وابسته به دو دسته رده بندی درختی6 برای متغیر رسته ای و رگرسیون درختی 7برای متغیر پیوسته تقسیم می شود. در این روش مجموعه ای از شرط های منطقی 8به صورت یک الگوریتم با ساختار درختی برای رده بندی یا پیش بینی یک پیامد به کار می رود.
الگوریتم CART : Classification and Regression Tree
درخت کلاس بندی-رگرسیونی یکی از قدرتمند ترین و در غین حال ساده ترین روش های ناپارامتری آماری به منظور کلاس بندی متغیر پاسخ است.شمای این روش همانند نمودار گردشی است که در آن هر گره آزمونی برای متغیر پیش بین یا مشخصه فرد مورد مطالعه بوده و هر شاخه آن نتیجه آزمون و هر برگ یا گره انتهایی کلاس متغیر پاسخ را نشان خواهد داد. یک درخت ابتدا با تعیین متغیر Xj از میان تمام متغیر های بالقوه ساخته می شود، این متغیر "بهترین پیش بینی" را برای Y(متغیر پاسخ) خواهد داشت. بعد از انتخاب این متغیر، افراد بر اساس مقادیر Xj به دو گروه مختلف در درخت تقسیم می شوند. در این صورت افرادی که MRI آن ها ویژگی های MRI بیمار اسکیزوفرنی را دارد به یک گروه و سایر افراد به گروه دیگر تقسیم می شوند. این فرایند در هر گره به وجود آمده تکرار می شود. مجموعه افراد با \Omega نشان داده می شود. "بهترین پیش بین" اول با X1 نشان داده می شود. بر اساس مقادیر X1 افراد به دو گروه \Omega1` و \Omega2 تقسیم می شوند. که در آن :
گام بعدی الگوریتم ساختن درخت، تشخیص متغیر بعدی است که "بهترین پیش بینی" را برای متغیر Y داشته باشد، اما در داخل هر گروه \Omega1` یا Omega1\ ، زیرگروه های بعدی بر اساس مقادیر Xi2 و Xi3 تعریف می شوند. این فرایند آنقدر به صورت بازگشتی ادامه می یابد تا به شرایط ملاک توقف برسیم. در آخر بعد از ساختن درخت ممکن آن را هرس نماییم، یعنی بعضی شاخه های درخت را حذف می نماییم تا از بیش برازش شدن مدل جلوگیری نماییم[10].
۳. آزمایشها
3.1 مجوعه داده های مورد استفاده برای پیاده سازی9
فایل Train : مجموعه داده ها برای یادگیری، شامل 86 فرد می باشد. این فایل شامل سه مجموعه ی زیر است :
فایل train_labels.csv : به هرکدام از افراد یک Id و یک برچسب داده شده است. به فرد سالم برچسب صفر و به بیمار اسکیزوفرنی برچسب یک داده شده است.
فایل train_FNC.csv : برای هر فرد 378FNC معین شده و اعدادی که به هر FNC نسبت داده شده، که این مقادیر در واقع از ارتباط بین هر جفت نقشه های مغز به دست آمده است.
فایل train_SBM.csv :شامل 32SBM برای هر فرد است. این مقادیر وزن های استانداردی هستند که غلظت ماده خاکستری در مناطق مختلف مغز را نشان می دهند.
فایل Test : واضح است که مجموعه داده هایی که برای تست داده می شوند، فاقد برچسب هستند و تنها ویژگی های اقتباس شده ی FNC و SBM را دارا می باشند.
3.2 پیش پردازش و استخراج ویژگی ها 10
تنها داده ای که در اختیار ما قرار می گیرد عکس های MRI مانند زیر می باشد، لذا لازم است ویژگی هایی را از این عکس ها به دست آوریم تا بتوانیم طبق این ویژگی ها عامل 11 خود را آموزش دهیم.
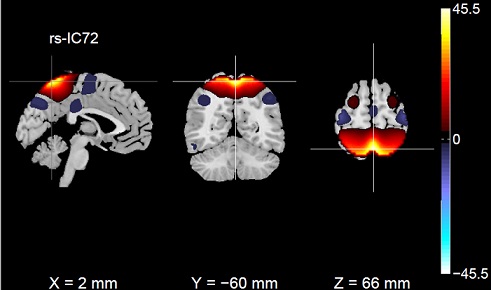
این عکس های رنگی توسط فرایند پردازش تصویر، نقشه های مستقل مغز 12 و ارتباط بین بخش های مختلف در مرور زمان را بررسی می کند و این مقادیر ارتباط را تحت عنوان FNC در فایل train_FNC.csv ذخیره می کند. بنابراین ویژگی FNC13 ، تصویری از الگوی اتصال بین شبکه های مستقل(همان نقشه های مغز) ارائه می دهد.
ویژگی دیگر مربوط به غلظت ماده خاکستری در بخش های مختلف مغز می باشد کهSBM14نامیده می شود.
مراحل اقتباس ویژگی ها از عکس ها نیز در گیت قرار داده شده است.
3.3 روش مدل کردن و یادگیری15
در مرحله ی آموزش از تابع فرایند گوسی به منظور طبقه بندی استفاده کرده ایم. برای استفاده از این فرایند که یک روش دارای فرمول های ریاضی جهت طبقه بندی است، نیاز داریم که از جعبه ابزار16 GPstuff استفاده نماییم. این ابزار را می توانید از این لینک دانلود و نصب نمایید. این ابزار، کامپایلرهای لازم جهت اجرای فرایندهای گوسی در متلب را فراهم می کند. در این برنامه (train.m) سه فایل Excel که در پوشه Train وجود دارد، به عنوان ورودی داده می شود و طبق روابط ریاضی فراید گوسی ، فایل مدل نهایی تحت عنوان gp ذخیره می شود.
3.4 مرحله ی تست کردن و پیش بینی17
کد قسمت پیش بینی ، داده های یادگیری و تست و نیز مدل gp را می خواند و احتمال ابتلا به بیماری را برای هر فرد بیان می کند.
کد های مربوط به پیاده سازی را می توانید از گیت هاب دریافت کنید.
۴. کارهای آینده
۵. مراجع
[1] Michael A. Arbib and T. Nathan Mundhenk. \Schizophrenia and the mirror system: an essay." Neuropsychologia, 43(2):268{280, 2005.
[2] fa.wikipedia.org/wiki/پردازشتصویر
[3] CYH/ImageFundamentals
[4] E. A. Allen, E. Damaraju, S. M. Plis, E. B. Erhardt, T. Eichele, and V. D. Calhoun. Tracking whole-brain connectivity dynamics in the resting state. Cerebral Cortex, pages 663–676, 2012.
[5] J. M. Segall, E. A. Allen, R. E. Jung, E. B. Erhardt, S. K. Arja, K. A. Kiehl, and V. D. Calhoun.Correspondence between structure and function in the human brain at rest. Frontiers in Neuroinformatics, 6(10), 2012.
[6] Arno Solin (arno.solin@aalto.fi) Doctoral student and Simo S¨arkk¨a (instructor) (simo.sarkka@aalto.fi) at Aalto University, Espoo, Finland
[7] http://research.cs.aalto.fi/pml/software/gpstuff/
[8] Can structural MRI aid in clinical classification A machine learning study in two independent samples of patients with schizophrenia, bipolar disorder and healthy subjects
[9]Lebedev_AV__MLSP2014_Sch.pdf - Kaggle
[10]Application and Comparison of Random Forest and CART in Genetic Association Study in Coronary Artery Disease
پیوندهای مفید
Classification
Overfitting
Prior distribution
Likelihood function/distribution
maximum margin
Classification Tree
Regression Tree
Logical if-then conditions
DataSet
PreProcessing
againt
brain maps
Functional Network Connectivity
Source-Based Morphometry
Modeling techniques and training
toolbox
Testing and Prediction